当前位置:网站首页>袋鼠雲數棧基於CBO在Spark SQL優化上的探索
袋鼠雲數棧基於CBO在Spark SQL優化上的探索
2022-06-11 05:23:00 【數棧研習社】

導讀:
Spark SQL有RBO和CBO兩種優化方式,數棧為什麼選擇CBO作為優化方式?又是在數棧中怎麼落地的?未來優化方式選擇是什麼,本期內容帶你了解數棧在Spark SQL優化方式上的探索。
你能看到
Spark SQL CBO選型背景
Spark SQL CBO實現原理
數棧在Spark SQL CBO上的探索
作者 / 修竹
編輯 / 花夏

Spark SQL CBO選型背景
Spark SQL的優化器有兩種優化方式:一種是基於規則的優化方式(Rule-Based Optimizer,簡稱為RBO);另一種是基於代價的優化方式(Cost-Based Optimizer,簡稱為CBO)。
01
RBO是傳統的SQL優化技術
RBO是發展比較早且比較成熟的一項SQL優化技術,它按照制定好的一系列優化規則對SQL語法錶達式進行轉換,最終生成一個最優的執行計劃。RBO屬於一種經驗式的優化方法,嚴格按照既定的規則順序進行匹配,所以不同的SQL寫法直接决定執行效率不同。且RBO對數據不敏感,在錶大小固定的情况下,無論中間結果數據怎麼變化,只要SQL保持不變,生成的執行計劃就都是固定的。
02
CBO是RBO改進演化的優化方式
CBO是對RBO改進演化的優化方式,它能根據優化規則對關系錶達式進行轉換,生成多個執行計劃,在根據統計信息(Statistics)和代價模型(Cost Model)計算得出代價最小的物理執行計劃。
03
CBO與RBO優勢對比
● RBO優化例子
下面我們來看一個例子:計算t1錶(大小為:2G)和t2錶(大小為:1.8G)join後的行數
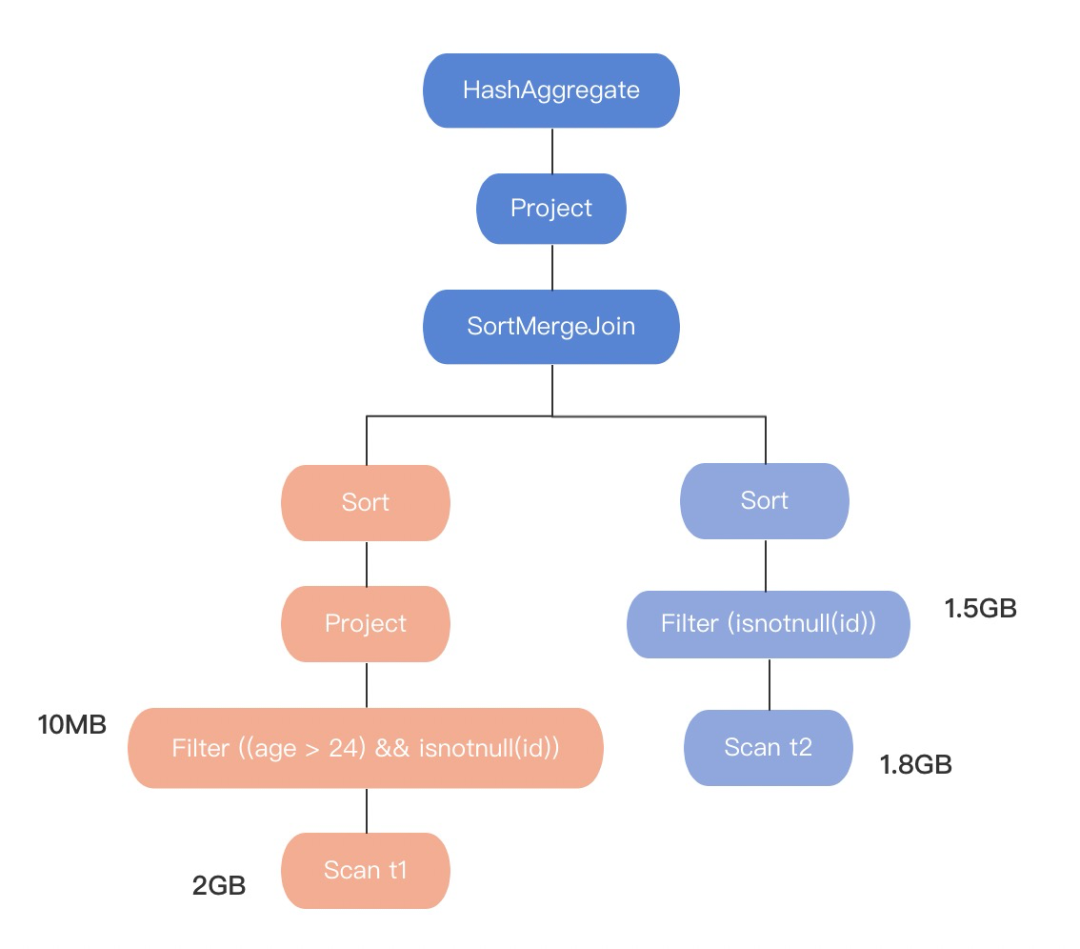
上圖是:
SELECT COUNT(t1.id) FROM t1 JOIN t2 ON t1.id = t2.id WHERE t1.age > 24
基於RBO優化後生成的物理執行計劃圖。在圖中我們可以看出,執行計劃最後是選用SortMergeJoin ⑴ 進行兩個錶join的。
在Spark中,join的實現有三種:
1.Broadcast Join
2.ShuffleHash Join
3.SortMerge Join
ShuffleHash Join和SortMerge Join都需要shuffle,相對Broadcast Join來說代價要大很多,如果選用Broadcast Join則需要滿足有一張錶的大小是小於等於
spark.sql.autoBroadcastJoinThreshold 的大小(默認為10M)。
而我們再看,上圖的執行計劃t1錶,原錶大小2G過濾後10M,t2錶原錶大小1.8G過濾後1.5G。這說明RBO優化器不關心中間數據的變化,僅根據原錶大小進行join的選擇了SortMergeJoin作為最終的join,顯然這得到的執行計劃不是最優的。
● CBO優化例子
而使用CBO優化器得到的執行計劃圖如下:

