当前位置:网站首页>Fluentd facile à utiliser avec le marché des plug - ins rainbond pour une collecte de journaux plus rapide
Fluentd facile à utiliser avec le marché des plug - ins rainbond pour une collecte de journaux plus rapide
2022-07-03 06:07:00 【Xuhss 1.】
Partage de ressources de qualité
| Guide d'apprentissage(Cliquez pour déverrouiller) | Positionnement des connaissances | Orientation de la population |
|---|---|---|
| 🧡 PythonApplet de commande de repas Wechat en direct 🧡 | Classe supérieure | Ce cours estpython flask+Une combinaison parfaite d'applets Wechat,De la construction du projet au déploiement de Tencent Cloud en ligne,Créer un système de commande de repas complet. |
| PythonQuantifier les transactions en direct | Niveau d'entrée | Les poignées vous permettent de créer une extension facile、Plus sûr、Un système d'échange quantitatif plus efficace |

Il y a eu un article sur EFK(Kibana + ElasticSearch + Filebeat)Collection de journaux plug - in pour.Filebeat Le plug - in est utilisé pour transmettre et centraliser les données du Journal,Et les transmettre à Elasticsearch Ou Logstash Pour indexer,Mais... Filebeat En tant que Elastic Un membre de,Seulement dans Elastic Utilisé dans tout le système.
Fluentd
FluentdEst une source ouverte,Système d'acquisition de journaux distribués,Disponible à partir de différents services,Journal de collecte des sources de données,Filtrage des journaux,Distribué à plusieurs systèmes de stockage et de traitement.Prise en charge de divers plug - ins,Mécanisme de mise en cache des données,Et il a besoin de peu de ressources,Fiabilité intégrée,En combinaison avec d'autres services,Peut former une plate - forme efficace et intuitive de collecte de journaux.
Cet article présente Rainbond Utilisé dans Fluentd Plug - in,Collecte des journaux d'affaires,Sortie vers plusieurs services différents.
