当前位置:网站首页>Pyspark data analysis basis: pyspark.sql.sparksession class method explanation and operation + code display
Pyspark data analysis basis: pyspark.sql.sparksession class method explanation and operation + code display
2022-07-25 22:22:00 【fanstuck】
Catalog
data Parameter code application :
schema Parameter code application :
Focus , Prevent losing , If there is a mistake , Please leave a message , Thank you very much
Preface
Spark SQL It's for structured data processing Spark modular . It provides a method called DataFrame Programming abstraction , By SchemaRDD Come and go . differ SchemaRDD Direct inheritance RDD,DataFrame Did it on its own RDD Most functions of .Spark SQL Added DataFrame( With Schema The information of RDD), Enable users to Spark SQL In the implementation of SQL sentence , Data can come from RDD, It can also be Hive、HDFS、Cassandra Wait for external data sources , It can also be JSON Formatted data .
Spark SQL At present, we support Scala、Java、Python Three languages , Support SQL-92 standard .
So according to the last article :
We know PySpark Can be DataFrame Convert to Spark DataFrame, This is for us python Use Spark SQL Provides the basis for implementation . And in spark3.3.0 In the catalog pyspark sql You can see all functions and class methods :
This article will cover PySpark Of SQL How to use core functions .
One 、pyspark.sql.SparkSession
Basic grammar :
class pyspark.sql.SparkSession(sparkContext: pyspark.context.SparkContext, jsparkSession: Optional[py4j.java_gateway.JavaObject] = None, options: Dict[str, Any] = {})SparkSession It's using Dataset and DataFrame API Programming Spark Entrance point .
SparkSession Can be used to create DataFrame、 take DataFrame Register as a table 、 Execute... On the table SQL、 Cache tables and reads parquet file . To create a SparkSession, You need to use the following generator pattern :
This class can be passed Builder To build SparkSession:
If you don't know about this function, you can see Spark SQL DataFrame Create an article to explain the application and methods and Spark RDD The article "data operation function and conversion function" explains the application and methods in detail These two articles .
Usage method :
spark = SparkSession.builder \
.master("local") \
.appName("Word Count") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()Benchmarking development Spark Of Scala Source code :
// For the time being User sparkContext spark For internal use
// for example SQLContext in this(SparkSession.builder().sparkContext(sc).getOrCreate())
// Used to create SQLContext example
private[spark] def sparkContext(sparkContext: SparkContext): Builder = synchronized {
userSuppliedContext = Option(sparkContext)
this
}
// Set up config To this class options To save , And all kinds of value Other types of overloaded methods
def config(key: String, value: String): Builder = synchronized {
options += key -> value
this
}
// Set up spark.app.name
def appName(name: String): Builder = config("spark.app.name", name)
// Put users in sparkConf Set in the config Add to This class of options In the middle
def config(conf: SparkConf): Builder = synchronized {
conf.getAll.foreach { case (k, v) => options += k -> v }
this
}
// Set up spark.master It can be local、lcoal[*]、local[int]
def master(master: String): Builder = config("spark.master", master)
// Used to check whether the connection can be supported hive Metadata , Support integration hive
def enableHiveSupport(): Builder = synchronized {
//hiveClassesArePresent yes SparkSession Object One way , Used to judge whether it contains
//hive Some support packages for (org.apache.spark.sql.hive.HiveSessionStateBuilder,org.apache.hadoop.hive.conf.HiveConf),
// adopt ClassForName Reflection to determine the required jar Whether there is , From here ClassForName yes spark Self encapsulated , The purpose is to use the Class loader
// If the integration required hive If you rely on everything ,hiveClassesArePresent Returns the true
if (hiveClassesArePresent) {
// In this case Builder Properties of options Add
//catalog Of config (spark.sql.catalogImplementation, hive)
config(CATALOG_IMPLEMENTATION.key, "hive")
} else {
throw new IllegalArgumentException(
"Unable to instantiate SparkSession with Hive support because " +
"Hive classes are not found.")
}
}
// This method is used to add extension points (injection points|extension points) To
//SparkSessionExtensions Inside
def withExtensions(f: SparkSessionExtensions => Unit): Builder = synchronized {
f(extensions)
this
}
that builder() There are the following configurations :
| Method | Description |
|---|---|
| getOrCreate() | Get or create a new SparkSession |
| enableHiveSupport() | increase Hive Support |
| appName() | Set up application Name |
| config() | Setting up various configurations |
| master() | load spark.master Set up |
The most direct way to use this function is to create a sparkContext:
data = sc.parallelize([1, 2, 3])
data.collect()[1, 2, 3]
Create conversion to RDD.
Two 、 Class method
1.parallelize
The method for Spark in SparkContext Class , Used to produce a RDD.
The above has been demonstrated .
2.createDataFrame
Basic grammar
SparkSession.createDataFrame(data,schema=None,samplingRatio=None,verifySchema=True)function
From a RDD、 A list or pandas dataframe The transformation is created as a Spark DataFrame.
Parameter description
- data: The type of acceptance is [pyspark.rdd.RDD[Any], Iterable[Any], PandasDataFrameLike]. Of any kind SQL The data shows (Row、tuple、int、boolean etc. )、 A list or pandas.DataFrame Of RDD.
