当前位置:网站首页>MySQL - index explanation
MySQL - index explanation
2022-08-02 07:53:00 【kk_lina】
目录
一、索引优缺点
- 优点:降低数据库的IO成本;The only index can ensure each line database data唯一性;Between the accelerometer and table连接;Using the grouping and sorting is queried can reduce the query of grouping and sorting时间.
- 缺点:创建和维护The index takes time;索引占用磁盘空间;Although increased query speed,但是会降低更新表的速度,比如删除字段.
二、设计索引
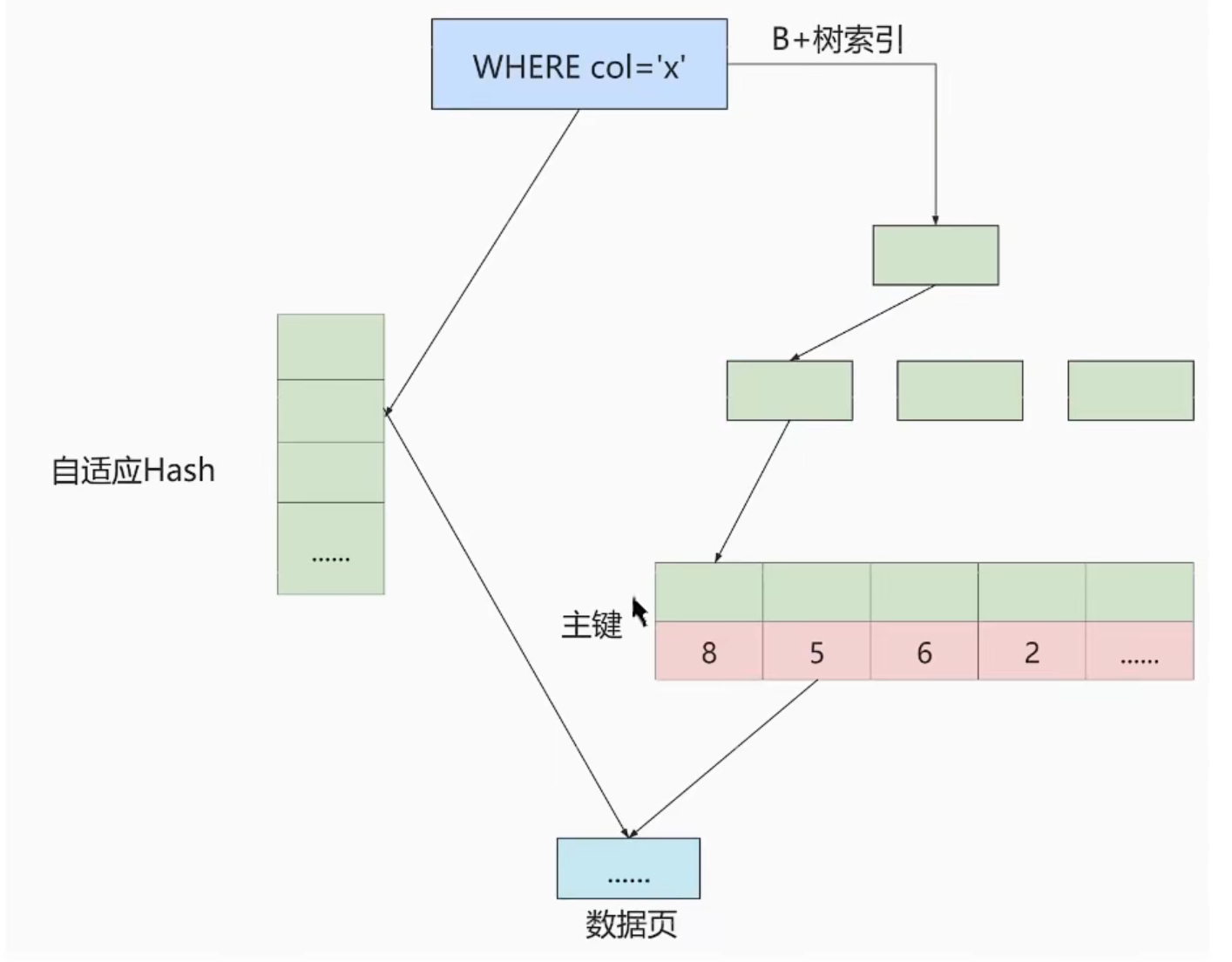
2.1、索引底层结构
Simplify the row format diagram:

- record_type:记录头信息的一项属性,表示记录的类型,2表示最小记录、3表示最大记录、1Said directory page.
- next_record:记录头信息的一项属性,表示下一条地址相对于本条记录的地址偏移量.
Data page of the diagram:

磁盘与内存交互的基本单位.
- 溢出列:Due to the size of each page is16kb,When a field is stored value is greater than that,Part of the bank records will record the data,This part is called overflow page,Then put the other data stored in other pages,At generating a bank20Byte address pointing to the other data page,The column is called overflow column.
- 页分裂:When the current page is full,Redistribute the next page,Or as a primary key for increasing,Add a primary key intermediate value,Move through the records to ensure that the next data page user record in the primary key value must be greater than the previous.
- 目录项:Due to the increasing primary key,So pages divided condition by an increase in data,From page to page through the two-way chain table form link,But to find the specific data is still not sure when the data items in which data page,So you need to set all of the data page directory entry,Record data pages minimum value and the corresponding data page address.

- 目录项记录的页:When to delete and insert data page,Corresponding entries need to delete,In addition to the back of the directory entry need forward,成本高,At this time can put the directory entry page constitute a directory entry record again.

- 更高级的目录:Due to the increase in data,Page directory entry record reaches a certain storage size will generate a new directory entry record page,Search data may appear at this time3次的IO,When multiple entries can be recorded page again to generate a more advanced directory.

- 该模型为B+树,一般情况下不会超过4层,层数越小IO次数越小.In the actual development data page storage16kb大小的数据,Layers increase the stack in the form of index,所以4Data storage layer is large enough.

2、索引的设计原则
适合创建索引:
- 字段的数值有唯一性的限制,Even if the field is the only index combined fields must also be completed
- 频繁的作为where查询条件的字段
- 经常group by、order by的列,Because the index data in a data pages are stored in sequence connected
- update、delete的where条件列
- distinct字段需要创建索引
- 对于join连接的whereConditions and connection field create indexes,joinConnection of the table as far as possible not more than3张表,Connection of the field type must agree,Otherwise it will involve function transformation lead to index the failure
- 使用列的类型小的创建索引
- 使用字符串前缀创建索引,When the node is small footprint
- 区分度高(散列性高)的列适合作为索引,重复性强,计算区分度:select count(distinct a)/count(*) from t1
- 使用最频繁的列放到联合索引的左侧,The increased use of combined index number
- Under the condition of multiple fields need to create an index,Joint index is better than that of single index
不适合创建索引:
- where中使用不到的字段
- 数据量小的表最好不使用索引
- 有大量重复数据的列
- 避免对经常更新的表创建过多的索引
- Not recommended disorderly的值作为索引
- Delete no longer use or use index
- Do not define redundant or duplicate index,例如:Combined index of the first field defined as an ordinary index
限制索引数目:
- Each index all need disk space;
- Optimizer execution when the index is best,Index too much will affect the optimizer generated execution plan
- 索引会影响insert、update、delete等语句的性能,The data in the table when making changes,The index will adjust data and updates,会造成负担
三、索引分类
MySQL的索引包括普通索引、唯一性索引、全文索引、单列索引、多列索引和空间索引等.
- 从功能逻辑上分:普通索引、唯一索引、主键索引、全文索引
- From a physical implementation points:聚簇索引、非聚簇索引
- From function field points:单列索引、联合索引
3.1、普通索引
不附加任何条件,可以创建在任何数据类型中,There is no requirement for empty and the only.
3.2、唯一性索引
That statementUNIQUEParameter will automatically generate a unique index.
3.3、主键索引
Primary key constraints to automatically generate the primary key index,也是聚簇索引,只能有一个,Determine the underlying physical implementation way.
3.4、单列索引
Create index on the individual fields in the table,Can be the only index、全文索引,只要保证该索引只对应一个字段即可.
3.5、多列(组合、联合)索引
The size of the column using multiple as ordering rules,比如为c1,c2创建一个联合索引,Page will put individual records and in accordance with thec1进行排序,在c1相同的情况下按照c2进行排序