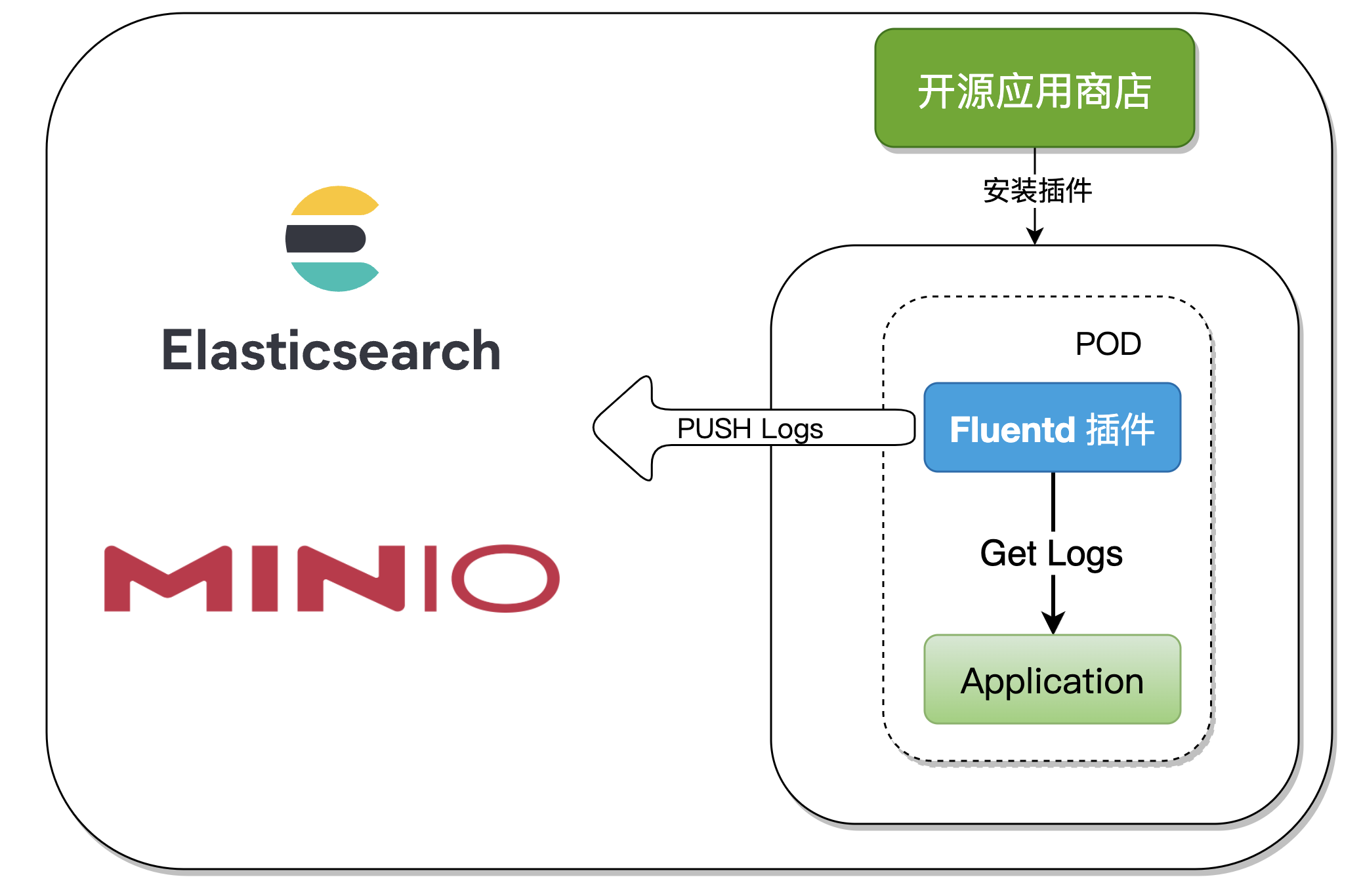
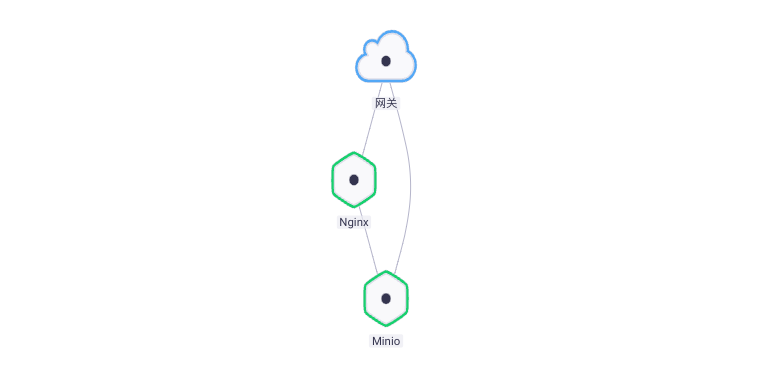
Un.、Architecture consolidée
Lors de la collecte des journaux de composants,Il suffit de l'activer dans le composant Fluentd Plug - in,Cet article montrera deux façons de:
- Kibana + ElasticSearch + Fluentd
- Minio + Fluentd
On va Fluentd Produit par Rainbond De Type général de plug - in ,Après le démarrage de l'application,Le plug - in démarre et recueille automatiquement les journaux de sortie vers plusieurs sources de service,L'ensemble du processus n'envahit pas le conteneur d'application,Et extensible.
2.、Analyse du principe du plug - in
Rainbond V5.7.0 Nouveau dans la version:Installer le plug - in depuis le magasin open source,Le plug - in de cet article a été publié dans le magasin open source,Une fois que nous l'utilisons, il suffit de l'installer en un seul clic,Modifier le profil au besoin.
Rainbond Le système plug - in est relatif à Rainbond Une partie du modèle d'application,Le plug - in est principalement utilisé pour mettre en œuvre les capacités o & M étendues du conteneur d'application.Parce que la mise en œuvre des outils o & M a une grande similitude,Pour que le plug - in lui - même puisse être réutilisé.Le plug - in doit être lié au conteneur d'application pour avoir l'état d'exécution,Pour réaliser une capacité o & M,Comme le plug - in d'analyse de performance、Module de gouvernance du réseau、Initialiser le plug - in de type.
En production Fluentd Pendant le processus du plug - in,C'est bon. Type général de plug - in,Peut être compris comme unPODDémarrer deux Container,KubernetesNative supporte unPODDémarrage multiple dans Container,Mais la configuration est relativement complexe,In Rainbond Le plug - in rend le fonctionnement de l'utilisateur plus facile.