- schema: The type of acceptance is [pyspark.sql.types.AtomicType, pyspark.sql.types.StructType, str, None] a pyspark.sql.types: data type 、 Data type string or column name list , The default value is none . The data type string format is equal to pyspark.sql.types.DataType.simpleString, Except for the top-level structure type, it can be omitted struct<>.
- When schema Is a column index name , The data type of each column will be defined according to the data type .
- When schema by None when , It will try to infer patterns from the data ( Name and type ), The judgment data is Row、namedtuple or dict.
- When schema by pyspark.sql.types.DataType Or data type string , It must match the real data , Otherwise, an exception will be thrown at runtime . If given schema No pyspark.sql.types.StructType, It will be packaged as pyspark.sql.types.StructType As its unique field , The field name will be “value”. Each record will also be wrapped into a tuple tuple, It can also be converted to row.
- If you don't specify schema, Then use samplingRatio To determine the ratio of rows used for pattern reasoning . If samplingRatio by None, Then use the first line .
- samplingRatio: The type of acceptance :float, optional. The sampling rate of the row used for inference
- verifySchema: Verify the data type of each row according to the schema . Enabled by default .
return
Return to one pyspark.sql.dataframe.DataFrame.
data Parameter code application :
pd_df=pd.DataFrame(
{'name':['id1','id2','id3','id4'],
'old':[21,23,22,35],
'city':[' Hangzhou ',' Beijing ',' nanchang ',' Shanghai ']
},
index=[1,2,3,4])
spark.createDataFrame(pd_df).collect() 
simple=[(' Hangzhou ','40')]
spark.createDataFrame(simple,['city','temperature']).collect() ![]()
simple_dict=[{'name':'id1','old':21}]
spark.createDataFrame(simple_dict).collect()[Row(name='id1', old=21)]
rdd = sc.parallelize(simple)
spark.createDataFrame(rdd).collect()[Row(_1=' Hangzhou ', _2='40')]
schema Parameter code application :
simple=[(' Hangzhou ',40)]
rdd = sc.parallelize(simple)
spark.createDataFrame(rdd, "city:string,temperatur:int").collect()[Row(city=' Hangzhou ', temperatur=40)]
3.getActiveSession
Basic grammar :
classmethod SparkSession.getActiveSession() function :
Back to pass builder Generated activity of the current thread SparkSession
Code example
s = SparkSession.getActiveSession()
simple=[(' Hangzhou ',40)]
rdd = s.sparkContext.parallelize(simple)
df = s.createDataFrame(rdd, ['city', 'temperatur'])
df.select("city").collect()[Row(city=' Hangzhou ')]
4.newSession
Basic grammar :
SparkSession.newSession() function :
New SparkSession Return as a new session , This session has a separate SQLConf、 Registered temporary views and UDF, But share SparkContext And table caching .
Return to a new newSparkSession, It can be used for table data comparison .
5.range
Basic grammar :
SparkSession.range(start,end= None, step: int = 1, numPartitions: = None) function :
Using a single pyspark.sql.types.LongType Column name is id, Contains from start to finish ( Monopoly ) Elements in scope , The step value is step.
Parameter description :
- start: type [int], Starting value
- end: type [int], End value
- step: type [int], step
- numPartitions: type [int],DataFrame Partition number
Code example :
spark.range(1, 100, 20).collect()[Row(id=1), Row(id=21), Row(id=41), Row(id=61), Row(id=81)]
If only one parameter is specified , Then use it as the end value , The default starting value is 0.
spark.range(5).collect()[Row(id=0), Row(id=1), Row(id=2), Row(id=3), Row(id=4)]
6.sql
Basic grammar :
SparkSession.sql(sqlQuery: str, **kwargs: Any)function :
Returns a that represents the result of a given query DataFrame. When specifying kwargs when , This method uses Python The standard formatter formats the given string .
Parameter description :
- sqlQuery: The type of acceptance [str],SQL Query string .
- kwargs: The type of acceptance [dict], What the user wants to set 、 Other variables that can be referenced in the query .
Code example :
spark.sql("SELECT current_date() FROM range(5)").show()
spark.sql(
"SELECT * FROM range(10) WHERE id > {bound1} AND id < {bound2}", bound1=7, bound2=9
).show()
mydf = spark.range(10)
spark.sql(
"SELECT {col} FROM {mydf} WHERE id IN {x}",
col=mydf.id, mydf=mydf, x=tuple(range(4))).show() 
Complex application :
spark.sql('''
SELECT m1.a, m2.b
FROM {table1} m1 INNER JOIN {table2} m2
ON m1.key = m2.key
ORDER BY m1.a, m2.b''',
table1=spark.createDataFrame([(1, "a"), (2, "b")], ["a", "key"]),
table2=spark.createDataFrame([(3, "a"), (4, "b"), (5, "b")], ["b", "key"])).show() 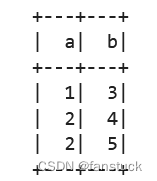
Besides , You can also use DataFrame Medium class:Column The query .
mydf = spark.createDataFrame([(1, 4), (2, 4), (3, 6)], ["A", "B"])
spark.sql("SELECT {df.A}, {df[B]} FROM {df}", df=mydf).show() 
7.table
Basic grammar
SparkSession.table(tableName: str) function :
Use the specified table as DataFrame return .
Focus , Prevent losing , If there is a mistake , Please leave a message , Thank you very much
That's what this issue is all about . I am a fanstuck , If you have any questions, please leave a message for discussion , See you next time .
Refer to the
边栏推荐
- Three ways to allocate disk space
- 访问者模式(visitor)模式
- 淦,为什么 '𠮷𠮷𠮷' .length !== 3 ??
- kubernetes之VictoriaMetrics单节点
- Smart S7-200 PLC channel free mapping function block (do_map)
- On the difference between break and continue statements
- How to call the size of two numbers with a function--- Xiao Tang
- ArcGIS中的WKID
- Nuclear power plants strive to maintain safety in the heat wave sweeping Europe
- TFrecord写入与读取
猜你喜欢

