当前位置:网站首页>Spark 3.0 DPP implementation logic
Spark 3.0 DPP implementation logic
2022-07-27 15:38:00 【wankunde】
Preparing the test environment
Test data and tests SQL
import spark.implicits._
import java.time.LocalDateTime
import java.time.format.DateTimeFormatter
import java.sql.Timestamp
spark.range(-1000, 1000).map {
id =>
val dt = Timestamp.valueOf(LocalDateTime.now.plusDays(id))
val dt_str = LocalDateTime.now.plusDays(id).format(DateTimeFormatter.ofPattern("yyyyMMdd"))
val dt_int = dt_str.toInt
(id.toInt, dt, dt_str, dt_int)
}.toDF("id", "dt", "dt_str", "dt_int")
.createOrReplaceTempView("tab")
spark.sql(
s"""create table dim_date (
| id int,
| dt timestamp,
| dt_str string,
| dt_int int
|)
|stored as parquet;
|""".stripMargin)
spark.sql("insert overwrite table dim_date select * from tab")
spark.sql(s"""select *
|from test_table t1
|join (
| select dt_str
| from dim_date
| where dt_int = 20201116
|) t2
|on t1.dt = t2.dt_str
|limit 1000
|""".stripMargin).show(10, false)
SQL Plan

The source code walkthrough
Pass above SQL As can be seen from the implementation plan of ,DPP The optimization of mainly occurs in Optimizer Optimization and Physical Plan Generate two stages . Next, analyze the main code of the implementation .
PartitionPruning Logical planning optimization
PartitionPruning Rule The optimization result is that DPP Of relation Replace with Filter(DynamicPruningSubquery(..), pruningPlan) object .
One of them is for canPruneLeft() and canPruneRight() The logic of judgment should be explained :
| JOIN type | canPruneLeft | canPruneRight | Logical explanation | |
|---|---|---|---|---|
| INNER JOIN: | TRUE | TRUE | Both sides support partition filtering , That's all right. | |
| LEFT OUTER JOIN | FALSE | TRUE | here Left table The data is complete ,Right Table It's incomplete , So only Broadcast Left table, And then according to Left Table The result of going to Prune Right Table Partition; conversely ,Broadcast Right table Come on Left Table Prune When , It can lead to Left Table Reading data causes data loss . | |
| RIGHT OUTER JOIN | TRUE | FALSE | The opposite of the above , Can only Prune Left Table | |
| LEFT SIME JOIN | TRUE | FALSE | This is also a requirement Right Table The data is complete , For convenience Left Table do Exists Judge , So it's equivalent to RIGHT OUTER JOIN |
object PartitionPruning extends Rule[LogicalPlan] with PredicateHelper {
/** * Search the partitioned table scan for a given partition column in a logical plan */
def getPartitionTableScan(a: Expression, plan: LogicalPlan): Option[LogicalRelation] = {
// Iterative search plan From node , return a and a Attributes come from leafNode
val srcInfo: Option[(Expression, LogicalPlan)] = findExpressionAndTrackLineageDown(a, plan)
// leafNode If it is LogicalRelation(fs: HadoopFsRelation, _), take fs All partition fields of
// If a The attribute of is a subset of the partition field , return leafNode, Otherwise return to None
srcInfo.flatMap {
case (resExp, l: LogicalRelation) =>
l.relation match {
case fs: HadoopFsRelation =>
val partitionColumns = AttributeSet(
l.resolve(fs.partitionSchema, fs.sparkSession.sessionState.analyzer.resolver))
if (resExp.references.subsetOf(partitionColumns)) {
return Some(l)
} else {
None
}
case _ => None
}
case _ => None
}
}
/** * {
{
{ Specifically responsible for inserting DPP Filter}}} */
private def insertPredicate(
pruningKey: Expression,
pruningPlan: LogicalPlan,
filteringKey: Expression,
filteringPlan: LogicalPlan,
joinKeys: Seq[Expression],
hasBenefit: Boolean): LogicalPlan = {
val reuseEnabled = SQLConf.get.exchangeReuseEnabled
val index = joinKeys.indexOf(filteringKey)
if (hasBenefit || reuseEnabled) {
// insert a DynamicPruning wrapper to identify the subquery during query planning
Filter(
DynamicPruningSubquery(
pruningKey,
filteringPlan,
joinKeys,
index,
!hasBenefit || SQLConf.get.dynamicPartitionPruningReuseBroadcastOnly),
pruningPlan)
} else {
// abort dynamic partition pruning
pruningPlan
}
}
/** * Mainly through CBO analysis , It's going on prune Whether the cost after optimization is sufficient , The threshold is not met , Then it is forbidden to push down the partition */
private def pruningHasBenefit(
partExpr: Expression,
partPlan: LogicalPlan,
otherExpr: Expression,
otherPlan: LogicalPlan): Boolean = {
}
private def prune(plan: LogicalPlan): LogicalPlan = {
plan transformUp {
// skip this rule if there's already a DPP subquery on the LHS of a join
// 1. skip Already exist DPP Of join
