当前位置:网站首页>【多任务模型】Progressive Layered Extraction: A Novel Multi-Task Learning Model for Personalized(RecSys‘20)
【多任务模型】Progressive Layered Extraction: A Novel Multi-Task Learning Model for Personalized(RecSys‘20)
2022-08-01 19:53:00 【chad_lee】
腾讯的视频推荐团队,建模的目标包含用户的多种不同的行为:点击,分享,评论等等。每次请求,候选的排序分根据公式计算:
score = p V T R w V T R × p V C R w V C R × p S H R w S H R × … × p C M R w C M × f ( video l e n ) \text { score }=p V T R^{w V T R} \times p V C R^{w V C R} \times p S H R^{w S H R} \times \ldots \times p_{C M R}^{w C M} \times f(\text { video } l e n) score =pVTRwVTR×pVCRwVCR×pSHRwSHR×…×pCMRwCM×f( video len)
其中w是超参,表示相对重要性

多目标之间经常会有比较复杂的关系,因此同时建模多目标经常会出现跷跷板的现象,即多个任务negative transfer的问题:
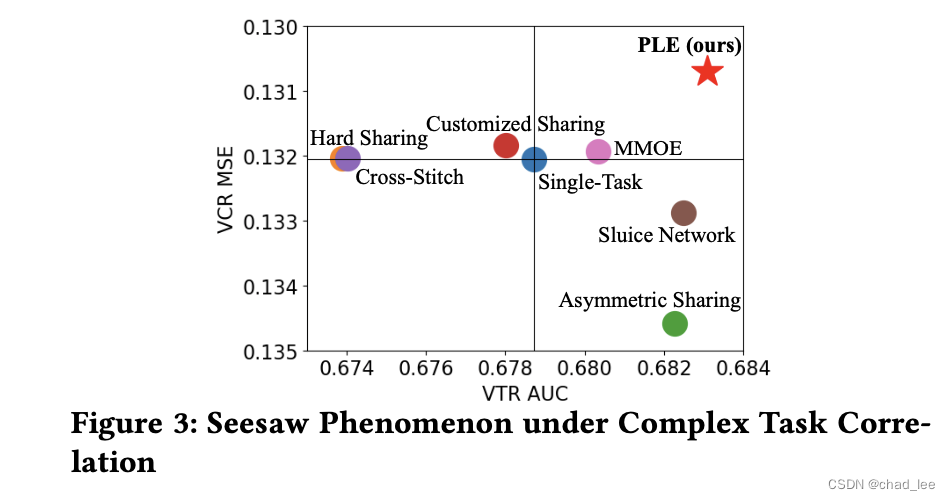
GCG
MMOE理论上存在一种可以自动选特征的最优情况,但这个情况依赖:1、gate能不能选出来;2、也依赖expert能不能产生多样性的特征(所有expert输出类似,无可奈何)。
因此本文提出的Customized Gate Control把这个问题变得简单了一些,把专家分为大同行和小同行,既有共享的expert们,每个task也有专门的expert们,难度小了一些。
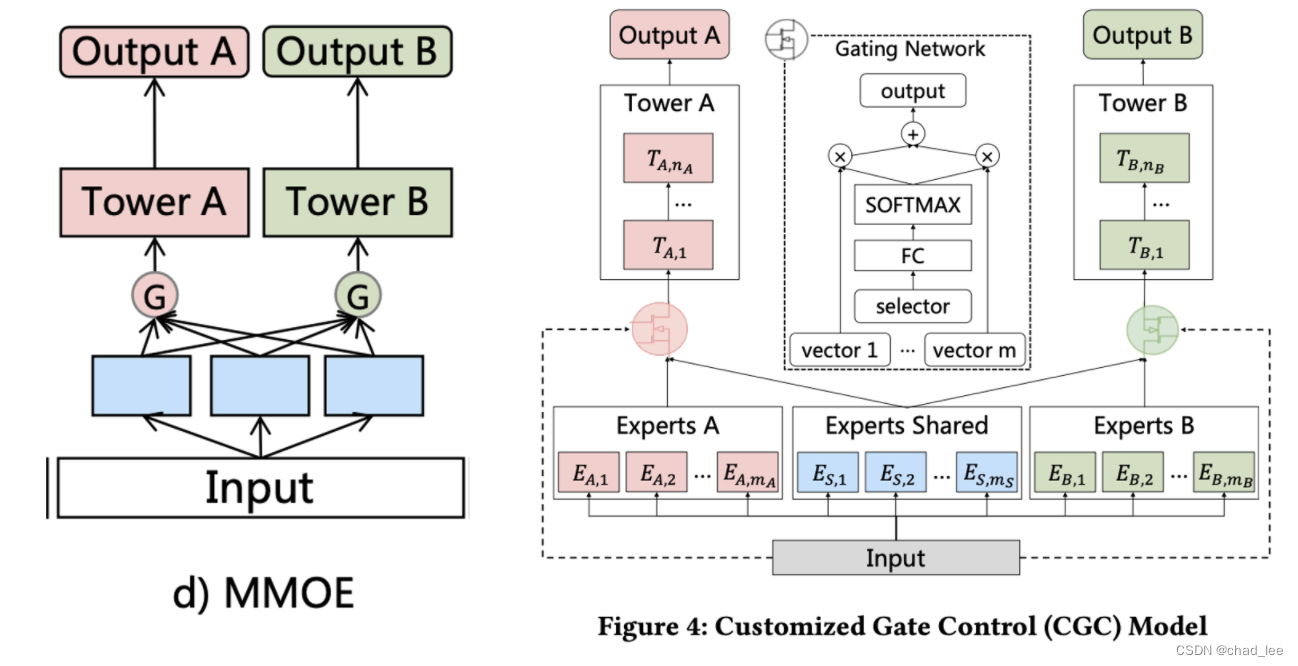
这样EA只被taskA训,EB只被taskB训,至少可以保底。
input是x,任务k的输出是
y k ( x ) = t k ( g k ( x ) ) y^{k}(x)=t^{k}\left(g^{k}(x)\right) yk(x)=tk(gk(x))
其中 t k t^k tk是这个任务的NN tower, g k ( x ) g^{k}(x) gk(x) 是第k个任务的门控网络的输出:
g k ( x ) = w k ( x ) S k ( x ) g^{k}(x)=w^{k}(x) S^{k}(x) gk(x)=wk(x)Sk(x)