Trois、EFK Pratiques de collecte des journaux
Fluentd-ElasticSearch7 Le plug - in de sortie écrit la journalisation Elasticsearch.Par défaut,Il utilise des lots APICréer un enregistrement,Le API En un seul API Effectuer plusieurs opérations d'indexation dans l'appel.Cela réduit les frais généraux et augmente considérablement la vitesse d'indexation.
3.1 Procédure de fonctionnement
Application (Kibana + ElasticSearch)Et plugins(Fluentd)Peut être déployé en un seul clic à partir d'un magasin open source.
- Dock open source store
- Recherche dans l'app store
elasticsearchEt installer7.15.2Version. - Vue de l'équipe -> Plug - in -> Installer à partir de l'app store
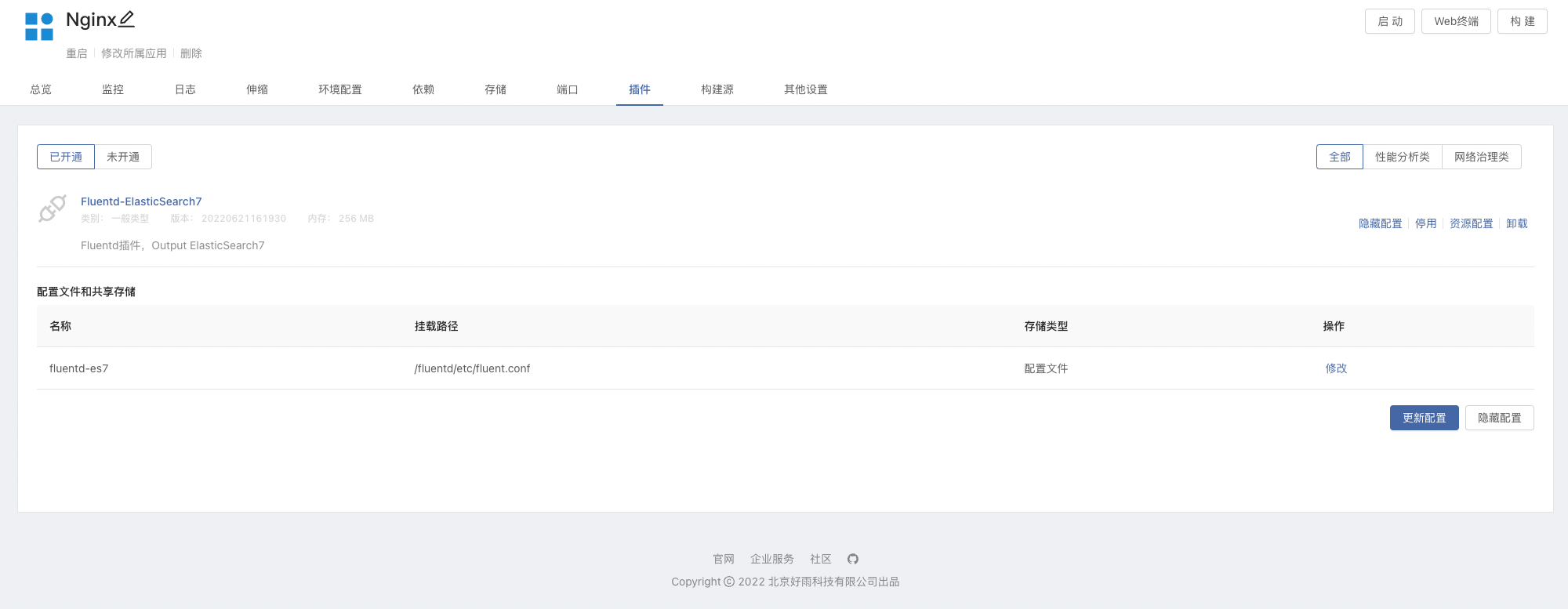
Fluentd-ElasticSearch7Plug - in - Créer un composant basé sur un miroir,Utilisation du miroir
nginx:latest,Et monter le stockagevar/log/nginx.Utilisez iciNginx:latestComme démo- Après avoir monté le stockage dans le composant,Le plug - in Monte également le stockage sur mesure,Et accessible Nginx Fichiers journaux générés.
- In Nginx Ouvrir le plug - in dans le composant,Peut être modifié au besoin
FluentdProfil,Voir la section introduction du profil ci - dessous.
