当前位置:网站首页>CVPR 2022 | single step 3D target recognizer based on sparse transformer
CVPR 2022 | single step 3D target recognizer based on sparse transformer
2022-07-05 12:49:00 【Zhiyuan community】

Code :https://github.com/TuSimple/SST
The paper :https://arxiv.org/abs/2112.06375
Reading guide
For automatic driving LiDAR 3D Object detection and control 2D Compared with the test , The object size is much smaller than the input scene size . many 3D Detector compliance 2D Common practices for detectors , The quantized feature map of point cloud is also down sampled , This approach ignores 3D And 2D The difference in the relative size of the target . In this paper , We reconsider the multi step scheme for LiDAR 3D Influence of object detector . Our experiment points out that , Downsampling offers few advantages , And inevitably lead to the loss of information . So , We propose a one-step sparse converter (SST) To keep the resolution of the neural network unchanged from the beginning to the end . With the help of Transformer, Our method solves the problem of insufficient receptive field in one-step Architecture . It also works well with the sparsity of point clouds , Avoid expensive calculations . Final , our SST On a large scale Waymo Best results on open datasets . It is worth mentioning that , Due to the characteristics of single step , Our method works on small objects ( Pedestrians ) It can achieve excellent performance in detection (83.8 LEVEL 1 AP on validation split). The code will be https://github.com/TuSimple/SST Release .
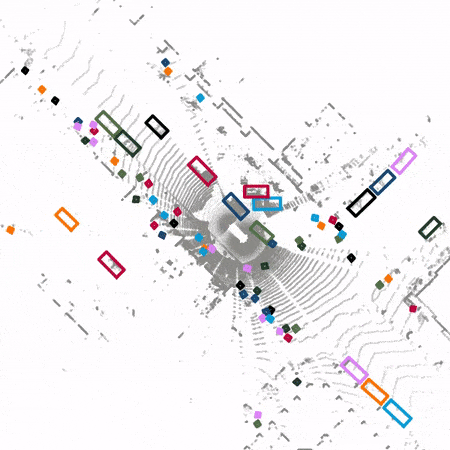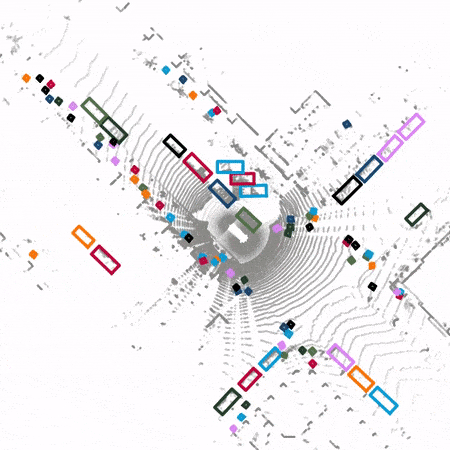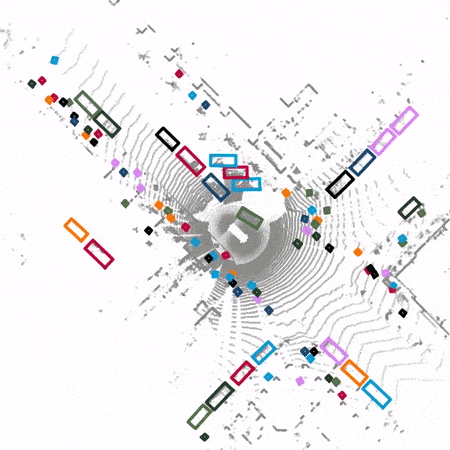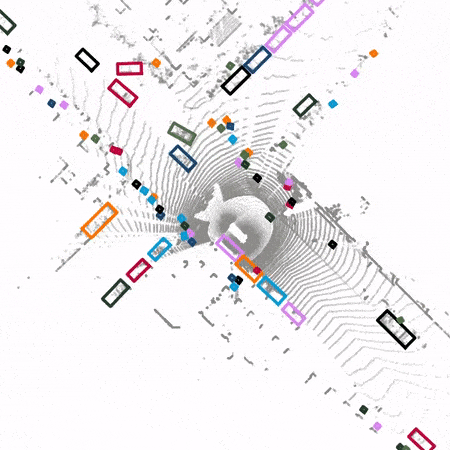
contribution
In the autopilot scenario , The size of the object is usually small compared to the whole input scene . And different from the image ,3D The size of the object in the scene is relative to it sensor It doesn't matter the distance , There will be no serious scale variation. So a question arises : Mainstream multiscale convolution backbone Is it really necessary in such a scenario ? Is it possible to design an efficient and feasible single step ( No downsampling ) The detector ?
In the process of exploration, we found two key points :1) Gradually throw away the downsampling operator , The overall network performance is improved . But throw them away completely , The effective receptive field will become very small .2) It's too slow to use convolution with single step .. So the core of the problem becomes how address These two points .( The exploration process here will be shown in detail later )
Based on the above difficulties , We thought of rubbing a wave Transformer in attention Mechanism , It has two advantages , One is to be able to model long-range dependency, It's easy to get enough receptive fields ; Second, it can handle variable length sequences , This does not apply to disordered and sparse point clouds ? So we follow 了 swin transformer To divide into window Ideas , The voxelized point cloud space is also delimited window. And with the swin The difference is , We gave up hierarchy structure , And put attention Sparse transformation has been carried out . In this way, we get a network without downsampling , How many voxels are there (voxel) Into the network , How many voxels are out of the network . And because attention Of locality and sparsity, The amount of calculation can also be kept within an acceptable range .
The problems solved in this paper can be summarized as follows :
- One of the problems of point cloud target detection is : The size of the target accounts for a very small proportion of the size of the overall scene , Here's the picture . The target size of two-dimensional image detection presents a long tail distribution , And the overall proportion is too large , Multiscale (Hierarchical) The structure of the network is very suitable . However, point cloud ( Outdoor automatic driving scene ) The proportion of the size of the objects is very small , thus , The author asks questions : What is the use of multiscale networks for down sampling in point cloud target detection ?
- The author aims at voxel based methods . There are two problems caused by not taking down sampling : Calculate the increase of consumption and the decrease of receptive field . The author practices several conventional methods , Include : Cavity convolution (dilated convolution) And a larger convolution kernel .
The main contributions of this paper can be summarized as follows :
- In this paper, experiments show that the step size of neural network is the current mainstream 3D The main problem of target recognition method .
- Simply shortening the step length is limited by the problem of insufficient receptive field . Therefore, this paper proposes a method based on Transformer Single step sparse converter (SST): It not only avoids the loss of information caused by down sampling , And ensure enough feeling fields .
- application SST, In this paper Waymo Excellent performance in small object detection on open data sets
Method
Pictured 1 Shown , Compared with the traditional 3D detector ,SST The voxelized feature map is not down sampled or up sampled ; also SST Convolution layers are not used , Instead, it uses the sparsity of point cloud feature map and applies self attention mechanism to extract features .

