当前位置:网站首页>Nebula importer data import practice
Nebula importer data import practice
2022-07-04 19:14:00 【InfoQ】
Preface
- Need to bring from Kafka、Pulsar Streaming data of the platform , Import Nebula Graph database
- From relational database ( Such as MySQL) Or distributed file systems ( Such as HDFS) Read batch data in
- Large quantities of data need to be generated Nebula Graph Recognable SST file
- Importer Applicable to local CSV Import the contents of the file into Nebula Graph in
- In different Nebula Graph Migrate data between clusters
- In the same Nebula Graph Migrate data between different graph spaces in the cluster
- Nebula Graph Migrate data with other data sources
- combination Nebula Algorithm Do graph calculation
- In different Nebula Graph Migrate data between clusters
- In the same Nebula Graph Migrate data between different graph spaces in the cluster
- Nebula Graph Migrate data with other data sources
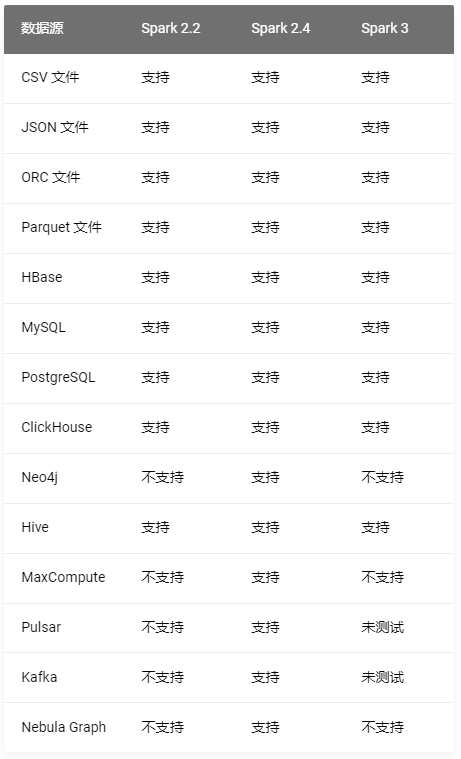
Nebula Importer Use
[[email protected] importer]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8269CY CPU @ 2.50GHz
Stepping: 7
CPU MHz: 2499.998
BogoMIPS: 4999.99
Hypervisor vendor: KVM
Virtualization type: full
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 36608K
NUMA node0 CPU(s): 0-15
Disk:SSD
Memory: 128G
Cluster environment
- Nebula Version:v2.6.1
- Deployment way :RPM
- The cluster size : Three copies , Six nodes
Data scale
---------+--------------------------+-----------+
| "Space" | "vertices" | 559191827 |
+---------+--------------------------+-----------+
| "Space" | "edges" | 722490436 |
+---------+--------------------------+-----------+Importer To configure
# Graph edition , Connect 2.x Is set to v2.
version: v2
description: Relation Space import data
# Whether to delete the temporarily generated logs and error data files .
removeTempFiles: false
clientSettings:
# nGQL Number of retries for statement execution failure .
retry: 3
# Nebula Graph Number of concurrent clients .
concurrency: 5
# Every Nebula Graph The cache queue size of the client .
channelBufferSize: 1024
# Specify the data to import Nebula Graph Graph space .
space: Relation
# Connection information .
connection:
user: root
password: ******
address: 10.0.XXX.XXX:9669,10.0.XXX.XXX:9669
postStart:
# configure connections Nebula Graph After the server , Some operations performed before inserting data .
commands: |
# The interval between the execution of the above command and the execution of the insert data command .
afterPeriod: 1s
preStop:
# Configure disconnect Nebula Graph Some operations performed before connecting to the server .
commands: |
# Error and other log information output file path .
logPath: /mnt/csv_file/prod_relation/err/test.log
....50 03 15 * * /mnt/csv_file/importer/nebula-importer -config /mnt/csv_file/importer/rel.yaml >> /root/rel.log 2022/05/15 03:50:11 [INFO] statsmgr.go:62: Tick: Time(10.00s), Finished(1952500), Failed(0), Read Failed(0), Latency AVG(4232us), Batches Req AVG(4582us), Rows AVG(195248.59/s)
2022/05/15 03:50:16 [INFO] statsmgr.go:62: Tick: Time(15.00s), Finished(2925600), Failed(0), Read Failed(0), Latency AVG(4421us), Batches Req AVG(4761us), Rows AVG(195039.12/s)
2022/05/15 03:50:21 [INFO] statsmgr.go:62: Tick: Time(20.00s), Finished(3927400), Failed(0), Read Failed(0), Latency AVG(4486us), Batches Req AVG(4818us), Rows AVG(196367.10/s)
2022/05/15 03:50:26 [INFO] statsmgr.go:62: Tick: Time(25.00s), Finished(5140500), Failed(0), Read Failed(0), Latency AVG(4327us), Batches Req AVG(4653us), Rows AVG(205619.44/s)
2022/05/15 03:50:31 [INFO] statsmgr.go:62: Tick: Time(30.00s), Finished(6080800), Failed(0), Read Failed(0), Latency AVG(4431us), Batches Req AVG(4755us), Rows AVG(202693.39/s)
2022/05/15 03:50:36 [INFO] statsmgr.go:62: Tick: Time(35.00s), Finished(7087200), Failed(0), Read Failed(0), Latency AVG(4461us), Batches Req AVG(4784us), Rows AVG(202489.00/s)The real time
Some notes
- About concurrency , It is mentioned in the question that , This concurrency Designated as your cpu cores Can , Indicates how many client Connect Nebula Server. In practice , Want to go trade off The impact of import speed and server pressure . Test on our side , If concurrency is too high , Will cause disk IO Too high , Trigger some set alarms , It is not recommended to increase concurrency , You can make a trade-off according to the actual business test .
- Importer It can't be continued at breakpoints , If something goes wrong , Need to be handled manually . In practice , We will analyze the program Importer Of log, Handle according to the situation , If any part of the data has unexpected errors , Alarm notification , Artificial intervention , Prevent accidents .
- Hive After the table is generated, it is transferred to Nebula Server, This part of the task The actual time consumption is and Hadoop Resources are closely related , There may be insufficient resources leading to Hive and CSV Table generation time is slow , and Importer Normal running , This part needs to be predicted in advance . Our side is based on hive Task end time and Importer Compare the task start time , To determine whether or not Importer The process of is running normally .
边栏推荐
- ByteDance dev better technology salon was successfully held, and we joined hands with Huatai to share our experience in improving the efficiency of web research and development
- 小发猫物联网平台搭建与应用模型
- 6.26CF模拟赛E:价格最大化题解
- C language printing exercise
- 学习路之PHP--phpstudy创建项目时“hosts文件不存在或被阻止打开”
- 每日一题(2022-07-02)——最低加油次数
- 基于C语言的菜鸟驿站管理系统
- vbs或vbe如何修改图标
- Digital "new" operation and maintenance of energy industry
- Scala基础教程--17--集合
猜你喜欢
.NET ORM框架HiSql实战-第二章-使用Hisql实现菜单管理(增删改查)
![[go ~ 0 to 1] read, write and create files on the sixth day](/img/cb/b6785ad7d7c7df786f718892a0c058.png)
[go ~ 0 to 1] read, write and create files on the sixth day
Nebula Importer 数据导入实践
Angry bird design based on unity
Build your own website (15)
Li Kou brush question diary /day4/6.26
Scala basic tutorial -- 20 -- akka
Uni app and uviewui realize the imitation of Xiaomi mall app (with source code)
力扣刷题日记/day5/2022.6.27

ByteDance dev better technology salon was successfully held, and we joined hands with Huatai to share our experience in improving the efficiency of web research and development
随机推荐
NBA赛事直播超清画质背后:阿里云视频云「窄带高清2.0」技术深度解读
未来几年中,软件测试的几大趋势是什么?
从实时应用角度谈通信总线仲裁机制和网络流控
神经网络物联网应用技术就业前景【欢迎补充】
激进技术派 vs 项目保守派的微服务架构之争
Scala基础教程--15--递归
Mxnet implementation of googlenet (parallel connection network)
MXNet对GoogLeNet的实现(并行连结网络)
Wireshark抓包TLS协议栏显示版本不一致问题
奥迪AUDI EDI INVOIC发票报文详解
小发猫物联网平台搭建与应用模型
Li Kou brush question diary /day4/6.26
使用SSH
Journal des problèmes de brosse à boutons de force / day6 / 6.28
基于lex和yacc的词法分析器+语法分析器
IBM WebSphere MQ检索邮件
力扣刷題日記/day6/6.28
Lex and yacc based lexical analyzer + parser
基于C语言的菜鸟驿站管理系统
Li Kou brush question diary /day6/6.28