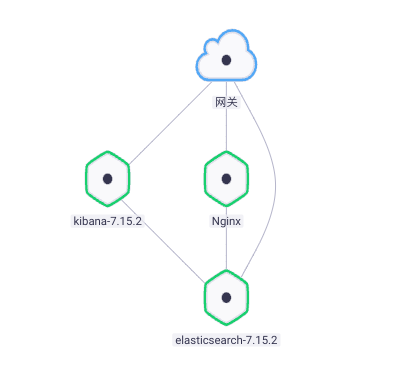
- Ajouter ElasticSearch Dépendance,Oui. Nginx Connectez - vous à ElasticSearch,Comme le montre la figure ci - dessous::
- Accès à
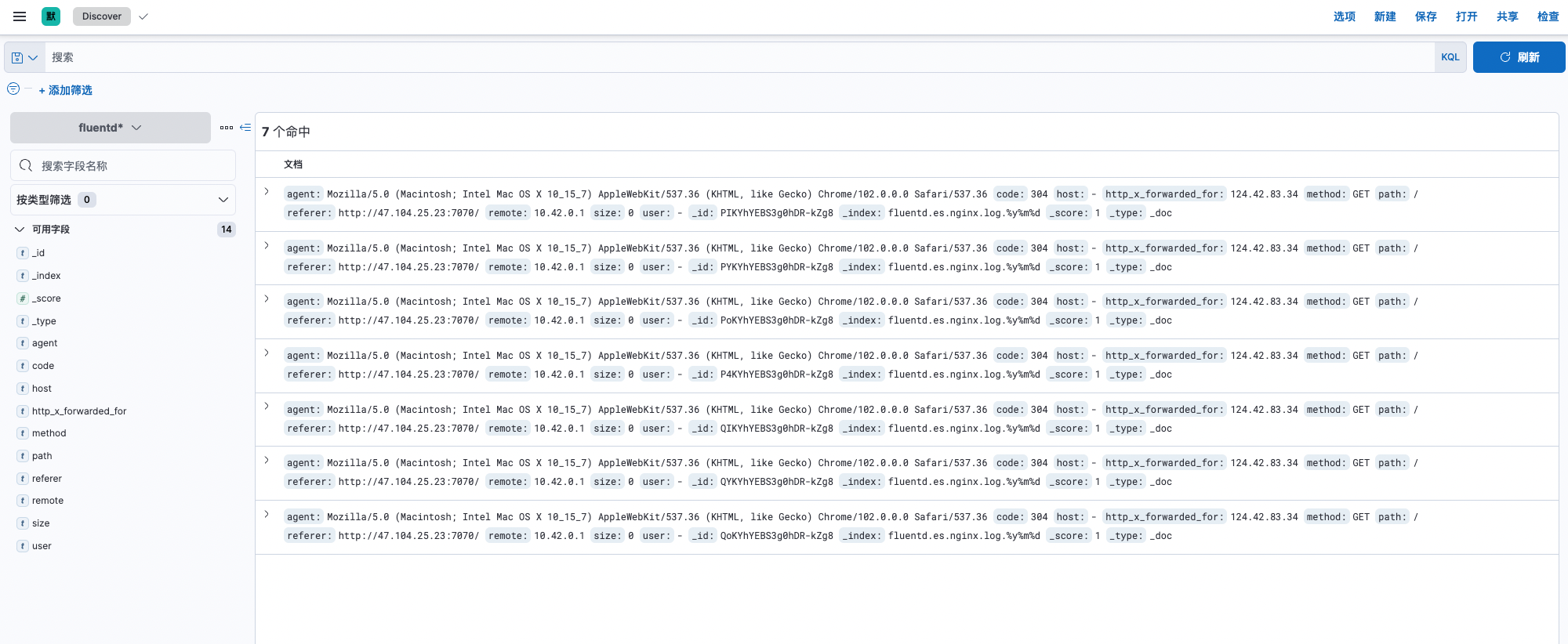
KibanaPanel,Entrée dans Stack Management -> Données -> Gestion des index,Vous pouvez voir que le nom d'index existant estfluentd.es.nginx.log, - Accès à
KibanaPanel,Entrée dans Stack Management -> Kibana -> Mode index,Créer un mode Index. - Entrée dans Discover,Affichage normal du Journal.
3.2 Profil Introduction
Référence du profil Fluentd Documentation output_elasticsearch.
