当前位置:网站首页>Accuracy improvement method: efficient visual transformer framework of adaptive tokens (open source)
Accuracy improvement method: efficient visual transformer framework of adaptive tokens (open source)
2022-07-27 13:53:00 【Computer Vision Research Institute】
Pay attention to the parallel stars
Never get lost
Institute of computer vision



official account ID|ComputerVisionGzq
Study Group | Scan the code to get the join mode on the homepage

Address of thesis :https://openaccess.thecvf.com/content/CVPR2022/papers/Yin_A-ViT_Adaptive_Tokens_for_Efficient_Vision_Transformer_CVPR_2022_paper.pdf
Code address :https://github.com/NVlabs/A-ViT
Computer Vision Institute column
author :Edison_G
YOLOv7 Under the same volume YOLOv5 Higher accuracy , Fast 120%(FPS), Than YOLOX fast 180%(FPS), Than Dual-Swin-T fast 1200%(FPS), Than ConvNext fast 550%(FPS), Than SWIN-L fast 500%(FPS).
01
summary
Introduced today , It is the researchers who put forward A-ViT, An image adaptive adjustment for different complexity vision transformers (ViT) The method of reasoning cost .A-ViT By automatically reducing the number of... In the visual converter processed in the network when reasoning is in progress tokens Quantity to achieve this .

The researchers redefined the adaptive computing time for this task (ACT[Adaptive computation time for recurrent neural networks]), Extended stop to discard redundant space tags .vision transformers Attractive architectural features make our The adaptive tokens The reduction mechanism can speed up reasoning without modifying the network architecture or reasoning hardware .
A-ViT No additional parameters or subnets are required to stop , Because the adaptive stop learning is based on the original network parameters . And previous ACT Methods compared , Distributed a priori regularization is further introduced , Can train stably . In the image classification task (ImageNet1K) in , Shows the proposed A-ViT Efficiency in filtering spatial features of information and reducing overall computing . The proposed method will DeiT-Tiny The throughput of 62%, take DeiT-Small The throughput of 38%, The accuracy rate has only decreased 0.3%, It is much better than the existing technology .
02
background
Transformers It has become a popular neural network architecture , It uses a highly expressed attention mechanism to calculate network output . They originated from naturallanguageprocessing (NLP) Community , It has been proved that it can effectively solve NLP A wide range of issues in , For example, machine translation 、 It means learning and question and answer .
lately ,vision transformers More and more popular in the visual community , They have been successfully applied to a wide range of visual applications , For example, image classification 、 object detection 、 Image generation and semantic segmentation . The most popular paradigm is still vision transformers It is formed by splitting the image into a series of orderly patches tokens And in tokens In between inter-/intra-calculations To solve basic tasks . Use vision transformers Processing images is still computationally expensive , This is mainly due to tokens The square of the number of interactions between . therefore , In the case of a large number of computing and memory resources , Deploy on a data processing cluster or edge device vision transformers Challenging .
03
New framework analysis
First look at the figure below :

The above figure is a kind of vision transformers Enable adaptation tokens The method of calculation . Use the adaptive stop module to increase vision transformers block , This module calculates each tokens Stopping probability of . This module reuses the parameters of the existing block , And a single neuron is borrowed from the last dense layer of each block to calculate the stopping probability , No additional parameters or calculations are imposed . Once the stop condition is reached ,tokens Will be discarded . Stop by adaptation tokens, We only work on activities that are considered useful for the task tokens Perform Intensive Computing . result ,vision transformers Successive blocks in gradually receive less tokens, This leads to faster reasoning . Learned tokens Stop varies by image , But it is very consistent with image semantics ( See the example above ). This will immediately accelerate reasoning out of the box on an off the shelf computing platform .
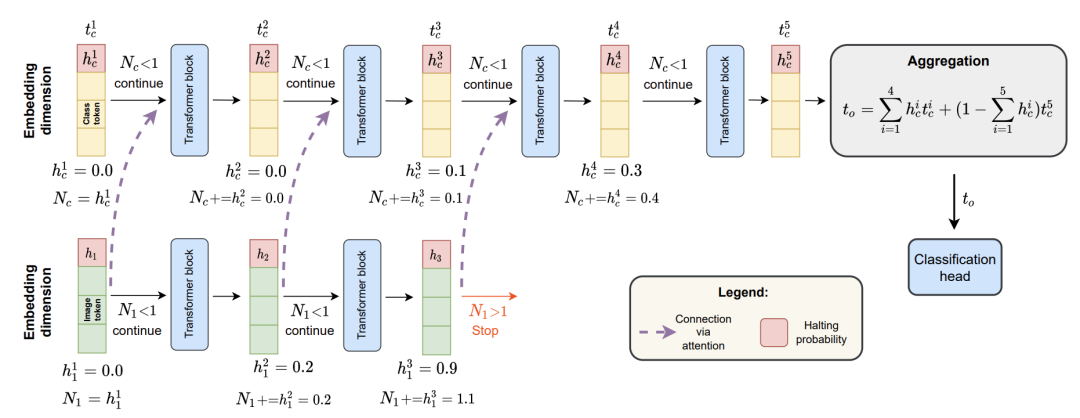
A-ViT An example of : In Visualization , For the sake of simplicity , omitted (i) Other patch marks ,(ii) Attention between classes and patch tags as well (iii) Residual connection .
The first element of each tag is reserved for stopping the score calculation , Do not increase computing overhead . We use subscripts c Represents a class tag , Because it has special treatment . from k Each of the indexes token There is a single Nk accumulator , And stop at different depths . With the standard ACT Different , The mean field formula is only applicable to classification marks , Other markers contribute to category markers through attention . This allows images to be aggregated without / Patch token In the case of adaptive tokens Calculation .

