当前位置:网站首页>Tear down the underlying mechanism of the five JOINs of SparkSQL
Tear down the underlying mechanism of the five JOINs of SparkSQL
2022-08-04 20:03:00 【Sensitive uncle V587】
关联形式(Join Types)都有哪些
My personal habit or, from the perspective of the source inside the definition,On the one hand, if there is adjustment,You know how to check,另一方面来说,There is nothing more than the source code defines the official.SparkSQL中的关于JOIN的定义位于
org.apache.spark.sql.catalyst.plans.JoinType,According to the division of package,JOINIs actually part of the execution plan.
具体的定义可以在JoinType的伴生对象中applyMethods construct.
object JoinType {
def apply(typ: String): JoinType = typ.toLowerCase(Locale.ROOT).replace("_", "") match {
case "inner" => Inner
case "outer" | "full" | "fullouter" => FullOuter
case "leftouter" | "left" => LeftOuter
case "rightouter" | "right" => RightOuter
case "leftsemi" | "semi" => LeftSemi
case "leftanti" | "anti" => LeftAnti
case "cross" => Cross
case _ =>
val supported = Seq(
"inner",
"outer", "full", "fullouter", "full_outer",
"leftouter", "left", "left_outer",
"rightouter", "right", "right_outer",
"leftsemi", "left_semi", "semi",
"leftanti", "left_anti", "anti",
"cross")
throw new IllegalArgumentException(s"Unsupported join type '$typ'. " +
"Supported join types include: " + supported.mkString("'", "', '", "'") + ".")
}
}
当然,We can clearly see why we usually say thatleft outer join 和left join 其实是一样的.
| 关联形式 | 关键字 |
|---|---|
| 内关联 | inner |
| 外关联 | outer、full、fullouter、full_outer |
| 左关联 | leftouter、left、left_outer |
| 右关联 | rightouter、right、right_outer |
| 左半关联 | leftsemi、left_semi、semi |
| 左逆关联 | leftanti、left_anti、anti |
| 交叉连接(笛卡尔积) | cross |
In front of several people familiar with,I said the three behind,Behind the three actually use very much,But we often is
With some other grammar expression,Because our presentation data behind,Set up tables in advance
import spark.implicits._
import org.apache.spark.sql.DataFrame
// 学生表
val seq = Seq((1, "小明", 28, "男","二班"), (2, "小丽", 22, "女","四班"), (3, "阿虎", 24, "男","三班"), (5, "张强", 18, "男","四班"))
val students: DataFrame = seq.toDF("id", "name", "age", "gender","class")
students.show(10,false);
students.createTempView("students")
// 班级表
val seq2 = Seq(("三班",3),("四班",4),("三班",1))
val classes:DataFrame = seq2.toDF("class_name", "id")
classes.show(10,false)
classes.createTempView("classes")
+---+----+---+------+-----+
|id |name|age|gender|class|
+---+----+---+------+-----+
|1 |小明|28 |男 |二班 |
|2 |小丽|22 |女 |四班 |
|3 |阿虎|24 |男 |三班 |
|5 |张强|18 |男 |四班 |
+---+----+---+------+-----+
+---+----+---+------+-----+
| id|name|age|gender|class|
+---+----+---+------+-----+
| 2|小丽| 22| 女| 四班|
| 3|阿虎| 24| 男| 三班|
| 5|张强| 18| 男| 四班|
+---+----+---+------+-----+
left_semi join
These two are just a pair of,One is to eliminate,One is to keep
我们经常有这种需求,We want to query class table exists in the student's name,我们会这样写SQL
select id,name,age,gender,class from students where class in (select class_name from classes group by class_name)
Is a kind of existence needs,转换成我们的left_semi就是
select id,name,age,gender,class from students left semi join classes on students.class=classes.class_name
当然,Will not forget our code form
val leftsemiDF: DataFrame = students.join(classes, students("class") === classes("class_name"), "leftsemi")
3 times computation results are consistent with the,Because there is no class 2 class information,So only three, and4班的信息,This kind of demand is we realizeexists 和 一些where 条件中inThe extensive use of
+---+----+---+------+-----+
| id|name|age|gender|class|
+---+----+---+------+-----+
| 2|小丽| 22| 女| 四班|
| 3|阿虎| 24| 男| 三班|
| 5|张强| 18| 男| 四班|
+---+----+---+------+-----+
left_anti join
left_anti其实是和semiInstead of working in front is for the retention,This is to get rid of,We really simple toleft_anti You can see a similar effect,We don't want to see the students class list,我们会这样写sql
select id,name,age,gender,class from students where class not in (select class_name from classes group by class_name)
转换成我们的anti join则是
select id,name,age,gender,class from students left anti join classes on students.class=classes.class_name
当然,There are code version
val leftantiDF: DataFrame = students.join(classes, students("class") === classes("class_name"), "leftanti")
结果如下,只有2Class of xiao Ming:
+---+----+---+------+-----+
| id|name|age|gender|class|
+---+----+---+------+-----+
| 1|小明| 28| 男| 二班|
+---+----+---+------+-----+
cross join
This is actually a cartesian product,We often forget to writejoin条件的时候,This is the cartesian product,
Because of this operation is very easy to collapse the program,So to add configuration
spark.sql.crossJoin.enabled=true
spark.conf.set("spark.sql.crossJoin.enabled", "true")
students.join(classes).show(10,false)
结果如下:
+---+----+---+------+-----+----------+---+
|id |name|age|gender|class|class_name|id |
+---+----+---+------+-----+----------+---+
|1 |小明|28 |男 |二班 |三班 |3 |
|1 |小明|28 |男 |二班 |四班 |4 |
|1 |小明|28 |男 |二班 |三班 |1 |
|2 |小丽|22 |女 |四班 |三班 |3 |
|2 |小丽|22 |女 |四班 |四班 |4 |
|2 |小丽|22 |女 |四班 |三班 |1 |
