当前位置:网站首页>[PSQL] 窗口函数、GROUPING运算符
[PSQL] 窗口函数、GROUPING运算符
2022-08-02 05:01:00 【wy_hhxx】
SQL基础教程读书笔记 MICK,第8章 SQL高级处理
示例程序下载 http://www.ituring.com.cn/book/1880
说明:如下笔记中的测试基于postgresql14
命令行连接本地PSQL: psql -U <username> -d <dbname> -h 127.0.0.1 -W
目录
8 SQL高级处理
8-1 窗口函数
重点:
窗口函数可以进行排序、生成序列号等一般的聚合函数无法实现的高级操作。
理解PARTITION BY和ORDER BY这两个关键字的含义十分重要。
什么是窗口函数
窗口函数也称为 OLAP 函数。
OLAP 是 OnLine Analytical Processing 的简称,意思是对数据库数据进行实时分析处理。例如,市场分析、创建财务报表、创建计划等日常性
商务工作。窗口函数就是为了实现 OLAP 而添加的标准 SQL 功能。
窗口函数的语法
语法8-1 窗口函数
<窗口函数> OVER ([PARTITION BY <列清单>]
ORDER BY <排序用列清单>)
能够作为窗口函数使用的函数
(1)能够作为窗口函数的聚合函数(SUM、AVG、COUNT、MAX、MIN)
(2)RANK、DENSE_RANK、ROW_NUMBER 等专用窗口函数
使用RANK函数
例如,对于之前使用过的 Product 表中的 8 件商品,根据不同的商品种类(product_type),按照销售单价(sale_price)从低到高的顺序排序,结果如下所示。
代码清单8-1 根据不同的商品种类,按照销售单价从低到高的顺序创建排序表
SELECT product_name, product_type, sale_price,
RANK () OVER (PARTITION BY product_type
ORDER BY sale_price) AS ranking
FROM Product;执行结果:
product_name | product_type | sale_price | ranking
--------------+--------------+------------+---------
圆珠笔 | 办公用品 | 100 | 1
打孔器 | 办公用品 | 500 | 2
叉子 | 厨房用具 | 500 | 1
擦菜板 | 厨房用具 | 880 | 2
菜刀 | 厨房用具 | 3000 | 3
高压锅 | 厨房用具 | 6800 | 4
T恤衫 | 衣服 | 1000 | 1
运动T恤 | 衣服 | 4000 | 2
(8 rows)
shop=#
说明:
PARTITION BY 能够设定排序的对象范围。本例中,为了按照商品种类进行排序,我们指定了 product_type。
ORDER BY 能够指定按照哪一列、何种顺序进行排序。为了按照销售单价的升序进行排列,我们指定了 sale_price。
通过 PARTITION BY 分组后的记录集合称为窗口。
无需指定PARTITION BY
PARTITION BY 并不是必需的,不指定就是将整个表作为一个大的窗口来使用。
代码清单8-2 不指定PARTITION BY
SELECT product_name, product_type, sale_price,
RANK () OVER (ORDER BY sale_price) AS ranking
FROM Product;执行结果:
product_name | product_type | sale_price | ranking
--------------+--------------+------------+---------
圆珠笔 | 办公用品 | 100 | 1
打孔器 | 办公用品 | 500 | 2
叉子 | 厨房用具 | 500 | 2
擦菜板 | 厨房用具 | 880 | 4
T恤衫 | 衣服 | 1000 | 5
菜刀 | 厨房用具 | 3000 | 6
运动T恤 | 衣服 | 4000 | 7
高压锅 | 厨房用具 | 6800 | 8
(8 rows)
shop=#
专用窗口函数的种类
@RANK函数
计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
例如,有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位……
@DENSE_RANK函数
同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
例如,有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位……
@ROW_NUMBER函数
赋予唯一的连续位次。
例如,有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位……
代码清单8-3 比较RANK、DENSE_RANK、ROW_NUMBER的结果
SELECT product_name, product_type, sale_price,
RANK () OVER (ORDER BY sale_price) AS ranking,