04
Experimental analysis and visualization

Original image (left) and the dynamic token depth (right) of A-ViT-T on the ImageNet-1K validation set. Distribution of token computation highly aligns with visual features. Tokens associated with informative regions are adaptively processed deeper, robust to repeating objects with complex backgrounds. Best viewed in color.

(a) ImageNet-1K On validation set A-ViT-T The average location of each image patch tokens depth .(b) Stop fraction distribution through transformer block . Each point is associated with a randomly sampled image , Represents the average of this layer tokens fraction .

By average tokens The depth is certain ImageNet-1K Visual comparison of difficult samples in the validation set . Please note that , All the images above are correctly classified —— The only difference is that difficult samples need more depth to process their semantic information . Compared with the image on the right , The mark in the left image exits about 5 layer .



THE END
Please contact the official account for authorization.

The learning group of computer vision research institute is waiting for you to join !
ABOUT
Institute of computer vision
The Institute of computer vision is mainly involved in the field of deep learning , Mainly devoted to face detection 、 Face recognition , Multi target detection 、 Target tracking 、 Image segmentation and other research directions . The Research Institute will continue to share the latest paper algorithm new framework , The difference of our reform this time is , We need to focus on ” Research “. After that, we will share the practice process for the corresponding fields , Let us really experience the real scene of getting rid of the theory , Develop the habit of hands-on programming and brain thinking !
VX:2311123606
Previous recommendation
AI Help social security , The latest video abnormal behavior detection method framework
ONNX elementary analysis : How to accelerate the engineering of deep learning algorithm ?
Improved shadow suppression for illumination robust face recognition
Text driven for creating and editing images ( With source code )
Based on hierarchical self - supervised learning, vision Transformer Scale to gigapixel images
边栏推荐
- QT clipboard qclipboard copy paste custom data
- ONNXRuntime【推理框架,用户可以非常便利的用其运行一个onnx模型】
- 网络异常流量分析系统设计
- 期货手续费标准和保证金比例
- 期货开户的条件和流程
- OPPO 自研大规模知识图谱及其在数智工程中的应用
- 期货公司开户后续会有哪些服务?
- Network packet loss, network delay? This artifact helps you get everything done!
- Huiliang technology app is a good place to go to sea: after more than ten years of popularity, why should the United States still choose to go to sea for gold
- 小程序毕设作品之微信校园洗衣小程序毕业设计成品(8)毕业设计论文模板
猜你喜欢

Set up SSH key based authentication using putty

Application layer World Wide Web WWW

特征工程中的缩放和编码的方法总结

redis集群搭建-使用docker快速搭建一个测试redis集群

Wechat campus laundry applet graduation design finished product (4) opening report

Matlab digital image processing experiment 2: single pixel spatial image enhancement

opencv图像的缩放平移及旋转

小程序毕设作品之微信校园洗衣小程序毕业设计成品(7)中期检查报告

Wechat campus laundry applet graduation design finished product of applet completion work (3) background function

Software system architecture designer concise tutorial | software system modeling
随机推荐
Wechat campus laundry applet graduation design finished product of applet completion work (3) background function
小程序毕设作品之微信校园洗衣小程序毕业设计成品(4)开题报告
Construction and application of industrial knowledge atlas (2): representation and modeling of commodity knowledge
Tencent cloud and the China Federation of industry released the research results of industrial AI quality inspection standardization to accelerate the intelligent transformation of manufacturing indus
SQL tutorial: introduction to SQL aggregate functions
7.26 simulation summary
汇量科技app出海好地:火了十几年,美国凭什么还是出海首选淘金地
eBPF/Ftrace
JS callback function (callback)
Differences between shell environment variables and set, env, export
JS basic knowledge collation - array
Is it still time to take the PMP Exam in September?
期货手续费标准和保证金比例
Redis cluster setup - use docker to quickly build a test redis cluster
[introduction to C language] zzulioj 1021-1025
Echart line chart displays the last point and vertical dotted line by default
Deliver temperature with science and technology, vivo appears at the digital China Construction Summit
MySQL高可用实战方案——MHA
看看有没有你,各赛区入围名单
Thinkphp+ pagoda operation environment realizes scheduled tasks