|3 |阿虎|24 |男 |三班 |三班 |3 |
|3 |阿虎|24 |男 |三班 |四班 |4 |
|3 |阿虎|24 |男 |三班 |三班 |1 |
|5 |张强|18 |男 |四班 |三班 |3 |
+---+----+---+------+-----+----------+---+
JOIN的实现机制
Spark中的JOIN对应BaseJoinExecFive children,他们分别是 BroadcastHashJoinExec、BroadcastNestedLoopJoinExec、ShuffledHashJoinExec、SortMergeJoinExec、CartesianProductExec,Source relations as follows:
May you usually not too concerned about it have what contact,But when we put these together we actually obviously foundBroadcast和HashIn a,我们可以大胆猜测,Link up here,其实Broadcast和ShuffledIs the form of data distribution,SortMergeJoinExec其实也是通过Shuffle的分发,Just class name didn't writeShuffledSortMergeJoinExec Watch is a bit long,Also is the merge sort is not actually radio.We according to the distribution ways to sort out a small table:
| 分发方式 | 关键字 |
|---|---|
| No distribution | CartesianProductExec |
| Broadcast | BroadcastNestedLoopJoinExec |
| Broadcast | BroadcastHashJoinExec |
| Shuffled | ShuffledHashJoinExec |
| Shuffled | SortMergeJoinExec |
CartesianProductExec No distribution
In order to understand calculation principle,We through the source code to study.The first can actually want,Cartesian product projection is the data directly to all the rows according to cross expansion,The things directly inMapThe finished distribution combination,The code inside is also like this,我们一起看看,我把CartesianProductExecTake out computation part.
override def compute(split: Partition, context: TaskContext): Iterator[(UnsafeRow, UnsafeRow)] = {
val rowArray = new ExternalAppendOnlyUnsafeRowArray(inMemoryBufferThreshold, spillThreshold)
val partition = split.asInstanceOf[CartesianPartition]
rdd2.iterator(partition.s2, context).foreach(rowArray.add)
// Create an iterator from rowArray
def createIter(): Iterator[UnsafeRow] = rowArray.generateIterator()
val resultIter =
for (x <- rdd1.iterator(partition.s1, context);
y <- createIter()) yield (x, y)
CompletionIterator[(UnsafeRow, UnsafeRow), Iterator[(UnsafeRow, UnsafeRow)]](
resultIter, rowArray.clear())
}
}
We are going to pick key part,其实核心点就是,x,yEach is as the elements on both sides of the,When we understand our operations setyide的操作.
val resultIter =
for (x <- rdd1.iterator(partition.s1, context);
y <- createIter()) yield (x, y)
这个其实就是scalaImplemented in the operation of the double loop,sparkThe above logic can analogy the logic below,I put my studentsjoinThe cartesian product operation reduction as follows:
val students=Array((1,"小明"),(2,"小丽"))
val classes= Array("三班","二班")
val result= for(student <-students; clazz <- classes) yield (student,clazz)
result.foreach(print)
结果如下:
((1,小明),三班)((1,小明),二班)((2,小丽),三班)((2,小丽),二班)
发现没有,Is actually we need the result of the,注意哦,SparkThe source code is such a,Is confident.
BroadcastNestedLoopJoinExec
This is the literal meaning,广播+Nested loop to realizejoin,我们一直在说,Radio is a way of distributing,Before we have said that the,Radio is actually,我们在rdd执行的时候,Just can get a local variable as directly,I still take out your core code:
protected override def doExecute(): RDD[InternalRow] = {
val broadcastedRelation = broadcast.executeBroadcast[Array[InternalRow]]()
val resultRdd = (joinType, buildSide) match {
case (_: InnerLike, _) =>
innerJoin(broadcastedRelation)
case (LeftOuter, BuildRight) | (RightOuter, BuildLeft) =>
outerJoin(broadcastedRelation)
case (LeftSemi, _) =>
leftExistenceJoin(broadcastedRelation, exists = true)
case (LeftAnti, _) =>
leftExistenceJoin(broadcastedRelation, exists = false)
case (_: ExistenceJoin, _) =>
existenceJoin(broadcastedRelation)
case _ =>
/** * LeftOuter with BuildLeft * RightOuter with BuildRight * FullOuter */
defaultJoin(broadcastedRelation)
}
val numOutputRows = longMetric("numOutputRows")
resultRdd.mapPartitionsWithIndexInternal {
(index, iter) =>
val resultProj = genResultProjection
resultProj.initialize(index)
iter.map {
r =>
numOutputRows += 1
resultProj(r)
}
}
最前面 broadcastedRelation,Is actually from broadcast variable access to data,This is the operation of the radio,剩下的就是NestedLoop的事情了,We noticed that in the generation of(joinType, buildSide) match条件,Is in accordance with the operating types to achieve,我们一起看看innser join 的操作:
private def innerJoin(relation: Broadcast[Array[InternalRow]]): RDD[InternalRow] = {
streamed.execute().mapPartitionsInternal {
streamedIter =>
val buildRows = relation.value
val joinedRow = new JoinedRow
streamedIter.flatMap {
streamedRow =>
val joinedRows = buildRows.iterator.map(r => joinedRow(streamedRow, r))
if (condition.isDefined) {
joinedRows.filter(boundCondition)
} else {
joinedRows
}
}
}
}
The meaning of this operation is to set a draw,关键点就是streamedIter.flatMap()中的操作,This part is a nested loop,This is why is calledNestedLoop的原因,Is the meaning of nested loop,I put this operation according to our data set is equivalent to realize again:
val students=Array((1,"小明"),(2,"小丽"))
val classes= Array("三班","二班")
students.flatMap(student=>{
classes.map(clazz=>{
print(student._1,student._2,clazz)
})
})
结果如下:
(1,小明,三班)(1,小明,二班)(2,小丽,三班)(2,小丽,二班)
We clearly see that the time complexity isM*N,看到这里.
