当前位置:网站首页>Hudi学习笔记(三) 核心概念剖析
Hudi学习笔记(三) 核心概念剖析
2022-07-03 09:00:00 【小胡今天有变强吗】
文章目录
3. Hudi核心概念剖析
3.1 基本概念
Hudi 提供了Hudi 表的概念,这些表支持CRUD操作,可以利用现有的大数据集群比如HDFS做数据文件存储,然后使 用SparkSQL或Hive等分析引擎进行数据分析查询。
Hudi表的三个主要组件:
1)有序的时间轴元数据,类似于数据库事务日志;
2)分层布局的数据文件:实际写 入表中的数据;
3)索引(多种实现方式):映射包含指定记录的数据集。
3.1.1 时间轴Timeline
Hudi 核心:在所有的表中维护了一个包含在不同的即时(Instant)时间对数据集操作(比如新增、修改或删除) 的时间轴(Timeline)。
在每一次对Hudi表的数据集操作时都会在该表的Timeline上生成一个Instant,从而可以实现在仅查询某个时间点 之后成功提交的数据,或是仅查询某个时间点之前的数据,有效避免了扫描更大时间范围的数据。
可以高效地只查询更改前的文件(如在某个Instant提交了更改操作后,仅query某个时间点之前的数据,则 仍可以query修改前的数据)。
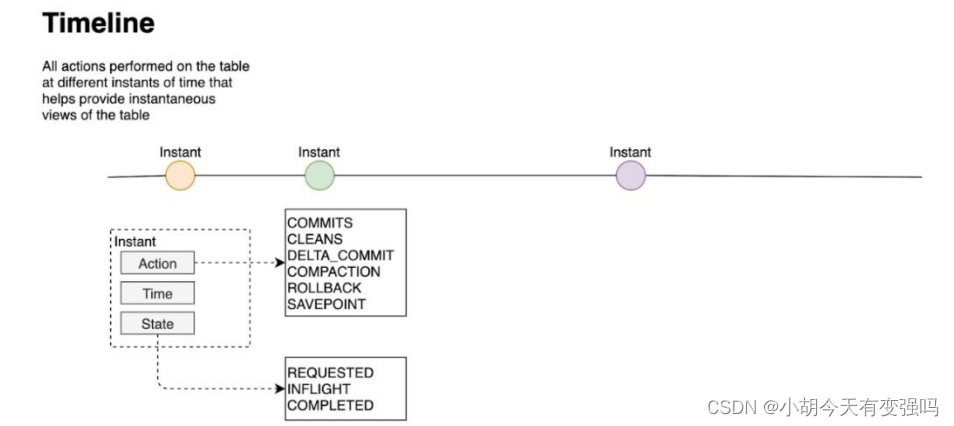
Timeline 是 Hudi 用来管理提交(commit)的抽象,每个 commit 都绑定一个固定时间戳,分散到时间线上。
在 Timeline 上,每个 commit 被抽象为一个 HoodieInstant,一个 instant 记录了一次提交 (commit) 的行为 、时间戳、和状态。
下图中采用时间(小时)作为分区字段,从 10:00 开始陆续产生各种 commits,10:20 来了一条 9:00 的数据, 该数据仍然可以落到 9:00 对应的分区,通过 timeline 直接消费 10:00 之后的增量更新(只消费有新 commits 的 group),那么这条延迟的数据仍然可以被消费到。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TGrRplFK-1654996918969)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220611204955345.png)]](/img/68/eab6796d847a4f34eb16bdafe4ddf5.png)
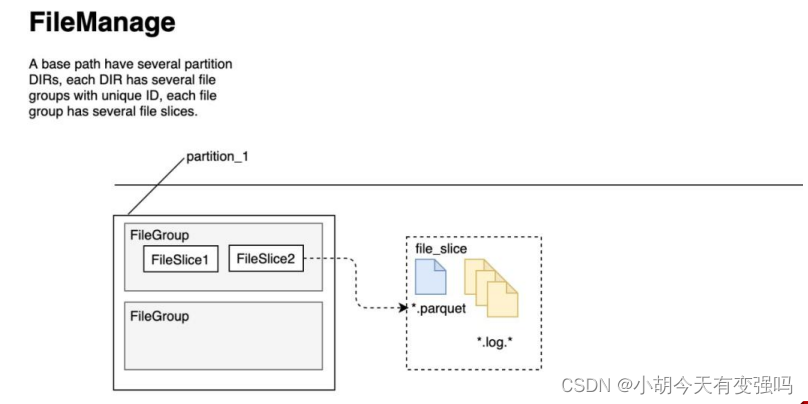
3.1.2 文件管理
Hudi将DFS上的数据集组织到基本路径(HoodieWriteConfig.BASEPATHPROP)下的目录结构中。
数据集分为多个分区(DataSourceOptions.PARTITIONPATHFIELDOPT_KEY),这些分区与Hive表非常相似,是包含 该分区的数据文件的文件夹。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xLBFkaUH-1654996918970)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220611205404177.png)]](/img/40/1f9c38b2c5676455e2411c537fa67f.png)
