当前位置:网站首页>Popular understanding of decision tree ID3
Popular understanding of decision tree ID3
2022-07-03 15:20:00 【alw_ one hundred and twenty-three】
I have planned to present this series of blog posts in the form of animated interesting popular science , If you're interested Click here .
0. What is a decision tree
The decision tree is simply a tree that can make decisions for us , Or it is a form of expression of our brain circuits . For example, I saw a person , Then I will YY Did this man buy a car . Then my brain circuit may be dark :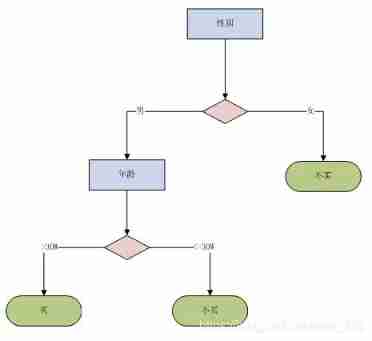
In fact, such a form of brain circuit is what we call decision tree . So we can see from the figure that the decision tree is a tree structure similar to people's decision-making process , Start at the root node , Each branch represents a new decision event , Two or more branches will be generated , Each leaf represents a final category . Obviously , If I have constructed a decision tree now , Now I get a piece of data ( male , 29), I will think this person has never bought a car . So , The key problem is how to construct the decision tree .
1. Construct a decision tree
When constructing the decision tree, we will follow an indicator , Some are built according to information gain , This is called ID3 Algorithm , There is information gain ratio to build , This is called C4.5 Algorithm , Some are constructed according to Gini coefficient , This is called CART Algorithm . Then this blog post is mainly about ID3 How does the algorithm construct a decision tree .
2. entropy
Whole ID3 In fact, it is mainly about information gain , So make sure ID3 Algorithm flow of , First of all, we should figure out what is information gain , But there is a concept that must be understood before we can figure out information gain , Is entropy . So let's first look at what entropy is .
In information theory and probability statistics , To represent the uncertainty of a random variable , Just YY There is a concept called entropy . If we assume X Is a discrete random variable with limited values , Obviously, its probability distribution or distribution law is maozi :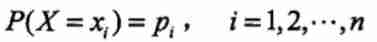
With the probability distribution , Then this random variable X The formula of entropy is (PS: there log In order to 2 Bottom ):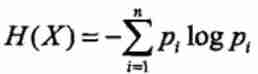
It can also be seen from this formula , If my probability is 0 Or is it 1 When , My entropy is 0.( Because in this case, the uncertainty of my random variable is the lowest ), Then if my probability is 0.5 That's when it's five to five ( Burn root incense for Grandpa Lu ), My entropy is maximum, that is 1.( It's like tossing a coin , You'll never know whether you'll throw it in the front or the back next time , So its uncertainty is very high ). So , The greater the entropy , The higher the uncertainty .
In our actual situation , The random variables we want to study are basically multi random variables , So suppose there is an arbitrary quantity (X,Y), Then its joint probability distribution is maozi :
Then if I want to know in my event X Under the premise of occurrence , My incident Y What is the entropy of occurrence , We call this entropy conditional entropy . Conditional entropy H(Y|X) Represents a random variable X Is a random variable Y uncertainty . The formula of conditional entropy is maozi :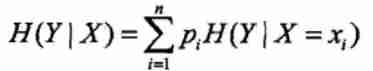
Of course, a property of conditional entropy is the same as that of entropy , The more certain my probability is , The smaller the conditional entropy , The more likely it is , The greater the conditional entropy .
OK, Now we know what entropy is , What is conditional entropy . Next, we can see what is information gain . The so-called information gain means that I know the conditions X You can get information after Y The degree of uncertainty reduction . like , I'm playing mind reading . You have something in mind , Let me guess . I have begun to ask you nothing , If I want to guess , It must be a blind guess . At this time, my entropy is very high, right . Then I will try to ask you right and wrong questions next , When I asked right and wrong questions , I can reduce the scope of guessing what you think , This actually reduces my entropy . Then the reduction of my entropy is my information gain .
So if the information gain is combined with machine learning, it is , If you take the characteristics A Pair training set D The information gain of is recorded as g(D, A) Words , that g(D, A) And the formula for that is :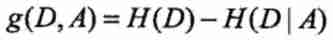
If you see this pile of formulas, you may be confused , It's better to take a chestnut to see how information gain is calculated . Suppose I have this data sheet now , The first column is gender , The second column is activity , The third column is whether the customer lost label.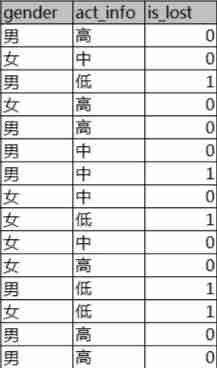
If I want to calculate the information gain of gender and activity , First, calculate the total entropy and conditional entropy .(5/15 In total, there are 15 In the sample label by 1 Samples are available. 5 strip ,3/8 The sample of male sex has 8 strip , Then this 8 There are 3 The bar is label by 1, Other values, and so on )
Total entropy =(-5/15)*log(5/15)-(10/15)*log(10/15)=0.9182
Gender is male entropy = -(3/8)*log(3/8)-(5/8)*log(5/8)=0.9543
Entropy of gender as female =-(2/7)*log(2/7)-(5/7)*log(5/7)=0.8631
Entropy with low activity =-(4/4)*log(4/4)-0=0
The activity is entropy in =-(1/5)*log(1/5)-(4/5)*log(4/5)=0.7219
Entropy with high activity =-0-(6/6)*log(6/6)=0
Now with total entropy and conditional entropy, we can calculate the information gain of gender and activity .
Gender information gain = Total entropy -(8/15)* Gender is male entropy -(7/15)* Entropy of gender as female =0.0064
Information gain of activity = Total entropy -(6/15)* Entropy with high activity -(5/15)* The activity is entropy in -(4/15)* Entropy with low activity =0.6776
What is the significance of information gain after it is calculated ? Back to mind reading , In order that I can guess what you think more accurately , I'm sure the better I ask, the more accurate I can guess ! In other words, I must think of a question to ask you about the biggest information gain , Isn't it ? Actually ID3 The algorithm also thinks so .ID3 The idea of the algorithm is from the training set D Calculate the information gain of each feature , Then choose the largest node as the current node . Then continue to repeat the steps just now to build the decision tree .
3.ID3
ID3 In fact, the algorithm constructs the tree according to the information gain of the feature . The specific routine is to start from the root node , Calculate the information gain of all possible features for the node , Then select the feature with the largest information gain as the feature of the node , According to the different values of the feature, the sub nodes are established , Then recursively execute the above routine on the child nodes until the information gain is very small or no features can be selected .
This may seem silly , It's better to use the data just now to build a decision tree .
At the beginning, we have calculated that the greatest information gain is activity , So the root node of the decision tree is activity . So at this time, the trees are dark brown :
Then I found that the data in the training set showed that I would lose when my activity was low , When you are active, you must not lose , So you can connect two leaf nodes to the root node first .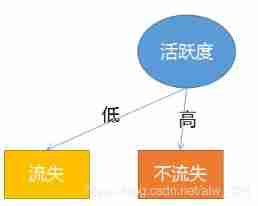
But when the activity is medium, it does not necessarily lose , So at this time, the data with low and high activity can be shielded , After shielding 5 Data , And then put this 5 The data is regarded as a training set to continue to calculate which feature has the highest information gain , It's obvious that after the calculation, it's gender , So at this time, the tree turns dark purple :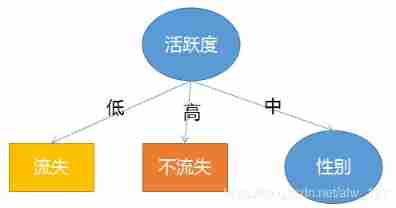
At this time , There are no other features to choose from in the dataset ( There are only two characteristics , Activity is already the root node ), So when my gender is male or female, that kind of situation is most likely to happen . At this time, there are male users 1 One is loss ,1 One is not to lose , Five five open . So you can consider randomly choosing a result as the output . All female users have lost , So when the gender is female, the output is lost . So , The tree becomes dark purple :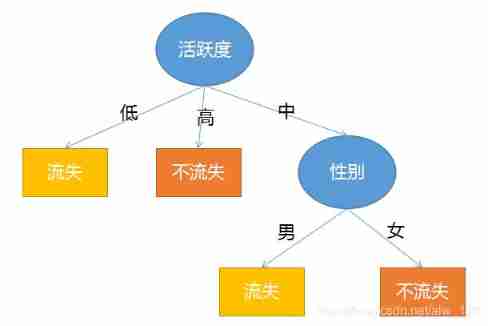
Okay , The decision tree is constructed . It can be seen from the figure that a very good thing about the decision tree is that the model is very explanatory !! Obviously , If there is a piece of data now ( male , high ) Words , The output will not be lost .
OK, This is my right to ID3 Simple understanding of the algorithm , I hope it helped you , Of course, you guys are also welcome to complain about roast . Slip first ~~~
边栏推荐
- Global and Chinese markets for indoor HDTV antennas 2022-2028: Research Report on technology, participants, trends, market size and share
- 在MapReduce中利用MultipleOutputs输出多个文件
- 视觉上位系统设计开发(halcon-winform)-3.图像控件
- Concurrency-01-create thread, sleep, yield, wait, join, interrupt, thread state, synchronized, park, reentrantlock
- 运维体系的构建
- 基于SVN分支开发模式流程浅析
- 自定义注解
- Matplotlib drawing label cannot display Chinese problems
- 使用Tengine解决负载均衡的Session问题
- 【pytorch学习笔记】Transforms
猜你喜欢

