当前位置:网站首页>机械硬盘随机IO慢的超乎你的想象
机械硬盘随机IO慢的超乎你的想象
2020-11-08 16:12:00 【张彦飞allen】
大家都知道硬盘的随机IO很慢,但是比顺序IO慢多少呢,不知道你是否有过数字上的直接对比。今天我来实际压测对比一下磁盘在顺序IO和随机IO不同场景下的性能数据表现。通过今天的实验数据,你将能深刻理解数据库事务中为什么要用日志的方式来实现,为什么索引中要用节点更大的B+树。
对于任何存储系统,性能指标无非就是带宽、延迟或IOPS。我的测试机器的硬盘配置是一个由7块300G万转机械磁盘组成的RAID5,压测工具使用的fio,压测过程中,我们固定几个参数:
- IO引擎我们选择libaio
- 为了避免操作系统管理的PageCache内存对测试结果的干扰,使用direct参数绕开
- 打开unified_rw_reporting,让结果中分别显示读和写
- 为了保证测试相对准确,我们运行时间设置为300s
- 由于服务器敏感性,压测对象没有选择裸设备,用的文件,会有一点文件系统额外开销
- 测试文件尺寸定义为100G,我的RAID卡缓存是1G,目的就是让它的命中率别太高
- 调度策略我们选择最最常用的noop
- 打开refill_buffers,每次I/O提交后都重新生成测试文件数据片段,保证随机性
- 按照RAID使用配置建议,关闭掉磁盘自带缓存
然后再对另外的参数进行动态调整,然后进行多次对比测试
- 读写模式上,使用顺序读和随机读进行分别验证
- 磁盘IO单位我们使用扇区的整数倍,512 1K 2K ...
- RAID卡预读策略,分别设置NORA(不开启预读)和RA(开启预读)来独立测试
顺序读取测试
我们先来看一下顺序读取情况下,在该磁盘阵列的带宽表现,见图1:

可以看到,当IO size比较小的时候,即使是顺序发起连续IO请求,带宽表现也不算给力,只有不到20MB/s。随着IO size增加的时候,带宽也上来了,最大能够达到1.2GB多。
大家注意看下在NORA情况下,在128K增加到256K的时候,带宽突然增加了很多,这是为啥呢?秘密在于我的RAID阵列里的条带大小是128K,当IO size为256K的时候,磁盘阵列才开始真正并行工作了。IO size小的时候,并不能发挥多盘优势。
/opt/MegaRAID/MegaCli/MegaCli64 -LDInfo -Lall -aALL
......
Strip Size : 128 KB
另外就是对于顺序IO的情况,RA预取也能起到一些作用,在IO size在64k的时候就能够达到1.2GB的带宽。
我们再来看延迟,见图2:

我们图中的单位是微秒-us,在《简单聊聊磁盘分区》中,我对磁盘耗时进行过理论上的估算,磁盘耗时主要在两个地方:
- 寻道时间:3-15ms,这个耗时可以通过合理分区优化
- 旋转延迟:万转磁盘这个延迟大概0-6ms
为什么在图2实验结果里,延时却都很低,在IO size为512的时候,平均竟然只有30us左右?其实顺序IO的情况下,RAID卡缓存命中率很高,其实绝大部分的读请求并没有穿透到让磁盘的机械轴来工作。
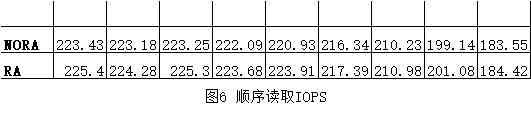
我们再来看IOPS,见图3:

