当前位置:网站首页>[acl2020] a novel method of component syntax tree serialization
[acl2020] a novel method of component syntax tree serialization
2022-07-27 09:00:00 【51CTO】

Author of the paper :godweiyang, sink 985 third year graduated school student ,ACM Retired konjak lettuce , Like Algorithm , Currently beating in bytes AI Lab Internship , Amateur likes PUBG and LOL.
「 Address of thesis :」A Span-based Linearization for Constituent Trees[1]
「 Code address :」 https://github.com/AntNLP/span-linearization-parser[2]
「PPT Address :」 https://godweiyang.com/2020/08/30/acl20-yangwei-parsing/ACL2020.pdf[3]
Preface
Unconsciously, I have been practicing in ByteDance for nearly four months , In this high-intensity and fast-paced work life , It is also a great harvest . However, the blog has not been updated for a long time , I have read so many papers , But I haven't had time to write this one in myself . Today, take advantage of the weekend to share my post this year ACL This job on , The main contribution is to propose a novel sequential representation of component syntactic trees . It is suggested to cooperate with my PPT read , There are a lot of examples .
Introduce
The purpose of component parsing task is to parse the phrase structure tree of a sentence , Detailed introductions can be found in the summary I wrote : A review of component parsing ( The second edition )[4].
The current mainstream component parsing methods are mainly divided into two categories according to the normalization goal :
- One is based on CKY Of 「 Global normalization 」 Method , Optimize the sum of scores of the whole syntax tree . That is to use dynamic programming algorithm to analyze , Time complexity is high ( ), But at the same time, the effect is now SOTA Of .
- Second, various 「 Local normalization 」 Method , The optimization goal is to score a single goal ( for example span、action、syntactic distance wait ). This type of method specifically includes methods based on shift-reduce The transfer system 、 Various serialization methods ( for example syntactic distance)、 be based on CKY Local normalization model of decoding, etc , Speed is usually very fast , However, local normalization does not take into account the global characteristics , So the effect is generally poor .
Let's talk about two previous local normalization methods in detail . For example, the parenthesis expression of the prediction syntax tree , Then revert to syntax tree , The effect of this method is very poor , Because it is difficult to solve the problem of the legitimacy of bracket matching , Models are hard to learn . Again syntactic distance, Because the prediction is a sequence of floating-point numbers , So the constraint is too loose , Only the relative size is required to be appropriate , The interpretability is also poor , No peace span Close together , Therefore, the final effect is also general . Finally, the transfer system will also exist exposure bias The problem of , The effect is not satisfactory , Almost no one uses it .
motivation
Back to the topic , For so many problems above , I want to find a better sequence representation , If you can and span It's best to connect more directly . In fact, this paper idea At the beginning of coming out , I want to use GNN(GAT) Of , Then there must be a picture , The traditional component syntax tree is not suitable for direct GNN modeling , Because the number of nodes is uncertain , Pictures cannot be obtained in advance . So I think of an application of dependency syntax tree sent by my senior brother last year GAT The job of :Graph-based Dependency Parsing with Graph Neural Networks[5]. It would be nice if there was a way to make the component syntax tree express as a dependency tree ! So this is me idea It gradually took shape , Although it was not used in the end GNN.
Serialization method
There are many formulas and proofs in my original paper , Here I skip , In fact, the idea of method is very simple .

Serialization examples
As shown in the figure above , Syntax tree may not be binary , So first turn it into a binary tree , Then the binary tree is span In the table ( chart c) The green part is all the left children ( Contains the root node ), The red part is all the right children .
Then you can easily find , There must be no repetition on the right boundary of all left children , So it must correspond one by one The value in , Then you can use them as subscripts after serialization , The corresponding left bound is the serialized value . for instance , In the figure This span It means "loves writing code" The phrase , Then serialize the array The subscript 4 The value at is .
At the same time, we can find , This sequence satisfies another definition , That is to say 「 Must be based on , This can be easily proved by the method of counter evidence .
Finally, you can get the serialized array , At the same time, this sequence satisfies two properties :
- Must be satisfied with , because
- For arbitrary , It must not be in In scope , Otherwise Just like There is a crossover .
At the same time, it can be proved that , Any sequence of nonnegative integers satisfying the above two conditions can be uniquely reduced to a syntax tree . The serialization and deserialization pseudocode is as follows :

Serialization and deserialization algorithms
Note that there is a premise assumption for deserialization here :
Model
There is nothing new about the model , The dependency parsing model is used for reference bi-affine attention.
The input is a word vector 、 Word vector 、 Position vector splicing :
And then use LSTM perhaps Transformer Get the hidden layer representation of each word , In order to distinguish between span The left and right boundaries of represent , I used two expressions :
And then you can use it bi-affine attention Calculate the correlation between the two boundaries :
Then for all less than Of attention Do local normalization , Then we get that the left boundary is
Finally, the left boundary with the highest probability is taken as the predicted sequence value :
For syntax tree label, I didn't directly use the sequence method to predict , Instead, use the sequence first
The loss function is Item structural losses plus
Deserialization
As mentioned before , What if the predicted sequence is illegal ? In fact, the previous two conditions , The first condition can pass mask The way to ensure satisfaction , Generally, the second condition cannot be met , That is, there will be cross span.
The optimal solution is the minimum vertex covering problem , That is, for the predicted
The first way is CKY decode , We directly from set out , Do not decode the sequence
The time complexity of this method is
The second method is top-down decoding , Then look for Of split when , Will satisfy And All of the The biggest one

Example of method 2
The example shown in the figure above may be better understood . This is a greedy decoding , The progressive time complexity is
The third method is similar to method two , Select directly to meet The smallest

Method 3 example
The effect of this method is exactly the same , It may be convenient to implement .
experiment
See the paper directly if you are interested in the detailed experimental comparison results , Here is a general table :

PTB and CTB result
It can be seen that either single model or BERT, Our methods have achieved and SOTA Exactly the same effect . How about the speed ?