Kubernetes will show you from beginning to end
Dataframe returns the whole row according to the value

Tensorflow realizes verification code recognition (I)

Visual upper system design and development (Halcon WinForm) -1 Process node design

Reentrantlock usage and source code analysis

Jvm-09 byte code introduction

mysql innodb 存储引擎的特性—行锁剖析

解决pushgateway数据多次推送会覆盖的问题

【Transform】【实践】使用Pytorch的torch.nn.MultiheadAttention来实现self-attention

Jvm-03-runtime data area PC, stack, local method stack
随机推荐
Visual upper system design and development (Halcon WinForm) -1 Process node design
[probably the most complete in Chinese] pushgateway entry notes
Can‘t connect to MySQL server on ‘localhost‘
视觉上位系统设计开发(halcon-winform)-2.全局变量设计
Characteristics of MySQL InnoDB storage engine -- Analysis of row lock
第04章_逻辑架构
Kubernetes will show you from beginning to end
Kubernetes advanced training camp pod Foundation
redis单线程问题强制梳理门外汉扫盲
Dataframe returns the whole row according to the value
Using Tengine to solve the session problem of load balancing
Puppet automatic operation and maintenance troubleshooting cases
[pytorch learning notes] transforms
Kubernetes 进阶训练营 Pod基础
视觉上位系统设计开发(halcon-winform)-1.流程节点设计
Leetcode the smallest number of the rotation array of the offer of the sword (11)
需要知道的字符串函数
Influxdb2 sources add data sources
PyTorch crop images differentiablly
运维体系的构建