其中x是原始输入, w k ( x ) w^{k}(x) wk(x)是一个加权函数,分别对应每个专家的权重,是一个softmax的输出:
w k ( x ) = Softmax ( W g k x ) w^{k}(x)=\operatorname{Softmax}\left(W_{g}^{k} x\right) wk(x)=Softmax(Wgkx)
其中 W g k ∈ R ( m k + m s ) × d W_{g}^{k} \in R^{\left(m_{k}+m_{s}\right) \times d} Wgk∈R(mk+ms)×d,mk和ms是 shared experts 和 specific experts 的个数。 S k ( x ) S^{k}(x) Sk(x)是所有专家的输出向量contack在一起的称之为selected matrix:
S k ( x ) = [ E ( k , 1 ) T , E ( k , 2 ) T , … , E ( k , m k ) T , E ( s , 1 ) T , E ( s , 2 ) T , … , E ( s , m s ) T ] T S^{k}(x)=\left[E_{(k, 1)}^{T}, E_{(k, 2)}^{T}, \ldots, E_{\left(k, m_{k}\right)}^{T}, E_{(s, 1)}^{T}, E_{(s, 2)}^{T}, \ldots, E_{\left(s, m_{s}\right)}^{T}\right]^{T} Sk(x)=[E(k,1)T,E(k,2)T,…,E(k,mk)T,E(s,1)T,E(s,2)T,…,E(s,ms)T]T
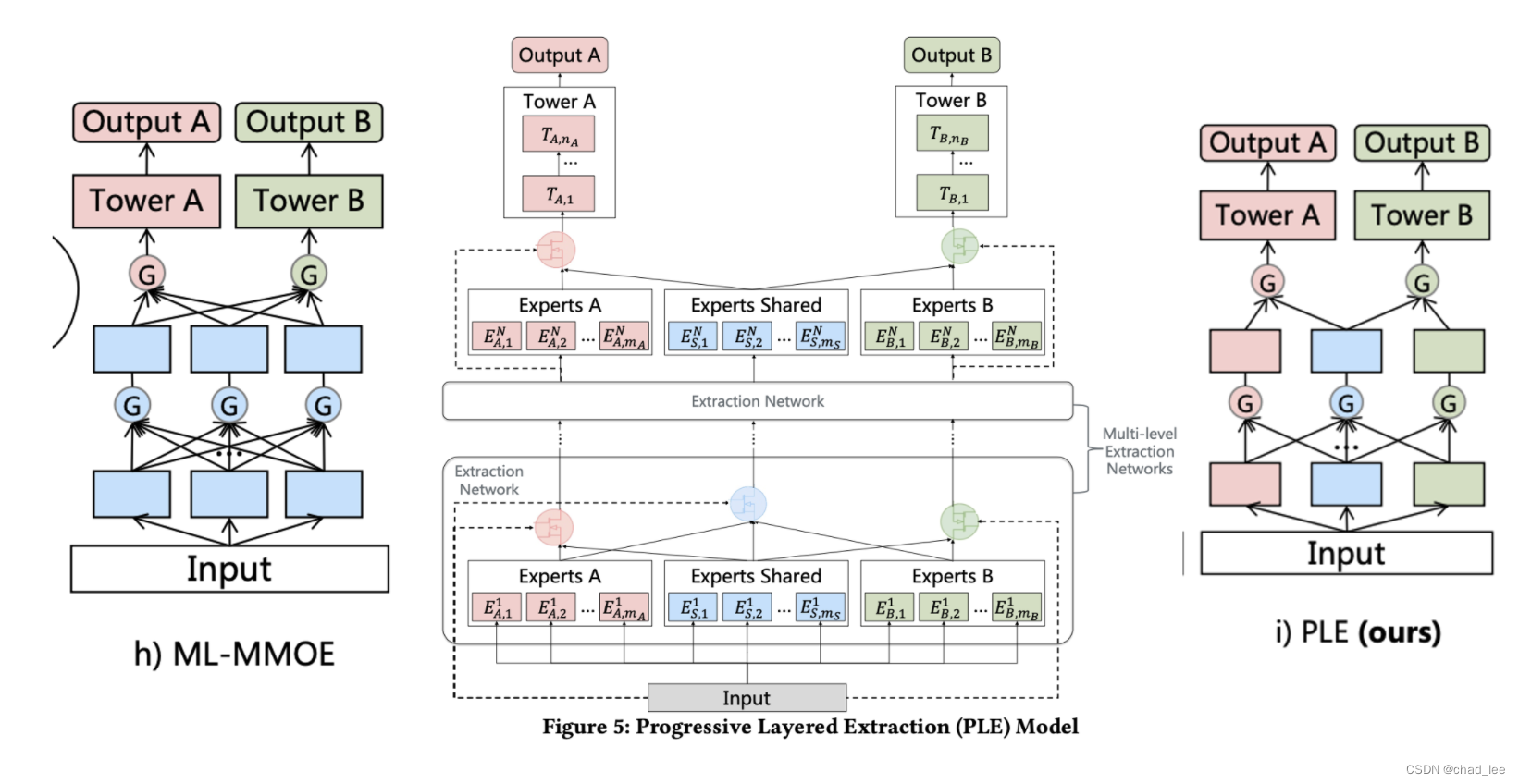
PLE
但是分了小同行后也有问题,不同task的辅助监督信号的作用又小了(因为和独立模型的区别就只有一个共享expert,能力有限)。所以PLE就是多接几层专家网络,让共享expert更强一些。
优化方法
一半多目标任务优化是针对不同的子任务设置不同的权重,损失函数加权:
L ( θ 1 , … … , θ K , θ s ) = ∑ k = 1 K ω k L k ( θ k , θ s ) L\left(\theta_{1}, \ldots \ldots, \theta_{K}, \theta_{s}\right)=\sum_{k=1}^{K} \omega_{k} L_{k}\left(\theta_{k}, \theta_{s}\right) L(θ1,……,θK,θs)=k=1∑KωkLk(θk,θs)
但是这篇文章更精细的考虑了训练样本空间不一致的问题:

比如用户只有点击后才能进行分享和评论。本文是在 Loss 上进行一定的优化,联合训练这些任务,在计算每个任务的损失时需要把样本空间相同的合并,并忽略不在自己样本空间的样本,即不同的任务仍使用其各自样本空间中的样本。我理解的意思是一次模型更新的时候,不会同时用SHR和CTR的loss来更新
同时这篇还考虑了不同任务设置一个动态权重,比如task k的初始loss权重为 ω k , 0 \omega_{k, 0} ωk,0,那么在第t个epoch的时候loss权重为:
ω k ( t ) = ω k , 0 × γ k t \omega_{k}^{(t)}=\omega_{k, 0} \times \gamma_{k}^{t} ωk(t)=ωk,0×γkt
其中 γ k t \gamma_{k}^{t} γkt 是上一步的更新率。
边栏推荐
- MySQL开发技巧——并发控制
- Mobile Zero of Likou Brush Questions
- Pytorch模型训练实用教程学习笔记:一、数据加载和transforms方法总结
- MySQL你到底都加了什么锁?
- GEE(8):使用MODIS填补由去云后的Landsat影像计算得到的NDVI数据
- XSS靶场中级绕过
- Win11怎么安装语音包?Win11语音包安装教程
- {ValueError}Number of classes, 1, does not match size of target_names, 2. Tr
- How to query database configuration parameters in GBase 8c, such as datestyle.What function or syntax to use?
- 数据库系统原理与应用教程(072)—— MySQL 练习题:操作题 121-130(十六):综合练习
猜你喜欢
有点奇怪!访问目的网址,主机能容器却不行