case j @ Join(Filter(_: DynamicPruningSubquery, _), _, _, _, _) => j
case j @ Join(_, Filter(_: DynamicPruningSubquery, _), _, _, _) => j
case j @ Join(left, right, joinType, Some(condition), hint) =>
var newLeft = left
var newRight = right
// extract the left and right keys of the join condition
// 2. It is concluded that join Conditions of the keys
val (leftKeys, rightKeys) = j match {
case ExtractEquiJoinKeys(_, lkeys, rkeys, _, _, _, _) => (lkeys, rkeys)
case _ => (Nil, Nil)
}
// checks if two expressions are on opposite sides of the join
def fromDifferentSides(x: Expression, y: Expression): Boolean = {
def fromLeftRight(x: Expression, y: Expression) =
!x.references.isEmpty && x.references.subsetOf(left.outputSet) &&
!y.references.isEmpty && y.references.subsetOf(right.outputSet)
fromLeftRight(x, y) || fromLeftRight(y, x)
}
// take join In the condition of AND Split into Seq[Expression], Then iterate through each join condition expression
splitConjunctivePredicates(condition).foreach {
// Filter Expression: EqualTo Condition type and EqualTo The properties on both sides of belong to join Left and right watches
case EqualTo(a: Expression, b: Expression)
if fromDifferentSides(a, b) =>
val (l, r) = if (a.references.subsetOf(left.outputSet) &&
b.references.subsetOf(right.outputSet)) {
a -> b
} else {
b -> a
}
// there should be a partitioned table and a filter on the dimension table,
// otherwise the pruning will not trigger
// partScan On the basis of join Obtained by conditional parsing leafNode, That is, partition table Relation object
var partScan = getPartitionTableScan(l, left)
if (partScan.isDefined && canPruneLeft(joinType) &&
hasPartitionPruningFilter(right)) {
val hasBenefit = pruningHasBenefit(l, partScan.get, r, right)
newLeft = insertPredicate(l, newLeft, r, right, rightKeys, hasBenefit)
} else {
partScan = getPartitionTableScan(r, right)
if (partScan.isDefined && canPruneRight(joinType) &&
hasPartitionPruningFilter(left) ) {
val hasBenefit = pruningHasBenefit(r, partScan.get, l, left)
newRight = insertPredicate(r, newRight, l, left, leftKeys, hasBenefit)
}
}
case _ =>
}
Join(newLeft, newRight, joinType, Some(condition), hint)
}
}
}
PlanDynamicPruningFilters Physical plan generation
Data processing main logic :
- case DynamicPruningSubquery
- If at present Plan in BroadcastHashJoinExec, And BroadcastHashJoinExec Of build side It's up there buildPlan, canReuseExchange = true
- establish BroadcastExchangeExec(mode, QueryExecution.prepareExecutedPlan(sparkSession, QueryExecution.createSparkPlan(buildPlan))) object
- establish InSubqueryExec(value, broadcastValues, exprId) object
case class PlanDynamicPruningFilters(sparkSession: SparkSession)
extends Rule[SparkPlan] with PredicateHelper {
/** * Identify the shape in which keys of a given plan are broadcasted. */
private def broadcastMode(keys: Seq[Expression], plan: LogicalPlan): BroadcastMode = {
val packedKeys = BindReferences.bindReferences(HashJoin.rewriteKeyExpr(keys), plan.output)
HashedRelationBroadcastMode(packedKeys)
}
/** * {
{
{ * Data processing logic : * 1. case DynamicPruningSubquery * 2. If at present Plan in BroadcastHashJoinExec, And BroadcastHashJoinExec Of build side It's up there buildPlan, canReuseExchange = true * 3. establish BroadcastExchangeExec(mode, QueryExecution.prepareExecutedPlan(sparkSession, QueryExecution.createSparkPlan(buildPlan))) object * 4. establish InSubqueryExec(value, broadcastValues, exprId) object * }}} */
override def apply(plan: SparkPlan): SparkPlan = {
if (!SQLConf.get.dynamicPartitionPruningEnabled) {
return plan
}
plan transformAllExpressions {
case DynamicPruningSubquery(
value, buildPlan, buildKeys, broadcastKeyIndex, onlyInBroadcast, exprId) =>
val sparkPlan = QueryExecution.createSparkPlan(
sparkSession, sparkSession.sessionState.planner, buildPlan)
// Using `sparkPlan` is a little hacky as it is based on the assumption that this rule is
// the first to be applied (apart from `InsertAdaptiveSparkPlan`).
val canReuseExchange = SQLConf.get.exchangeReuseEnabled && buildKeys.nonEmpty &&
plan.find {
case BroadcastHashJoinExec(_, _, _, BuildLeft, _, left, _) =>
left.sameResult(sparkPlan)
case BroadcastHashJoinExec(_, _, _, BuildRight, _, _, right) =>
right.sameResult(sparkPlan)
case _ => false
}.isDefined
if (canReuseExchange) {
val mode = broadcastMode(buildKeys, buildPlan)
val executedPlan = QueryExecution.prepareExecutedPlan(sparkSession, sparkPlan)
// plan a broadcast exchange of the build side of the join
val exchange = BroadcastExchangeExec(mode, executedPlan)
