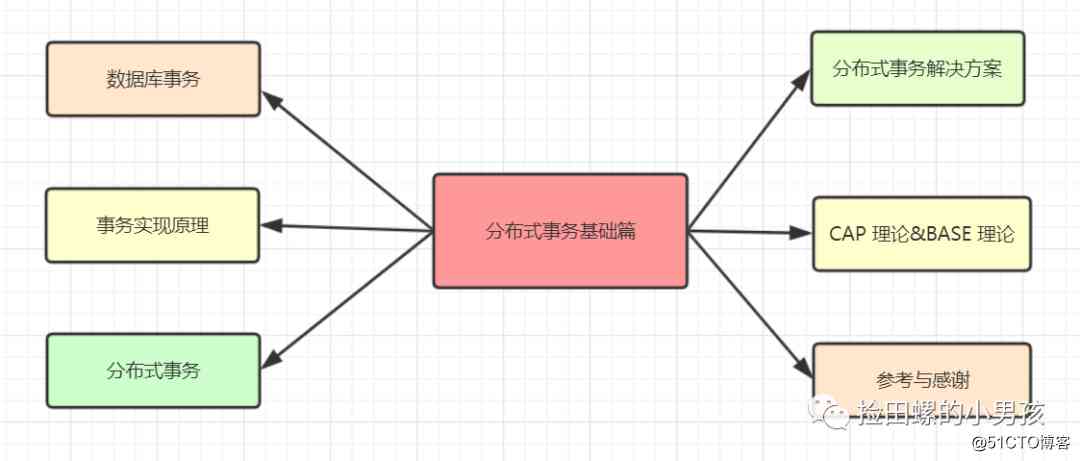
当前位置:网站首页>后端程序员必备:分布式事务基础篇
后端程序员必备:分布式事务基础篇
2020-11-08 12:11:00 【osc_lg0msmnd】
前言
最近看了几篇有关于分布式事务的博文,做一下笔记。哈哈~
数据库事务
数据库事务(简称:事务),是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。
数据库事务的几个典型特性:原子性(Atomicity )、一致性( Consistency )、隔离性( Isolation)和持久性(Durabilily),简称就是ACID。
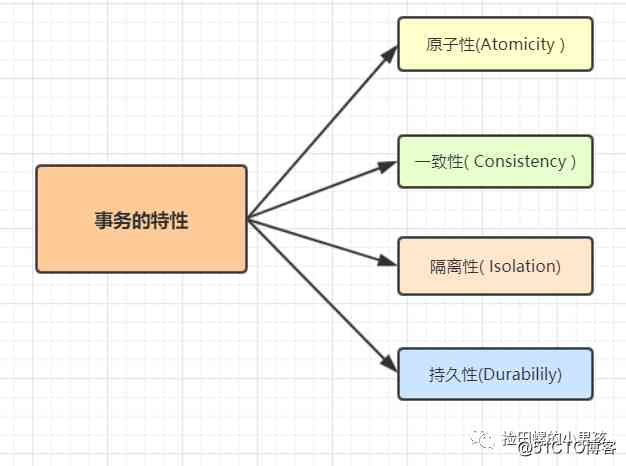
- 原子性: 事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性: 指在事务开始之前和事务结束以后,数据不会被破坏,假如A账户给B账户转10块钱,不管成功与否,A和B的总金额是不变的。
- 隔离性: 多个事务并发访问时,事务之间是相互隔离的,即一个事务不影响其它事务运行效果。简言之,就是事务之间是进水不犯河水的。
- 持久性: 表示事务完成以后,该事务对数据库所作的操作更改,将持久地保存在数据库之中。
事务的实现原理
本地事务
传统的单服务器,单关系型数据库下的事务,就是本地事务。本地事务由资源管理器管理,JDBC事务就是一个非常典型的本地事务。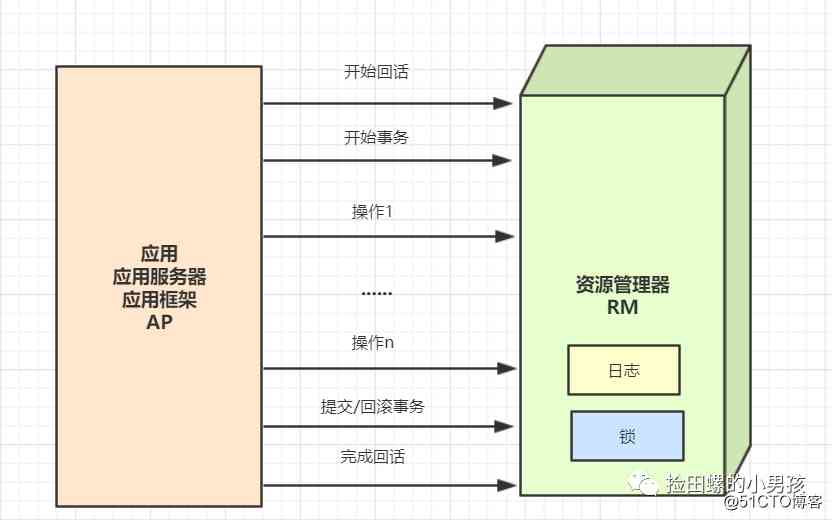
事务日志
innodb事务日志包括redo log和undo log。
redo log(重做日志)
redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样,它用来恢复提交后的物理数据页。
undo log(回滚日志)
undo log是逻辑日志,和redo log记录物理日志的不一样。可以这样认为,当delete一条记录时,undo log中会记录一条对应的insert记录,当update一条记录时,它记录一条对应相反的update记录。
