当前位置:网站首页>xss课堂内容复现
xss课堂内容复现
2022-08-04 20:25:00 【傲然*】
文章目录
命名空间混淆
原理
- HTML 解析器可以创建一个包含三个命名空间元素的 DOM 树:
HTML 命名空间 (
http://www.w3.org/1999/xhtml)
SVG 命名空间(http://www.w3.org/2000/svg)
MathML 命名空间 (http://www.w3.org/1998/Math/MathML)
- 默认情况下,所有元素都在HTML命名空间中;但是,如果解析器遇到
<svg>或者<math>元素时,则会分别切换到SVG和MATHML命名空间。并且这两个命名空间都会产生外部内容。 - 在外部内容中,标记的解析方式与普通HTML不同。如在解析
<style>元素时,在HTML命名空间中,<style>只能包含文本,没有子元素,并且不解码HTML实体。但在SVG和MATHML空间下,<style>可以有子元素,且实体编码会被解码 - 考虑如下标记
<style><a>ABC</style><svg><style><a>ABC
- 它被解析为以下 DOM 树:

- DOM树中的所有元素都处于命名空间下,上图中
<html style>表示该<style>是HTML命名空间下的元素,而svg style表示它是SVG 命名空间中的元素。 - 从生成的DOM树中可以看出,
html style只有文本内容,而svg style像普通元素一样被解析。 - 在
<svg>,<math>里的所有元素都处于非 HTML 命名空间中吗?答案不是的。HTML 规范中有一些元素称为MathML 文本集成点和HTML 集成点。这些元素的子元素具有 HTML 命名空间。 - 考虑以下示例:
<math><style><a>A</style><mtext><style><a>B</style>
它被解析为以下 DOM 树:

在该实例中,解析器遇到
<math>标签,将命名空间切换为MATHML,第一个<style>作为math的直接子元素在MATHML命名空间下,而第二个<style>在<metext>下则是HTML命名空间下。这是因为mtext是MathML 文本集成点,它使解析器切换命名空间,使得子元素具有 HTML 命名空间。MathML 文本集成点是:
math mi、math mo、math mn、math ms
<math><mn><style><a>A</style>
<math><mo><style><a>B</style>
- HTML 集成点是:
<math> <annotation encoding=”text/html/application/xhtml+xml“、svg foreignObject、svg desc、svg title
<math><annotation encoding=”text/html><style><a>B</style>
<svg><foreignObject><style><a>B</style>
- 大部分Mathml文本集成点的子元素都是HTML 命名空间的啊,但是除了
<mglyph>和<malignmark>。当它们是文本集成点的直接子元素的时候。他们不会切换命名空间。
<math><mtext><mglyph></mglyph><a><mglyph>

- 图中可以看出mtext
的直接子元素mglyph在 MathML 命名空间中,而html a`元素的子元素在 HTML 命名空间中。本来mtext下的元素都应该以html为命名空间的,但mglyph改变了这一个规则 - 那如何确定当前元素的命名空间呢?
除非满足以下几点的条件,否则当前元素位于其父元素的命名空间中。
如果当前元素是<svg>or<math>并且父元素在 HTML 命名空间中,则当前元素分别在 SVG 或 MathML 命名空间中。
如果当前元素的父元素是 HTML 集成点,则当前元素在 HTML 命名空间中,除非它是<svg>或<math>。
如果当前元素的父元素是MATHML集成点,那么目前的元素是HTML的命名空间,除非它是<svg>,<math>,<mglyph>或<malignmark>。
DOMPurify-2.0.7绕过
- 下面的代码为
xss.pwnfunction.com关卡中的ok,Boomer
<h2 id="boomer">Ok, Boomer.</h2>
<script> boomer.innerHTML = DOMPurify.sanitize(new URL(location).searchParams.get('boomer') || "Ok, Boomer") setTimeout(ok, 2000) </script>
- DOMPurify库,由一个世界著名安全团队cure53维护,原理是利用白名单,将非白名单内的属性和标签全部过滤
- 我们可以通过命名空间混淆xss绕过DOMPurify的过滤
- 在绕过之间需要在了解一些知识点
DOMPurify过滤过程
- 设我们有一个不受信任的 HTML
htmlMarkup并且我们想将它分配给某个div,我们使用以下代码使用 DOMPurify 对其进行清理并分配给div
div.innerHTML = DOMPurify.sanitize(htmlMarkup)
- 在DOMPurify对
htmlMarkup过滤到将其添加到DOM树时,发生了以下操作:
htmlMarkup被解析为 DOM 树。
DOMPurify 清理 DOM 树:遍历 DOM 树中的所有元素和属性,并删除所有不在允许列表中的节点
DOM 树被序列化回 HTML 标记
分配给innerHTML,浏览器会再次解析 HTML 标记
解析后的 DOM 树被附加到文档的 DOM 树中
- 简而言之,DOMPurify会将我们需要插入的标签解析为DOM树,遍历其元素和属性,通过白名单过滤,过滤完成后序列化为html语句交由HTML解析。
- 这是有个疑问:序列化 DOM 树并再次解析它应该是否总是返回初始 DOM 树
嵌套 FORM 元素
- 在HTML规范中关于序列化 HTML 片段的部分说明:反复的序列化和解析未必会得到相同的DOM结构。这种情况往往是html解析器或序列化过程造成了错误。但是存在情况是由于html规范导致的。
- html规范中,不允许form元素的子元素是form。那么说明嵌套form元素是不被允许的。这会导致嵌套里面的form元素被html解析器忽略。如下实例:
<form id=form1>
INSIDE_FORM1
<form id=form2>
INSIDE_FORM2
- 这将产生以下 DOM 树:

- 但是我们可以通过带有错误嵌套标签的稍微损坏的标记,可以创建嵌套表单
<form id="outer"><div></form><form id="inner"><input>
- 它产生以下 DOM 树,其中包含一个嵌套的表单元素:

- 这不是任何特定浏览器中的错误;它直接来自 HTML 规范,并在解析 HTML 的算法中进行了描述。
- 当你打开一个
<form>标签时,解析器需要使用表单元素指针打开的(在规范中是这样调用的)。如果指针不是null,则form无法创建元素。
结束<form>标记时,表单元素指针始终设置为null。
- 一开始,表单元素指针指向
id=outer,然后,出现一个div,遇到</form>后将表单元素指针设置为null,因为时null,所以id='inner'可以创建下一个表单;又因为inner在div中,所以有一个form嵌套在form里. - 现在,如果我们尝试序列化生成的 DOM 树,我们将得到以下标记:
<form id="outer"><div><form id="inner"><input></form></div></form>
- 注意,此标记不再有任何错误嵌套的标签。当再次解析标记时,会创建以下 DOM 树:

- 所以这证明了序列化后再次解析不能保证返回原始 DOM 树。更有趣的是,这是一个符合规范的突变。利用该特性,是我们能绕过DOMPURIFY的利器.
最终绕过
- 利用错误嵌套的
form表单,将我们的恶意代码放进第二个form元素中,利用命名空间使此时的恶意代码被识别为文本,然后错误嵌套的form表单由DOMPurify解析和序列化,导致第二个form被html解析器忽略,恶意代码的命名空间发生变化,被HTML解析 - 绕过 DOMPurify 的payload:
<form><math><mtext></form><form><mglyph><style></math><img src onerror=alert(1)>
- payload利用错误嵌套的
html form元素,并且还包含mglyph元素。它生成以下 DOM 树
- 这个 DOM 树是无害的。所有元素都在 DOMPurify 的允许列表中,序列化后发生变化
<form><math><mtext><form><mglyph><style></math><img src οnerrοr=alert(1)></style></mglyph></form></mtext></math></form>
- 当它被赋值给 时
innerHTML,它会被解析成下面的 DOM 树:

- 所以现在第二个
html form没有被创建,mglyph现在是 mtext的直接子元素,在MathML 命名空间中。因此,style它也在 MathML 命名空间中,因此其内容不被视为文本。然后</math>关闭<math>元素,现在img在HTML命名空间中创建,导致XSS。
Dom clombing
- 如果你在 HTML 里面设定一个有 id 的元素之后,在 JS 中就可以直接操作:
<button id="btn">click me</button>
<script>
console.log(window.btn)
</script>
- 我设置了一个id为
btn的按钮,然后将window.btn输出到控制台中
- 结果将
<buttn>标签输出,这是为什么呢?由于 JS 的作用域规则,你就算直接用btn也可以,因为在当前的作用域找不到时就会往上找,一路找到window。 - 不需要
getElementById,也不需要querySelector,只要直接用与id同名的变量去拿,就能得到。 - 除了
id可以直接用window存取,embed,form,img和object这四个标签用name也可以操作:
<embed name="a"></embed>
<form name="b"></form>
<img name="c" />
<object name="d"></object>
- 把这个手法用在攻击上,就是 DOM Clobbering。通过 DOM 把一些东西覆盖掉来达到攻击的手段。
进一步分析
- 假设我们有以下 JavaScript 代码,
if (window.test1.test2) {
eval(''+window.test1.test2)
}
- 如果想利用Dom Clobbering技巧来执行任意的js,需要解决两个问题
如何控制
test1.test2
怎么控制DOM elements被强制转为string之后的值,大多数的dom节点被转为string后是[object HTMLInputElement]。
- 第一个问题开始。最常引用的解决方法是使用
<form>标签,标记的每个<input>都属于<form>后代,通过form_id.input_id可抓取input
<form id=test1>
<input id=test2>
</form>
<script>
alert(test1.test2); // 结果弹出 [object HTMLInputElement]"
</script>
- 如果dom节点被转为string后是只能返回[object HTMLInputElement]的话,那我就无法利用了,但发现在使用
<a>元素的情况下,toString只返回一个href属性值。
<a id=test1 href=https://securitum.com>
<script>
alert(test1); // 弹出 "https://securitum.com"
</script>
- 此时,似乎如果我们要解决原来的问题(即
window.test1.test2通过 DOM Clobbering攻击),我们需要类似于以下的代码:
<form id=test1>
<a id=test2 href="javascript:alert(1)"></a>
</form>
- 但结果根本没有弹窗,
test1.test2为undefined,虽然<input>元素可以被该方式抓取,但同样的情况不适合`。 - 不过,这个问题有一个有趣的解决方案,它适用于基于 WebKit 和 Blink 的浏览器。假设我们有两个相同的元素
id:
<a id=test1>click!</a>
<a id=test1>click2!</a>
- 此时访问
window.test1会得到什么呢?直觉会获得其中一个,但实际上,在Chromlun中得到了一个HTMLCollection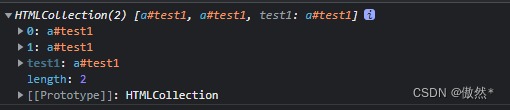
- 我们可以
HTMLCollection通过 index(0和1示例中)以及 访问其中的特定元素id。这意味着window.test1.test1实际上是指第一个元素。事实证明,设置name属性也会在HTMLCollection. 所以现在我们有以下代码:
<a id=test1>click!</a>
<a id=test1 name=test2>click2!</a>
- 我们可以通过name访问第二个
window.test1.test2。
- 回到
eval(''+window.test1.test2),解决方案是
<a id="test1"></a><a id="test1" name="test2" href="javascript:alert(1)"></a>
Ok,Boomer绕过
<h2 id="boomer">Ok, Boomer.</h2>
<script>
boomer.innerHTML = DOMPurify.sanitize(new URL(location).searchParams.get('boomer') || "Ok, Boomer")
