当前位置:网站首页>基于YOLOV5行人跌倒检测实验
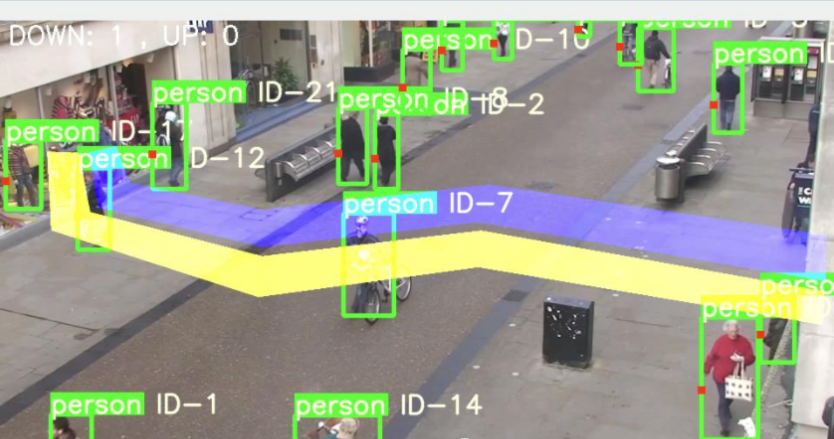
基于YOLOV5行人跌倒检测实验
2022-08-04 19:01:00 【InfoQ】
边栏推荐
猜你喜欢
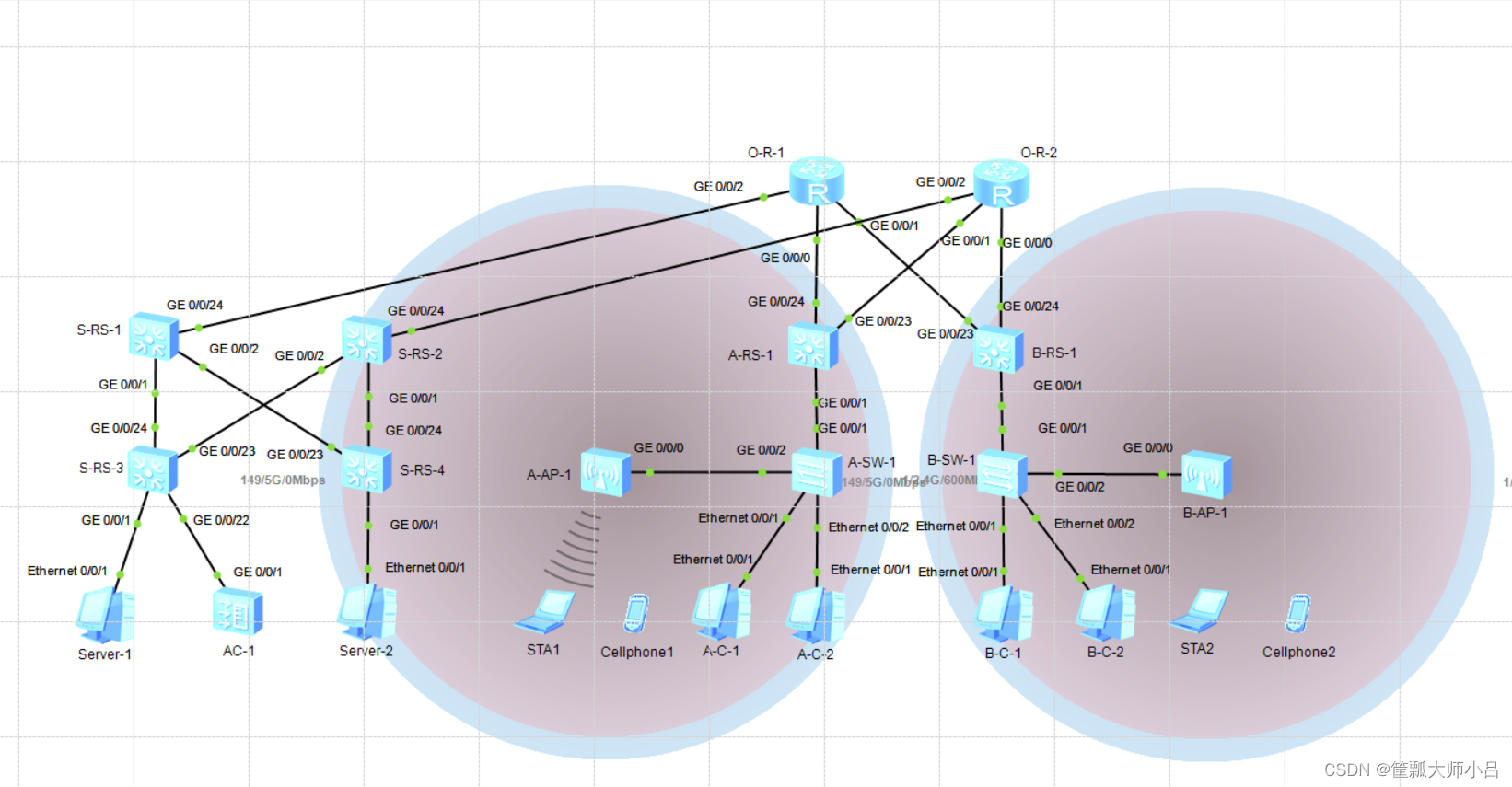
网络运维管理从基础到实战-自用笔记(1)构建综合园区网、接入互联网
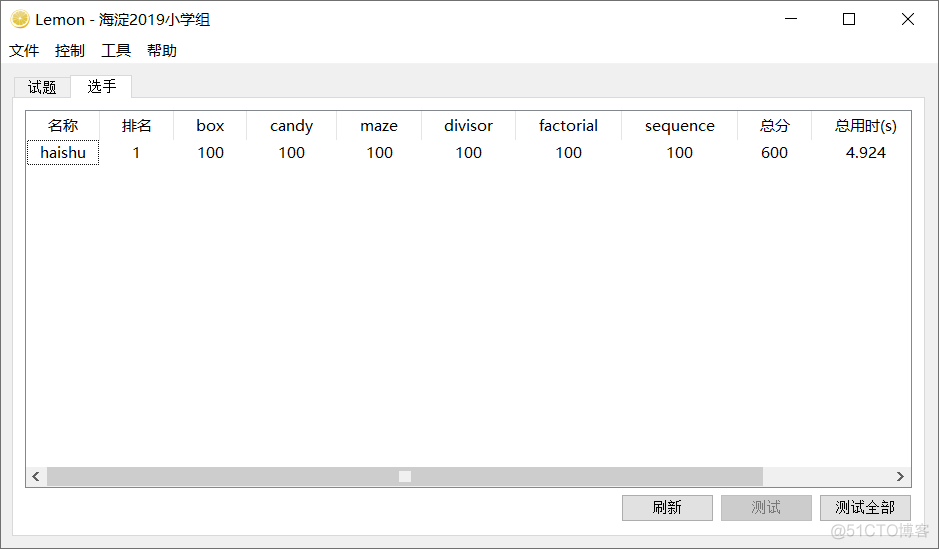
2019 Haidian District Youth Programming Challenge Activity Elementary Group Rematch Test Questions Detailed Answers