BroadcastHashJoinExec
有了前面的基础,对于Broadcast类型的操作,我们可以进一步归纳,三部曲
1、From radio variable values
2、Complete associated operation
3、输出结果
有了这些操作,We can foresee the code
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
val broadcastRelation = buildPlan.executeBroadcast[HashedRelation]()
if (isNullAwareAntiJoin) {
//Anti joinTrying to solve the subquery is the nested(Subquery Unnesting)中和NULlValues related to all sorts of problems,这里不展开,也是
//In order to code less
} else {
streamedPlan.execute().mapPartitions {
streamedIter =>
val hashed = broadcastRelation.value.asReadOnlyCopy()
TaskContext.get().taskMetrics().incPeakExecutionMemory(hashed.estimatedSize)
join(streamedIter, hashed, numOutputRows)
}
}
}
Radio is obtained from the radio and variable we want results
val broadcastRelation = buildPlan.executeBroadcastHashedRelation
我们需要关注else 里面的内容,val hashed = broadcastRelation.value.asReadOnlyCopy()Is actually got ushash的清单,After processing will be in the backjoinIn the operation of further processing,我们需要深入JOIN内部
protected def join(
streamedIter: Iterator[InternalRow],
hashed: HashedRelation,
numOutputRows: SQLMetric): Iterator[InternalRow] = {
val joinedIter = joinType match {
case _: InnerLike =>
innerJoin(streamedIter, hashed)
case LeftOuter | RightOuter =>
outerJoin(streamedIter, hashed)
case LeftSemi =>
semiJoin(streamedIter, hashed)
case LeftAnti =>
antiJoin(streamedIter, hashed)
case _: ExistenceJoin =>
existenceJoin(streamedIter, hashed)
case x =>
throw new IllegalArgumentException(
s"HashJoin should not take $x as the JoinType")
}
val resultProj = createResultProjection
joinedIter.map {
r =>
numOutputRows += 1
resultProj(r)
}
}
JOINWithin the main process is in accordance with theJOINType each processing,返回JOIN之后的结果,我们还是以Inner为例,分析一下实现的过程
private def innerJoin(
streamIter: Iterator[InternalRow],
hashedRelation: HashedRelation): Iterator[InternalRow] = {
val joinRow = new JoinedRow
val joinKeys = streamSideKeyGenerator()
if (hashedRelation == EmptyHashedRelation) {
Iterator.empty
} else if (hashedRelation.keyIsUnique) {
streamIter.flatMap {
srow =>
joinRow.withLeft(srow)
val matched = hashedRelation.getValue(joinKeys(srow))
if (matched != null) {
Some(joinRow.withRight(matched)).filter(boundCondition)
} else {
None
}
}
} else {
streamIter.flatMap {
srow =>
joinRow.withLeft(srow)
val matches = hashedRelation.get(joinKeys(srow))
if (matches != null) {
matches.map(joinRow.withRight).filter(boundCondition)
} else {
Seq.empty
}
}
}
}
We focus on the core operation,从hashElements in the table to get what we want,实现join,同样的,Our data set is used to implement a
import scala.collection.mutable.HashMap
val students = Array((1, "小明", "002"), (2, "小丽", "003"))
val hashClass = HashMap[String, String]("003" -> "三班", "002" -> "二班")
students.map(student => (student, hashClass.get(student._3))).foreach(print)
Because itself logic of the whole traversal results back together again,时间复杂度是O(N)
((1,小明,002),Some(二班))((2,小丽,003),Some(三班))
阶段性总结
Described above three kinds ofJOINWay is already can fully implement allJOIN操作了,But these actions have a characteristic,As the main table we can be divided into differentPartition上面执行,But from the table we are all asExecutorLocal mode to perform,因为我们的TaskIs distributed in a lot of running on the cluster,All of us in order to let all nodes have the data,All were given to all nodes are a,That's why is what is called a broadcast.
