当前位置:网站首页>How much disk IO does a byte of read file actually take place?
How much disk IO does a byte of read file actually take place?
2020-11-08 16:12:00 【Zhang Yanfei Allen】
No matter what language you use ,C/PHP/GO、 still Java, I believe everyone has the experience of reading files . Let's think about two questions , If we read a byte in a file :
- Whether a disk will occur IO?
- If it happens ,Linux How many bytes were actually read to disk ?
To make it easier to understand the problem , We put c The code for is listed :
int main()
{
char c;
int in;
in = open("in.txt", O_RDONLY);
read(in,&c,1);
return 0;
}
If not engaged in c/c++ Students in the development work , It's really not easy to understand this problem in depth . Because the mainstream language that is commonly used at present ,PHP/Java/Go The encapsulation level of what is relatively high , Many details of the kernel are completely shielded . If you want to make the above two questions clear , It needs to be cut open Linux To understand from the inside of Linux Of IO Stack .
Linux IO Introduction to the stack
I don't say much nonsense , Let's go straight to Linux IO A simplified version of the stack is drawn :( Official IO The stack refers to this Linux.IO.stack_v1.0.pdf)
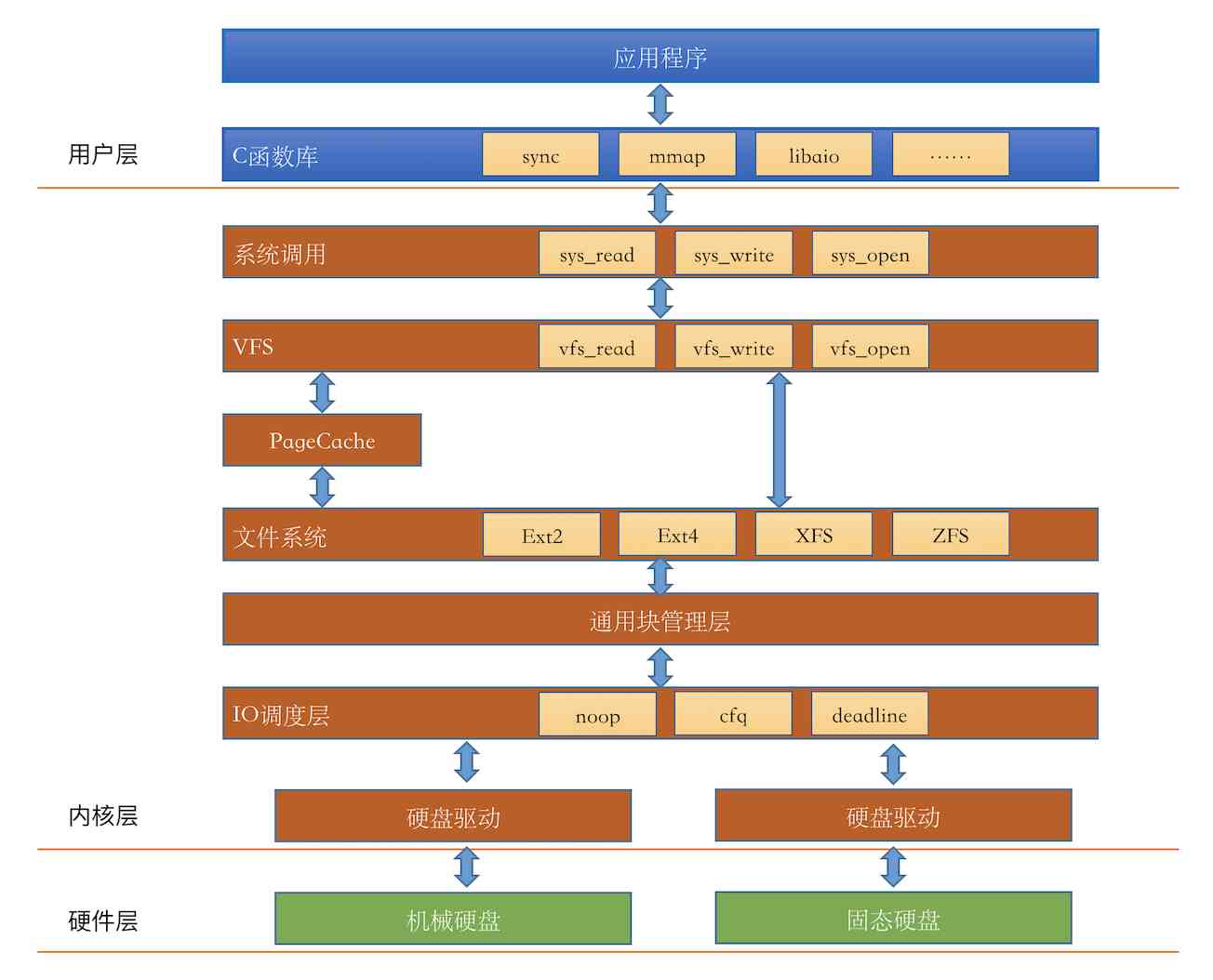
We also shared several articles earlier on the hardware layer in the figure above , And file system module . But through this IO Stack we found , We are right. Linux Of documents IO The understanding of is still far from enough , There are several kernel components :IO engine 、VFS、PageCache、 General management block 、IO We don't know much about scheduling layer and other modules . take it easy , Let's come together :
IO engine
We develop students who want to read and write files , stay lib The library layer has many functions to choose from , such as read,write,mmap etc. . This is actually a choice Linux Provided IO engine . What we use most often read、write Functions belong to sync engine , except sync, also map、psync、vsync、libaio、posixaio etc. . sync,psync It's all synchronous ,libaio and posixaio It's asynchronous IO.
Yes, of course IO The engine also needs VFS、 General block layer and other lower level support can be realized . stay sync Engine read Function will enter VFS Provided read system call .
VFS Virtual file system
In the kernel layer , The first thing to see is VFS.VFS The idea was to abstract a generic file system model , Provide a set of common interfaces for our developers or users , Let's not care Specific file system implementation .VFS There are four core data structures provided , They are defined in the kernel source code include/linux/fs.h and include/linux/dcache.h in .
- superblock:Linux Used to mark information about a specific installed file system
- inode:Linux Every file in has a inode, You can take inode The ID card that is understood as a document
- file: File objects in memory , It is used to save the correspondence between process and disk file