@type tail
path /var/log/nginx/access.log,/var/log/nginx/error.log
pos_file /var/log/nginx/nginx.access.log.pos
@type nginx
tag es.nginx.log
@type elasticsearch
log\_level info
hosts 127.0.0.1
port 9200
user elastic
password elastic
index\_name fluentd.${tag}
chunk\_limit\_size 2M
queue\_limit\_length 32
flush\_interval 5s
retry\_max\_times 30
Explication de l'élément de configuration:
Source d'entrée du Journal:
| Éléments de configuration | Notes explicatives |
|---|---|
| @type | Type de journal d'acquisition,tailReprésente le contenu du Journal de lecture incrémental |
| path | Chemin du Journal,Plusieurs chemins peuvent être séparés par des virgules |
| pos_file | Pour marquer les fichiers qui ont été lus à l'emplacement(position file)Chemin |
| Résolution du format du Journal,Selon votre propre format de journal,Écrivez les règles d'analyse correspondantes. |
Sortie du Journal:
| Éléments de configuration | Notes explicatives |
|---|---|
| @type | Type de service exporté vers |
| log_level | Définir le niveau du Journal de sortie àinfo;Les niveaux de log pris en charge sont:fatal, error, warn, info, debug, trace. |
| hosts | elasticsearchAdresse |
| port | elasticsearchLe port de |
| user/password | elasticsearchNom d'utilisateur utilisé/Mot de passe |
| index_name | indexNom défini |
| Tampon pour le journal,Pour mettre en cache les événements du Journal,Amélioration des performances du système.Utilisation de la mémoire par défaut,Peut également être utiliséfileDocumentation | |
| chunk_limit_size | Taille maximale par bloc:L'événement sera écrit dans le bloc,Jusqu'à ce que la taille du bloc devienne cette taille,La mémoire par défaut est8M,Documentation256M |
| queue_limit_length | Limite de longueur de file d'attente pour cette instance de plug - in tampon |
| flush_interval | Événement de rafraîchissement du Journal tampon,Par défaut60sRafraîchir la sortie une fois |
| retry_max_times | Nombre maximum de retraits de la sortie du bloc défaillant |
Ce qui précède ne sont que quelques paramètres de configuration,D'autres configurations peuvent être personnalisées avec des documents officiels.
Quatre、Fluentd + Minio Pratiques de collecte des journaux
Fluentd S3 Le plug - in de sortie écrit la journalisation à la norme S3 Services de stockage d'objets,Par exemple Amazon、Minio.
4.1 Procédure de fonctionnement
Application(Minio)Et plugins(Fluentd S3)Peut être déployé en un seul clic à travers le magasin open source.
Dock open source store.Recherche dans le magasin open source
minio,Et installer22.06.17Version.Vue de l'équipe -> Plug - in -> Installer à partir de l'app store
Fluentd-S3Plug - in.Accès à Minio 9090 Port,Le mot de passe de l'utilisateur est Minio Components -> Obtenir dans la dépendance.
Création Bucket,Nom personnalisé.
Entrée Configurations -> Region,Paramètres Service Location
- Fluentd Dans le fichier de configuration du plug - in
s3_regionPar défauten-west-test2.
- Fluentd Dans le fichier de configuration du plug - in
Créer un composant basé sur un miroir,Utilisation du miroir
nginx:latest,Et monter le stockagevar/log/nginx.Utilisez iciNginx:latestComme démo- Après avoir monté le stockage dans le composant,Le plug - in Monte également le stockage sur mesure,Et accessible Nginx Fichiers journaux générés.