DENSE_RANK () OVER (ORDER BY sale_price) AS dense_ranking,
ROW_NUMBER () OVER (ORDER BY sale_price) AS row_num
FROM Product;执行结果:
product_name | product_type | sale_price | ranking | dense_ranking | row_num
--------------+--------------+------------+---------+---------------+---------
圆珠笔 | 办公用品 | 100 | 1 | 1 | 1
打孔器 | 办公用品 | 500 | 2 | 2 | 2
叉子 | 厨房用具 | 500 | 2 | 2 | 3
擦菜板 | 厨房用具 | 880 | 4 | 3 | 4
T恤衫 | 衣服 | 1000 | 5 | 4 | 5
菜刀 | 厨房用具 | 3000 | 6 | 5 | 6
运动T恤 | 衣服 | 4000 | 7 | 6 | 7
高压锅 | 厨房用具 | 6800 | 8 | 7 | 8
(8 rows)
shop=#
使用上述专用窗口函数无需任何参数,只需要像 RANK () 这样保持括号中为空就可以了。这也是专用窗口函数通常的使用方式。
窗口函数的适用范围
使用窗口函数只能在 SELECT 子句之中。
反过来说,就是这类函数不能在 WHERE 子句或者 GROUP BY 子句中使用。为什么? -->
在 DBMS 内部,窗口函数是对 WHERE 子句或者 GROUP BY 子句处理后的“结果”进行的操作。
作为窗口函数使用的聚合函数
所有的聚合函数都能用作窗口函数,其语法和专用窗口函数完全相同。
代码清单8-4 将SUM函数作为窗口函数使用
SELECT product_id, product_name, sale_price,
SUM (sale_price) OVER (ORDER BY product_id) AS current_sum
FROM Product;执行结果:
product_id | product_name | sale_price | current_sum
------------+--------------+------------+-------------
0001 | T恤衫 | 1000 | 1000
0002 | 打孔器 | 500 | 1500
0003 | 运动T恤 | 4000 | 5500
0004 | 菜刀 | 3000 | 8500
0005 | 高压锅 | 6800 | 15300
0006 | 叉子 | 500 | 15800
0007 | 擦菜板 | 880 | 16680
0008 | 圆珠笔 | 100 | 16780
(8 rows)
shop=#
说明:本例中我们计算出了销售单价(sale_price)的合计值(current_sum)。
按照 ORDER BY 子句指定的 product_id 的升序进行排列,计算出商品编号“小于自己”的商品的销售单价的合计值。因此,计算该合计值的逻辑就像金字塔堆积那样,一行一行逐渐添加计算对象。
代码清单8-5 将AVG函数作为窗口函数使用
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id) AS current_avg
FROM Product;执行结果:
product_id | product_name | sale_price | current_avg
------------+--------------+------------+-----------------------
0001 | T恤衫 | 1000 | 1000.0000000000000000
0002 | 打孔器 | 500 | 750.0000000000000000
0003 | 运动T恤 | 4000 | 1833.3333333333333333
0004 | 菜刀 | 3000 | 2125.0000000000000000
0005 | 高压锅 | 6800 | 3060.0000000000000000
0006 | 叉子 | 500 | 2633.3333333333333333
0007 | 擦菜板 | 880 | 2382.8571428571428571
0008 | 圆珠笔 | 100 | 2097.5000000000000000
(8 rows)
shop=#
说明:对于current_avg ,作为统计对象的只是“排在自己之上”的记录。像这样 以“自身记录(当前记录)” 作为基准进行统计,就是将聚合函数当作窗 口函数使用时的最大特征。
计算移动平均
窗口函数就是将表以窗口为单位进行分割,并在其中进行排序的函数。
其中还包含在窗口中指定更加详细的汇总范围的备选功能,该备选功能中的汇总范围称为框架。
代码清单8-6 指定“最靠近的3行”作为汇总对象
注:在 ORDER BY 子句之后使用指定范围的关键字
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id
ROWS 2 PRECEDING) AS moving_avg
FROM Product;执行结果:

@指定框架(汇总范围)
上述例子我们使用了 ROWS(“行”)和 PRECEDING(“之前”)两个关键字,将框架指定为“截止到之前 ~ 行”,因此“ROWS 2 PRECEDING”就是将框架指定为“截止到之前 2 行”,也就是将作为汇总对象的记录限定为如下的“最靠近的 3 行”。
- 自身(当前记录)
- 之前 1行的记录
- 之前 2行的记录
这样的统计方法称为移动平均(moving average)。由于这种方法在希望实时把握“最近状态”时非常方便,因此常常会应用在对股市趋势的实时跟踪当中。
使用关键字 FOLLOWING 替换 PRECEDING,就可以指定“截止到之后 ~ 行”作为框架了。
@将当前记录的前后行作为汇总对象
代码清单8-7 将当前记录的前后行作为汇总对象
SELECT product_id, product_name, sale_price,
AVG (sale_price) OVER (ORDER BY product_id
ROWS BETWEEN 1 PRECEDING AND
1 FOLLOWING) AS moving_avg
FROM Product;执行结果:

在上述代码中,我们通过指定框架,将“1 PRECEDING”(之前 1 行)和“1 FOLLOWING”(之后 1 行)的区间作为汇总对象。即将如下 3 行作为汇总对象来进行计算。
- 之前 1行的记录
- 自身(当前记录)
- 之后 1行的记录
两个ORDER BY
OVER 子句中的 ORDER BY 只是用来决定窗口函数按照什么样的顺序进行计算的,对结果的排列顺序并没有影响。
代码清单8-8 无法保证如下SELECT语句的结果的排列顺序
SELECT product_name, product_type, sale_price,
RANK () OVER (ORDER BY sale_price) AS ranking
FROM Product;说明:我在自己的环境测试的结果看着是已排序的
代码清单8-9 在语句末尾使用ORDER BY子句对结果进行排序
SELECT product_name, product_type, sale_price,
RANK () OVER (ORDER BY sale_price) AS ranking
FROM Product
ORDER BY ranking;8-2 GROUPING运算符
同时得到合计行
代码清单8-11 分别计算出合计行和汇总结果再通过UNION ALL进行连接
shop=# SELECT '合计' AS product_type, SUM(sale_price) FROM Product
shop-# UNION ALL SELECT product_type, SUM(sale_price) FROM Product GROUP BY product_type;
product_type | sum
--------------+-------
合计 | 16780
衣服 | 5000
办公用品 | 600
厨房用具 | 11180
(4 rows)
shop=#ROLLUP 同时得出合计和小计
@ROLLUP的使用方法
代码清单8-12 使用ROLLUP同时得出合计和小计
shop=# SELECT product_type, SUM(sale_price) AS sum_price
shop-# FROM Product GROUP BY ROLLUP(product_type);
product_type | sum_price
--------------+-----------
| 16780
衣服 | 5000
办公用品 | 600
厨房用具 | 11180
(4 rows)
shop=#说明:
1.在MySQL中执行代码 --> “GROUP BY product_type WITH ROLLUP;”
2. ROLLUP (< 列 1>,< 列 2>,...)--> 一次计算出不同聚合键组合的结果
例如,在本例中就是一次计算出了如下两种组合的汇总结果
① GROUP BY () 表示没有聚合键,也就相当于没有 GROUP BY 子句
② GROUP BY (product_type)
@将“登记日期”添加到聚合键当中
代码清单8-13 在GROUP BY中添加“登记日期”(不使用ROLLUP)
SELECT product_type, regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY product_type, regist_date;执行结果:

代码清单8-14 在GROUP BY中添加“登记日期”(使用ROLLUP)
SELECT product_type, regist_date, SUM(sale_price) AS sum_price FROM Product
GROUP BY ROLLUP(product_type, regist_date);执行结果:

说明:
1.在MySQL中执行代码 --> “GROUP BY product_type, regist_date WITH ROLLUP;”
2.该 SELECT 语句的结果相当于使用 UNION 对如下 3 种模式的聚合级的不同结果进行连接。
① GROUP BY ()
② GROUP BY (product_type)
③ GROUP BY (product_type, regist_date)
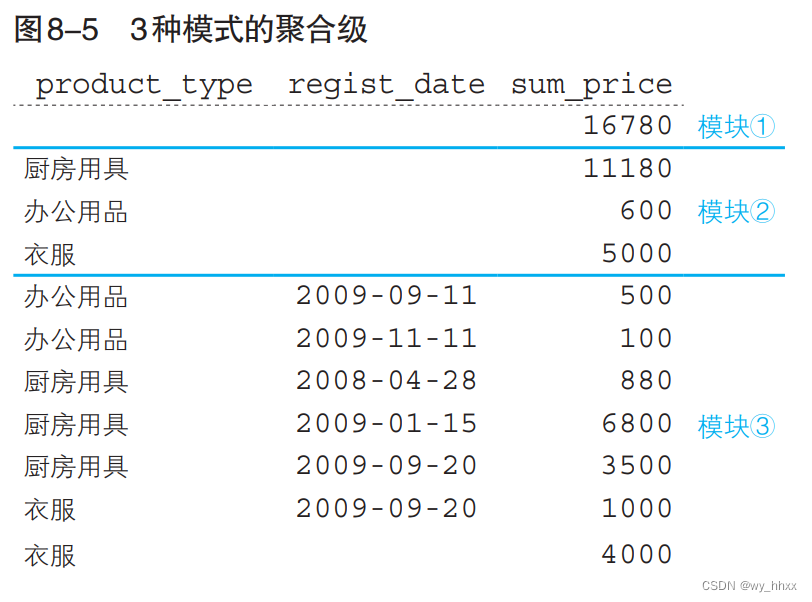
@GROUPING函数 让NULL更加容易分辨
SQL 提供了一个用来判断超级分组记录的 NULL 的特定函数 -> GROUPING 函数
该函数在其参数列的值为超级分组记录所产生的 NULL 时返回 1,其它情况返回 0
代码清单8-15 使用GROUPING函数来判断NULL
SELECT GROUPING(product_type) AS product_type, GROUPING(regist_date) AS regist_date, SUM(sale_price) AS sum_price FROM Product
GROUP BY ROLLUP(product_type, regist_date);执行结果:
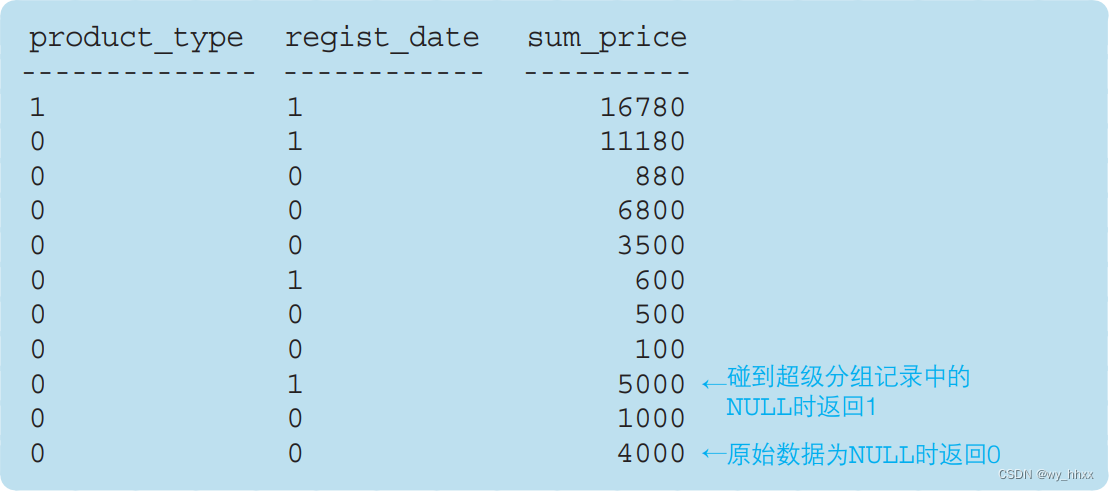
这样就能分辨超级分组记录中的 NULL 和原始数据本身的 NULL 了。 使用 GROUPING 函数还能在超级分组记录的键值中插入字符串。也就是说,当 GROUPING 函数的返回值为 1 时,指定“合计”或者“小计”等 字符串,其他情况返回通常的列的值。
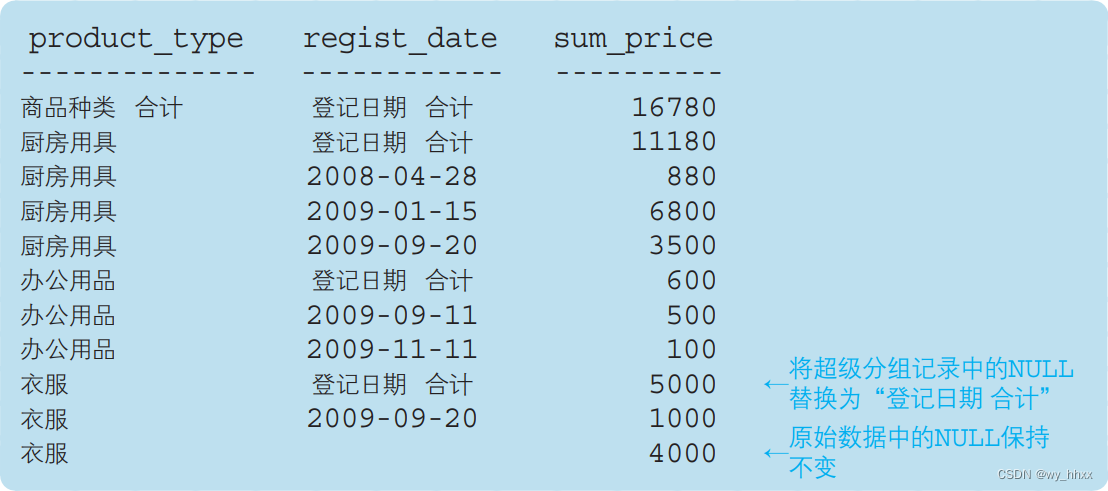
代码清单8-16 在超级分组记录的键值中插入恰当的字符串
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);说明:regist_date 列转换为 CAST (regist_date AS VARCHAR(16))形式的字符串,是为了满足 CASE 表达式所有分支的返回值必须一致的条件。
执行结果:
附:
法则 8-1 窗口函数兼具分组和排序两种功能。
法则 8-2 通过PARTITION BY分组后的记录集合称为“窗口”。
法则 8-3 由于专用窗口函数无需参数,因此通常括号中都是空的。
法则 8-4 原则上窗口函数只能在SELECT子句中使用。
法则 8-5 将聚合函数作为窗口函数使用时,会以当前记录为基准来决定汇总对象的记录。
法则 8-6 超级分组记录默认使用NULL作为聚合键。
法则 8-6 超级分组记录默认使用NULL作为聚合键。
法则 8-8 使用GROUPING函数能够简单地分辨出原始数据中的NULL和超级分组记录中的NULL。
边栏推荐
猜你喜欢