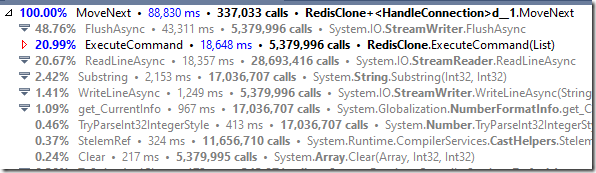
使用.NET简单实现一个Redis的高性能克隆版(二)
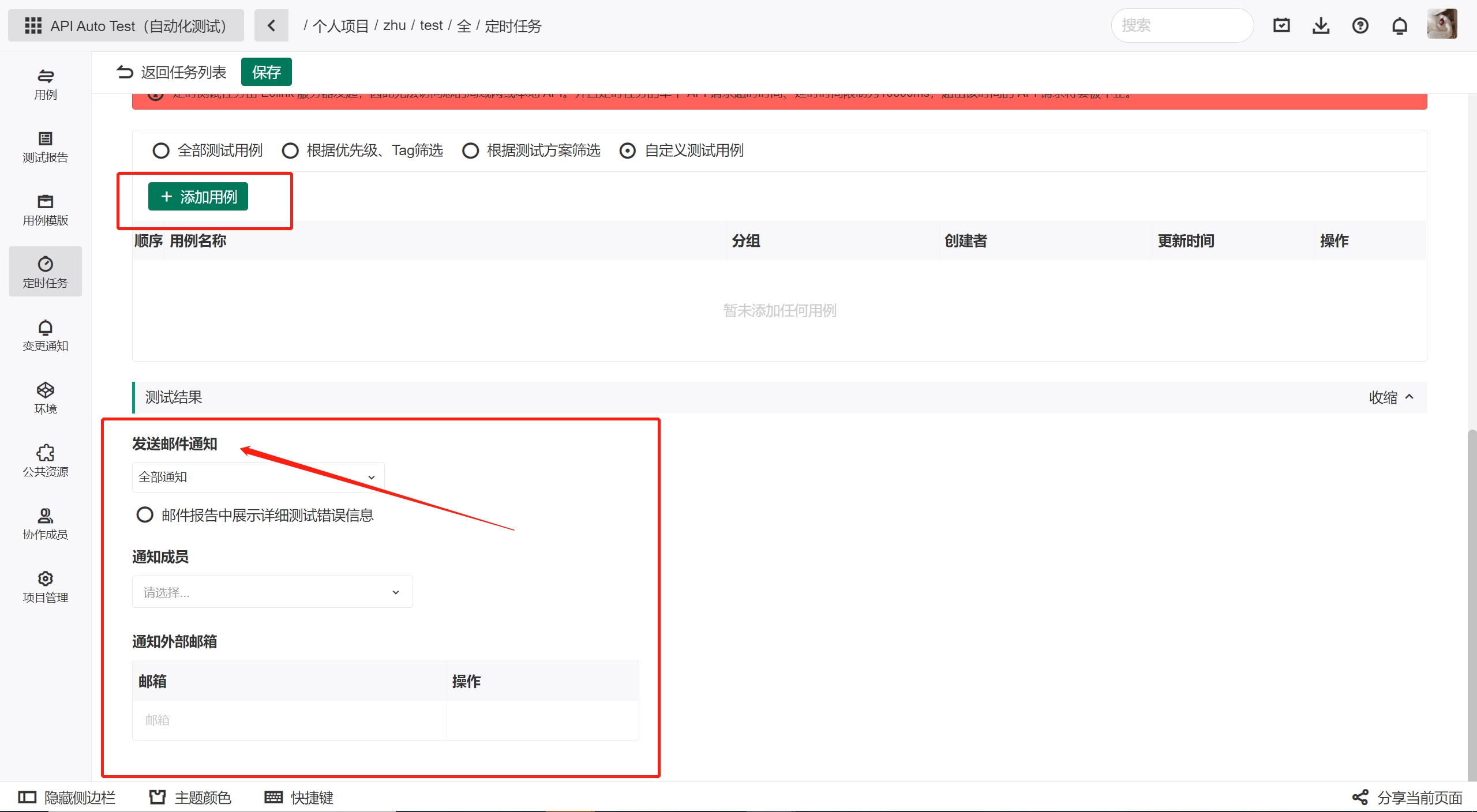
如何进行自动化测试?【Eolink分享】
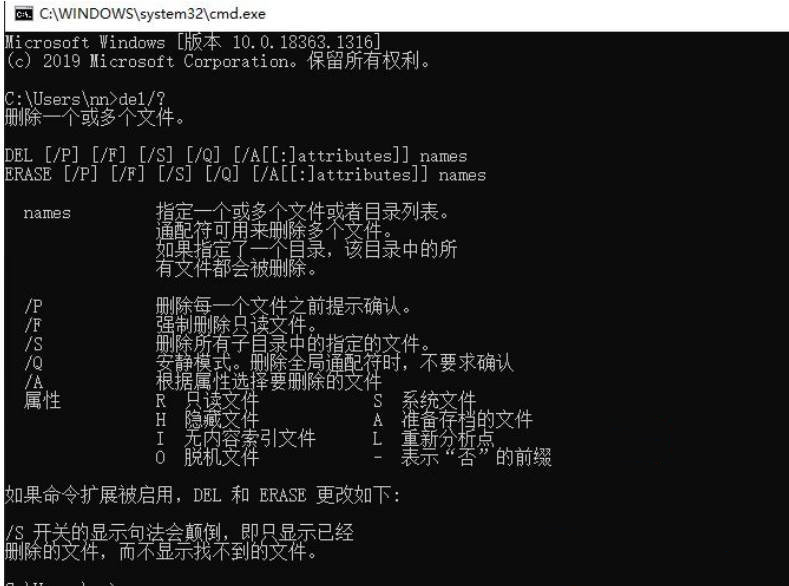
Win10只读文件夹怎么删除
![[Sql刷题篇] 查询信息数据--Day1](/img/a7/67b59bd41803dfc07ecb8f00669c29.png)
