当前位置:网站首页>基于YOLOv1的口罩佩戴检测
基于YOLOv1的口罩佩戴检测
2022-07-04 12:50:00 【小段学长】
摘 要
近些年来,目标检测算法取得了很大的突破。比较流行的算法可以分为两类,一类是基于 Region Proposal 的 R-CNN 系算法(R-CNN,Fast R-CNN, Faster R-CNN),它们是 two-stage 的,需要先使用启发式方法(selective search)或者 CNN 网络(RPN)产生 Region Proposal,然后再在 Region Proposal 上做分类与回归。而另一类是 Yolo、SSD 这类 one-stage 算法,其仅仅使用一个 CNN 网络直接预测不同目标的类别与位置。第一类方法准确度高一些,但是速度慢;第二类算法速度快,但是准确性要低一些。本文介绍的 Yolo 算法,其全称是 You Only Look Once: Unified, Real-Time Object Detection。这个题目基本上把 Yolo 算法的特点概括了:You Only Look Once 指的是只需要一次 CNN 运算;Unified 指的是这是一个统一的框架,提供 end-to-end 的预测;而 Real-Time 体现 Yolo 算法速度快。
关键词 图像分类;口罩检测;YOLOv1;特征学习;预训练
引言
2019 新冠肺炎疫情爆发,让人们的出行发生了很大的变化——自 1 月 24 日武汉宣布封城之后,各省市陆续启动重大突发公共卫生事件一级响应以控制人口流动。很多城市都已规定必须佩戴口罩、测量体温才能搭乘公共交通。2 月 10 号返工日之前,上海、北京等重点城市也陆续放出新规:出入机场、轨道交通、长途汽车站、医疗卫生机构、商场超市等公共场所,未佩戴口罩者将被劝阻。
2 月 13 日,百度飞桨宣布开源业界首个口罩人脸检测及分类模型。基于此模型,可以在公共场景检测大量的人脸同时,把佩戴口罩和未佩戴口罩的人脸标注出来,快速识别各类场景中不重视、不注意防护病毒,甚至存在侥幸心理的人,减少公众场合下的安全隐患。同时构建更多的防疫公益应用。
设计理念
整体来看,Yolo 算法采用一个单独的 CNN 模型实现 end-to-end 的目标检测,整个系统如上图所示:首先将输入图片 resize 到 448 × 448 448 \times 448 448×448,然后送入 CNN 网络,最后处理网络预测结果得到检测的目标。相比 R-CNN 算法是一个统一的框架,其速度更快,而且 Yolo 的训练过程也是 end-to-end 的。
系统将输入图像划分为 S × S S \times S S×S 网格。 如果一个目标的中心落入网格单元,则该网格单元负责检测该目标。每个网格单元预测 B B B 个 bounding box 和 box 的置信度得分。 这些置信度得分反映了该模型对盒子包含一个对象的信心,以及它认为盒子预测的准确性。 形式上,我们将置信度定义为 P r ( O b j e c t ) × I O U Pr(Object)\times IOU Pr(Object)×IOU, I O U IOU IOU 指 intersection over union between the predicted box and the ground truth。 如果该单元格中没有预测对象,则置信度应为零;否则置信度等于 I O U IOU IOU。每个 bounding box 由 5 5 5个预测组成: x x x, y y y, w w w, h h h和置信度。 x , y x, y x,y 表示 bounding box 相对于网格单元边界的中心; w , h w, h w,h 相对于整个图像预测宽度和高度;最后,置信度表示预测框与真实框之间的 I O U IOU IOU。
每个网格单元还预测$ C $个条件类概率 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i | Object) Pr(Classi∣Object)。 这些概率以网格单元包含检测对象为条件。 无论 B 的数量如何,仅预测每个网格单元的一组类概率。 在测试时,将条件类别的概率与各个框的置信度预测相乘:
P r ( C l a s s i ∣ O b j e c t ) × P r ( O b j e c t ) × I O U t r u t h p r e d = P r ( C l a s s i ) × I O U t r u t h p r e d Pr(Class_i | Object) \times Pr(Object) \times IOU^{truth}{pred} = Pr(Class_i) \times IOU^{truth}{pred} Pr(Classi∣Object)×Pr(Object)×IOUtruthpred=Pr(Classi)×IOUtruthpred
从而得出每个框的某一类的置信度。 这些结果既代表了该类别出现在盒子中的概率,也预测了 bounding box 适合所检测对象的程度。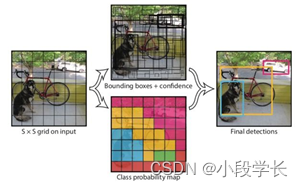
网络设计
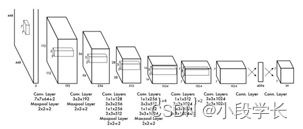
根据以上结构图,输入图像大小为 448 × 448 448 \times 448 448×448,经过若干个卷积层与池化层,变为 7 × 7 × 1024 7\times7\times1024 7×7×1024 张量(图一中倒数第三个立方体),最后经过两层全连接层,输出张量维度为 7 × 7 × 30 7\times7\times30 7×7×30,这就是 Yolo v1 的整个神经网络结构,和一般的卷积物体分类网络没有太多区别,最大的不同就是:分类网络最后的全连接层,一般连接于一个一维向量,向量的不同位代表不同类别,而这里的输出向量是一个三维的张量( 7 × 7 × 30 7\times7\times30 7×7×30)。上图中 Yolo 的网络结构,受启发于 GoogLeNet,也是 v2、v3 中 Darknet 的先锋。本质上来说没有什么特别,没有使用 BN 层,用了一层 Dropout。除了最后一层的输出使用了线性激活函数,其他层全部使用 Leaky Relu 激活函数。
论文中还训练了一种快速版本的 YOLO,旨在突破快速物体检测的界限。 Fast YOLO 使用的神经网络具有较少的卷积层( 9 个而不是 24 个),并且这些层中的过滤器较少。 除了网络的规模外,YOLO 和 Fast YOLO 之间的所有训练和测试参数都相同。
LOSS函数
神经网络结构确定之后,训练效果好坏,由 Loss 函数和优化器决定。Yolo v1 使用普通的梯度下降法作为优化器。这里重点解读一下 Yolo v1 使用的 Loss 函数:
Loss 函数,论文中给出了比较详细的解释。所有的损失都是使用平方和误差公式,暂时先不看公式中的 λ c o o r d \lambda_{coord} λcoord与 λ n o o b j \lambda_{noobj} λnoobj ,输出的预测数值以及所造成的损失有:
预测框的中心点 ( x , y ) (x, y) (x,y) 。造成的损失是第一行。其中 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj 为控制函数,在标签中包含物体的那些格点处,该值为 1 ;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。(x, y) 数值与标签用简单的平方和误差。
预测框的宽高 ( w , h ) (w, h) (w,h) 。造成的损失是图第二行。 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj 的含义一样,也是使得只有真实物体所属的格点才会造成损失。这里对(w, h)在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如, 20 20 20 个像素点的偏差,对于 800 × 600 800 \times 600 800×600 的预测框几乎没有影响,此时的 IOU 数值还是很大,但是对于 30 × 40 30 \times 40 30×40 的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
预测框的置信度 C。第三行与第四行。当该格点不含有物体时,该置信度的标签为 0;若含有物体时,该置信度的标签为预测框与真实物体框的 IOU 数值。
物体类别概率 P。第五行。对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。
此时再来看 λ c o o r d \lambda_{coord} λcoord与 λ n o o b j \lambda_{noobj} λnoobj ,Yolo 面临的物体检测问题,是一个典型的类别数目不均衡的问题。其中 49 个格点,含有物体的格点往往只有 3、4 个,其余全是不含有物体的格点。此时如果不采取措施,那么物体检测的 mAP 不会太高,因为模型更倾向于不含有物体的格点。 λ c o o r d \lambda_{coord} λcoord与 λ n o o b j \lambda_{noobj} λnoobj 的作用,就是让含有物体的格点,在损失函数中的权重更大,让模型更加“重视”含有物体的格点所造成的损失。在论文中, λ c o o r d \lambda_{coord} λcoord与 λ n o o b j \lambda_{noobj} λnoobj 的取值分别为 5 与 0.5。
参 考 文 献
[]李星辰.融合YOLO检测的多目标跟踪算法[J].计算机工程与科学,2020(4):665-672.
[2]李章维.基于视觉的目标检测方法综述[J].计算机工程与应用,2020(3):1-9.
[3]刘磊.一种YOLO识别与Mean shift跟踪的车流量统计方法[J.制造业自动化,2020(2):16-20.
[4]王沣.人工智能在门窗检测中图纸识别的应用[J].四川水泥,2019(9):137-138.
欢迎大家加我微信交流讨论(请备注csdn上添加)
边栏推荐
- C语言小型商品管理系统
- 源码编译安装MySQL
- Byte interview algorithm question
- 担心“断气” 德国正修改《能源安全法》
- SQL language
- C language dormitory management query software
- 2022kdd pre lecture | 11 first-class scholars take you to unlock excellent papers in advance
- CommVault cooperates with Oracle to provide metallic data management as a service on Oracle cloud
- Programmer anxiety
- Optional values and functions of the itemized contenttype parameter in the request header
猜你喜欢
Redis —— How To Install Redis And Configuration(如何快速在 Ubuntu18.04 与 CentOS7.6 Linux 系统上安装 Redis)
The only core indicator of high-quality software architecture

