当前位置:网站首页>开源一夏 | 查询分页不只有limit,这四种分页方法值得掌握
开源一夏 | 查询分页不只有limit,这四种分页方法值得掌握
2022-08-04 09:06:00 【InfoQ】
- 由于前端在页面显示数据时,希望每个页面只显示指定条数的数据,由于数据量较大,不能够一次性展示,所以就通过限制每个页面固定的条数进行展示。
- 如果数据量较大的话,页面也不一定加载完全,所以造成效率比较差,所以解决方案分页查询就可以很好的解决这个问题了,通过把庞大的数据按照固定的数目显示,在通过上一页或下一页的按钮显示其它的数据。
limit的传统方式
- 如果是一个参数,如limit 10,则表示默认从开始位置开始获取10条数据。
- 如果是两个参数,第一个参数指定的是返回行数的开始位置,第二个参数指定的是返回记录行的数目。Eg: select * from user limit 0,10表示从第0个位置开始获取10条数据。
PageHelper插件的方式
- 引入依赖
<!-- pagehelper -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper-spring-boot-starter</artifactId>
<version>${pagehelper.version}</version>
</dependency>
- 使用代码注意
PageHelper.startPage(pageNo, pageSize)
PageResult<List<Employee>> result = new PageResult<>();
//就是下边的这个地方,使用了 pageNo是offset就是开始位置的偏移量,第二个参数pageSize是查询返回的数据的条数
PageHelper.startPage(pageNo, pageSize);
try {
List<Employee> employeeList = employeeService.findAll();
PageInfo<Employee> pageInfo = new PageInfo<>(employeeList);
log.info(String.valueOf(employeeList));
result.setTotal(pageInfo.getTotal());
result.setPages(pageInfo.getPages());
result.setCurrent(pageInfo.getPageNum());
result.setSize(pageInfo.getPageSize());
result.setResult(employeeList);
result.success("查询成功!");
}
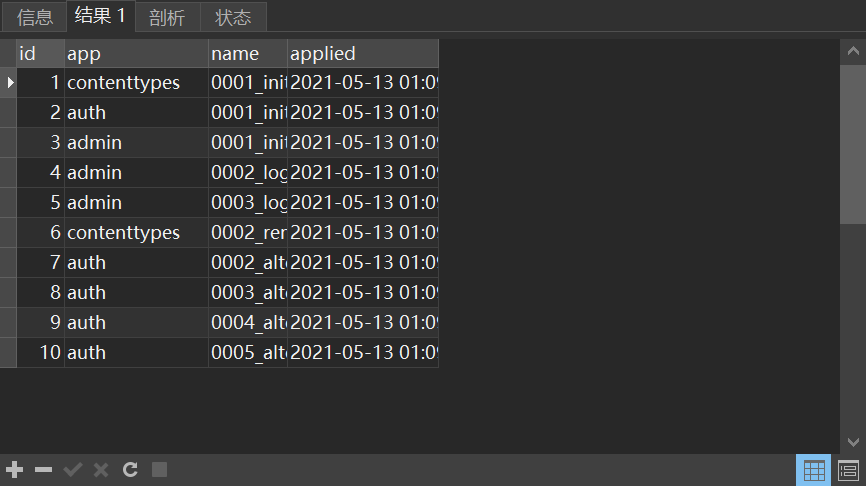
- 查询结果
自定义Interceptor的方式
RowsBounds方式
service层:
RowBounds rowbounds = new RowBounds(offset, Integer.parseInt(pageSize));
//用户数据集合
List<Map<String, Object>> userList = userDao.queryUserList(rowbounds);
Dao层:
public List<Map<String, Object>> queryUserList(RowBounds rowbounds);
mapperxml层:
<!-- 查询用户列表 -->
<select id="queryUserList" resultType="java.util.Map">
select * from user
</select>
总结
边栏推荐
猜你喜欢
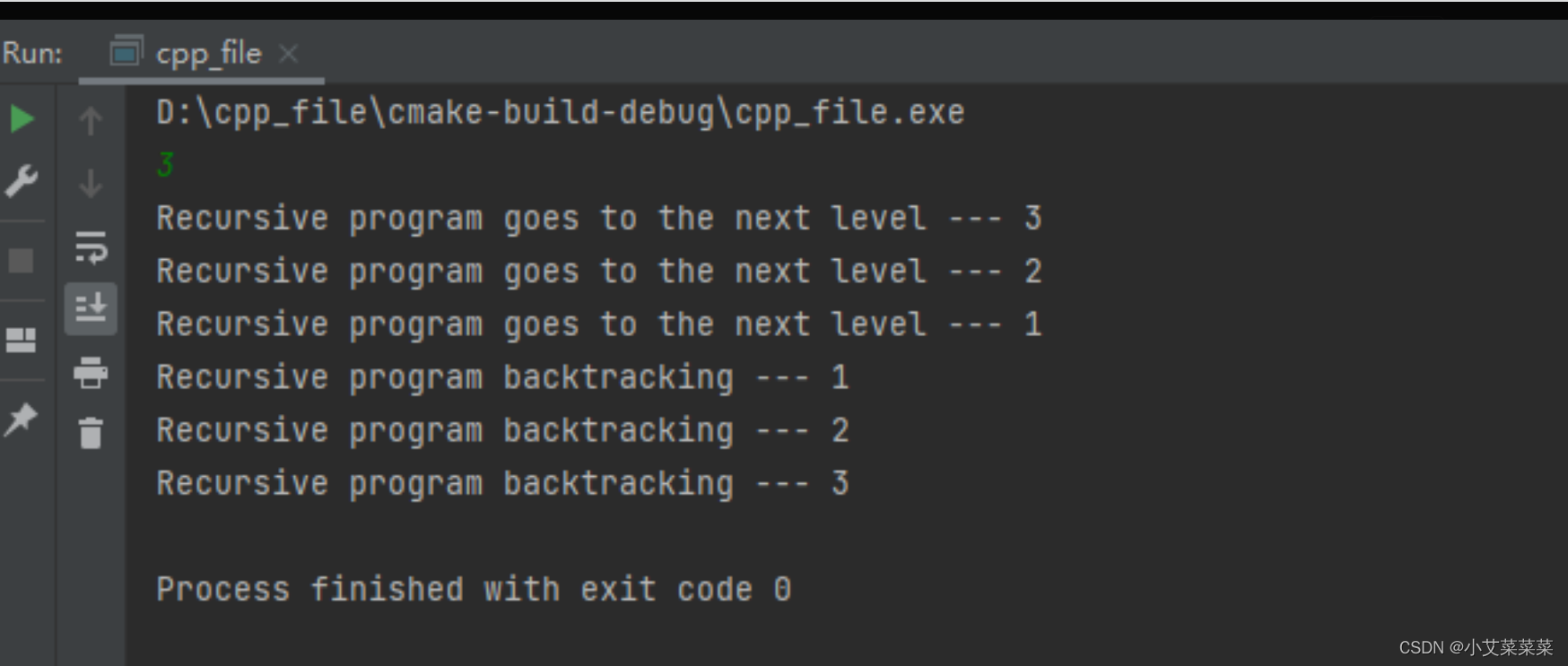
递归思想