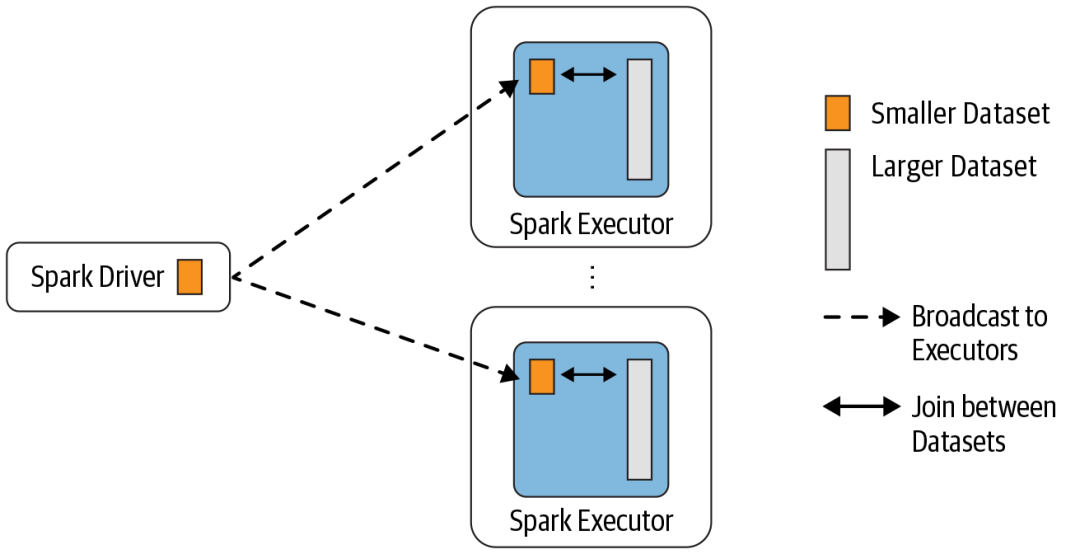
The way is very efficient when data volume is not big,The scale of the amount of data can be10Class thousands to millions of differ,That is to say, actually can control,源码中的定义如下,We can see that actually behind have a default value to us10MB
val AUTO_BROADCASTJOIN_THRESHOLD = buildConf("spark.sql.autoBroadcastJoinThreshold")
.doc("...解释信息")
.version("1.1.0")
.bytesConf(ByteUnit.BYTE)
.createWithDefaultString("10MB")
Have so a description By setting this value to -1 broadcasting can be disabled,就是给-1Can close the numerical,这种10MThe concept of general is less than tens of thousands of,Itself number field and the data content have to do with you,If not satisfied can adjust.
我们做如下设置,Can not open the radio
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "-1")
Also a situation is everyone on the Internet to see said broadcast mode is suitable for small amount of data,When slow.Actually here in the production of the actual situation is,Amount of data is bigger when he is running out,Not slow problem,Because sometimes a task execution down itself is more than half a hour,But after running an hour to a failure,This is the stand,Downstream of the production environment and rely on,So this time we are no longer the pursuit of fast,But the pray to Buddha for help just ran out of the line as long as you can,Even if be again, and so on,But don't fail.This is the actual situation.基于此,We will introduceShuffledHashJoinExec和SortMergeJoinExec的计算方式,大家注意,This is two ways to achieve a larger amount of dataJOIN而产生的,On the overall time efficiency is much less than the way in front of,But the biggest benefit is the result,Combined with practical production enterprises in the process of data are very large,So these two approaches are in production on a large number of existing operation mode.
ShuffledHashJoinExec
ShuffledHashJoinExecWay is injoinOperation from the table information fromHash中获取,Here the difference between,We need to do a radio table is too big,So we need to turn the radio watch onShuffleThe way to decompose a large table into small table generationhash,What is a principle.First we see implementation source code:
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
streamedPlan.execute().zipPartitions(buildPlan.execute()) {
(streamIter, buildIter) =>
val hashed = buildHashedRelation(buildIter)
joinType match {
case FullOuter => fullOuterJoin(streamIter, hashed, numOutputRows)
case _ => join(streamIter, hashed, numOutputRows)
}
}
}
ShuffledHashJoinExecThe back of the part is actually reuse in front ofBroadcastHashJoinExec的操作,It still need to get to aHashedRelation,This is also our buildHashTable的部分,Behind is can be carried in the localjoin操作了,Is the main difference from access toHashedRelation的时候,The former is from radio variables to obtain,这里不再是了:
def buildHashedRelation(iter: Iterator[InternalRow]): HashedRelation = {
val buildDataSize = longMetric("buildDataSize")
val buildTime = longMetric("buildTime")
val start = System.nanoTime()
val context = TaskContext.get()
val relation = HashedRelation(
iter,
buildBoundKeys,
taskMemoryManager = context.taskMemoryManager(),
// Full outer join needs support for NULL key in HashedRelation.
allowsNullKey = joinType == FullOuter)
buildTime += NANOSECONDS.toMillis(System.nanoTime() - start)
buildDataSize += relation.estimatedSize
// This relation is usually used until the end of task.
context.addTaskCompletionListener[Unit](_ => relation.close())
relation
}
Core part is from,这部分其实就是一个Shuffle的迭代结果,That means we get this partHash的时候是按照buildBoundKeysAs within the scope of the for,No longer is the scope of the entire table
val relation = HashedRelation(
iter,
buildBoundKeys,
taskMemoryManager = context.taskMemoryManager(),
// Full outer join needs support for NULL key in HashedRelation.
allowsNullKey = joinType == FullOuter)
当然,From the understanding or simple,因为SparkOn the design is very clever,We can still as aMap来看待,Only this time the data range is local area.