Leaf nodes by combining field data of the index and primary key field data,Also has the back to the table.使用时遵循最左前缀原则.
3.6、全文索引
Search engine use key technology,Can analyze the frequency and importance of text text keywords and search results according to the algorithm selected want.FULLTEXTYou can set the full-text index,只能创建在CHAR、VARCHAR或TEXT字段上,Query data volume larger string type field can use full-text index
3.7、聚簇索引
Composed of the primary key index,一种数据存储方式,All user records are stored in the leaf node,索引即数据,数据即索引.The above example is the clustering index structure.
- B+树的叶子节点存储的是完整的用户记录.
- Using the size of the primary key for record and page sorting
- From page to page is formed between the two-way chain table
- 即使自己不创建,innodb也会自动创建
优点:
- 数据访问快,索引和数据保存在同一个B+树中,To get the data than the clustering index
- Sorting and scope search fast
- 节省大量IO操作
缺点
- 插入速度依赖于插入顺序
- Update the primary key high price
- 二级索引访问需要两次索引查找,For the first time to find the primary key,The second find rows of data
补充
- MyISAM不支持聚簇索引
- There can be data physical sorting a way,所以每个MySQL只能有一个聚簇索引,Under normal circumstances is the table's primary key
- 如果没有定义主键,innodbThe only index will automatically choose a non empty instead of,如果没有该索引,会隐式定义一个主键来作为聚簇索引
- In order to make full use of the cluster index characteristics,InnodbTable primary key columns as far as possible choose orderly sequenceid,Not recommended disorderly、加密、Listed as the primary keys, such as string
3.8、二级索引(辅助索引、非聚簇索引)
A table can have only one cluster index but there can be multiple secondary indexes,Insert the secondary index、删除、Update operation than the cluster index of high efficiency
- Secondary index leaf nodes only store the index value and the value of the primary key field under,Do not recommend storing other fields,In the case of multiple secondary indexes can be set,Too much storage field to waste of space,会降低性能
- A secondary index in addition to the field to find data quickly,A more important role is to help the other fields corresponds to the primary key and then through the back table data to find
- 回表:If the other lookup fields at this time,You need to through the secondary indexes corresponding to find the primary key,To travel through the clustering index for the primary key of other field values

四、InnoDB的B+树索引注意事项
4.1、根页面位置万年不动
For a table to create aB+树索引时,Will create a root for the index page,No entries at this time,The root node and no user record.When inserting a data to the root node to add,When the root node reaches a maximum storage,To the root node data is copied to a new page,On this page for page divided,得到新的页,Insert the data key value will be stored in the page,At this time the root node upgrade to storage directory entry record page.
4.2、内节点中目录项记录的唯一性
Mainly for secondary indexes,Directory entry record store the index of field plus a primary key and page number,There is no primary key index field may exist the same numerical case,Can't query down,After joining the primary key in the index phase field at the same time,Be able to query the primary key,According to the main key to continue down the query.
4.3、一个页面最少存储2条记录
五、MyISAM索引原理
在innodb中索引即数据,MyISAM中索引和数据是分开存储的,InnodbStorage of data in the page are the primary key+数据,MyISAMAs the number of data records in the address.

5.1、myisam与Innodb的区别:
- InnodbIn a clustering index lookup can get data,myisamNeed to carry on the back to the table,可以认为myisamIn the index are all secondary indexes.
- innodb中索引即数据,myisamThe index and data points stored in different files,.myd和.myi
- innodbPage data store of the primary key,myisam存储的是地址
- myisam回表操作十分快速,Taken directly address for back to the table,innodbWith a primary key is back to the table
- innodb必须有主键,Will not take a non-empty unique value as the primary key,Even if no will automatically generate an implicit primary key,myisam可以没有
5.2、总结
- 不建议使用过长字段作为主键,Because all secondary indexes references the primary key,The primary key for too long can lead to secondary indexes too
- 使用自增字段作为主键,维护方便
六、其他数据结构
6.1、全表遍历
6.2、Hash结构
- HashAlgorithm can guarantee the same input can always get the same output.
- Accelerate the search data data structure,常见的有两类:
树,例如平衡二叉搜索树,查询、插入、修改、删除的平均时间复杂度都是O(log2N);
哈希,例如HashMap,查询、插入、修改、The average time complexity of the three places areO(1)