小程序直播 + 电商,想做新零售电商就用它吧!
Commvault 和 Oracle 合作,在 Oracle 云上提供 Metallic数据管理即服务

Oracle 被 Ventana Research 评为数字创新奖总冠军

2022g3 boiler water treatment examination question simulation examination question bank and simulation examination
一次 Keepalived 高可用的事故,让我重学了一遍它

基于链表管理的单片机轮询程序框架
Introduction to reverse debugging PE structure resource table 07/07
结合案例:Flink框架中的最底层API(ProcessFunction)用法
随机推荐
嵌入式编程中五个必探的“潜在错误”
Getting started with the go language is simple: go implements the Caesar password
Scripy framework learning
2022g3 boiler water treatment examination question simulation examination question bank and simulation examination
C array supplement
如何在 2022 年为 Web 应用程序选择技术堆栈
C语言课程设计题
Interview disassembly: how to check the soaring usage of CPU after the system goes online?
MySQL version 8 installation Free Tutorial
忠诚协议是否具有法律效力
C language programming topic reference
C#基础深入学习一
Five "potential errors" in embedded programming
1200. 最小绝对差
1200. Minimum absolute difference
Understanding and difference between viewbinding and databinding
Variable promotion and function promotion in JS
2022G3锅炉水处理考试题模拟考试题库及模拟考试
Introduction to XML III
JVM系列——栈与堆、方法区day1-2