We also do some practical example to understand the process,As compared to the front or more steps,我们画图理解一下:
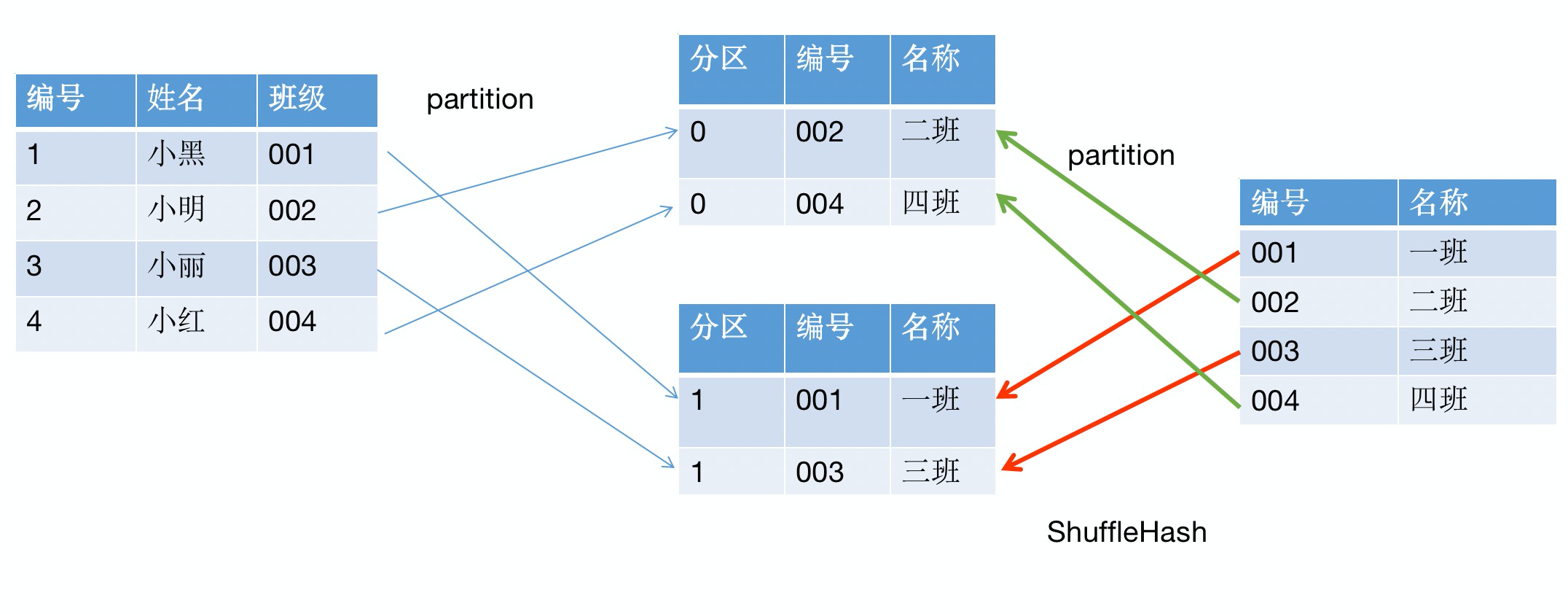
Students as the main goal is to find information and the class number matching the main table,在此之前,Do a class numberpartition操作,The data distribution in different partitions to,与此同时,The class information is alsopartition,This same class number information will fall into the samepartition中去,针对单独的partitionIs implementation andHashJoin一样的操作了.要注意的是partition就是Shuffle实现的,我们都知道shuffleWhen is the need to define ahashpartition的操作,So the operation there are twohash,For the first time partition data,第二次,实现关联操作.We put the whole process in code simulated,I am here to partition will be less complicated,仅仅按照%2的方式分发:
//To partition the class number
def partition(key:String):Integer={
val keyNum= Integer.valueOf(key)
keyNum%2
}
接下来是模拟Shuffle的操作,Because we are need to put the class information throughshuffle的方式分发,We implemented the multipleHashMap分发到了partitions内部
def shuffleHash(classes:Array[(String, String)]):mutable.HashMap[Integer,mutable.HashMap[String,(String, String)]]={
val partitions=new mutable.HashMap[Integer,mutable.HashMap[String,(String, String)]]();
for(clazz <- classes){
val hashKey=partition(clazz._1)
val map=partitions.getOrElse(hashKey,mutable.HashMap[String,(String, String)]())
map += (clazz._1->clazz)
partitions += hashKey->map
}
partitions
}
最后,We realize the realJOIN操作:
val students = Array[(Integer,String,String)]((1, "小黑", "001"),(2, "小明", "002"), (3, "小丽", "003"),(4, "小红", "004"))
val classes: Array[(String, String)] = Array(("001", "一班"), ("002", "一班"), ("003", "三班"), ("004", "四班"))
val partitions= shuffleHash(classes)
students.map(student=>{
val partitionId= partition(student._3)
val classHashMap= partitions.get(partitionId).get
val clazz= classHashMap.get(student._3)
println("分区:"+partitionId,"学生:"+student,"班级:"+clazz.get)
})
查看结果:
(分区:1,学生:(1,小黑,001),班级:(001,一班))
(分区:0,学生:(2,小明,002),班级:(002,一班))
(分区:1,学生:(3,小丽,003),班级:(003,三班))
(分区:0,学生:(4,小红,004),班级:(004,四班))
这个也能理解,为什么ShuffleOperation must be distributed the same data to the same partition inside,This is actually a partition algorithm,Feels less mysterious~~
SortMergeJoinExec
We really pay attention to,Evolutionary algorithm is in order to achieve the different size of data,SortMergeJoinExecWe also apply,Perhaps the name would be too long relationship,If we add completely,According to the data generation,我们可以命名为ShuffledSortMergeJoinExec,That is to say need toShuffle的方式生成,At the same time at the time of merger ofSortMerge,We can see it out from the inheritance of class.