setTimeout(ok, 2000)
</script>
- 可以发现,源码中有一个
setTimeout函数,该函数可以执行函数或字符串,代码中的setTimeout函数执行了ok,那我们可以传入一个id为ok的a标签,让setTimeout函数执行传入的a标签的href属性值。
payload:<a id="ok" href="javascript:alert(1)">
- 但发现没有成功,想起还有个传入的标签会被过滤,由于
href属性是a标签比较重要的属性,因此该属性不会被删除,而是对其中的协议进行白名单过滤,查看DOMPurify过滤部分的代码: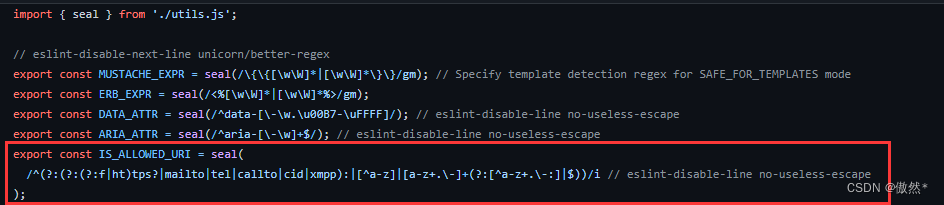
- 发现其URL协议的白名单中有
cid、tel等属性,于是传入<a id="ok" href="tel:alert(1337)">,成功绕过
对删除传入标签所有属性的绕过
案例1
- 代码如下:创建了一个
div标签,将我们在URL中#后传入的值,将其作为子元素添加到div中,然后第一个for循环获取div下的所有子元素,第二个for循环获取子元素的属性并删除
const root = document.createElement('div');
const data = decodeURIComponent(location.hash.substr(1))
root.innerHTML = data;
for (let el of root.querySelectorAll('*')){
for(let attr of el.attributes){
el.removeAttribute(attr.name);
}
}
document.body.appendChild(root);
- 先随便传个
<img src=1 onerror=alert(1)进去,结果发现生成的DOM树如下:
- 按道理说应该是将我们传入的
<a>标签的所有属性都删除了,但为什么只删除了src属性,留下了onerror属性 - 分析源码发现,源码中是在for循环遍历元素属性的同时移除了元素属性,假设有一个数组,存放
a-e5个值,当我们遍历该数组时是通过其索引进行遍历,首先获取索引未0的值也就是a,然后我删除a,导致数组变化,只存放了b-e4个值;继续遍历,此时需要获取索引为1的值,由于数组发生了变化,此时索引为1的值为c,然后删除c,b逃过了删除。 - 所以可以根据这个代码的漏洞进行绕过,只需在标签中添加几个属性就可进行绕过
payload:<img a=xx src=1 b=yy οnerrοr=alert(1)
案例2
- 由于上个案例的代码存在漏洞,所以被轻易绕过,该案例是对上述代码的优化
const root = document.createElement('div');
const data = decodeURIComponent(location.hash.substr(1))
root.innerHTML = data;
let attrs = []
for (let el of root.querySelectorAll('*')){
for(let attr of el.attributes){
attrs.push(attr.name);
}
for(let name of attrs){
el.removeAttribute(name);
}
}
document.body.appendChild(root);
- 这次依然是先传个
<img src=1 onerror=alert(1)进去,结果如下:可以看到img的所有属性都被删除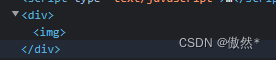
- 此时我们应该如何绕过呢?有两个思路可以绕过:1.进入循环但不删除关键属性;2.在进入循环前就执行恶意代码
- 我们首先思考如何使我们的标签进入循环但不被删除属性,分析代码,发现
el.attributes,这个本应该是传入标签的所有属性,我们是否可以通过DOM clombing进行覆盖呢? - 进行尝试,由于
el是通过遍历获取到的子元素,那我们传入一个<form>作为第一个子元素,然后在<form>中添加一个id为attributes的<input>,这样在调用el.attributes也就是form.attributes获取到的值就是<input>标签
传入:<form action='1'><input id="attributes">
- 发现没有反应,并且在控制台报了个错:
el.attributes is not iterable,通过报错我们可以得知,el.attributes确实如我们期望的获取到了<input>,但<input>不使一个可迭代对象所以报错 - 需要一个可迭代对象,在上面的DOM clombing中提到过,获取两个相同id的标签返回的是一个HTMLcollection,所以:
传入:<form action='1'><input id="attributes"><input id="attributes">
- 发现form的属性没有被删除