val name = s"dynamicpruning#${exprId.id}"
// place the broadcast adaptor for reusing the broadcast results on the probe side
val broadcastValues =
SubqueryBroadcastExec(name, broadcastKeyIndex, buildKeys, exchange)
DynamicPruningExpression(InSubqueryExec(value, broadcastValues, exprId))
} else if (onlyInBroadcast) {
// it is not worthwhile to execute the query, so we fall-back to a true literal
DynamicPruningExpression(Literal.TrueLiteral)
} else {
// we need to apply an aggregate on the buildPlan in order to be column pruned
val alias = Alias(buildKeys(broadcastKeyIndex), buildKeys(broadcastKeyIndex).toString)()
val aggregate = Aggregate(Seq(alias), Seq(alias), buildPlan)
DynamicPruningExpression(expressions.InSubquery(
Seq(value), ListQuery(aggregate, childOutputs = aggregate.output)))
}
}
}
}
Physical execution plan
We from FileSourceScanExec Of def doExecute(): RDD[InternalRow] The method looks good
- In execution
execute()Before method ,SparkPlan Will wait for all subquery Execution andupdateResult(). about DPP Of subqueryInSubqueryExecWill subquery Result collect, Again broadcast get out , return broadcast References toresultBroadcast - The return object depends on the internal
inputRDDobject inputRDDfromcreateReadRDD()establish , It is mainly divided into two parts , First, determine which files to read , Including partition filtering ,Bucket Processing and third-party file processing plug-ins ; The second is to determine the method of reading documentsreadFile- Partial function
val readFile: (PartitionedFile) => Iterator[InternalRow]according to relation Of fileFormat Create a method to read files ( This is for ORC and Parquet There are also special treatments ), Including the parametersfilters = pushedDownFilters ++ dynamicPushedFilters - dynamicPushedFilters yes lazy object , In practice Executor perform Task When , Will execute
readFile()Method , aboutDynamicPruningExpressionexample , Will execute firstchild.predicate()Method , This method will read broadcast The data of , Store inresultIn the object , Then return according to the resultinSetobject - Inset The object is a big set, In execution
def eval(input: InternalRow): Anyanddef doGenCode(ctx: CodegenContext, ev: ExprCode)When , Based on the incoming row data , To set To determine whether the data exists , Achieve the effect of filtering data
@transient
private lazy val dynamicPushedFilters = {
dataFilters.flatMap {
case DynamicPruningExpression(child: InSubqueryExec) => Some(child.predicate)
case _ => Nil
}.flatMap(DataSourceStrategy.translateFilter(_, supportNestedPredicatePushdown))
}
abstract class SparkPlan extends QueryPlan[SparkPlan] with Logging with Serializable {
/** * Executes a query after preparing the query and adding query plan information to created RDDs * for visualization. */
protected final def executeQuery[T](query: => T): T = {
RDDOperationScope.withScope(sparkContext, nodeName, false, true) {
prepare()
waitForSubqueries()
query
}
}
/** * Blocks the thread until all subqueries finish evaluation and update the results. */
protected def waitForSubqueries(): Unit = synchronized {
// fill in the result of subqueries
runningSubqueries.foreach {
sub =>
sub.updateResult()
}
runningSubqueries.clear()
}
}
case class InSubqueryExec(
child: Expression,
plan: BaseSubqueryExec,
exprId: ExprId,
private var resultBroadcast: Broadcast[Set[Any]] = null) extends ExecSubqueryExpression {
@transient private var result: Set[Any] = _
@transient private lazy val inSet = InSet(child, result)
def updateResult(): Unit = {
val rows = plan.executeCollect()
result = rows.map(_.get(0, child.dataType)).toSet
resultBroadcast = plan.sqlContext.sparkContext.broadcast(result)
}
def predicate: Predicate = {
prepareResult()
inSet
}
private def prepareResult(): Unit = {
require(resultBroadcast != null, s"$this has not finished")
if (result == null) {
result = resultBroadcast.value
}
}
}
case class InSet(child: Expression, hset: Set[Any]) extends UnaryExpression with Predicate {
protected override def nullSafeEval(value: Any): Any = {
if (set.contains(value)) {
true
} else if (hasNull) {
null
} else {
false
}
}
}
边栏推荐
- [daily question 1] 558. Intersection of quadtrees
- C语言:数据的存储
- 【剑指offer】面试题56-Ⅰ:数组中数字出现的次数Ⅰ
- Leetcode 240. search two-dimensional matrix II medium
- shell脚本读取文本中的redis命令批量插入redis
- 股票开户佣金优惠,炒股开户哪家证券公司好网上开户安全吗
- 直接插入排序
- 【剑指offer】面试题39:数组中出现次数超过一半的数字
- Network equipment hard core technology insider router Chapter 3 Jia Baoyu sleepwalking in Taixu Fantasy (middle)
- EMC design scheme of CAN bus
猜你喜欢

