当前位置:网站首页>Google's AI model, which can translate 101 languages, is only one more than Facebook
Google's AI model, which can translate 101 languages, is only one more than Facebook
2020-11-08 12:56:00 【osc_1x6ycmfm】

Big data digest
source :VB
10 End of month ,Facebook Released a translatable 100 Machine learning models for languages , Microsoft has released a version that can translate 94 Models of languages , Google, of course, is not to be outdone .
Following Facebook After Microsoft , Google has open source a MT5 Model of , The model has achieved the most advanced results in a series of English natural language processing tasks .
MT5 It's Google's T5 Multilingual variants of the model , Is already containing 101 Pre training was conducted in data sets of six languages , Just like Facebook There's one more .
Github Address :
https://github.com/google-research/multilingual-t5
MT5 contain 3 Million to 130 One hundred million parameters , It can be directly applied to multiple language environments
MT5 contain 3 Million to 130 One hundred million parameters , It is reported that , It can learn 100 Multiple languages without interference .
MT5 Is in MC4 Trained on ,MC4 yes C4 A subset of ,MC4 Contains about 750GB The English text of , These texts come from Common Crawl The repository (Common Crawl Contains billions of web pages crawled from the Internet ). although C4 The dataset is explicitly designed to use only English , but MC4 covers 107 Languages , contain 10,000 Web pages or more .
however , There are still some deviations in the data set , Google researchers are trying to remove MC4 Duplicate lines in the document and filter pages with incorrect words to alleviate MT5 The deviation of . They also used tools to detect the main language of each page , And deleted credibility lower than 70% The page of .
Google said , maximal MT5 The model has 130 One hundred million parameters , More than the 2020 year 10 All benchmarks for monthly testing . Of course , Whether the benchmark fully reflects the real performance of the model , This is a topic worthy of debate .
Some research shows that , Open Domain Question Answering Model (Open-Domain Question-Answering, A model that can theoretically answer novel questions with novel answers ) It's usually just a matter of simply remembering the answers found in the training data based on the data set . But Google researchers assert that MT5 It's a step towards a powerful model , These functions do not require challenging modeling techniques .
Google researchers describe MT5 In his paper, he wrote ,“ in general , Our findings highlight the importance of model competence in cross language representation learning , And show , By relying on filtering 、 Parallel data or intermediate tasks , Expanding the simple pre training formula is a viable alternative .”“ We demonstrated T5 Recipes are directly applicable to Multilingual Settings , And it achieves powerful performance on different benchmark sets .”
comparison Facebook And Microsoft , Google's MT5 It seems to be a little better
Facebook The new model of is called M2M-100,Facebook Claim to be the First Multilingual Machine Translation Model , Can be directly in 100 Translate back and forth between any pair of languages .Facebook AI Build a total of 100 Language 75 A huge data set of hundreds of millions of sentences . Using this dataset , The research team trained a man with more than 150 A universal translation model with hundreds of millions of parameters , According to the Facebook A blog description of , The model can “ Get information about the relevant language , And reflect a more diverse language text and language form ”.
And Microsoft's machine learning translation model is called T-ULRv2, It can be translated. 94 Languages . Microsoft claims ,T-ULRv2 stay XTREME( A natural language processing benchmark created by Google ) Got the best search results in , And will use it to improve Word Semantic search in 、Outlook and team Reply suggestions and other functions in .
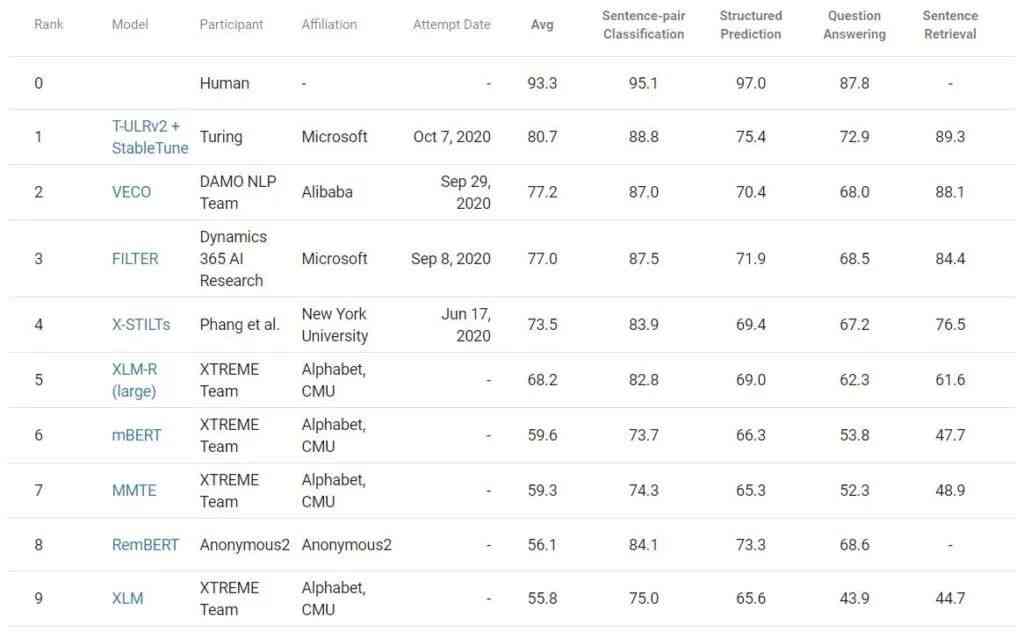
T-ULRv2 stay XTREME At the top of the list
T-ULRv2 It is a joint research product of Microsoft Research Institute and Turing team , contain 5.5 One hundred million parameters , The model uses these parameters to predict . Microsoft researchers trained on a multilingual data corpus T-ULRv2, The data corpus comes freely 94 Web pages made up of languages . In the process of training ,T-ULRv2 Translation by predicting the hidden words in sentences of different languages , Occasionally, contextual cues are obtained from paired translations of English and French .
All in all , In terms of the number of languages translated , Google's MT5 It seems to be a little better , But large numbers don't mean high accuracy , Just Google and Facebook For two translation models , There is still room for improvement in the translation of some low resource languages , Like wolov 、 Malathi . Besides , Each machine learning model will have a certain deviation , Just like Allen AI What the researchers at the Institute said ,“ The existing machine learning technology can not avoid this defect , People are in urgent need of better training mode and model construction ”.
Relevant reports :
https://venturebeat.com/2020/10/26/google-open-sources-mt5-a-multilingual-model-trained-on-over-101-languages/
https://venturebeat.com/2020/10/20/microsoft-details-t-urlv2-model-that-can-translate-between-94-languages/
The main work of the future intelligent laboratory includes : establish AI Intelligence system intelligence evaluation system , Carry out the world artificial intelligence IQ evaluation ; Launch the Internet ( City ) Cloud brain research project , Building the Internet ( City ) Cloud brain technology and enterprise map , For the promotion of enterprises , Intelligent level service of industry and city .
If you are interested in laboratory research , Welcome to the future intelligent laboratory online platform . Scan the QR code below or click on the bottom left corner of this article “ Read the original ”