【蓝桥杯选拔赛真题47】Scratch潜艇游戏 少儿编程scratch蓝桥杯选拔赛真题讲解

XSS靶场中级绕过
Does LabVIEW really close the COM port using VISA Close?
如何看待腾讯云数据库负责人林晓斌借了一个亿炒股?

我的驾照考试笔记(4)

专利检索常用的网站有哪些?
Win10, the middle mouse button cannot zoom in and out in proe/creo

经验共享|在线文档协作:企业文档处理的最佳选择

Pytorch模型训练实用教程学习笔记:一、数据加载和transforms方法总结

随机推荐
使用Huggingface在矩池云快速加载预训练模型和数据集
Greenplum Database Source Code Analysis - Analysis of Standby Master Operation Tools
nacos安装与配置
How to install voice pack in Win11?Win11 Voice Pack Installation Tutorial
To drive efficient upstream and downstream collaboration, how can cross-border B2B e-commerce platforms release the core value of the LED industry supply chain?
升哲科技携全域数字化方案亮相2022全球数字经济大会
经验共享|在线文档协作:企业文档处理的最佳选择
使用微信公众号给指定微信用户发送信息
1个小时!从零制作一个! AI图片识别WEB应用!
密码学的基础:X.690和对应的BER CER DER编码
Redis 做签到统计
Gradle系列——Gradle文件操作,Gradle依赖(基于Gradle文档7.5)day3-1
密码学的基础:X.690和对应的BER CER DER编码
The graphic details Eureka's caching mechanism/level 3 cache
1个小时!从零制作一个! AI图片识别WEB应用!
OSPO 五阶段成熟度模型解析
【kali-信息收集】(1.2)SNMP枚举:Snmpwalk、Snmpcheck;SMTP枚举:smtp-user-enum
【1374. 生成每种字符都是奇数个的字符串】
deploy zabbix
mysql解压版简洁式本地配置方式