case class SortMergeJoinExec(
leftKeys: Seq[Expression],
rightKeys: Seq[Expression],
joinType: JoinType,
condition: Option[Expression],
left: SparkPlan,
right: SparkPlan,
isSkewJoin: Boolean = false) extends ShuffledJoin {
这个是因为,不管是前面的Hash方式做Shuffle,We are used to aclassHashMap的类,这个操作时间复杂度O(1),快得很,But to hold the data more ah,Relatively large amount of dataclassHashMapIs turn more than,所以我还是那句话,The time is running out,Because memory will blow,Is not really the cause of the slow,Because the slow, at least can wait,But if exceeds the capability of the itself this way,The whole computing won't go down,I'm forced us to find a new way of calculating,May performance does not so fast,But at least ran out.
val classHashMap= partitions.get(partitionId).get Accept the memory limit
val clazz= classHashMap.get(student._3)
SortMergeThis is everybody impression should be both familiar and strange,Because a lot of homework is in this way,So always can see,But strange because don't know what is inside a mechanism,Today we carted to haul around.前面我也说过ShuffleIs the data in the same for usHashPartitionIn the same partition algorithm is distributed to go,This and the previous operation is exactly the same,SortMergeIs to solve how to put the data on both sides of theJOIN在一起的问题,So we focus on theSortMerge的操作.Still want to focus on the execution of source,我们需要注意到,This time the input and the front is thereleftIter, rightIterIs two input iterator operations,不再是Hash,So itself on this algorithm is to solve the twolist的合并操作
protected override def doExecute(): RDD[InternalRow] = {
val numOutputRows = longMetric("numOutputRows")
val spillThreshold = getSpillThreshold
val inMemoryThreshold = getInMemoryThreshold
left.execute().zipPartitions(right.execute()) {
(leftIter, rightIter) =>
val boundCondition: (InternalRow) => Boolean = {
condition.map {
cond =>
Predicate.create(cond, left.output ++ right.output).eval _
}.getOrElse {
(r: InternalRow) => true
}
}
...
}
doExecute()The following code is actually longer,Here just learning how to learn together such a long train of thought for studying the code,
首先,我们要知道doExecute(): RDD[InternalRow] 一定需要返回一个RDD,这个是我们需要的结果,So in the following code will have a place in return,Code for a long time we fold a long first part: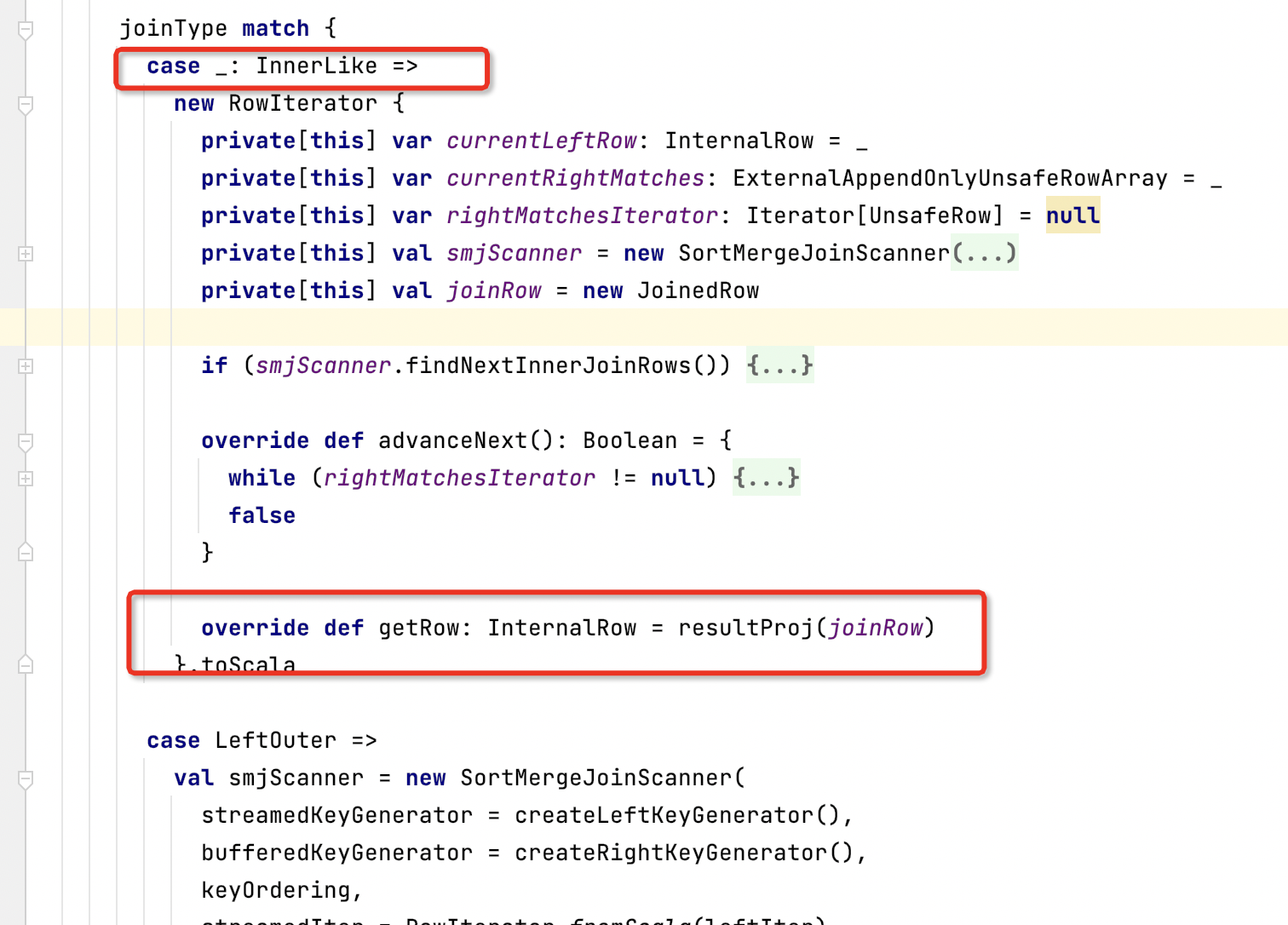