事务ACID特性的实现思想
- 原子性:是使用 undo log来实现的,如果事务执行过程中出错或者用户执行了rollback,系统通过undo log日志返回事务开始的状态。
- 持久性:使用 redo log来实现,只要redo log日志持久化了,当系统崩溃,即可通过redo log把数据恢复。
- 隔离性:通过锁以及MVCC,使事务相互隔离开。
- 一致性:通过回滚、恢复,以及并发情况下的隔离性,从而实现一致性。
分布式事务
分布式事务: 就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单来说,分布式事务指的就是分布式系统中的事务,它的存在就是为了保证不同数据库节点的数据一致性。
为什么需要分布式事务?接下来分两方面阐述:
微服务架构下的分布式事务
随着互联网的快速发展,轻盈且功能划分明确的微服务,登上了历史舞台。比如,一个用户下订单,购买直播礼物的服务,被拆分成三个service,分别是金币服务(coinService),下订单服务(orderService)、礼物服务(giftService)。这些服务都部署在不同的机器上(节点),对应的数据库(金币数据库、订单数据库、礼物数据库)也在不同节点上。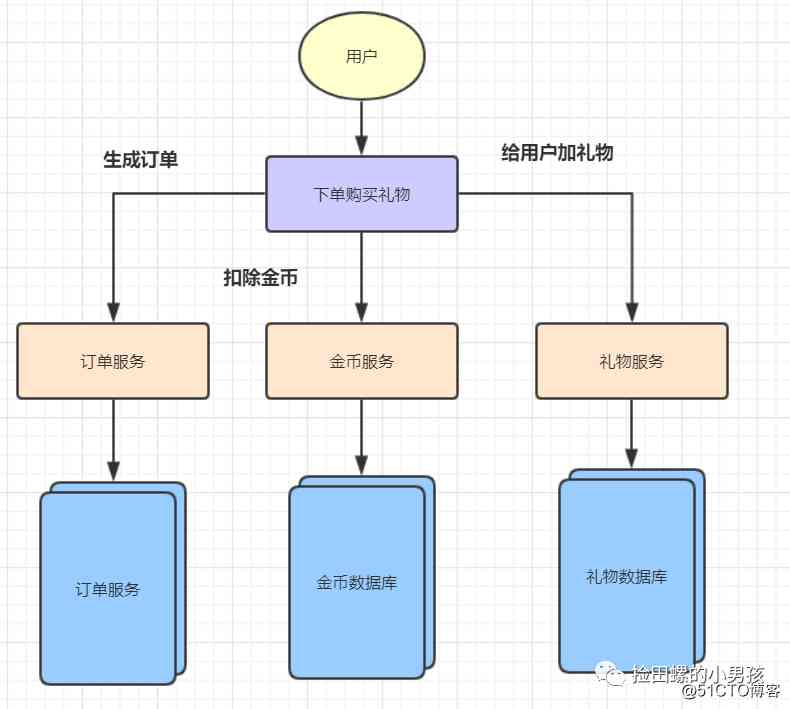
用户下单购买礼物,礼物数据库、金币数据库、订单数据库在不同节点上,用本地事务是不可以的,那么如何保证不同数据库(节点)上的数据一致性呢?这就需要分布式事务啦~
分库分表下的分布式事务
随着业务的发展,数据库的数据日益庞大,超过千万级别的数据,我们就需要对它分库分表(以前公司是用mycat分库分表,后来用sharding-jdbc)。一分库,数据又分布在不同节点上啦,比如有的在深圳机房,有的在北京机房~你再想用本地事务去保证,已经无动于衷啦~还是需要分布式事务啦。