版权声明
本文为[osc_1x6ycmfm]所创,转载请带上原文链接,感谢
边栏推荐
- Where is the new target market? What is the anchored product? |Ten questions 2021 Chinese enterprise service
- Flink: from introduction to Zhenxiang (6. Flink implements UDF function - realizes more fine-grained control flow)
- 为 Docsify 自动生成 RSS 订阅
- 你的云服务器可以用来做什么?云服务器有什么用途?
- 新的目标市场在哪里?锚定的产品是什么?| 十问2021中国企业服务
- 这次,快手终于比抖音'快'了!
- 华为云重大变革:Cloud&AI 升至华为第四大 BG ,火力全开
- Tight supply! Apple's iPhone 12 power chip capacity exposed
- 第二次作业
- 啥是数据库范式
猜你喜欢

值得一看!EMR弹性低成本离线大数据分析最佳实践(附网盘链接)
OR Talk NO.19 | Facebook田渊栋博士:基于蒙特卡洛树搜索的隐动作集黑盒优化 - 知乎
Service architecture and transformation optimization process of e-commerce trading platform in mogujie (including ppt)
Ali teaches you how to use the Internet of things platform! (Internet disk link attached)
This paper analyzes the top ten Internet of things applications in 2020!
Bccoin tells you: what is the most reliable investment project at the end of the year!
The young generation of winner's programming life, the starting point of changing the world is hidden around
C语言I博客作业03
新的目标市场在哪里?锚定的产品是什么?| 十问2021中国企业服务
PMP experience sharing
随机推荐
Major changes in Huawei's cloud: Cloud & AI rises to Huawei's fourth largest BG with full fire
Flink from introduction to Zhenxiang (7. Sink data output file)
用 Python 写出来的进度条,竟如此美妙~
[Python 1-6] Python tutorial 1 -- number
Tight supply! Apple's iPhone 12 power chip capacity exposed
211 postgraduate entrance examination failed, stay up for two months, get the byte offer! [face to face sharing]
Understanding design patterns
Flink from introduction to Zhenxiang (10. Sink data output elasticsearch)
还不快看!对于阿里云云原生数据湖体系全解读!(附网盘链接)
Flink: from introduction to Zhenxiang (6. Flink implements UDF function - realizes more fine-grained control flow)
值得一看!EMR弹性低成本离线大数据分析最佳实践(附网盘链接)
Personal current technology stack
Python basic syntax
Windows10关机问题----只有“睡眠”、“更新并重启”、“更新并关机”,但是又不想更新,解决办法
Ali tear off the e-commerce label
Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
优化if-else代码的八种方案
A scheme to improve the memory utilization of flutter
android基础-CheckBox(复选框)
11 server monitoring tools commonly used by operation and maintenance personnel