Entrée dans Nginx Dans le module,Ouvert Fluentd S3 Plug - in,Modifier le
s3_buckets3_region
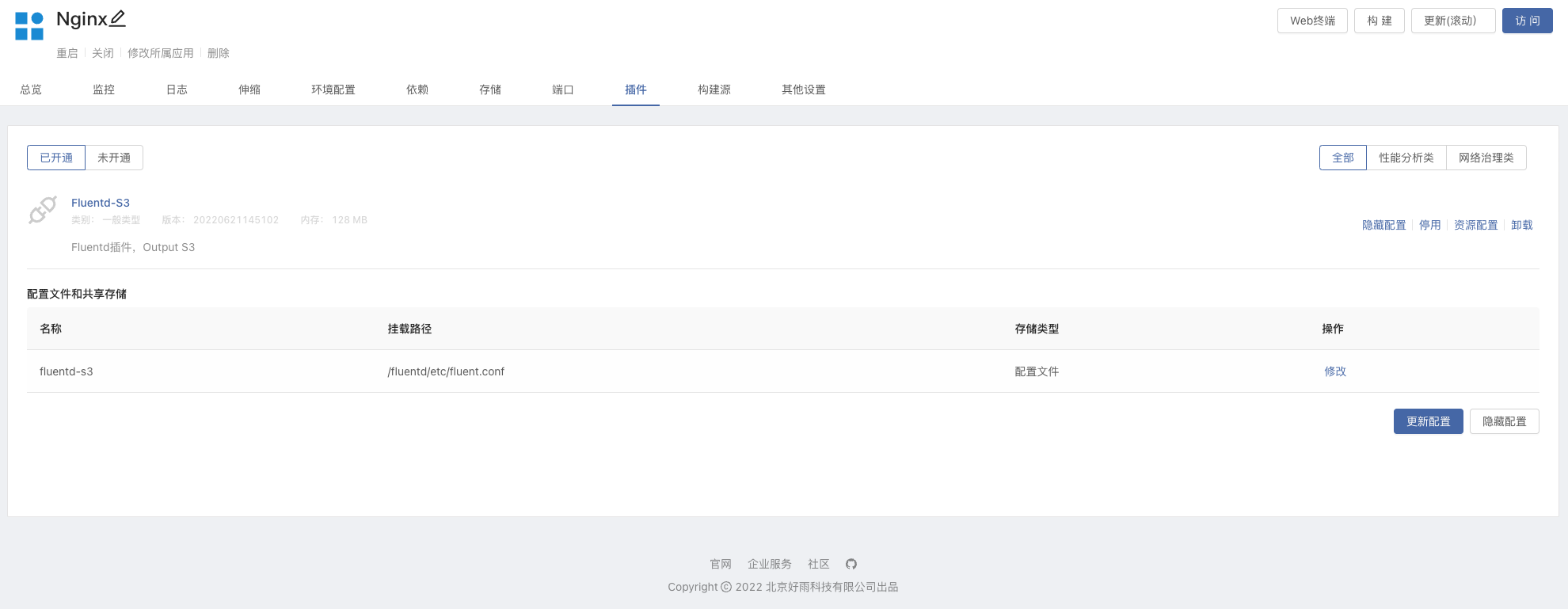
- Créer des dépendances,Nginx Dépendance des composants Minio,Mettre à jour le composant pour qu'il prenne effet.
- Accès à Nginx Services,Pour qu'il produise un journal,Dans un instant, vous pourrez Minio De Bucket Voir.

4.2 Profil Introduction
Référence du profil Fluentd Documentation Apache to Minio.
@type tail
path /var/log/nginx/access.log
pos_file /var/log/nginx/nginx.access.log.pos
tag minio.nginx.access
@type nginx
@type s3
aws\_key\_id "#{ENV['MINIO\_ROOT\_USER']}"
aws\_sec\_key "#{ENV['MINIO\_ROOT\_PASSWORD']}"
s3\_endpoint http://127.0.0.1:9000/
s3\_bucket test
s3\_region en-west-test2
time\_slice\_format %Y%m%d%H%M
force\_path\_style true
path logs/
@type file
path /var/log/nginx/s3
timekey 1m
timekey\_wait 10s
chunk\_limit\_size 256m
Explication de l'élément de configuration:
Source d'entrée du Journal:
| Éléments de configuration | Notes explicatives |
|---|---|
| @type | Type de journal d'acquisition,tailReprésente le contenu du Journal de lecture incrémental |
| path | Chemin du Journal,Plusieurs chemins peuvent être séparés par des virgules |
| pos_file | Pour marquer les fichiers qui ont été lus à l'emplacement(position file)Chemin |
| Résolution du format du Journal,Selon votre propre format de journal,Écrivez les règles d'analyse correspondantes. |
Sortie du Journal:
| Éléments de configuration | Notes explicatives |
|---|---|
| @type | Type de service exporté vers |
| aws_key_id | Minio Nom d'utilisateur |
| aws_sec_key | Minio Mot de passe |
| s3_endpoint | Minio Adresse d'accès |
| s3_bucket | Minio Nom du baril |
| force_path_style | Prévention AWS SDK Détruire le paramètre URL |
| time_slice_format | Chaque nom de fichier est estampillé avec cet horodatage |
| Tampon pour le journal,Pour mettre en cache les événements du Journal,Amélioration des performances du système.Utilisation de la mémoire par défaut,Peut également être utiliséfileDocumentation | |
| timekey | Chaque 60 Secondes pour rafraîchir une foischunk |
| timekey_wait | Attendez. 10 Rafraîchir en quelques secondes |
| chunk_limit_size | Taille maximale par bloc |
Enfin
Fluentd Le plug - in est flexible pour collecter les journaux d'affaires et produire plusieurs services,Et combiner Rainbond Installation d'un bouton sur le marché des plug - ins,Rendre notre utilisation plus simple、Rapide.