我們不難看出,CBO優化器充分考慮到中間結果,感知到中間結果的變化滿足能Broadcast Join的條件,所以生成的最終執行計劃會選擇Broadcast Join來進行兩個錶join。
● 其他優勢
其實除了刻板的執行導致不能得到最優解的問題,RBO還有學習成本高的問題:開發人員需要熟悉大部分優化規則,否則寫出來的SQL性能可能會很差。
● CBO是數棧Spark SQL 優化的更佳選擇
相對於RBO,CBO無疑是更好的選擇,它使Spark SQL的性能提昇上了一個新臺階,Spark作為數棧平臺底層非常重要的組件之一,承載著離線開發平臺上大部分任務,做好Spark的優化也將推動著數棧在使用上更加高效易用。所以數棧選擇CBO做研究探索,由此進一步提高數棧產品性能。

Spark SQL CBO實現原理
Spark SQL中實現CBO的步驟分為兩大部分,第一部分是統計信息收集,第二部分是成本估算:
統計信息收集
統計信息收集分為兩個部分:第一部分是原始錶信息統計、第二部分是中間算子的信息統計。
01
原始錶信息統計
Spark中,通過增加新的SQL語法ANALYZE TABLE來用於統計原始錶信息。原始錶統計信息分為錶級別和列級別兩大類,具體的執行如下所示:
● 錶級別統計信息
通過執行 ANALYZE TABLE table_name COMPUTE STATISTICS 語句來收集,統計指標包括estimatedSize解壓後數據的大小、rowCount數據總條數等。
● 列級別統計信息
通過執行 ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS column-name1, column-name2, …. 語句來收集。
列級別的信息又分為基本列信息和直方圖,基本列信息包括列類型、Max、Min、number of nulls, number of distinct values, max column length, average column length等,直方圖描述了數據的分布。Spark默認沒有開啟直方圖統計,需要額外設置參數:spark.sql.statistics.histogram.enabled = true。
原始錶的信息統計相對簡單,推算中間節點的統計信息相對就複雜一些,並且不同的算子會有不同的推算規則,在Spark中算子有很多,有興趣的同學可以看Spark SQL CBO設計文檔:
https://issues.apache.org/jira/secure/attachment/12823839/Spark_CBO_Design_Spec.pdf
02
中間算子的信息統計
我們這裏以常見的filter算子為例,看看推算算子統計信息的過程。基於上一節的SQL SELECT COUNT(t1.id) FROM t1 JOIN t2 ON t1.id = t2.id WHERE t1.age > 24生成的語法樹來看下t1錶中包含大於運算符 filter節點的統計信息。