- 从效率上来说Hash比B+树快,但是HashRange find need to calculate,适用于等值查找;数据存储是无序的,Sorting can't useHash特征;联合索引时HashIs to merge together to calculate,Unable to query a single or a few index;For the duplicate values more column,Would reduce efficiency to traverse the list;innodbDoes not support this index but support adaptiveHash索引、myisamDoes not support the structure,Memory支持;适用于Redis.
6.3、二叉搜索树
特点:
- 一个节点只能有两个子节点
- 左子节点<本节点;右子节点>=本节点,比我大的向右,比我小的向左
查找规则:
- 大于根节点,在右子树中查找
- 小于根节点,在左子树中查找
- 等于根节点,返回根节点
6.4、AVL平衡二叉搜索树
In an ordered data using a binary search tree will form a list,查找数据的时间复杂度变成了O(n).The need to balance binary search tree.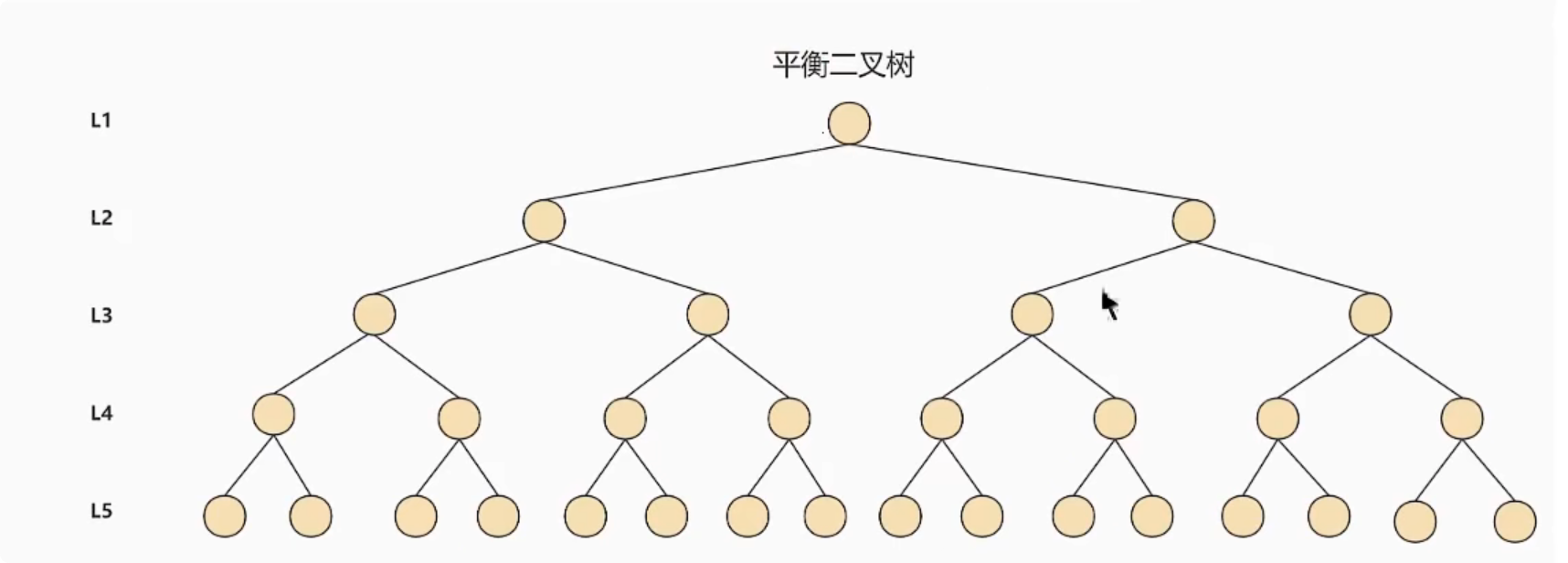
Common balanced binary tree:红黑树、数堆、伸展树、平衡二叉搜索树.
6.5、B-Tree多路平衡查找树