[Sql刷题篇] 查询信息数据--Day1
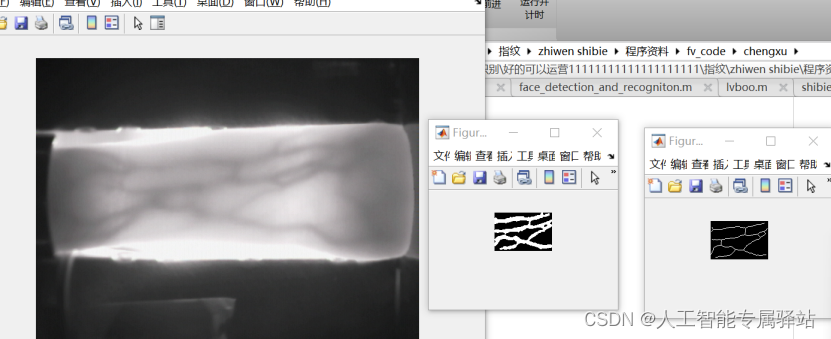
指静脉识别-matlab
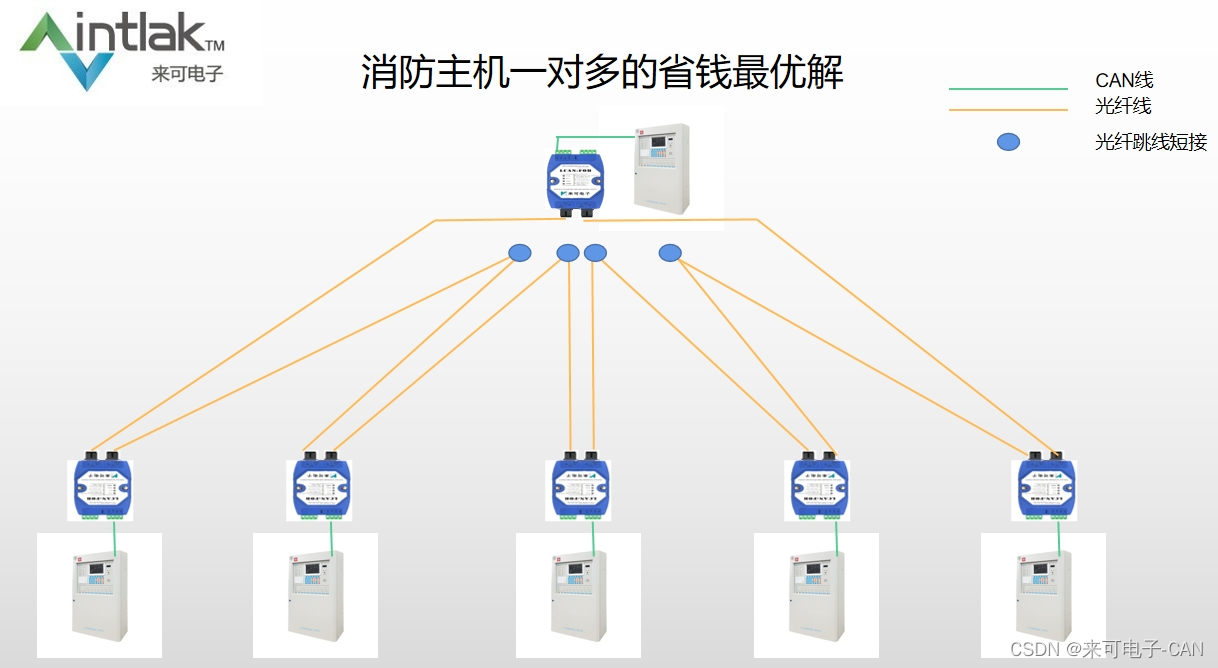
CAN光纤转换器CAN光端机解决消防火灾报警
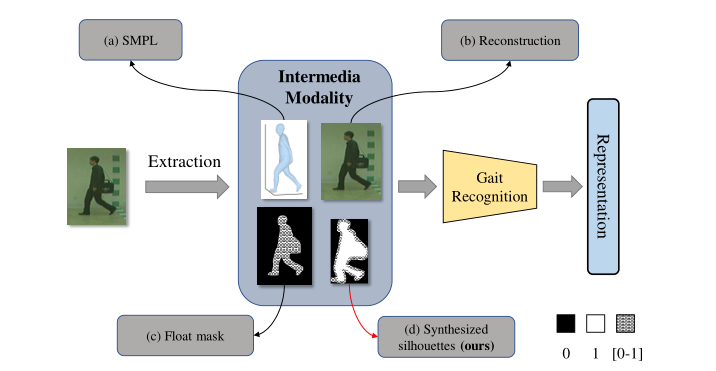
(ECCV-2022)GaitEdge:超越普通的端到端步态识别,提高实用性

【CCIG 2022】视觉大模型论坛
随机推荐
如何理解 SAP UI5 的 sap.ui.define 函数
【最新资讯】2022下半年软考新增2个地区公布报名时间
How can test engineers break through career bottlenecks?
关于使用腾讯云HiFlow场景连接器每天提醒签到打卡
Nintendo won't launch any new hardware until March 2023, report says
如何让 JS 代码不可断点
测试/开发程序员男都秃头?女都满脸痘痘?过好我们“短暂“的一生......
After EasyCVR is locally connected to the national standard device to map the public network, the local device cannot play and cascade the solution
方法的重写
迪赛智慧数——其他图表(主题河流图):近年居民消费、储蓄、投资意愿
【杰神说说】物联大师2.0版本预告
WPF 多个 StylusPlugIn 的事件触发顺序
正畸MIA微种植体支抗技术中国10周年交流会在沈举办
如何进行自动化测试?
如何进行自动化测试?【Eolink分享】
win10 uwp ping
Homework 8.3 Thread Synchronization Mutex Condition Variables
《学会写作》粥佐罗著
Scala104-Spark.sql的内置日期时间函数
在表格数据集上训练变分自编码器 (VAE)示例