Speed comparison
We can see that our speed is much faster than CKY Algorithm , Even more than many sequential methods , And we didn't use Cython To optimize for loop .
Some thoughts
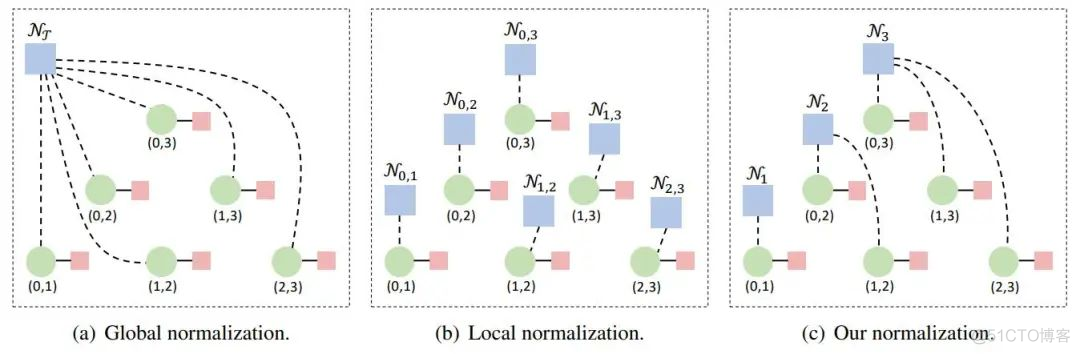
Comparison of normalization methods
And global normalization model (CKY Algorithm ) comparison , What they optimize is the whole syntax tree span The sum of the scores , What we optimize is the sum of all left children's scores . Because we think , The original optimization goal was to include redundancy , After the left child gets , The right child can only be sure .
and CKY Top down greedy optimization of Algorithm + The combination of the two local models proposed by Mr. Zhang Yue , I think our method is also different . Their method will lead to more complex span Express , The same span Will be optimized twice , Therefore, more complex representations are needed to avoid this problem . At the same time, our method only needs matrix operation to predict the structure ,span It means simple , Faster, too .
In addition, there is still a lot of unfinished work :
- Using my sequence method ,GNN It can be used .
- If you use all the right children , Another set of equivalent sequence representations can be generated , How to combine these two sets of representations to accurately decode ?
- Other parsing tasks (CCG,semantic etc. ) Can be transformed into my sequence representation , How to learn these tasks together ?
- Use this expression , Many other downstream tasks ( Machine translation, etc ) Syntactic information can be added , Can you enhance their performance ?
The end of the
I don't know when it will be the next time to share , Autumn moves are also coming to an end , The following is the graduation thesis . If you have the time , I will also share with you the papers I have read recently . Goodbye in the Jianghu !
Reference
[1]
Address of thesis : https://www.aclweb.org/anthology/2020.acl-main.299/
[2]
Code address : https://github.com/AntNLP/span-linearization-parser
[3]
PPT Address : https://godweiyang.com/2020/08/30/acl20-yangwei-parsing/ACL2020.pdf
[4]
A review of component parsing ( The second edition ): https://godweiyang.com/2019/08/15/con-parsing-summary-v2/
[5]
Graph-based Dependency Parsing with Graph Neural Networks: https://www.aclweb.org/anthology/P19-1237/

Author's brief introduction :godweiyang, Know the same name , A master's degree in computer science of East China Normal University , Direction Natural language processing and deep learning . Like to share technology and knowledge with others , Looking forward to further communication with you ~
If you have any questions, you can leave a message in the comments section , Welcome to join us for in-depth communication on wechat ~

边栏推荐
猜你喜欢

4279. Cartesian tree

NIO示例

Flink1.15 source code reading Flink clients client execution process (reading is boring)

flex布局 (实战小米官网)

vscod

String type and bitmap of redis

网络IO总结文

Five kinds of 2D attention finishing (non local, criss cross, Se, CBAM, dual attention)

4274. 后缀表达式

BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Trans
随机推荐
Deep understanding of Kalman filter (1): background knowledge
Huawei machine test question: Martian computing JS
4276. 擅长C
2036: [Blue Bridge Cup 2022 preliminary] statistical submatrix (two-dimensional prefix sum, one-dimensional prefix sum)
【每日算法Day 96】腾讯面试题:合并两个有序数组
被三星和台积电挤压的Intel终放下身段,为中国芯片定制芯片工艺
新年小目标!代码更规范!
Is online account opening safe? Want to know how securities companies get preferential accounts?
Flask login implementation
5G没能拉动行业发展,不仅运营商失望了,手机企业也失望了
[nonebot2] several simple robot modules (Yiyan + rainbow fart + 60s per day)
General Administration of Customs: the import of such products is suspended
【渗透测试工具分享】【dnslog服务器搭建指导】
数智革新
Tensorflow package tf.keras module construction and training deep learning model
Low cost, low threshold, easy deployment, a new choice for the digital transformation of 48 million + small and medium-sized enterprises
PVT的spatial reduction attention(SRA)
Flex layout (actual Xiaomi official website)
【微服务~Sentinel】Sentinel之dashboard控制面板
4279. Cartesian tree