- desty: Catalog items , It's part of the path , All the directory entry objects are concatenated into one tree Linux Under the directory tree .
Around these four core data structures ,VFS It also defines a series of operation methods . such as ,inode The definition of the operation method of inode_operations(include/linux/fs.h), It defines what we are very familiar with mkdir and rename etc. .
struct inode_operations {
......
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*mkdir) (struct inode *,struct dentry *,umode_t);
int (*rmdir) (struct inode *,struct dentry *);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *, unsigned int);
......
stay file Corresponding operation method file_operations It defines what we often use read and write:
struct file_operations {
......
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
......
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
Page Cache
stay VFS Look down , We have noticed Page Cache. Its Chinese translation is called page cache , yes Linux The main disk cache used by the kernel , Is a pure memory working component , Its function is to speed up access to relatively slow disks . If you want to access the file block It happens to exist in Page Cache Inside , So there's no actual disk IO happen . If it doesn't exist , Then you will apply for a new page , Issue page break , And then read it on disk block Content to fill it in , Next time use it directly .Linux The kernel uses a search tree to efficiently manage a large number of pages .
If you have a special need you want to bypass Page Cache, Just set DIRECT_IO That's all right. . There are two situations that need to be bypassed :
- Test disk IO Real performance of
- Save the use of Page Cache When the system call falls into kernel state , And copy kernel memory to user process memory to overhead .
file system
In my previous article 《 How much disk space does a new empty file take ?》、《 Understand the principle of formatting 》 It's all about specific file systems . The two most important concepts in a file system are inode and block, We have seen both of them in previous articles . One block How big , This is decided by operation and maintenance when formatting , The general default is 4KB.
except inode and block, Each file system also defines its own actual operation function . For example, in ext4 As defined in ext4_file_operations and ext4_file_inode_operations as follows :
const struct file_operations ext4_file_operations = {
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.mmap = ext4_file_mmap,
.open = ext4_file_open,
......
};
const struct inode_operations ext4_file_inode_operations = {
.setattr = ext4_setattr,
.getattr = ext4_file_getattr,
......
};
General block layer
The general block layer is all the block devices in a processing system IO The requested kernel module . It defines a name called bio To represent once IO Operation request (include/linux/bio.h).