比如A转10块给B,A的账户数据是在北京机房,B的账户数据是在深圳机房。流程如下: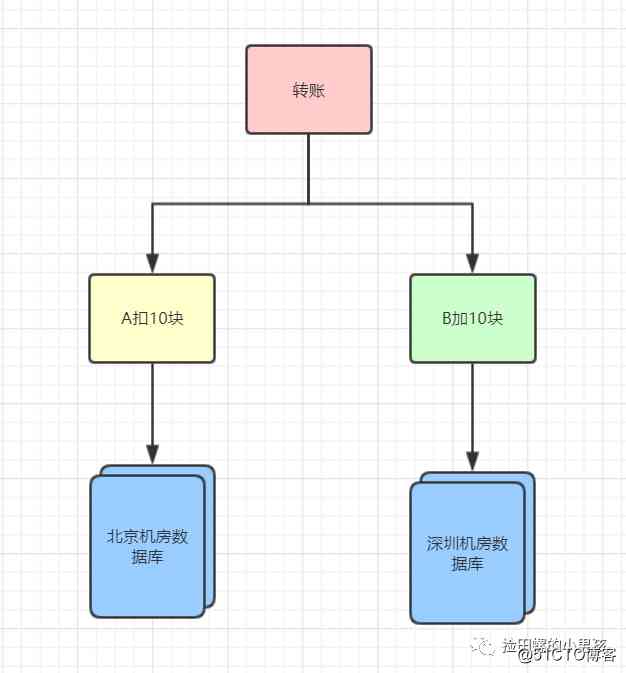
CAP 理论&BASE 理论
学习分布式事务,当然需要了解 CAP 理论和BASE 理论。
CAP理论
CAP理论作为分布式系统的基础理论,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),这三个要素最多只能同时实现两点。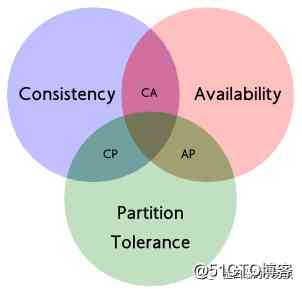
一致性(C:Consistency):
一致性是指数据在多个副本之间能否保持一致的特性。例如一个数据在某个分区节点更新之后,在其他分区节点读出来的数据也是更新之后的数据。
可用性(A:Availability):
可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。这里的重点是"有限时间内"和"返回结果"。
分区容错性(P:Partition tolerance):
分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务。
选择 说明
CA 放弃分区容错性,加强一致性和可用性,其实就是传统的单机数据库的选择
AP 放弃一致性,分区容错性和可用性,这是很多分布式系统设计时的选择
CP 放弃可用性,追求一致性和分区容错性,网络问题会直接让整个系统不可用
BASE 理论
BASE 理论, 是对CAP中AP的一个扩展,对于我们的业务系统,我们考虑牺牲一致性来换取系统的可用性和分区容错性。BASE是Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写。
Basically Available
基本可用:通过支持局部故障而不是系统全局故障来实现的。如将用户分区在 5 个数据库服务器上,一个用户数据库的故障只影响这台特定主机那 20% 的用户,其他用户不受影响。
Soft State
软状态,状态可以有一段时间不同步
Eventually Consistent