在IO请求size正好为1个扇区大小的时候,磁盘阵列的IOPS表现最高,达到了3W多次每秒。当IO size增加的时候,IOPS在逐步下降,但这时候,其实磁盘的吞吐是在增加的。
汇总一下,磁盘阵列在顺序IO的情况下表现还是很不错的,原因有三个:
- 顺序IO的情况下,RAID卡的命中率高,尤其是设置了RAID预取
- 单盘本身顺序IO也是磁盘工作最舒服的状态,因为节约了寻道的延时
- 当IO超过RAID条状大小的时候,IO会分散到多块盘上并行处理
随机读取测试
我们作为开发者使用磁盘的时候,可能不一定能保证永远都能让它工作在最舒服的状态,有些时候可能也必须得让它进行随机访问。所以我们今天也试一下我的磁盘阵列在随机情况下的表现,对于fio工具来说只需要设置rw参数为randread既可。不过IO size我只测试到了128就停了,因为再大了就越像顺序IO了。
我们还是先来看带宽,见图4:

机械硬盘即使是组成了RAID阵列,而且还有缓存,貌似对随机IO也无可奈何。在随机IO的情况下,带宽吞吐糟糕透了,在IO size比较小的时候,竟然只有零点几兆每秒。
我们再来看延时,见图5:

随机情况下延时基本都5ms左右,这就和我们前面理论上的计算结果对上了。随机访问导致更多的请求真正穿透到了机械轴上。
再来看IOPS,这个指标也很差,也就是200左右吧。这个数据和图5的延迟形成了呼应,处理一次请求5ms左右,那么1秒可不就是只能处理200次左右么。所以硬盘厂家们天天给你吹风,说他家磁盘IOPS能达到几万几万。但是他们从来闭口不提随机IO情况下,其实特么的只有200。
大家看到了我的万转机械硬盘组成RAID5阵列,在顺序条件最好的情况下,带宽可以达到1GB/s以上,平均延时也非常低,最低只有20多us。但是在随机IO的情况下,机械硬盘的短板就充分暴露了,零点几兆的带宽,将近5ms的延迟,IOPS只有200左右。其原因是因为
- 随机访问直接让RAID卡缓存成了个摆设
- 磁盘不能并行工作,因为我的机器RAID宽度Strip Size为128 KB
- 机械轴也得在各个磁道之间跳来跳去。
理解了磁盘顺序IO时候的几十M甚至一个GB的带宽,随机IO这个真的是太可怜了。
结论
从上面的测试数据中我们看到了机械硬盘在顺序IO和随机IO下的巨大性能差异。在顺序IO情况下,磁盘是最擅长的顺序IO,再加上Raid卡缓存命中率也高。这时带宽表现有几十、几百M,最好条件下甚至能达到1GB。IOPS这时候能有2-3W左右。 到了随机IO的情形下,机械轴也被逼的跳来跳去寻道,RAID卡缓存也失效了。带宽跌到了1MB以下,最低只有100K,IOPS也只有可怜巴巴的200左右。
如果你真正理解了以上实验中的数据,就能理解很多工程实践中的许多的事情。
复制文件夹:我们都知道,在复制一个文件夹的时候,如果这个文件夹里面包含了许多堆碎文件,这时候复制起来非常慢。原因就是这时候机械硬盘大概率都是在随机IO。怎么提高复制速度呢?很简单,就是把它们先打一个包。打包之后这个文件夹就变成一个大文件了,这时候再复制的话,磁盘就是执行的最擅长的顺序IO了,所以会快很多。
数据库事务:所有的数据库在实现事务的时候,都要保证写数据落盘成功才能返回。但为什么他们几乎都是落盘到自己的事务日志文件里去就返回成功的,而不是直接写入到数据表文件里。这背后的原因还是磁盘读写性能问题,事务只需要保证数据落地成功就可以,至于写到哪里并不重要。写到数据文件中的话大概率就变成随机IO了。如果写到一个日志文件中,就是地地道道的顺序IO,性能就发挥到极致。
Mysql的B+树:在上面的数据中大家还可以看到,无论是顺序IO还是随机IO,只要增加每次IO的单位,性能都会上涨。理解了这个,你就能真正理解为什么Mysql是采用B+树当索引,而不是用其它的树了(比如二叉树)。因为B+树的节点更大,IO起来会让磁盘工作更舒服一些。
最后结尾我想分享一个5年前我在工程中实际性能优化的案例。当时接手了一个系统,要用数以百万级的用户imei,到Mysql中去查询用户的另一个字符串id(clientid)数据。前开发的实现方式是传统的分批进行Mysql语句查询。这种实现下,且不说多次的网络RTT耗时,单说Mysql查询,即使是有索引这时候也得需要进行大量的随机IO,因为用户imei是随机分布的。我采用的优化方式也非常简单,直接把Mysql用户整张用户表一次性通过顺序IO的方式读出来,load到内存中。在内存中用HashTable组织好,通过Hash的方式进行快速查询。最终耗时优化掉了90%以上。