SST Use similar PointPillars The point cloud is transformed into a pseudo feature image from an aerial view . Then the obtained sparse pseudo feature image is compared with Vision Transformer Similar methods are used to segment into non overlapping regions . Self attention mechanism is applied to features in the same region . To solve the problem of objects with cross regional features , Pictured 3 Shown ,SST After a local self attention , Region segmentation is performed by global translation for the second local self attention . In this way, even the features of the region edge can notice the features on the other side of the region edge during the second local self attention .

Due to the sparsity of radar point cloud data , The pseudo feature image of aerial view angle as input also has a certain sparsity . There is a quadratic relationship between the computational complexity of attention mechanism and the computational complexity of attention , Such sparsity naturally matches the self attention mechanism perfectly . in addition , The self attention mechanism does not need to be specially adapted for sparsity like the convolution layer .
Multiple such SST Stack the modules , In addition, a module that transforms sparse features back to dense feature graph can form a single step sparse Converter (SST), The input is a voxelized pseudo feature image , The output is a pseudo feature image of the same size . On this basis , Any target recognizer can be used to predict the category of three-dimensional objects 、 Location and size .

experiment
surface 2 Show SST stay Waymo The performance of vehicle detection on public data set is better than other methods . In a single stage , A single frame SST Slightly lower than CenterPoint, Three frames SST There is a sharp rise ; The performance is average in two stages . There are two points of improvement from single stage to dual stage , explain SST It also relies on two-stage fine-tuning .

surface 3 Show SST stay Waymo The performance of pedestrian detection on public data sets is better than other methods . Main experiment ( Pedestrians ) In the experiments , A single frame SST You can achieve SOTA The effect of , And the points lead more . This explanation SST Design of fixed step structure , Reduced information loss , Fully interact with nearby and far points , Keep fine granularity , This makes it very outstanding in small target detection .