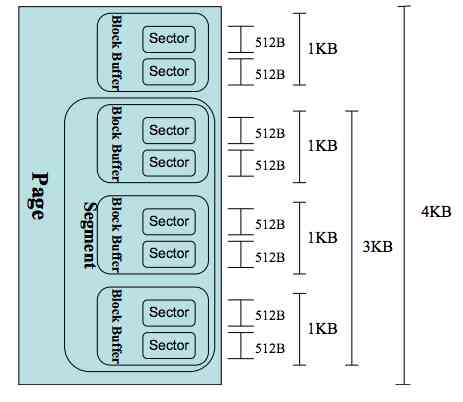
So once bio Corresponding to IO The size unit is the page , Or sectors ? Are not , It's a paragraph ! Every bio It may contain multiple segments . A segment is a complete page , Or part of the page , Please refer to https://www.ilinuxkernel.com/files/Linux.Generic.Block.Layer.pdf.
Why come up with something so puzzling ? This is because of the data continuously stored on the disk , When it comes to memory Page Cache The memory may not be continuous . It's normal for this to happen , I can't say that continuous data in the disk, I have to use continuous space to cache in memory . Segment is to make memory available once IO DMA To many “ paragraph ” Address is not continuous in memory .
A common sector / paragraph / The page size comparison is shown in the figure below :
IO Scheduling layer
When the general block layer puts IO After the request was actually sent out , It doesn't have to be executed immediately . Because the scheduling layer will start from the overall situation , Try to make the whole disk IO Maximize performance . The general way to work is to make the head work like an elevator , Go in one direction first , Come back at the end of the day , In this way, the disk efficiency will be higher . The specific algorithms are noop,deadline and cfg etc. .
On your machine , adopt dmesg | grep -i scheduler To check out your Linux Supported algorithms , And you can choose one of them when testing .
The process of reading files
We have Linux IO The various kernel components in the stack are introduced . Now let's go through the whole process of reading files from the beginning
- lib Inside read Function first enters the system call sys_read
- stay sys_read Enter again VFS Inside vfs_read、generic_file_read Such as function
- stay vfs Inside generic_file_read Will determine whether the cache hit , Hit returns
- If the kernel is not hit Page Cache Assign a new page box to , Issue page break ,
- The kernel initiates blocks to the general block layer I/O request , Block devices block disks 、U The difference between plates
- General block layer uses bio Representative I/O Ask to put in IO Request queue
- IO The scheduling layer uses the elevator algorithm to schedule the requests in the queue
- The driver sends a read command to the disk controller to control ,DMA The method is filled directly into Page Cache New page box in
- The controller sends out interrupt notification
- The kernel will be what the user needs 1 Bytes filled into user memory
- Then your process is awakened
You can see , If Page Cache If you hit it , There's no disk at all IO produce . therefore , Don't think that the performance will be slow if there are several read-write logic in the code . The operating system has been optimized a lot for you , Memory level access latency is about ns Grade , Than mechanical disks IO fast 2-3 An order of magnitude . If you have enough memory , Or your files are accessed frequently enough , In fact, at this time read Very few operations have real disks IO happen .
Let's look at the second situation , If Page Cache If you miss ,Linux How many bytes of disk are actually carried out IO. Whole IO Several kernel components are involved in the process . Each component uses different length blocks to manage disk data .
- Page Cache It's in pages ,Linux Page size is usually 4KB( Avoid being pricked by gods , Here under Linux Can set up large memory pages )
- File systems are managed in blocks . Use
dumpe2fsYou can see , Generally, a block defaults to 4KB - The general block layer deals with disks in segments IO Requested , A segment is a page or part of a page
- IO The scheduler passes through DMA Mode transmission N Sectors to memory , The sector is usually 512 byte
- Hard disk also uses “ A sector ” Management and transmission of data
You can see , Although we are really read-only from the user's point of view 1 Bytes ( In the opening code, we only give this disk IO Left a byte of cache ). But throughout the kernel workflow , The smallest unit of work is the sector of the disk , by 512 byte , Than 1 It's a lot bigger than a byte . in addition block、page cache Higher level components work in larger units , So the actual disk read is a lot of bytes together . If a segment is a memory page , One disk IO Namely 4KB(8 individual 512 Byte sector ) Read together .
Linux What we don't talk about in the kernel is that there is also a complex pre read strategy . therefore , In practice , Maybe it's better than 8 More sectors are transferred to memory together .