IPv4地址已经完全耗尽,互联网还能正常运转,NAT是最大功臣!

Jenkins+svn configuration

Selenium basic use and use selenium to capture the recruitment information of a website (continuously updating)

『Skywalking』. Net core fast access distributed link tracking platform

Ffmpeg plays audio and video, time_ Base solves the problem of audio synchronization and SDL renders the picture

【C语法】void*浅说
Ts:typera code fragment indentation display exception (resolved) -2022.7.24

QML module not found
4day

What is partition and barrel division?
随机推荐
Don't vote, software testing posts are saturated
Playwright tutorial (I) suitable for Xiaobai
Victoriametrics single node of kubernetes
3dslicer import cone beam CT image
数据平台下的数据治理
All you want to know about interface testing is here
Math programming classification
【PMP学习笔记】第1章 PMP体系引论
3dslicer introduction and installation tutorial
Gan, why '𠮷 𠮷'.Length== 3 ??
How to implement an app application to limit users' time use?
H5 lucky scratch lottery free official account + direct operation
Call of addition, subtraction, multiplication and division of integer type only
Why is the integer type 128 to byte -128
Build commercial projects based on ruoyi framework
Jenkins+svn configuration
kubernetes之VictoriaMetrics单节点
Square root of X
TFrecord写入与读取
Some summary about function