Pour l'instant Rainbond Sur le marché des applications plug - in Open Source Flunetd Le plugin n'a que Flunetd-S3Flunetd-ElasticSearch7,Bienvenue aux petits amis pour contribuer au plugin Oh!
边栏推荐
- 伯努利分布,二项分布和泊松分布以及最大似然之间的关系(未完成)
- Skywalking8.7 source code analysis (I): agent startup process, agent configuration loading process, custom class loader agentclassloader, plug-in definition system, plug-in loading
- pytorch DataLoader实现miniBatch(未完成)
- Kubernetes notes (10) kubernetes Monitoring & debugging
- CAD插件的安装和自动加载dll、arx
- Life is a process of continuous learning
- Convolution operation in convolution neural network CNN
- Apple submitted the new MAC model to the regulatory database before the spring conference
- Alibaba cloud Alipay sandbox payment
- Synthetic keyword and NBAC mechanism
猜你喜欢

Cesium 点击获三维坐标(经纬度高程)
![[teacher Zhao Yuqiang] use the catalog database of Oracle](/img/0b/73a7d12caf955dff17480a907234ad.jpg)
[teacher Zhao Yuqiang] use the catalog database of Oracle
Jedis source code analysis (I): jedis introduction, jedis module source code analysis

Svn branch management
![[teacher Zhao Yuqiang] Flink's dataset operator](/img/cc/5509b62756dddc6e5d4facbc6a7c5f.jpg)
[teacher Zhao Yuqiang] Flink's dataset operator
![[teacher Zhao Yuqiang] redis's slow query log](/img/a7/2140744ebad9f1dc0a609254cc618e.jpg)
[teacher Zhao Yuqiang] redis's slow query log
pytorch 搭建神经网络最简版
Simple solution of small up main lottery in station B
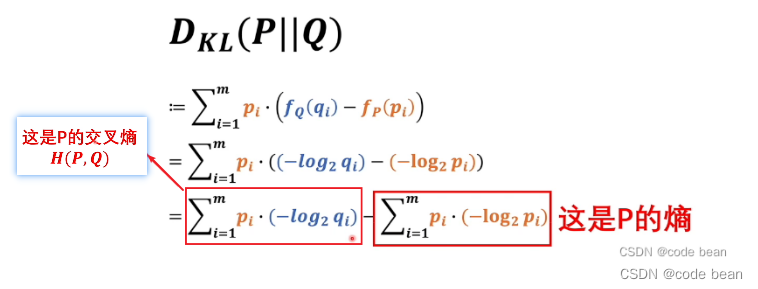
最大似然估计,散度,交叉熵

Migrate data from Mysql to tidb from a small amount of data
随机推荐
最大似然估计,散度,交叉熵
SVN分支管理
[teacher Zhao Yuqiang] MySQL high availability architecture: MHA
Kubernetes notes (II) pod usage notes
Phpstudy setting items can be accessed by other computers on the LAN
Exception when introducing redistemplate: noclassdeffounderror: com/fasterxml/jackson/core/jsonprocessingexception
[escape character] [full of dry goods] super detailed explanation + code illustration!
Strategy pattern: encapsulate changes and respond flexibly to changes in requirements
Solve the 1251 client does not support authentication protocol error of Navicat for MySQL connection MySQL 8.0.11
It is said that the operation and maintenance of shell scripts are paid tens of thousands of yuan a month!!!
[function explanation (Part 1)] | | knowledge sorting + code analysis + graphic interpretation
Exportation et importation de tables de bibliothèque avec binaires MySQL
ThreadLocal的简单理解
pytorch DataLoader实现miniBatch(未完成)
Virtual memory technology sharing
Method of converting GPS coordinates to Baidu map coordinates
智牛股项目--05
Download the corresponding version of chromedriver
1. 两数之和
有意思的鼠标指针交互探究