认识CAN光纤转换器的光纤接口和配套光纤线缆

ORA-04044:此处不允许过程、函数、程序包或类型,系统分析与解决
Android studio连接MySQL并完成简单的登录注册功能

MYSQL 唯一约束
Does Conway's Law Matter for System Architecture?

18年程序员生涯,读了200多本编程书,挑出一些精华分享给大家
MySQL导入sql文件的三种方法

MySQL 8.0.28 version installation and configuration method graphic tutorial

PDF file conversion format

一线大厂软件测试流程(思维导图)详解
随机推荐
Grid布局介绍
go项目的打包部署
MySQL如何创建用户
IOT物联网概述及应用层架构入门篇
SQL数据表增加列
MySql字符串拆分实现split功能(字段分割转列、转行)
Jmeter使用多线程测试web接口
从DES走到AES(现代密码的传奇之路)
UE4 创建暂停和结束游戏UI
Mysql常用命令大全
MySQL(7)
11种你需要了解的物联网(IoT)协议
浏览器的onload事件
MySQL multi-table association one-to-many query to get the latest data
MySQL 5.7 detailed download, installation and configuration tutorial
【Gazebo入门教程】第一讲 Gazebo的安装、UI界面、SDF文件介绍
Detailed explanation of AMQP protocol
ELK log analysis system
软件测试常见的问题
元宇宙:活在未来