当前位置:网站首页>After the deployment is created, the pod problem handling cannot be created
After the deployment is created, the pod problem handling cannot be created
2022-06-27 13:11:00 【51CTO】
Problem description
I installed it in binary kubernetes Cluster deployment Ingress During the service , Use yaml file apply Create corresponding resources Deployment In the process , Never seen Pod To be created .
[[email protected] Install]
# kubectl apply -f ingress-nginx-controller.yaml
deployment.apps/default-http-backend created
service/default-http-backend created
serviceaccount/nginx-ingress-serviceaccount created
clusterrole.rbac.authorization.k8s.io/nginx-ingress-clusterrole created
role.rbac.authorization.k8s.io/nginx-ingress-role created
clusterrolebinding.rbac.authorization.k8s.io/nginx-ingress-clusterrole-nisa-binding created
deployment.apps/nginx-ingress-controller created
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.


Treatment process
see Deployment Details of
[[email protected] Install]
# kubectl -n kube-system describe deployments.apps nginx-ingress-controller
- 1.
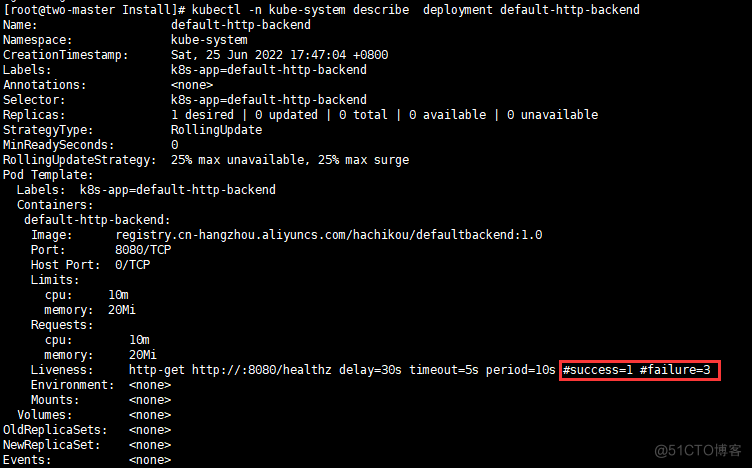
Not getting valuable information .
see kube-controller-manager Service status
[[email protected] Install]
# systemctl status kube-controller-manager.service
......
6 month
25
18:54:54 two-master kube-controller-manager[759]: E0625
18:54:54.563462
759 leaderelection.go:325] error retrieving resource lo...nager)
- 1.
- 2.
- 3.

It can be seen that kube-controller-manager There is a problem with the service status .
- Keep looking at kube-controller-manager Detailed error reporting information of the service
[[email protected] Install]
# systemctl status kube-controller-manager.service > kube-controller.log
[[email protected] Install]
# vim + kube-controller.log # Export to log file , Convenient view
known reason (get leases.coordination.k8s.io kube-controller-manager)
6 month
25
19:10:25 two-master kube-controller-manager[759]: E0625
19:10:25.198986
759 leaderelection.go:325]
error retrieving resource lock kube-system/kube-controller-manager:
the server rejected our request
for an unknown reason (get leases.coordination.k8s.io kube-controller-manager)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.

Get effective error reporting information :
known reason (get leases.coordination.k8s.io kube-controller-manager)
6 month
25
19:10:25 two-master kube-controller-manager[759]: E0625
19:10:25.198986
759 leaderelection.go:325] error retrieving resource lock kube-system/kube-controller-manager: the server rejected our request
for an unknown reason (get leases.coordination.k8s.io kube-controller-manager)
- 1.
- 2.
Baidu translation :

Meaning :
Retrieve resource locks kube-system/kube-controller-manager error : The server rejected our request for an unknown reason (get leaves.coordination.k8s.io kube Controller manager )
see etcd Cluster status and alarm information
Copy the error information to Baidu search , Some say it is etcd Cluster problem , So check my etcd If there is something wrong .
my kubernetes Just one master、2 individual node.
- see etcd Whether the state is normal
[[email protected] Install]
# etcdctl endpoint health --endpoints=https://192.168.2.70:2379 \
>
--write
-out
=table \
>
--cacert
=/etc/kubernetes/pki/etcd/ca.pem \
>
--cert
=/etc/kubernetes/pki/etcd/etcd.pem \
>
--key
=/etc/kubernetes/pki/etcd/etcd-key.pem
+
--
--
--
--
--
--
--
--
--
--
--
--
--
-
+
--
--
--
--
+
--
--
--
--
--
--
+
--
--
--
-
+
| ENDPOINT | HEALTH | TOOK | ERROR |
+
--
--
--
--
--
--
--
--
--
--
--
--
--
-
+
--
--
--
--
+
--
--
--
--
--
--
+
--
--
--
-
+
| https://192.168.2.70:2379 |
true |
4.965087ms | |
+
--
--
--
--
--
--
--
--
--
--
--
--
--
-
+
--
--
--
--
+
--
--
--
--
--
--
+
--
--
--
-
+
# normal , No report error
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- see etcd The alarm information
[[email protected] Install]
# etcdctl --endpoints 192.168.2.70:2379 alarm list \
>
--cacert
=/etc/kubernetes/pki/etcd/ca.pem \
>
--cert
=/etc/kubernetes/pki/etcd/etcd.pem \
>
--key
=/etc/kubernetes/pki/etcd/etcd-key.pem
- 1.
- 2.
- 3.
- 4.