【剑指offer】面试题49:丑数

Summer Challenge harmonyos realizes a hand-painted board

Pictures to be delivered

HaoChen CAD building 2022 software installation package download and installation tutorial

Spark TroubleShooting整理
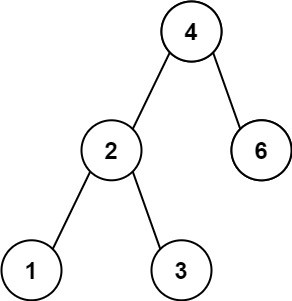
Leetcode 783. binary search tree node minimum distance tree /easy

md 中超链接的解析问题:解析`this.$set()`,`$`前要加空格或转义符 `\`

QT (IV) mixed development using code and UI files

初识结构体

QT (five) meta object properties
随机推荐
Hyperlink parsing in MD: parsing `this$ Set() `, ` $` should be preceded by a space or escape character`\`
直接插入排序
Is it safe to open an account on a mobile phone?
Leetcode 781. rabbit hash table in forest / mathematical problem medium
Leetcode 341. flattened nested list iterator DFS, stack / medium
C语言:扫雷小游戏
[正则表达式] 匹配多个字符
Network equipment hard core technology insider router Chapter 4 Jia Baoyu sleepwalking in Taixu Fantasy (Part 2)
JS find the maximum and minimum values in the array (math.max() method)
Spark 3.0 测试与使用
Overview of wechat public platform development
Google team launches new transformer to optimize panoramic segmentation scheme CVPR 2022
MLX90640 红外热成像仪测温传感器模块开发笔记(七)
Analysis of spark task scheduling exceptions
Multi table query_ Exercise 1 & Exercise 2 & Exercise 3
扩展Log4j支持日志文件根据时间分割文件和过期文件自动删除功能
js使用一元运算符简化字符串转数字
Explanation of various attributes of "router link"
C language: factorial recursive implementation of numbers
$router.back(-1)