Further , To explore the positioning accuracy , take IoU Setting the threshold smaller makes it more stringent . In the single frame method , contrast MVF++*,SST In normal IoU Below the threshold , But the strict threshold can exceed , explain SST It has certain effect on improving positioning accuracy . The key point is , In the multi frame method , Although it is not as good as MVF and 3DAL(CVPR2021 Qi stay waymo Proposed offboard test method ), But in pedestrian detection , The test results are better than 200 The frame of 3DAL also 1 A point of improvement , It still shows SST Performance advantages in small target detection .

The following figure shows the query feature of powder points , The attention weight corresponding to other features around it . The weight is high to low, and the color changes from red to blue . It can be seen that the high attention weight is highly correlated with the corresponding object .

Finally, some discussions and thoughts shared by the original author are attached
honestly ,SST There are still many limitations and improvements , We are also trying some of them :
- It directly uses the original multi-head attention, The amount of calculation is really not small , But now with ViT This wave of heat , There's a lot of attention Method of acceleration , This point deserves further improvement . Others are stronger attention trick It may also be worth trying , For example, it is used in many jobs cosine similarity To replace dot product, And relative position coding (RPE) etc. .
- Will it be more cost-effective to conduct some mild down sampling ? The exploration on this point also involves sparse data How to do “ correct ” The problem of down sampling . For example, in a 2*2 In the field of , According to whether there is a value in each position, there will be 15 Patterns , This sum dense feature Upper token merge It's different . How do I feel better merge Sparse voxels in the neighborhood are still a open problem. About Sparsity Further discussion of , If you are interested, you can see the third section .
- Transformer It is a sharp weapon of multimodality , Maybe combined with the image of killing all sides Swin Can make LiDAR and image Better fusion.
- Can we learn from it transformer in decoder In the form of sparse attention Further achieve head Up ( Similar to introducing object query)? The overall structure seems to be much more beautiful .
- SST Of detection head Directly followed PointPillars The more primitive anchor-based head. Change some stronger head, Add some extra branch( such as IoU score The forecast ) In theory, it would be better .
- In recent years LiDAR detection There are endless two-stage methods , The combination with these methods may also be a sharp weapon for rising points .
If you want to try the above improvement ideas or have better ideas , Welcome to our codebase A shuttle , Welcome to communicate and discuss with us .
边栏推荐
- 2021.12.16-2021.12.20 empty four hand transaction records
- ZABBIX monitors mongodb (template and deployment operations)
- DNS的原理介绍
- Summary of C language learning problems (VS)
- Principle of universal gbase high availability synchronization tool in Nanjing University
- ActiveMQ installation and deployment simple configuration (personal test)
- Learn the garbage collector of JVM -- a brief introduction to Shenandoah collector
- Resnet18 actual battle Baoke dream spirit
- Transactions from December 29, 2021 to January 4, 2022
- Learn the memory management of JVM 03 - Method area and meta space of JVM
猜你喜欢
About LDA model
Taobao, pinduoduo, jd.com, Doudian order & Flag insertion remarks API solution
UNIX socket advanced learning diary -ipv4-ipv6 interoperability

Pytoch uses torchnet Classerrormeter in meter
实战模拟│JWT 登录认证
Knowledge representation (KR)
Yum only downloads the RPM package of the software to the specified directory without installing it
SAP 自开发记录用户登录日志等信息
ZABBIX customized monitoring disk IO performance
Taobao flag insertion remarks | logistics delivery interface
随机推荐
在家庭智能照明中应用的测距传感芯片4530A
超高效!Swagger-Yapi的秘密
JDBC -- use JDBC connection to operate MySQL database
Learning JVM garbage collection 06 - memory set and card table (hotspot)
Neural network of PRML reading notes (1)
从39个kaggle竞赛中总结出来的图像分割的Tips和Tricks
Taobao, pinduoduo, jd.com, Doudian order & Flag insertion remarks API solution
Learn the memory management of JVM 03 - Method area and meta space of JVM
Anaconda creates a virtual environment and installs pytorch
Migrate data from Mysql to neo4j database
Leetcode-1. Sum of two numbers (Application of hash table)
Interviewer: is acid fully guaranteed for redis transactions?
ActiveMQ installation and deployment simple configuration (personal test)
About LDA model
Sqoop import and export operation
Learn JVM garbage collection 05 - root node enumeration, security points, and security zones (hotspot)
上午面了个腾讯拿 38K 出来的,让我见识到了基础的天花
NLP engineer learning summary and index
C language structure is initialized as a function parameter
Keras implements verification code identification