No alarm information ,etcd normal , The cause of the problem has not been found yet .
restart kube-controller-manager service
Try restarting the Dharma .

[[email protected] ~]
# systemctl restart kube-controller-manager.service
[[email protected] ~]
# systemctl status kube-controller-manager.service
- 1.
- 2.

The service is still abnormal .
View resource locks
leases Is a lightweight resource lock , Used to replace the old version of configmap and endpoints, We use kubectl get lease kube-controller-manager -n kube-system -o yaml The command can see the following yaml.
$ kubectl
get lease kube-controller-manager
-n kube-system
-o yaml
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
creationTimestamp:
"2022-06-08T07:52:17Z"
managedFields:
- apiVersion: coordination.k8s.io/v1
fieldsType: FieldsV1
fieldsV1:
f:spec:
f:acquireTime: {}
f:holderIdentity: {}
f:leaseDurationSeconds: {}
f:leaseTransitions: {}
f:renewTime: {}
manager: kube-controller-manager
operation: Update
time:
"2022-06-08T07:52:17Z"
name: kube-controller-manager
namespace: kube-system
resourceVersion:
"977951"
uid: 758e5b3d-422f-4254-9839-3581f532b7e5
spec:
acquireTime:
"2022-06-24T02:08:11.905250Z"
holderIdentity: two-master_f1deccfa-7a21-4b6c-97b6-611eaaff083c
leaseDurationSeconds:
15
leaseTransitions:
7
renewTime:
"2022-06-24T03:01:34.576989Z"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
The resource records which instance holds the resource , Time for renewal of tenure , Information such as the time when the lock was obtained .
- LeaseDuration: Time to hold lock , Indicates the duration of the term , Others during this time LeaderElector The client cannot get leader Position , Even if the current leader Not working properly .
- RenewDeadline: Update the holding time of the lock , This field is only for leader take effect , Used to refresh leaseDuration The duration of his term of office , Retry refreshing the leader's time before giving up .RenewDeadline Must be less than LeaseDuration.
- RetryPeriod: Retry time , Every LeaderElector Retry time of the client , Used to try to be leader.
- Callbacks: Every time leader Or lose leader Call back functions when you need to .
Request resource lock
[[email protected] ~]
# curl -X GET https://192.168.2.70:6443/apis/coordination.k8s.io/v1/namespaces/kube-system/leases/kube-controller-manager -k
{
"kind":
"Status",
"apiVersion":
"v1",
"metadata": {
},
"status":
"Failure",
"message":
"Unauthorized",
"reason":
"Unauthorized",
"code":
401
# return 401 abnormal ,
}[[email protected] ~]
#
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
Add :
After investigation, it was found that /etc/kubernetes/kube-controller-manager.conf The file has been added to kube-apiserver Parameters of , After deleting this parameter and restarting the service, it is normal .

边栏推荐
- Openfeign service interface call
- Centos7命令行安装Oracle11g
- [tcaplusdb knowledge base] Introduction to tcaplusdb tcapulogmgr tool (I)
- Cool in summer
- Pyqt, pyside slot functions are executed twice
- ThreadLocal 源码全详解(ThreadLocalMap)
- The browser enters the URL address, and what happens to the page rendering
- zabbix支持钉钉报警
- Industry insight - how should brand e-commerce reshape growth under the new retail format?
- Record number of visits yesterday
猜你喜欢








随机推荐
scrapy
LeetCode_ Fast power_ Recursion_ Medium_ 50.Pow(x, n)
Record number of visits yesterday
【周赛复盘】LeetCode第81场双周赛
栈的计算(入栈出栈顺序是否合法)-代码
ThreadLocal 源码全详解(ThreadLocalMap)
Infiltration learning diary day20
阿里一个面试题:使用两个线程,交替输出字母和数字
这是什么空调?
Esp32s3 iperf routine test esp32s3 throughput test
Hue new account error reporting solution
本地可视化工具连接阿里云centOS服务器的redis
Airbnb double disk microservice
内网学习笔记(8)
Neo4j: basic introduction (I) installation and use
如何修改 node_modules 里的文件
printf不定长参数原理
Vs debugging skills
Prometheus 2.26.0 新特性
Summary of redis master-slave replication principle