当前位置:网站首页>Masked Autoencoders Are Scalable Vision Learners (MAE)
Masked Autoencoders Are Scalable Vision Learners (MAE)
2022-07-05 22:46:00 【Lian Li o】
Catalog
Introduction
- stay ViT Of paper in , The author dug the pit of self supervised learning , and MAE (Masked AutoEncoders) It belongs to the work of filling the pit , it stay ImageNet It even achieves the effect comparable to supervised learning through self encoder , This is CV The subsequent large-scale model training in the field has laid a solid foundation
Autoencoders ( Self encoder ) Medium Auto It means self supervised learning , On behalf of model learning label From the picture itself
Approach
Motivation
- MAE Be similar to BERT Medium MLM, By means of CV Field is introduced into Masked autoencoding To conduct self supervised learning . In a further introduction MAE Before the structure , We can take a look at NLP and CV in masked autoencoding The difference between :
- (1) Architectural gap: in the past ,CNN Has always been a CV The most popular model in the field , And integrate in convolution mask tokens But not so intuitive . But fortunately , This problem has been Vision Transformers (ViT) It's solved
- (2) Information density: The information density of language and vision is different . Language is an artificial signal with high information density containing a lot of semantics , When we train a model to predict the hidden words in a sentence , Models require complex language understanding . But the image is a natural signal with a lot of spatial redundant information , For example, an occluded pixel can be simply interpolated by adjacent pixels without any high-level understanding of the image . This problem can be solved in a very simple way : Randomly mask most of the pictures patches, This helps to reduce the information redundancy of the image and promote the overall understanding of the image by the model ( In the following figure, from left to right masked image、MAE reconstruction and ground-truth, The covering ratio is 80%)

- (3) The autoencoder’s decoder: The decoder of the self encoder is responsible for mapping the implicit representation obtained by the encoder back to the input space . In language tasks , The decoder is responsible for reconstructing high semantic level words , therefore BERT There is only one decoder in MLP. But in visual tasks , The decoder is responsible for reconstructing pixels at low semantic levels , here The design of decoder is very important , It must have enough ability to restore the information obtained by the encoder to low semantic level information
MAE
- MAE It is a simple self encoder , Be similar to BERT Medium MLM,MAE adopt Some of the random occlusion images patches And reconstruct to carry out self supervised learning . Through the above analysis , We can design the following structure :
- (1) MAE Randomly mask most of the input image patches (e.g., 75%) And reconstruct it in the pixel space .Mask token Is a vector that can be learned
- (2) use Asymmetric encoder-decoder framework , Encoder Only for uncovered patches Encoding , more Lightweight decoder For all patches refactoring ( Including the vector sum obtained by the encoder Mask token, And they all have to add positional embeddings). This asymmetrical design can save a lot of computation , Further improve MAE extensibility (“ Asymmetric ” It means that the encoder only sees part patches, The decoder sees everything patches, Handle all at the same time patches Our decoder is lighter )
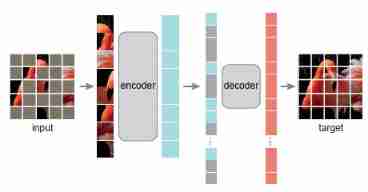
- (3) Loss function . The last layer of the decoder is a linear layer , Each output represents a patch Pixel value . The loss function uses Mean square loss (MSE), also Loss only in masked patches Count up (This choice is purely result-driven: computing the loss on all pixels leads to a slight decrease in accuracy (e.g., ∼0.5%).). besides , We also studied a variant , Let the decoder predict patches Of normalized pixel values, This helps to improve the quality of life representation quality ( Of course , This variant method must be known to be covered in advance patches The mean and variance of , Therefore, it doesn't work when making image reconstruction prediction )
After pre-training, the decoder is discarded and the encoder is applied to uncorrupted images (full sets of patches) for recognition tasks.
Simple implementation (no sparse operations are needed)
- (1) Through the linear projection layer and positional embedding Enter... For each patch All generate a token
- (2) Random shuffle all token Sequence and according to masking ratio Remove a large part of the end tokens, And that creates visible patches For input encoder . After the encoder finishes encoding , And then encoded patches After the sequence, add mask tokens, And restore the whole sequence to the original sequence , Then add the position coding and send it to the decoder (This simple implementation introduces negligible overhead as the shuffling and unshuf-fling operations are fast.)
Experiments
ImageNet Experiments
- We are ImageNet-1K On the training set Self supervised pre training , Then do it on the same data set There's supervised training To test the effect of self supervised learning . When doing supervised learning , Two methods are used :(1) end-to-end fine-tuning, It is allowed to change all parameters of the model during supervised learning ;(2) linear probing, In supervised learning, only the parameters of the last linear layer of the model can be changed
- Baseline: ViT-Large (ViT-L/16). because ViT-L The model is very large , stay ImageNet It is easy to over fit , So we added Strong regularization (scratch, our impl.) And trained 200 individual epoch, But the result is still worse than just fine-tune 了 50 individual epoch Of MAE:

Main Properties
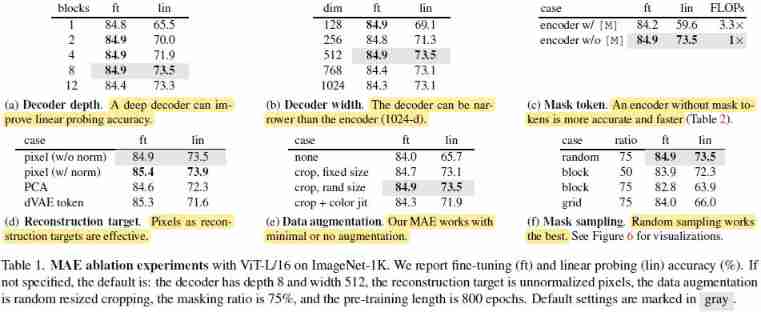
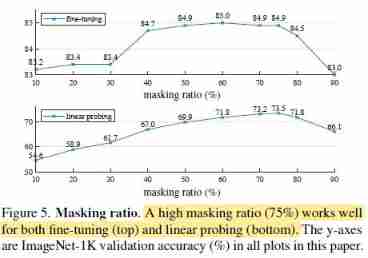
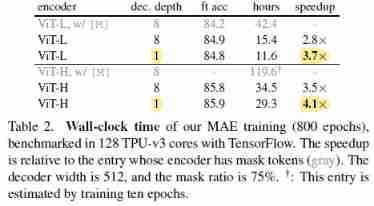

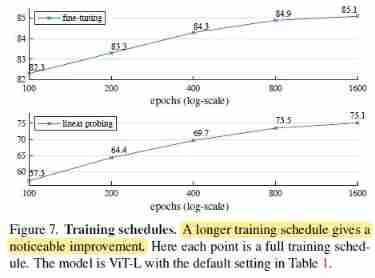
Comparisons with Previous Results
Comparisons with self-supervised methods
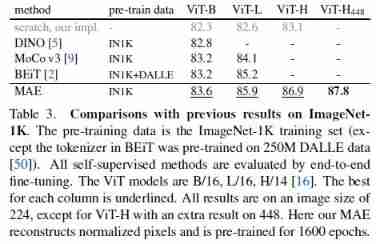
Comparisons with supervised pre-training
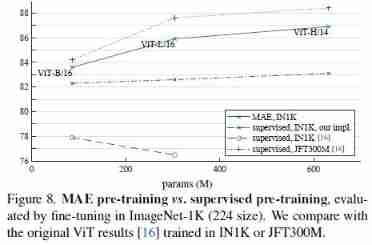
Partial Fine-tuning
Transfer Learning Experiments
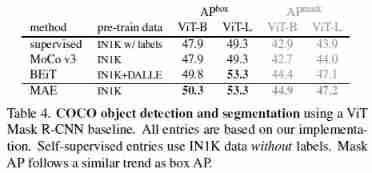
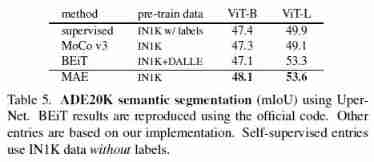
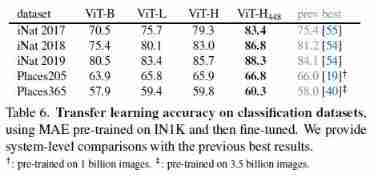
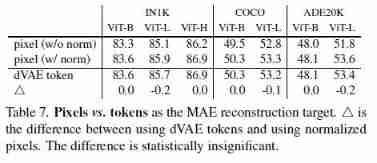
References
边栏推荐
- Global and Chinese markets for welding products 2022-2028: Research Report on technology, participants, trends, market size and share
- Nanjing: full use of electronic contracts for commercial housing sales
- 3 find the greatest common divisor and the least common multiple
- What if the files on the USB flash disk cannot be deleted? Win11 unable to delete U disk file solution tutorial
- Qtquick3d real time reflection
- FBO and RBO disappeared in webgpu
- Metaverse Ape上线倒计时,推荐活动火爆进行
- Vcomp110.dll download -vcomp110 What if DLL is lost
- The difference between MVVM and MVC
- [Chongqing Guangdong education] National Open University autumn 2018 0088-21t Insurance Introduction reference questions
猜你喜欢
EasyCVR集群部署如何解决项目中的海量视频接入与大并发需求?
第一讲:蛇形矩阵

Google Maps case
Kubernetes Administrator certification (CKA) exam notes (IV)
![[secretly kill little buddy pytorch20 days] - [Day2] - [example of picture data modeling process]](/img/41/4de83d2c81b9e3485d503758e12108.jpg)
[secretly kill little buddy pytorch20 days] - [Day2] - [example of picture data modeling process]
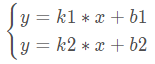
Distance entre les points et les lignes
![[untitled]](/img/98/aa874a72f33edf416f38cb6e92f654.png)
[untitled]
audiopolicy
Paddy serving v0.9.0 heavy release multi machine multi card distributed reasoning framework
Nacos 的安装与服务的注册
随机推荐
ESP32 hosted
Nacos 的安装与服务的注册
如何创建线程
344. Reverse String. Sol
My experience and summary of the new Zhongtai model
The introduction to go language is very simple: String
南京:全面启用商品房买卖电子合同
How can Bluetooth in notebook computer be used to connect headphones
點到直線的距離直線的交點及夾角
TOPSIS code part of good and bad solution distance method
Global and Chinese market of water treatment technology 2022-2028: Research Report on technology, participants, trends, market size and share
Nanjing: full use of electronic contracts for commercial housing sales
509. Fibonacci Number. Sol
Double pointer of linked list (fast and slow pointer, sequential pointer, head and tail pointer)
The code generator has deoptimised the styling of xx/typescript.js as it exceeds the max of 500kb
The countdown to the launch of metaverse ape is hot
Binary tree (III) -- heap sort optimization, top k problem
Shelved in TortoiseSVN- Shelve in TortoiseSVN?
Nacos 的安装与服务的注册
Character conversion PTA