Fold after done, we can see clearly the backbone of the,The logic is corresponding to differentJOINDo a type
new RowIterator()的操作,而RowIterator.toScalaYou can return to usRDD[InternalRow] 了,顺着这个思路,We can actually create the differentJOINThe corresponding andRowIterator类型
| JOIN类型 | RowIterator实现 |
|---|---|
| InnerLike | new RowIterator 重写了advanceNext和 getRow |
| LeftOuter | LeftOuterIterator |
| RightOuter | RightOuterIterator |
| FullOuter | FullOuterIterator |
| LeftSemi | new RowIterator 重写了advanceNext和 getRow |
| LeftAnti | new RowIterator 重写了advanceNext和 getRow |
| ExistenceJoin | new RowIterator 重写了advanceNext和 getRow |
ok到了这一步,We to the whole is very clear to return to the,So the whole implementation of trigger entrance is actually
RowIterator.toScala我们进一步查看RowIterator的实现
abstract class RowIterator {
def advanceNext(): Boolean
def getRow: InternalRow
def toScala: Iterator[InternalRow] = new RowIteratorToScala(this)
}
RowIterator是一个抽象类,toScala里面其实是new RowIteratorToScala(this)做了这件事情,具体RowIteratorToScala的实现如下:
private final class RowIteratorToScala(val rowIter: RowIterator) extends Iterator[InternalRow] {
private [this] var hasNextWasCalled: Boolean = false
private [this] var _hasNext: Boolean = false
override def hasNext: Boolean = {
// Idempotency:
if (!hasNextWasCalled) {
_hasNext = rowIter.advanceNext()
hasNextWasCalled = true
}
_hasNext
}
override def next(): InternalRow = {
if (!hasNext) throw QueryExecutionErrors.noSuchElementExceptionError()
hasNextWasCalled = false
rowIter.getRow
}
}
看到这里,We are actually very clear,In the whole process is actually aIterator操作,我们都知道,RDD本身就是一个Iterator在做RDDThe iteration time,Core method is the triggerhasNext和 next方法,这两个方法也是Iterator的入口,We clearly see thehasNext调用了advanceNext操作,而在
nextWe are from the incomingrowIter: RowIterator调用了getRow操作,These two methods is the place where did rewrite in the front,The whole implementation structure we are together.接下来我们只需要关注advanceNext()的实现:
while (rightMatchesIterator != null) {
if (!rightMatchesIterator.hasNext) {
if (smjScanner.findNextInnerJoinRows()) {
currentRightMatches = smjScanner.getBufferedMatches
currentLeftRow = smjScanner.getStreamedRow
rightMatchesIterator = currentRightMatches.generateIterator()
} else {
currentRightMatches = null
currentLeftRow = null
rightMatchesIterator = null
return false
}
}
joinRow(currentLeftRow, rightMatchesIterator.next())