最终一致,最终数据是一致的就可以了,而不是时时保持强一致。
分布式事务的几种解决方案
分布式事务解决方案主要有以下这几种:
- 2PC(二阶段提交)方案
- TCC(Try、Confirm、Cancel)
- 本地消息表
- 最大努力通知
- Saga事务
二阶段提交方案
二阶段提交方案是常用的分布式事务解决方案。事务的提交分为两个阶段:准备阶段和提交执行方案。
二阶段提交成功的情况
准备阶段,事务管理器向每个资源管理器发送准备消息,如果资源管理器的本地事务操作执行成功,则返回成功。
提交执行阶段,如果事务管理器收到了所有资源管理器回复的成功消息,则向每个资源管理器发送提交消息,RM 根据 TM 的指令执行提交。如图: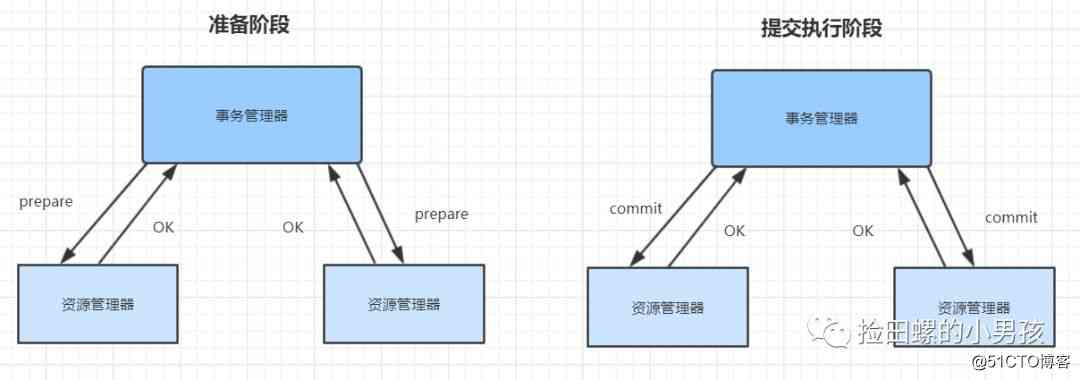
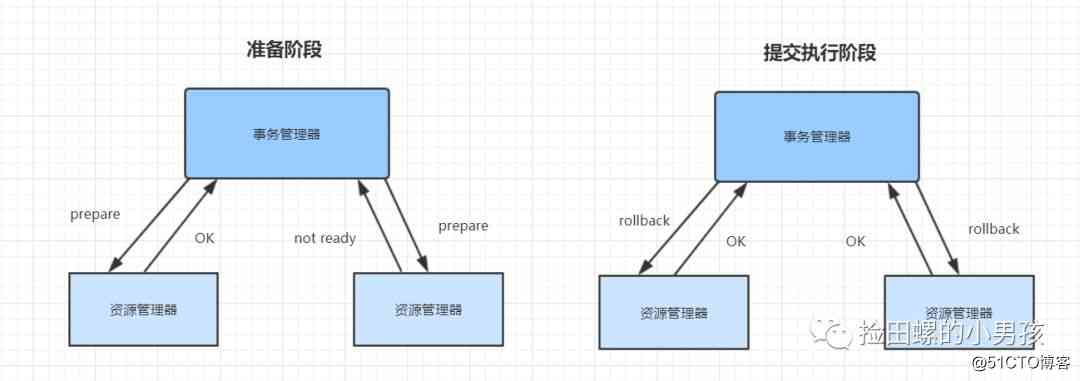
二阶段提交失败的情况
准备阶段,事务管理器向每个资源管理器发送准备消息,如果资源管理器的本地事务操作执行成功,则返回成功,如果执行失败,则返回失败。
提交执行阶段,如果事务管理器收到了任何一个资源管理器失败的消息,则向每个资源管理器发送回滚消息。资源管理器根据事务管理器的指令回滚本地事务操作,释放所有事务处理过程中使用的锁资源。
二阶段提交优缺点
2PC方案实现起来简单,成本较低,但是主要有以下缺点:
- 单点问题:如果事务管理器出现故障,资源管理器将一直处于锁定状态。
- 性能问题:所有资源管理器在事务提交阶段处于同步阻塞状态,占用系统资源,一直到提交完成,才释放资源,容易导致性能瓶颈。
- 数据一致性问题:如果有的资源管理器收到提交的消息,有的没收到,那么会导致数据不一致问题。
TCC(补偿机制)
TCC 采用了补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。
TCC(Try-Confirm-Cancel)模型
TCC(Try-Confirm-Cancel)是通过对业务逻辑的分解来实现分布式事务。针对一个具体的业务服务,TCC 分布式事务模型需要业务系统都实现一下三段逻辑:
try阶段:尝试去执行,完成所有业务的一致性检查,预留必须的业务资源。
Confirm阶段:该阶段对业务进行确认提交,不做任何检查,因为try阶段已经检查过了,默认Confirm阶段是不会出错的。
Cancel 阶段:若业务执行失败,则进入该阶段,它会释放try阶段占用的所有业务资源,并回滚Confirm阶段执行的所有操作。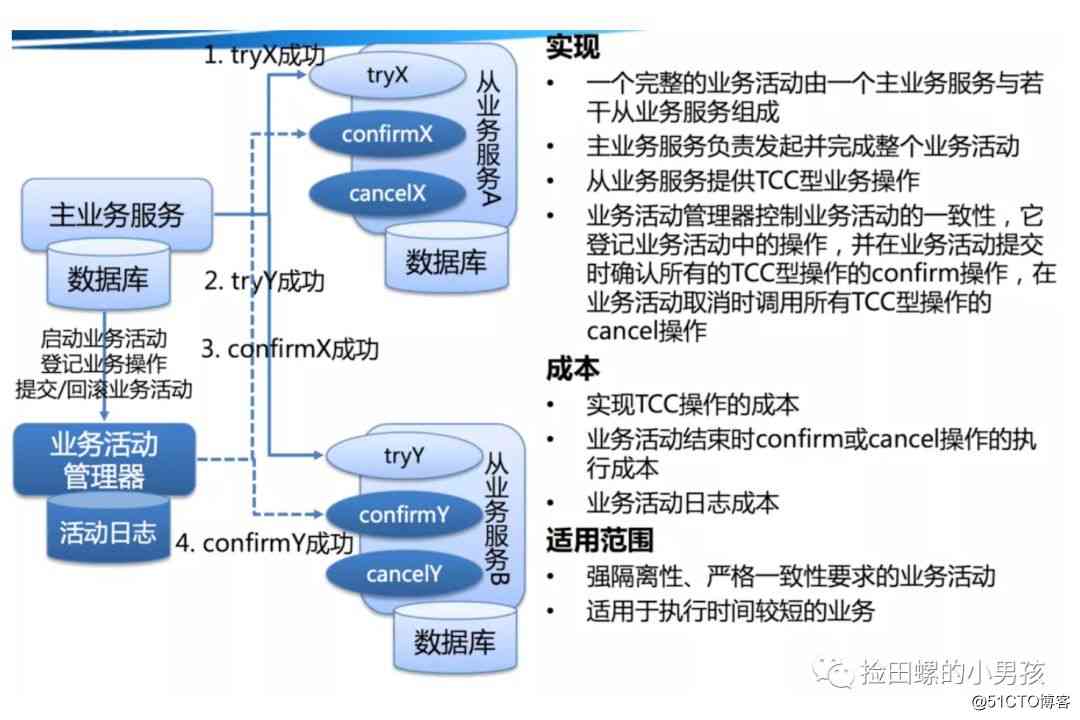
TCC 分布式事务模型包括三部分:主业务服务、从业务服务、业务活动管理器。
- 主业务服务:主业务服务负责发起并完成整个业务活动。
- 从业务服务:从业务服务是整个业务活动的参与方,实现Try、Confirm、Cancel操作,供主业务服务调用。
- 业务活动管理器:业务活动管理器管理控制整个业务活动,包括记录事务状态,调用从业务服务的 Confirm 操作,调用从业务服务的 Cancel 操作等。
下面再拿用户下单购买礼物作为例子来模拟TCC实现分布式事务的过程:
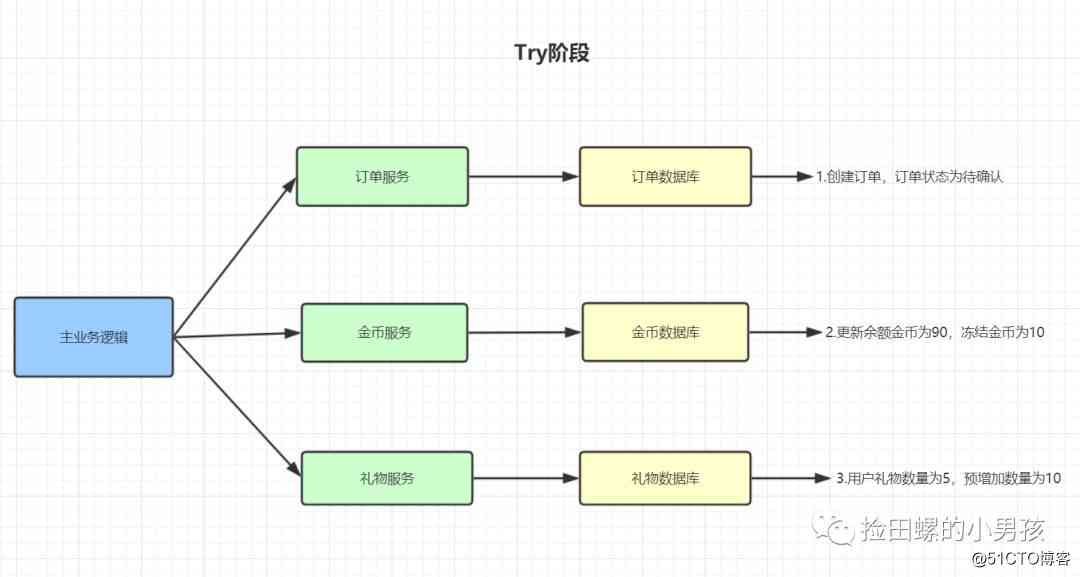
假设用户A余额为100金币,拥有的礼物为5朵。A花了10个金币,下订单,购买10朵玫瑰。余额、订单、礼物都在不同数据库。
TCC的Try阶段:
- 生成一条订单记录,订单状态为待确认。
- 将用户A的账户金币中余额更新为90,冻结金币为10(预留业务资源)
- 将用户的礼物数量为5,预增加数量为10。
- Try成功之后,便进入Confirm阶段
- Try过程发生任何异常,均进入Cancel阶段
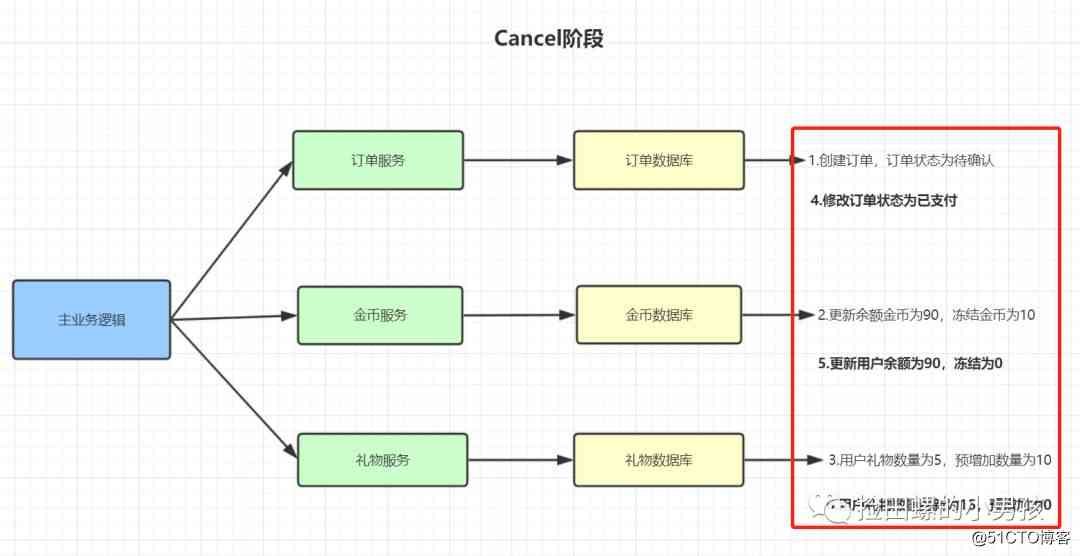
TCC的Confirm阶段:
- 订单状态更新为已支付
- 更新用户余额为90,可冻结为0
- 用户礼物数量更新为15,预增加为0
- Confirm过程发生任何异常,均进入Cancel阶段
- Confirm过程执行成功,则该事务结束
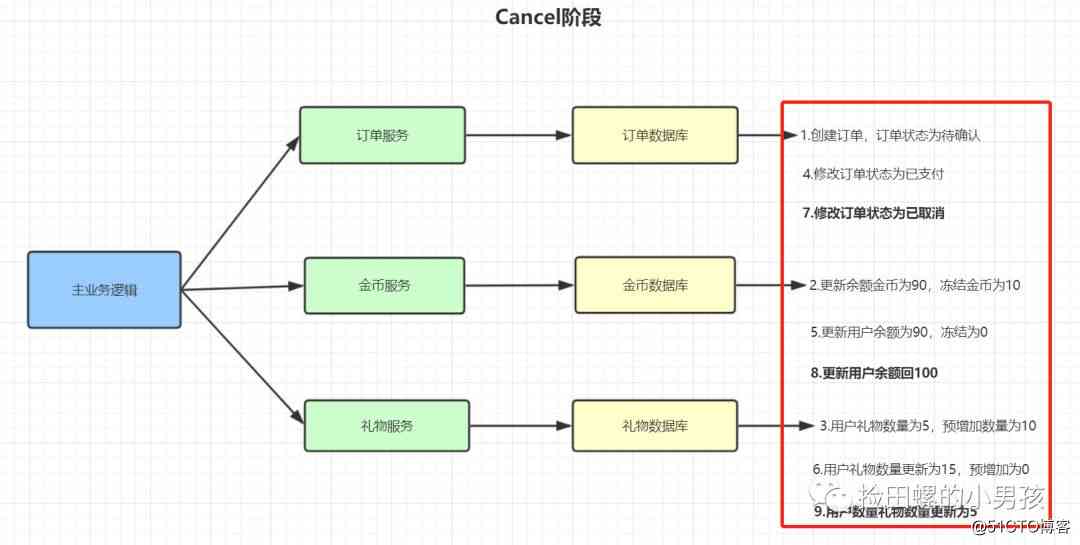
TCC的Cancel阶段:
- 修改订单状态为已取消