- 这时又有一个疑问了,如何通过form的属性执行恶意代码呢?可以利用
tabindex使form表单可被聚焦、onfocus事件和autofocus自动聚焦执行代码
传入:<form tabindex=1 onfocus=alert(1) autofocus=true><input id="attributes"><input id="attributes">
- 成功执行恶意代码

- 自动聚焦导致重复执行恶意代码,于是我们在执行过一次依次后移除
onfocus事件
传入:<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus')" autofocus=true><input id="attributes"><input id="attributes">
- 进入循环但不删除关键属性实现了,还有种看起来非常简单的payload也可以绕过
<svg><svg onload=alert(1)>
- 该payload就是在进入循环前就执行了onload中的恶意代码,原理为利用了svg的特性
svg的深度利用绕过
- 首先我们需要了解DOM树的构建过程:解析一份文档时,先由标记生成器做词法分析,将读入的字符转化为不同类型的Token,然后将Token传递给树构造器处理;接着标识识别器继续接收字符转换为Token,如此循环。实际上对于很多其他语言,词法分析全部完成后才会进行语法分析(树构造器完成的内容),但由于HTML的特殊性,树构造器工作的时候有可能会修改文档的内容,因此这个过程需要循环处理。
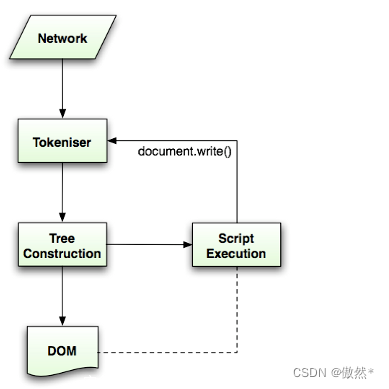
- 在树构建过程中,遇到不同的Token有不同的处理方式。Token类型共有7种,
kStartTag代表开标签,kEndTag代表闭标签,kCharacter代表标签内的文本。所以一个<script>alert(1)</script>会被解析成3个不同种类的Token,分别是kStartTag、kCharacter和kEndTag。 - 在处理Token的时候,还会用到
HTMLElementStack,一个栈的结构。当解析器遇到开标签时,会创建相应元素并附加到其父节点,然后将token和元素构成的Item压入该栈。遇到一个闭标签的时候,就会一直弹出栈直到遇到对应元素构成的item为止。这也是一个处理文档异常的办法。比如<div><p>1</div>会被浏览器正确识别成<div><p>1</p></div>正是借助了栈的能力。 - 而当处理script的闭标签时,除了弹出相应item,还会暂停当前的DOM树构建,进入JS的执行环境。换句话说,在文档中的script标签会阻塞DOM的构造。JS环境里对DOM操作又会导致回流,为DOM树构造造成额外影响。
img失败原因
- 将过滤代码进行注释,并传入
<img src=1 onerror=alert(1)
const root = document.createElement('div');
const data = decodeURIComponent(location.hash.substr(1))
root.innerHTML = data;
document.body.appendChild(root);
在浏览器中对打断点调试一下,查看img的执行时间
发现知道
<script>标签结束,也没有执行alert(1),跳出<script>后继续调试,弹窗执行
很明显,
alert(1)是在页面上script标签中的代码全部执行完毕以后才被调用的。这里涉及到浏览器渲染的另外一部分内容: 在DOM树构建完成以后,就会触发DOMContentLoaded事件,接着加载脚本、图片等外部文件,全部加载完成之后触发load事件。img的onerror只能在加载外部文件时执行,在等到执行时,onerror属性已经被清除掉了,所以img失败
svg成功原因
依然使用被注释的代码,传入
<svg><svg onload=alert(1)>,打断点进行调试
结果发现:
alert(1)在短点后立马执行了,直接弹出了窗口,点击确定以后,调试器才会走到下一行代码。而且,这个地方如果只有一个<svg onload=alert(1)>,那么结果将同img一样,直到script标签结束以后才能执行相关的代码。这时为什么呢?在使用
HTMLElementStack的结构用来帮助构建DOM树时,当我们没有正确闭合标签的时候,如<svg><svg>,都会调用栈中元素的FinishParsingChildren函数。这个函数用于处理子节点解析完毕以后的工作。但
<svg>元素的FinishParsingChildren函数会判断当前的<svg>元素是否是最外层的svg,如果不是,在达到结束标记的时候触发load事件,所以通过<svg><svg onload=alert(1)>构建两层svg,第二层的svg在innerHTML解析时执行总结:img和其他payload的失败原因在于过滤代码执行的时间早于事件代码的执行时间,过滤代码将恶意代码清除了。套嵌的svg之所以成功,是因为当页面为
root.innerHtml赋值的时候浏览器进入DOM树构建过程;在这个过程中会触发非里层svg标签的load事件,最终成功执行代码。所以,过滤代码执行的时间点在这之后,无法影响我们的payload。
边栏推荐
猜你喜欢





随机推荐
MYSQL获取数据库的表名和表注释
零知识证明——zkSNARK证明体系
深度解析:为什么跨链桥又双叒出事了?
Aura clock chip generation configuration file script
使用 Chrome 开发者工具的 lighthouse 功能分析 web 应用的性能问题
June To -.-- -..- -
零知识证明笔记——私密交易,pederson,区间证明,所有权证明
构建Buildroot根文件系统(I.MX6ULL)
Unreal 本地化 国家化 多语言
如何用好建造者模式
成品升级程序
zynq records
二叉树的遍历
How to use the Chrome DevTools performance tab
动态规划_双数组字符串
如何手动下载并安装 Visual Studio Code 的 SAP Fiori tools - Extension Pack
vehemently condemn
【CAS:2306109-91-9 |胺-PEG4-脱硫生物素】价格
[Awards for Essays] Autumn recruitment special training to create your exclusive product experience
How to carry out AI business diagnosis and quickly identify growth points for cost reduction and efficiency improvement?