p1、p2、p3为指针,Data is less than this range is gop1,Data in this range, walkp2,Data is greater than the scope of the walkp3.
B树和B+树的差异:
- B+树有k个关键字就有k个节点,B-Tree有kA keyword isk+1个节点;
- B+Central African tree leaf nodes of the keyword may also exist in leaf node,And all the keywords in the child nodes of the biggest(或最小);
- B+树中非叶子节点仅用于索引,不保存数据记录,The relevant data records are stored in a leaf node in the.B-TreeThe china-africa leaf node also store indexes and the specific data;
- All the key words according to the key words in the leaf node size orderly connection;
- B+树查询效率更稳定,BTree search data may be on the leaf nodes may also be at the leaf node;
- 范围查询时,B+树更快,Not a leaf node list form more convenient,BTrees need back tree search.





七、区、段、碎片区
7.1、区
Each page distance may be far away,XunDao long time,出现随机IO,速度慢,建议使用顺序IO,So you need to let the pages stored in order.A zone is continuous64个页,一个区为1M大小,Area and the area between may not be continuous.
7.2、段
To store a leaf node and the leaf node,Classified into a period of,常见的段有数据段、索引段、回滚段.是一个逻辑上的概念,Is not a continuous physical area,Is a scattered page.
7.3、Scattered area
When a leaf node is an area、Not a leaf node to become a district,此时会出现2m大小的区,When data amount not so big,会造成空间浪费,Hence fragments area,Pieces of the page can be used for different scenarios,Good use of the remaining space
For a certain period of allocation of storage space strategy:
- Just began to like insert data in the table,段是从某个碎片区以单个页面为单位来分配存储空间的
- When a section is using32个碎片区页面之后,就会申请以完整的区为单位来分配存储空间
7.4、区的分类
- 空闲的区:现在还没有用到这个区的任何页面
- 有剩余空间的碎片区:表示碎片区中还有可用的页面
- 没有剩余空间的碎片区:表示碎片区中的所有页面都被使用,没有空闲的页面
- Affiliated with a section of the area of:Each index can be divided into the leaf node and the leaf node
7.5、表空间
All data is stored in a table space,是Innodb存储引擎逻辑结构的最高层.
表空间是一个逻辑容器,Storage was a,A table space can store multiple period,一个段只能属于一个表空间.
分类:系统表空间、独立表空间、撤销表空间、临时表空间.
独立表空间:
Each table has a separate table space,Index and data are stored in table space,For data migration and recycling,删除表空间、Release the table space is more convenient.
mysql8中.idbFile storage size for7个页的大小,5.7为6个,8Also need to store.ifm数据,所以空间大.
边栏推荐
猜你喜欢

![带手续费买卖股票的最大利益[找DP的状态定义到底缺什么?]](/img/14/cd6ed7452230571db2e027f61dbdba.png)




随机推荐
Please tell me, how to write Flink SQL and JDBC sink into mysql library and want to create an auto-incrementing primary key
查看端口号占用
【红队】ATT&CK - 创建或修改系统进程实现持久化(更新ing)
About the SQL concat () function problem, how to splice
FormData上传二进制文件、对象、对象数组
根据一个字段的内容去更新另一个字段的数据,这样的sql语句该怎么样书写
MySQL-执行流程+缓存+存储引擎
【CV】OpenVINO安装教程
MySQL-FlinkCDC-Hudi enters the lake in real time
带手续费买卖股票的最大利益[找DP的状态定义到底缺什么?]
【网络】IP、子网掩码
spark read folder data
OC-NSDictionary
OC-NSNumber and NSValue are generally used for boxing and unboxing
LeetCode 2360. 图中的最长环
MySQL报错1055解决办法:[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains
正则表达式
OC-NSString
【故障诊断分析】基于matlab FFT轴承故障诊断(包络谱)【含Matlab源码 2002期】
反射课后习题及做题记录