- 更新用户余额回100
- 更新用户礼物数量为5
TCC优缺点
TCC方案让应用可以自定义数据库操作的粒度,降低了锁冲突,可以提升性能,但是也有以下缺点:
- 应用侵入性强,try、confirm、cancel三个阶段都需要业务逻辑实现。
- 需要根据网络、系统故障等不同失败原因实现不同的回滚策略,实现难度大,一般借助TCC开源框架,ByteTCC,TCC-transaction,Himly。
本地消息表
ebay最初提出本地消息表这个方案,来解决分布式事务问题。业界目前使用这种方案是比较多的,它的核心思想就是将分布式事务拆分成本地事务进行处理。可以看一下基本的实现流程图: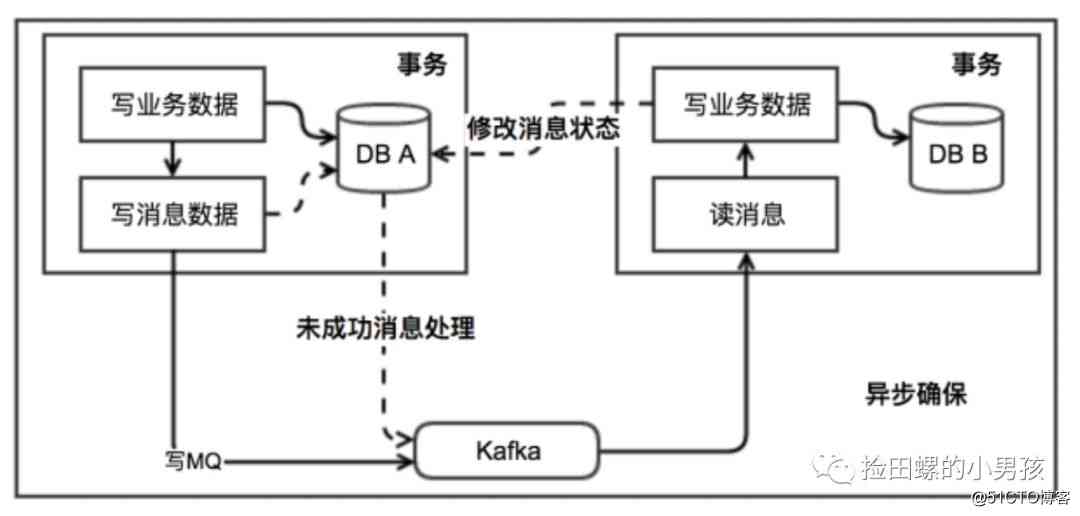
基本实现思路
发送消息方:
- 需要有一个消息表,记录着消息状态相关信息。
- 业务数据和消息表在同一个数据库,即要保证它俩在同一个本地事务。
- 在本地事务中处理完业务数据和写消息表操作后,通过写消息到MQ消息队列。
-
消息会发到消息消费方,如果发送失败,即进行重试。
消息消费方:
- 处理消息队列中的消息,完成自己的业务逻辑。
- 此时如果本地事务处理成功,则表明已经处理成功了。
- 如果本地事务处理失败,那么就会重试执行。
- 如果是业务上面的失败,给消息生产方发送一个业务补偿消息,通知进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
优点&缺点:
该方案的优点是很好地解决了分布式事务问题,实现了最终一致性。缺点是消息表会耦合到业务系统中。
最大努力通知
什么是最大通知
最大努力通知也是一种分布式事务解决方案。下面是企业网银转账一个例子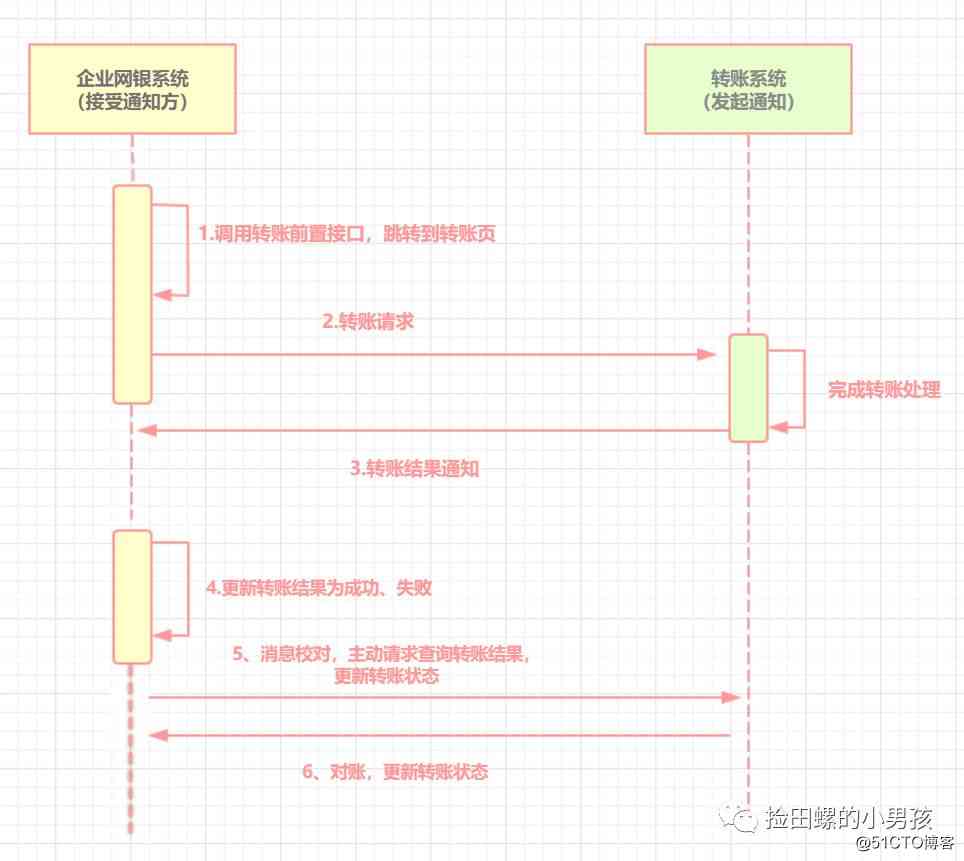
- 企业网银系统调用前置接口,跳转到转账页
- 企业网银调用转账系统接口
- 转账系统完成转账处理,向企业网银系统发起转账结果通知,若通知失败,则转账系统按策略进行重复通知。
- 企业网银系统未接收到通知,会主动调用转账系统的接口查询转账结果。