开发内功修炼之硬盘篇专辑:
- 1.磁盘开篇:扒开机械硬盘坚硬的外衣!
- 2.磁盘分区也是隐含了技术技巧的
- 3.我们怎么解决机械硬盘既慢又容易坏的问题?
- 4.拆解固态硬盘结构
- 5.新建一个空文件占用多少磁盘空间?
- 6.只有1个字节的文件实际占用多少磁盘空间
- 7.文件过多时ls命令为什么会卡住?
- 8.理解格式化原理
- 9.read文件一个字节实际会发生多大的磁盘IO?
- 10.write文件一个字节后何时发起写磁盘IO?
- 11.机械硬盘随机IO慢的超乎你的想象
- 12.搭载固态硬盘的服务器究竟比搭机械硬盘快多少?
我的公众号是「开发内功修炼」,在这里我不是单纯介绍技术理论,也不只介绍实践经验。而是把理论与实践结合起来,用实践加深对理论的理解、用理论提高你的技术实践能力。欢迎你来关注我的公众号,也请分享给你的好友~~~
版权声明
本文为[张彦飞allen]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4746202/blog/4707205
边栏推荐
- LiteOS-消息队列-实战
- 二叉树的四种遍历方应用
- Improvement of maintenance mode of laravel8 update
- C++的那些事儿:从电饭煲到火箭,C++无处不在
- SQL 速查
- Android Basics - check box
- Travel notes of Suzhou
- Improvement of rate limit for laravel8 update
- The first open source Chinese Bert pre training model in the financial field
- Flink: from introduction to Zhenxiang (3. Reading data from collection and file)
猜你喜欢

Xiaoqingtai officially set foot on the third day of no return

Python基础语法
Solution to the problem of offline connection between ADB and mobile phone

Talking about, check the history of which famous computer viruses, 80% of the people do not know!
用 Python 写出来的进度条,竟如此美妙~
阿里云加速增长,进一步巩固领先优势
Travel notes of Suzhou
基于阿里云日志服务快速打造简版业务监控看板
Millet and oppo continue to soar in the European market, and Xiaomi is even closer to apple
Flink from introduction to Zhenxiang (7. Sink data output file)
随机推荐
Arduino IDE搭建ESP8266开发环境,文件下载过慢解决方法 | ESP-01制作WiFi开关教程,改造宿舍灯
构建者模式(Builder pattern)
Drink soda, a bottle of soda water 1 yuan, two empty bottles can change a bottle of soda, give 20 yuan, how much soda can you
svg究竟是什么?
“他,程序猿,35岁,被劝退”:不要只懂代码,会说话,胜过10倍默默努力
Returning to the third place in the world, what did Xiaomi do right?
【Python 1-6】Python教程之——数字
构建者模式(Builder pattern)
华为在5G手机市场占据绝对优势,市调机构对小米的市占出现分歧
laravel8更新之速率限制改进
第五章编程题
wanxin finance
Elasticsearch learning one (basic introduction)
Python基础语法
用 Python 写出来的进度条,竟如此美妙~
AI周报:允许“员工自愿降薪”;公司回应:员工内心高兴满意;虎牙HR将员工抬出公司;瑞典禁用华为中兴5G设备
It's just right. It's the ideal state
擅长To C的腾讯,如何借腾讯云在这几个行业云市场占有率第一?
Blockchain weekly: the development of digital currency is written into the 14th five year plan; Biden invited senior adviser of MIT digital currency program to join the presidential transition team; V
I used Python to find out all the people who deleted my wechat and deleted them automatically