在這裏需要分三種情况考慮:
第一種
過濾條件常數值大於max(t1.age),返回結果為0;
第二種
過濾條件常數值小於min(t1.age),則全部返回;
第三種
過濾條件常數介於min(t1.age)和max(t1.age)之間,當沒有開啟直方圖時過濾後統計信息的公式為after_filter = (max(t1.age) - 過濾條件常數24)/(max(t1.age) – min(t1.age)) * before_filter,沒有開啟直方圖則默認任務數據分布是均勻的;當開啟直方圖時過濾後統計信息公式為after_filter = height(>24) / height(All) * before_filter。然後將該節點min(t1.age)等於過濾條件常數24。
成本估算
介紹完如何統計原始錶的統計信息和如何計算中間算子的統計信息,有了這些信息後就可以計算每個節點的代價成本了。
在介紹如何計算節點成本之前我們先介紹一些成本參數的含義,如下:
Hr: 從 HDFS 讀取 1 個字節的成本
Hw: 從 HDFS 寫 1 個字節的成本
NEt: 在 Spark 集群中通過網絡從任何節點傳輸 1 個字節到 目標節點的平均成本
Tr: 數據總條數
Tsz: 數據平均大小
CPUc: CPU 成本
計算節點成本會從IO和CPU兩個維度考慮,每個算子成本的計算規則不一樣,我們通過join算子來舉例說明如何計算算子的成本:
假設join是Broadcast Join,大錶分布在n個節點上,那麼CPU代價和IO代價計算公式分別如下:
CPU Cost=小錶構建Hash Table的成本 + 大錶探測的成本 = Tr(Rsmall) * CPUc + (Tr(R1) + Tr(R2) + … + Tr(Rn)) * n * CPUc
IO Cost =讀取小錶的成本 + 小錶廣播的成本 + 讀取大錶的成本 = Tr(Rsmall) * Tsz(Rsmall) * Hr + n * Tr(Rsmall) * Tsz(Rsmall) * NEt + (Tr(R1)* Tsz(R1) + … + Tr(Rn) * Tsz(Rn)) * Hr
但是無論哪種算子,成本計算都和參與的數據總條數、數據平均大小等因素直接相關,這也是為什麼在這之前要先介紹如何統計原錶信息和推算中間算子的統計信息。
每個算子根據定義的規則計算出成本,每個算子成本相加便是整個執行計劃的總成本,在這裏我們可以考慮一個問題,最優執行計劃是列舉每個執行計劃一個個算出每個的總成本得出來的嗎?顯然不是的,如果每個執行計劃都計算一次總代價,那估計黃花菜都要凉了,Spark巧妙的使用了動態規劃的思想,快速得出了最優的執行計劃。

數棧在Spark SQL CBO上的探索
了解完Spark SQL CBO的實現原理之後,我們來思考一下第一個問題:大數據平臺想要實現支持Spark SQL CBO優化的話,需要做些什麼?
在前文實現原理中我們提到,Spark SQL CBO的實現分為兩步,第一步是統計信息收集,第二步是成本估算。而統計信息收集又分為兩步:第一步的原始錶信息統計、第二步中間算子的信息統計。到這裏我們找到了第一個問題的答案:平臺中需要先有原始錶信息統計的功能。
第一個問題解决後,我們需要思考第二個問題:什麼時候進行錶信息統計比較合適?針對這個問題,我們初步設想了三種解决信息統計的方案:
● 在每次SQL查詢前,先進行一次錶信息統計
這種方式得到的統計信息比較准確,經過CBO優化後得出的執行計劃也是最優的,但是信息統計的代價最大。
● 定期刷新錶統計信息
每次SQL查詢前不需要進行錶信息統計,因為業務數據更新的不確定性,所以這種方式進行SQL查詢時得到的錶統計信息可能不是最新的,那麼CBO優化後得到的執行計劃有可能不是最優的。
● 在變更數據的業務方執行信息統計
這種方式對於信息統計的代價是最小的,也能保證CBO優化得到的執行計劃是最優的,但是對於業務代碼的侵入性是最大的。
不難看出三種方案各有利弊,所以進行錶信息統計的具體方案取决於平臺本身的架構設計。
基於數棧平臺建設數倉的結構圖如下圖所示:

首先通過ChunJun將業務數據庫數據采集到Hive ODS層
然後通過Hive或者Spark進行數據處理
最後通過ChunJun將Hive庫的數據寫入到業務數據庫用於業務處理
從結構圖可看出數棧有用到Hive、Spark和ChunJun三個組件,並且這三個組件都會讀寫Hive, 數棧多個子產品(如離線平臺和實時平臺)也都有可能對Hive進行讀寫,所以如果基於方案3來做成本是非常高的。
方案1本身代價就已經較大,每次查詢前都進行一次信息統計,信息統計的時間是要算在本次查詢耗時中的,如果錶數據量比較大增加的時間可能是十幾分鐘甚至更久。
綜合考慮,我們選用了更靈活合理的方案2來進行錶信息統計。雖然Spark SQL運行時得到的統計信息可能不是最新的,但是總體相比較RBO來說還是有很大的性能提昇。
接下來就為大家分享,數棧是如何如何統計收集原錶信息統計:
我們在離線平臺項目管理頁面上添加了錶信息統計功能,保證了每個項目可以根據項目本身情况配置不同的觸發策略。觸發策略可配置按天或者按小時觸發,按天觸發支持配置到從當天的某一時刻觸發,從而避開業務高峰期。配置完畢後,到了觸發的時刻離線平臺就會自動以項目為單比特提交一個Spark任務來統計項目錶信息。
在數棧沒有實現CBO支持之前,Spark SQL的優化只能通過調整Spark本身的參數實現。這種調優方式很高的准入門檻,需要使用者比較熟悉Spark的原理。數棧CBO的引入大大降低了使用者的學習門檻,用戶只需要在Spark Conf中開啟
CBO-spark.sql.cbo.enabled=true
然後在對應項目中配置好錶信息統計就可以做到SQL優化了。

未來展望
在CBO優化方面持續投入研究後,Spark SQL CBO整體相比較RBO而言已經有了很大的性能提昇。但這並不說明整個操作系統就沒有優化的空間了,已經拿到的進步只會鼓舞我們繼續進行更深層次的探索,努力往前再邁一步。
完成對CBO的初步支持探索後,數棧把目光看向了Spark 3.0 版本引入的新特性——AQE(Adaptive Query Execution)。
AQE是動態CBO的優化方式,是在CBO基礎上對SQL優化技術又一次的性能提昇。如前文所說,CBO目前的計算對前置的原始錶信息統計是仍有依賴的,而且信息統計過時的情况會給CBO帶來不小的影響。
如果在運行時動態的優化 SQL 執行計劃,就不再需要像CBO那樣需要提前做錶信息統計。數棧正在針對這一個新特性進行,相信不久的將來我們就能引入AQE,讓數棧在易用性高性能方面更上一層樓。希望小夥伴們保持關注,數棧願和大家一起成長。
+
往期推薦

開
源
交
流
● ChunJun
https://github.com/DTStack/chunjun
https://gitee.com/dtstack_dev_0/chunjun
● Taier
https://github.com/DTStack/Taier
https://gitee.com/dtstack_dev_0/taier
● ChengYing
https://github.com/DTStack/chengying
https://gitee.com/dtstack_dev_0/chengying
● Molecule
https://github.com/DTStack/molecule
https://gitee.com/dtstack_dev_0/molecule

袋鼠雲開源技術框架交流群
釘釘群|30537511

點擊“閱讀原文”,直達開源社區!

边栏推荐
- es-ik 安装报错
- Carrier coordinate system inertial coordinate system world coordinate system
- Inventory | ICLR 2022 migration learning, visual transformer article summary
- Combien de courant le câblage des PCB peut - il supporter?
- How much current can PCB wiring carry
- Poverty has nothing to do with suffering
- Use acme SH automatically apply for a free SSL certificate
- Customize the layout of view Foundation
- wxParse解析iframe播放视频
- Zed2 camera calibration -- binocular, IMU, joint calibration
猜你喜欢

Huawei equipment is configured to access the virtual private network through GRE tunnel
Share | guide language image pre training to achieve unified visual language understanding and generation

English digital converter

Preliminary understanding of DFS and BFS

jvm调优六:GC日志分析和常量池详解

Yolov5 training personal data set summary

Top 100 video information of station B

String sorting times --- bubble sorting deformation

点击图标不灵敏咋整?

Lianrui electronics made an appointment with you with SIFA to see two network cards in the industry's leading industrial automation field first
随机推荐
Use acme SH automatically apply for a free SSL certificate
自定义View之基础篇
Dongmingzhu said that "Gree mobile phones are no worse than apple". Where is the confidence?
Share | guide language image pre training to achieve unified visual language understanding and generation
Sealem finance builds Web3 decentralized financial platform infrastructure
Some details about memory
jvm调优五:jvm调优工具和调优实战
Huawei equipment configuration MCE
Top 100 video information of station B
The central rural work conference has released important signals. Ten ways for AI technology to help agriculture can be expected in the future
点击图标不灵敏咋整?
Chapter I: Net architecture (1)
[NIPS2021]MLP-Mixer: An all-MLP Architecture for Vision
Using keras to build the basic model yingtailing flower
Restoration of binary tree -- number restoration
Combien de courant le câblage des PCB peut - il supporter?
Paper reproduction: expressive body capture
Section III: structural characteristics of cement concrete pavement
Topological sorting
How to apply for free idea with official documents