- 转账系统会遇到退汇等情况,会定时回来对账。
最大努力通知方案的目标,就是发起通知方通过一定的机制,最大努力将业务处理结果通知到接收方。最大努力通知实现机制如下: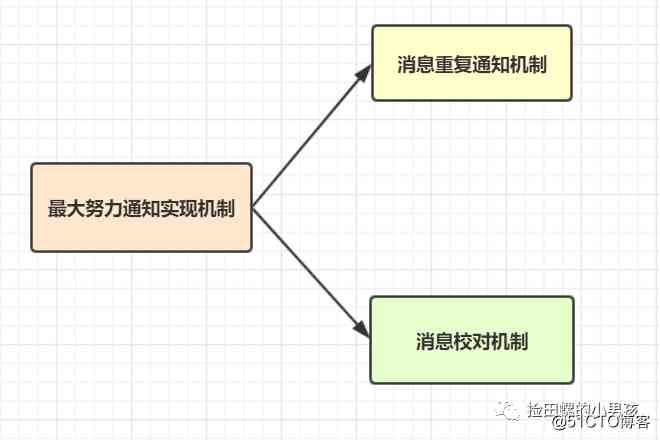
最大努力通知解决方案
要实现最大努力通知,可以采用MQ的ack机制。
方案
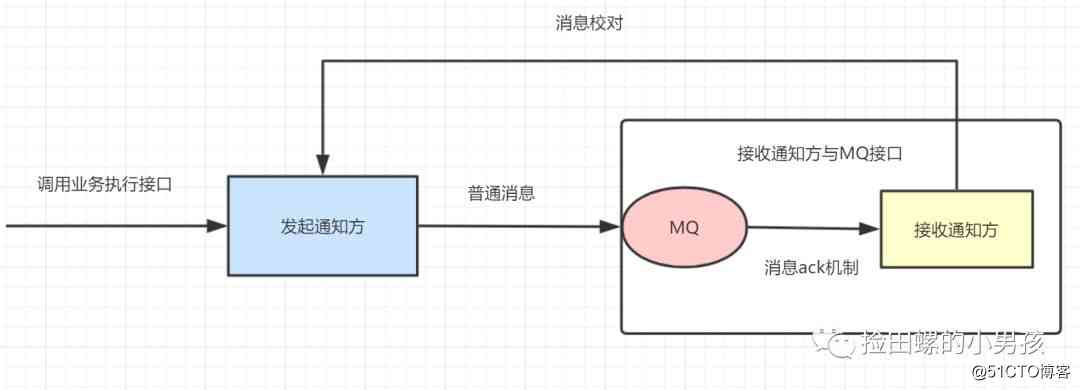
- 1.发起方将通知发给MQ。
- 2.接收通知方监听MQ消息。
- 3.接收通知方收到消息后,处理完业务,回应ack。
- 4.接收通知方若没有回应ack,则MQ会间隔1min、5min、10min等重复通知。
-
5.接受通知方可用消息校对接口,保证消息的一致性。
转账业务实现流程图: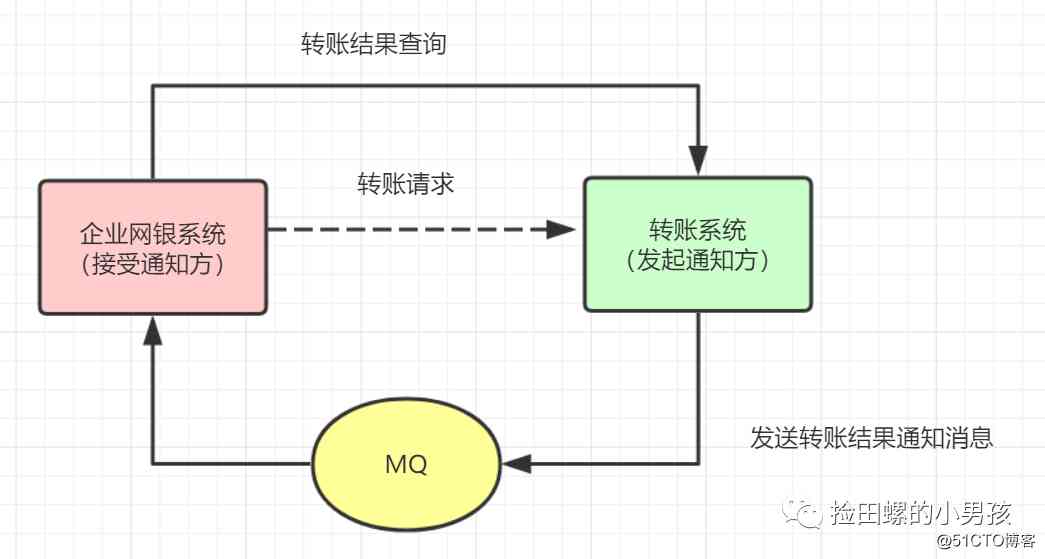
交互流程如下: - 1、用户请求转账系统进行转账。
- 2、转账系统完成转账,将转账结果发给MQ。
- 3、企业网银系统监听MQ,接收转账结果通知,如果接收不到消息,MQ会重复发送通知。接收到转账结果,更新转账状态。
- 4、企业网银系统也可以主动查询转账系统的转账结果查询接口,更新转账状态。
Saga事务
Saga事务由普林斯顿大学的Hector Garcia-Molina和Kenneth Salem提出,其核心思想是将长事务拆分为多个本地短事务,由Saga事务协调器协调,如果正常结束那就正常完成,如果某个步骤失败,则根据相反顺序一次调用补偿操作。
saga简介
- Saga = Long Live Transaction (LLT,长活事务)
- LLT = T1 + T2 + T3 + ... + Ti(Ti为本地短事务)
-
每个本地事务Ti 有对应的补偿 Ci
Saga的执行顺序
- 正常情况:T1 T2 T3 ... Tn
-
异常情况:T1 T2 T3 C3 C2 C1
Saga两种恢复策略
- 向后恢复,如果任意本地子事务失败,补偿已完成的事务。如异常情况的执行顺序T1 T2 Ti Ci C2 C1.