Last
The original intention of operating system is to make you simple and reliable , Let's try to think of it as a black box . You want a byte , It gives you a byte , But I did a lot of work in silence . Although most of our domestic development is not at the bottom , But if you're concerned about the performance of your application , You should understand when the operating system quietly improves your performance , How to improve . So that at some time in the future your online server can't bear to hang up , You can quickly find out where the problem lies .
Let's expand , If Page Cache missed , Then there must be disks that drive to the mechanical shaft IO Do you ?
Not necessarily , Why? , Because now the disk itself will carry a cache . In addition, today's servers will build disk arrays , The core hardware in a disk array Raid The card will also integrate RAM As caching . Only when all the caches miss , The mechanical shaft works only with a magnetic head .

Development of hard disk album of internal training :
- 1. Disk opening : Take off the hard coat of the mechanical hard disk !
- 2. Disk partitioning also implies technical skills
- 3. How can we solve the problem that mechanical hard disks are slow and easy to break down ?
- 4. Disassemble the SSD structure
- 5. How much disk space does a new empty file take ?
- 6. Only 1 How much disk space does a byte file actually take up
- 7. When there are too many documents ls Why is the command stuck ?
- 8. Understand the principle of formatting
- 9.read How much disk does a byte of file actually take place on IO?
- 10.write When to write to disk after one byte of file IO?
- 11. Mechanical hard disk random IO Slower than you think
- 12. How much faster is a server equipped with a SSD than a mechanical hard disk ?
My official account is 「 Develop internal skill and practice 」, I'm not just talking about technical theory here , It's not just about practical experience . It's about combining theory with practice , Deepen the understanding of theory with practice 、 Use theory to improve your technical practice ability . Welcome to my official account , Please also share with your friends ~~~
版权声明
本文为[Zhang Yanfei Allen]所创,转载请带上原文链接,感谢
边栏推荐
- Js中常见的内存泄漏场景
- Don't release resources in finally, unlock a new pose!
- It's just right. It's the ideal state
- 一分钟全面看懂forsage智能合约全球共享以太坊矩阵计划
- Build simple business monitoring Kanban based on Alibaba cloud log service
- GopherChina 2020大会
- .NET 大数据量并发解决方案
- 构建者模式(Builder pattern)
- Xiaoqingtai officially set foot on the third day of no return
- Tencent: Although Ali's Taichung is good, it is not omnipotent!
猜你喜欢
Liteos message queuing

Use markdown
学习记录并且简单分析

We made a medical version of the MNIST dataset, and found that the common automl algorithm is not so easy to use

Comics: looking for the best time to buy and sell stocks
The birth of a new integrated memory and computing chip is conducive to the application of artificial intelligence~
漫画:寻找股票买入卖出的最佳时机(整合版)
10个常见的软件架构模式
laravel8更新之维护模式改进
DeepMind 最新论文解读:首次提出离散概率树中的因果推理算法
随机推荐
GopherChina 2020大会
wanxin finance
uni-app实战仿微信app开发
别再在finally里面释放资源了,解锁个新姿势!
聊聊Go代码覆盖率技术与最佳实践
API生命周期的5个阶段
vim-配置教程+源码
Drink soda, a bottle of soda water 1 yuan, two empty bottles can change a bottle of soda, give 20 yuan, how much soda can you
Apache Kylin远程代码执行漏洞复现(CVE-2020-1956)
Alibaba cloud accelerates its growth and further consolidates its leading edge
数据库连接报错之IO异常(The Network Adapter could not establish the connection)
浅谈,盘点历史上有哪些著名的电脑病毒,80%的人都不知道!
Stm32uberide download and install - GPIO basic configuration operation - debug (based on CMSIS DAP debug)
阿里云视频云技术专家 LVS 演讲全文:《“云端一体”的智能媒体生产制作演进之路》
Jsliang job series - 07 - promise
喜获蚂蚁offer,定级p7,面经分享,万字长文带你走完面试全过程
AI周报:允许“员工自愿降薪”;公司回应:员工内心高兴满意;虎牙HR将员工抬出公司;瑞典禁用华为中兴5G设备
Golang ICMP Protocol detects viable hosts
Summary of rendering of water wave and caustics (etching) in webgl
我们做了一个医疗版MNIST数据集,发现常见AutoML算法没那么好用