if (boundCondition(joinRow)) {
numOutputRows += 1
return true
}
}
false
}
看到这里,We can clearly see the wholemerge逻辑了,rightMatchesIterator和smjScanner就是我们做joinAfter the two sides of theIterator, 而joinRow(currentLeftRow, rightMatchesIterator.next())Is the current access to the data row together,Here because if our data are in both sides have done a sort of,So you just need to move the iterator to the front,并不需要做HashWhen find operations.Or according to our tradition,I to a wave of small code implements a:
def merge(students: Array[(Integer,String,String)],classes: Array[(String, String)]):Unit= {
val stuIterator=students.iterator
val claIterator=classes.iterator
var curRow=claIterator.next()//当前行
var stuRow=stuIterator.next() //获取当前行的数据
while (stuRow !=null ) {
var needNext=true
if(stuRow._3==curRow._1){
//Students of class and class number equals the number,就join起来
println("学生:"+stuRow,"班级:"+curRow)
}else{
//匹配不上的情况,Class number in the future mobile
curRow=claIterator.next()
needNext=false
}
if(needNext ){
if(stuIterator.hasNext){
stuRow=stuIterator.next()
}else{
stuRow=null
}
}
}
}
mergeAfter the implementation is already sorted in the collection of sorts,So we are in the input to ensure that the order
val students = Array[(Integer,String,String)]((1, "小黑", "001"),(2, "小明", "002"), (3, "小丽", "003"),(4, "小红", "004"))
val classes: Array[(String, String)] = Array(("001", "一班"), ("002", "二班"), ("003", "三班"), ("004", "四班"))
merge(students,classes)
结果如下:
(学生:(1,小黑,001),班级:(001,一班))
(学生:(2,小明,002),班级:(002,二班))
(学生:(3,小丽,003),班级:(003,三班))
(学生:(4,小红,004),班级:(004,四班))
Graphical we show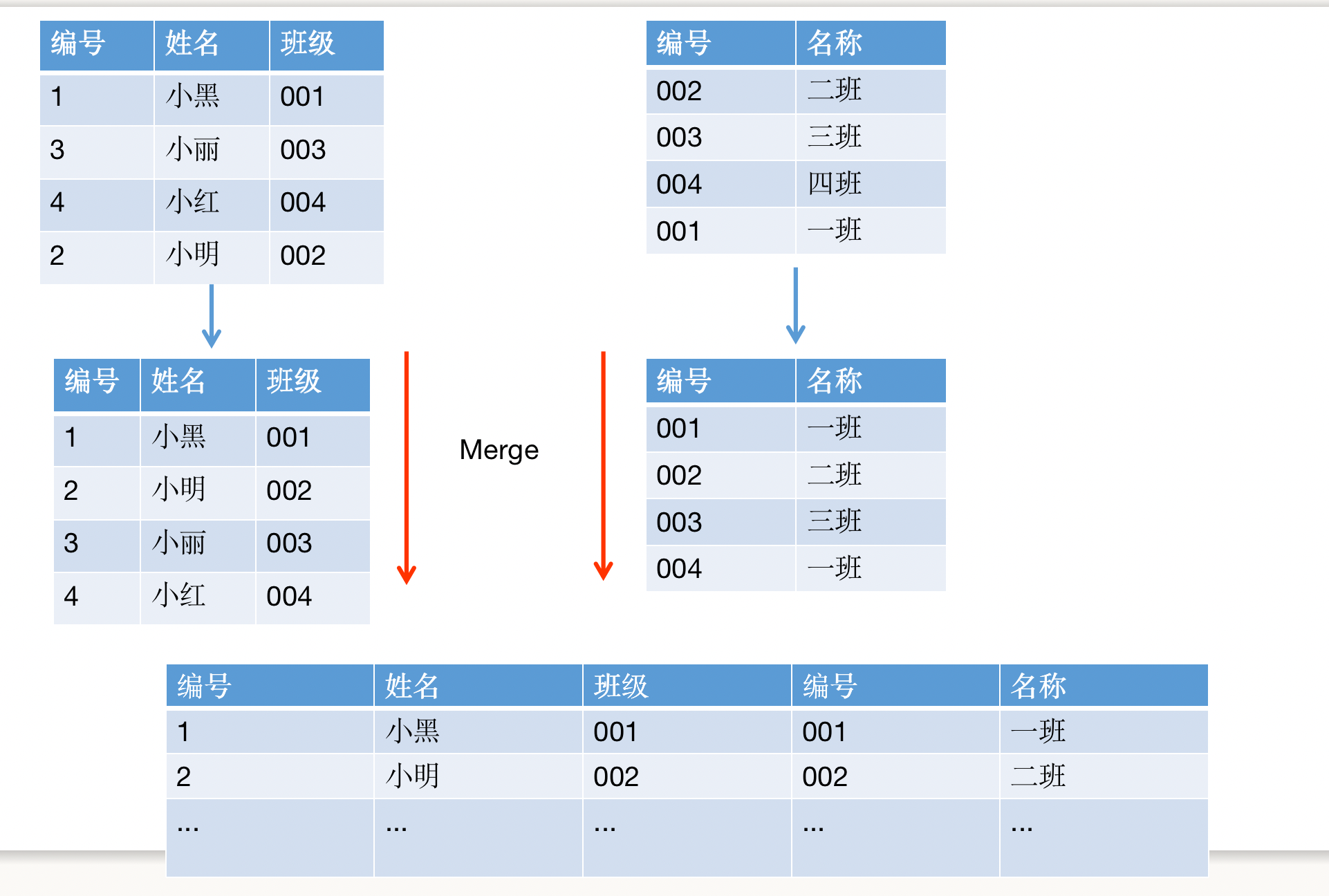
总结
Though the small code is a bit rough,But that is the essence^^
边栏推荐
猜你喜欢



随机推荐
致-.-- -..- -
二叉树的前序遍历
vscode离线安装插件方法
Client Side Cache 和 Server Side Cache 的区别
性能测试流程
vs Code 运行一个本地WEB服务器
web 应用开发最佳实践之一:避免大型、复杂的布局和布局抖动
SAP UI5 ensures that the control id is globally unique implementation method
Nuxt.js的优缺点和注意事项
【Web漏洞探索】跨站脚本漏洞
AWS SES 的监控和告警
SAP UI5 的初始化过程
visual studio 与 visual studio code
5G NR 笔记记录
In July 2022, domestic database memorabilia
"WAIC 2022 · hackers marathon" two ants wealth competition invited you to fight!
awk 统计平均 最大 最小值
如果是测试 axi dma抓数的话 看这里
Ant Group's time series database CeresDB is officially open source
Desthiobiotin衍生物Desthiobiotin-PEG4-Amine/Alkyne/Azide/DBCO