- 向前恢复,即重试失败的事务,假设最后每个子事务都会成功。执行顺序:T1, T2, ..., Tj(失败), Tj(重试),..., Tn。
举个例子,假设用户下订单,花10块钱购买了10多玫瑰,则有
T1=下订单 ,T2=扣用户10块钱,T3=用户加10朵玫瑰, T4=库存减10朵玫瑰
C1=取消订单 ,C2= 给用户加10块钱,C3 =用户减10朵玫瑰, C4=库存加10朵玫瑰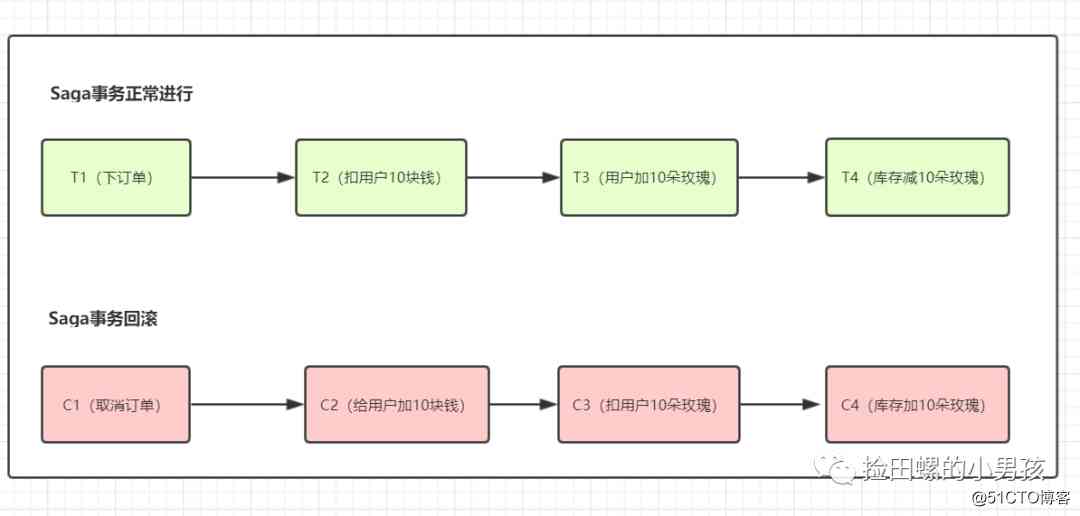
假设事务执行到T4发生异常回滚,在C4的要把玫瑰给库存加回去的时候,发现用户的玫瑰都用掉了,这是Saga的一个缺点,由于事务之间没有隔离性导致的问题。
可以通过以下方案解决这个问题:
- 在应⽤层⾯加⼊逻辑锁的逻辑。
- Session层⾯隔离来保证串⾏化操作。
- 业务层⾯采⽤预先冻结资⾦的⽅式隔离此部分资⾦。
- 业务操作过程中通过及时读取当前状态的⽅式获取更新。
参考与感谢
- 干货 | 一篇文章带你学习分布式事务
- 再有人问你分布式事务,把这篇扔给他
- 聊聊分布式事务,再说说解决方案
- Mysql事务实现原理
- 详细分析MySQL事务日志(redo log和undo log)
- 《Saga分布式事务解决⽅案与实践》
- 分布式事务解决方案之最大努力通知
个人公众号

- 觉得写得好的小伙伴给个点赞+关注啦,谢谢~
- 同时非常期待小伙伴们能够关注我公众号,后面慢慢推出更好的干货~嘻嘻
版权声明
本文为[osc_lg0msmnd]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4267086/blog/4708082
边栏推荐
- Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
- Tidb performance competition 11.02-11.06
- 个人目前技术栈
- 入门级!教你小程序开发不求人(附网盘链接)
- Istio流量管理--Ingress Gateway
- laravel8更新之速率限制改进
- 用科技赋能教育创新与重构 华为将教育信息化落到实处
- Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
- AQS analysis
- Hematemesis! Alibaba Android Development Manual! (Internet disk link attached)
猜你喜欢

This paper analyzes the top ten Internet of things applications in 2020!

Second assignment
PMP心得分享
为什么 Schnorr 签名被誉为比特币 Segwit 后的最大技术更新
供货紧张!苹果被曝 iPhone 12 电源芯片产能不足
阿里出品!视觉计算开发者系列手册(附网盘链接)
2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
![[computer network] learning notes, Part 3: data link layer (Xie Xiren version)](/img/b0/b236a52e38f1cd3eff25a398dac7aa.jpg)
[computer network] learning notes, Part 3: data link layer (Xie Xiren version)
Introduction to mongodb foundation of distributed document storage database
211考研失败后,熬夜了两个月拿下字节offer!【面经分享】
随机推荐
When kubernetes encounters confidential computing, see how Alibaba protects the data in the container! (Internet disk link attached)
Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
2 days, using 4 hours after work to develop a test tool
Web novice problem of attacking and defending the world
Introduction to mongodb foundation of distributed document storage database
Rust: performance test criteria Library
临近双11,恶补了两个月成功拿下大厂offer,跳槽到阿里巴巴
Harbor项目高手问答及赠书活动
OR Talk NO.19 | Facebook田渊栋博士:基于蒙特卡洛树搜索的隐动作集黑盒优化 - 知乎
Written interview topic: looking for the lost pig
A scheme to improve the memory utilization of flutter
This paper analyzes the top ten Internet of things applications in 2020!
供货紧张!苹果被曝 iPhone 12 电源芯片产能不足
Entry level! Teach you how to develop small programs without asking for help (with internet disk link)
Enabling education innovation and reconstruction with science and technology Huawei implements education informatization
python基础教程python opencv pytesseract 验证码识别的实现
Ubuntu20.04下访问FTP服务器乱码问题+上传文件
最全!阿里巴巴经济体云原生实践!(附网盘链接)
C语言I博客作业03
2天,利用下班后的4小时开发一个测试工具