从零开始的tensorflow小白使用指北

蜜芽CEO刘楠:垂直电商黄金时代已落幕 坚定转型品牌之路

Anton Paar安东帕密度计比重计维修DMA35性能参数
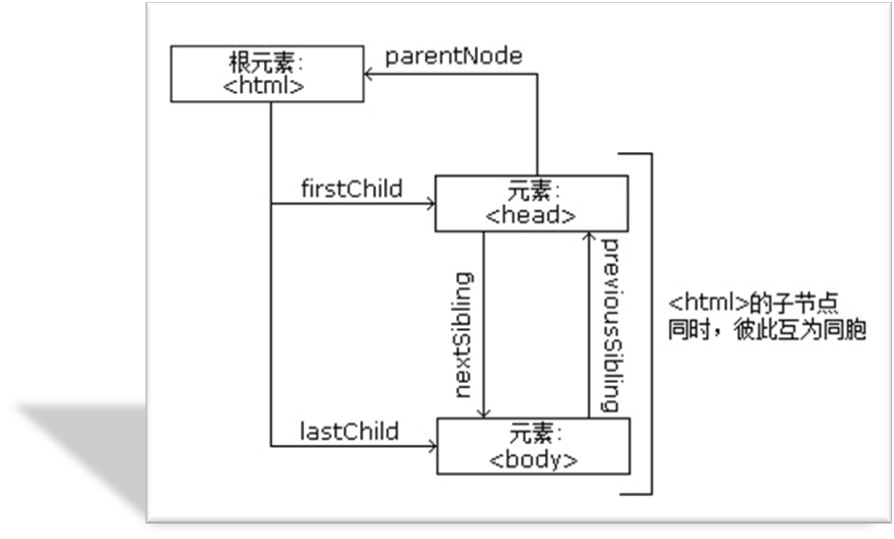
DOM简述
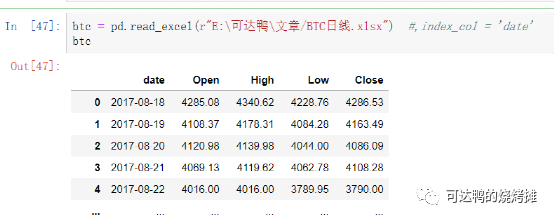
加降息与BTC流动性事件策略研究
TiDB升级与案例分享(TiDB v4.0.1 → v5.4.1)
【正点原子STM32连载】第三章 开发环境搭建 摘自【正点原子】MiniPro STM32H750 开发指南_V1.1
cannot import name ‘import_string‘ from ‘werkzeug‘【bug解决】
Interview at 14:00 in the afternoon, I came out at 14:08 with my head down, asking too much...
随机推荐
MindSpore:mirrorpad算子速度过慢的问题
Oracle怎么获取当前库或者同一台服务器上某几个库的数据总行数?
华为od项目
注意力机制
OAK-FFC-4P全网首次测试
他97年的,我既然卷不过他...
MindSpore:【mindinsight】【Profiler】用execution_time推导出来的训练耗时远小于真实的耗时
记录十条工作中便利的API小技巧
Wang Shuang's Assembly Language Chapter 4: The First Program
About Oracle RAC 11g rebuilding the disk group
[Punctuality Atom STM32 Serial] Chapter 3 Development Environment Construction Excerpted from [Punctual Atom] MiniPro STM32H750 Development Guide_V1.1
Detailed explanation of MSTP protocol configuration on Layer 3 switches [Huawei eNSP experiment]
Producer and Consumer Problems in Concurrent Programming
请你谈谈网站是如何进行访问的?【web领域面试题】
Quick tips for getting out of a single
oracle sql multi-table query
telnet远程登录aaa模式详解【华为eNSP】
Shared_preload_libraries导致很多语法不支持
Apache Druid 实时分析数据库入门介绍
2022年化工自动化控制仪表考试模拟100题及模拟考试