在每个分区内,文件被组织为文件组,由文件id充当唯一标识。每个文件组包含多个文件切片,其中每个切片包含 在某个即时时间的提交/压缩生成的基本列文件(.parquet)以及一组日志文件(.log),该文件包含自生成基本 文件以来对基本文件的插入/更新。
Hudi 的 base file (parquet 文件) 在 footer 的 meta 去记录了 record key 组成的 BloomFilter,用于在 file based index 的实现中实现高效率的 key contains 检测。
Hudi 的 log (avro 文件)是自己编码的,通过积攒数据 buffer 以 LogBlock 为单位写出,每个 LogBlock 包 含 magic number、size、content、footer 等信息,用于数据读、校验和过滤。
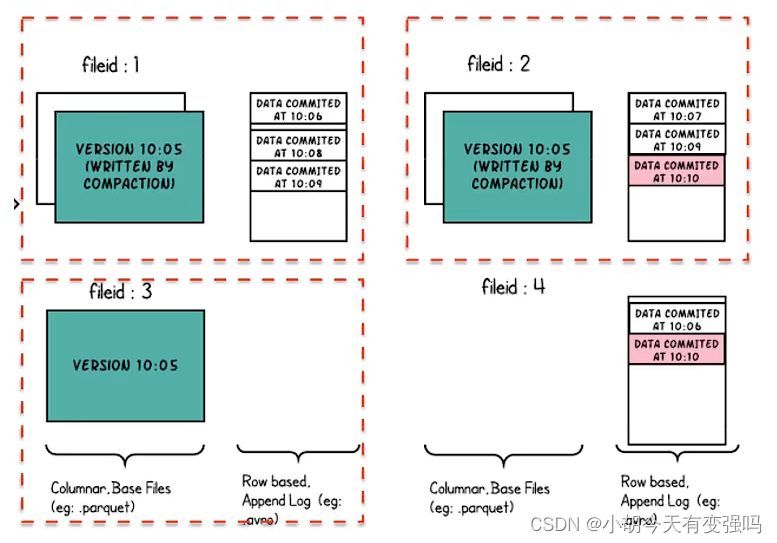
Hudi 存储管理总结:
3.1.3 索引 Index
- Hudi通过索引机制提供高效的Upsert操作,该机制会将一个RecordKey+PartitionPath组合的方式作为唯一标识映射到一个文件ID,而且这个唯一标识和文件组/文件ID之间的映射自记录被写入文件组开始就不会再改变。
- 全局索引:在全表的所有分区范围下强制要求键保持唯一,即确保对给定的键有且只有一个对应的记录。
- 非全局索引:仅在表的某一个分区内强制要求键保持唯一,它依靠写入器为同一个记录的更删提供一致的分区路径。

3.2 表的存储类型
Hudi提供两类型表:写时复制(Copy on Write,COW)表和读时合并(Merge On Read,MOR)表。
- 对于 Copy-On-Write Table,用户的 update 会重写数据所在的文件,所以是一个写放大很高,但是读放大为 0,适合写少读 多的场景。
- 对于 Merge-On-Read Table,用户的写入先写入到 delta data 中,这部分数据使用行存,这部分 delta data 可以手动 merge 到存量文件中,整理为 parquet 的列存结构,适合读少写多的场景。
3.2.1 数据的计算模型
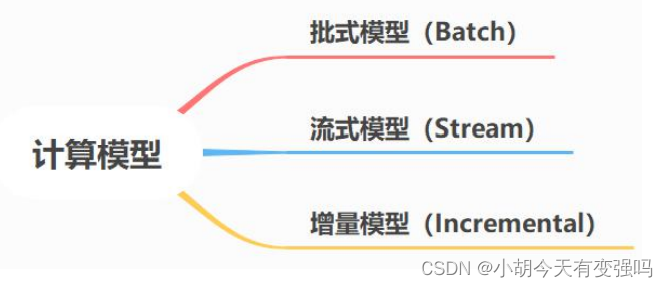
- 批式模型(Batch)
批式模型就是使用 MapReduce、Hive、Spark 等典型的批计算引擎,以小时任务或者天任务的形式来做数据计算。小时级延迟或者天级别延迟;数据较完整;:成本很低,只有在做任务计算时,才会占用资源。
- 流式模型(Stream)
流式模型,典型的就是使用 Flink 来进行实时的数据计算。数据延迟很短,接近于实时;数据完整度较差;成本较高,流式任务是常驻的,通常要借助内存或者数据库来做 state 的存储。
- 增量模型(Incremental)
针对批式和流式的优缺点,Uber 提出了增量模型(Incremental Mode),相对批式来讲,更加实时;相对流式而 言,更加经济。
增量模型,简单来讲,是以 mini batch 的形式来跑准实时任务。Hudi 在增量模型中支持了两个最重要的特性:
- Upsert:这个主要是解决批式模型中,数据不能插入、更新的问题,有了这个特性,可以往 Hive 中写入增量数据,而不 是每次进行完全的覆盖。(Hudi 自身维护了 key->file 的映射,所以当 upsert 时很容易找到 key 对应的文件)
- Incremental Query:增量查询,减少计算的原始数据量。
3.2.2 查询类型
Hudi支持三种不同的查询表的方式:Snapshot Queries、Incremental Queries和Read Optimized Queries。
- Snapshot Queries(快照查询)
查询某个增量提交操作中数据集的最新快照,先进行动态合并最新的基本文件(Parquet)和增量文件(Avro)来提供近实时数据 集(通常会存在几分钟的延迟)。
读取所有 partiiton 下每个 FileGroup 最新的 FileSlice 中的文件,Copy On Write 表读 parquet 文件,Merge On Read 表读 parquet + log 文件。
- Incremental Queries(增量查询)
- 仅查询新写入数据集的文件,需要指定一个Commit/Compaction的即时时间(位于Timeline上的某个Instant)作为条件,来查 询此条件之后的新数据。
- 可查看自给定commit/delta commit即时操作以来新写入的数据,有效的提供变更流来启用增量数据管道。
- Read Optimized Queries(读优化查询)
- 直接查询基本文件(数据集的最新快照),其实就是列式文件(Parquet)。并保证与非Hudi列式数据集相比,具有相同的列 式查询性能。
- 可查看给定的commit/compact即时操作的表的最新快照。
- 读优化查询和快照查询相同仅访问基本文件,提供给定文件片自上次执行压缩操作以来的数据。通常查询数据的最新程度的保 证取决于压缩策略。
j简而言之,三种查询方式的特点如下:
(1)快照查询数据是最全的;
(2)增量查询查询的是新增的数据;
(3)读优化查询查询的是上一次压缩以后的数据(parquet文件的最新版本)。
3.3.3 表类型
3.3.3.1 Copy On Write
在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据。
- 优点:读取时,只读取对应分区的一个数据文件即可,较为高效;
- 缺点:数据写入的时候,需要复制一个先前的副本再在其基础上生成新的数据文件,这个过程比较耗时。

COW表主要使用列式文件格式(Parquet)存储数据,在写入数据过程中,执行同步合并,更新数据版本并重写数 据文件,类似RDBMS中的B-Tree更新。
(1)更新update:在更新记录时,Hudi会先找到包含更新数据的文件,然后再使用更新值(最新的数据)重写该文件,包含 其他记录的文件保持不变。当突然有大量写操作时会导致重写大量文件,从而导致极大的I/O开销。
(2)读取read:在读取数据时,通过读取最新的数据文件来获取最新的更新,此存储类型适用于少量写入和大量读取的场景。
3.3.3.2 Merge On Read
新插入的数据存储在delta log 中,定期再将delta log合并进行parquet数据文件。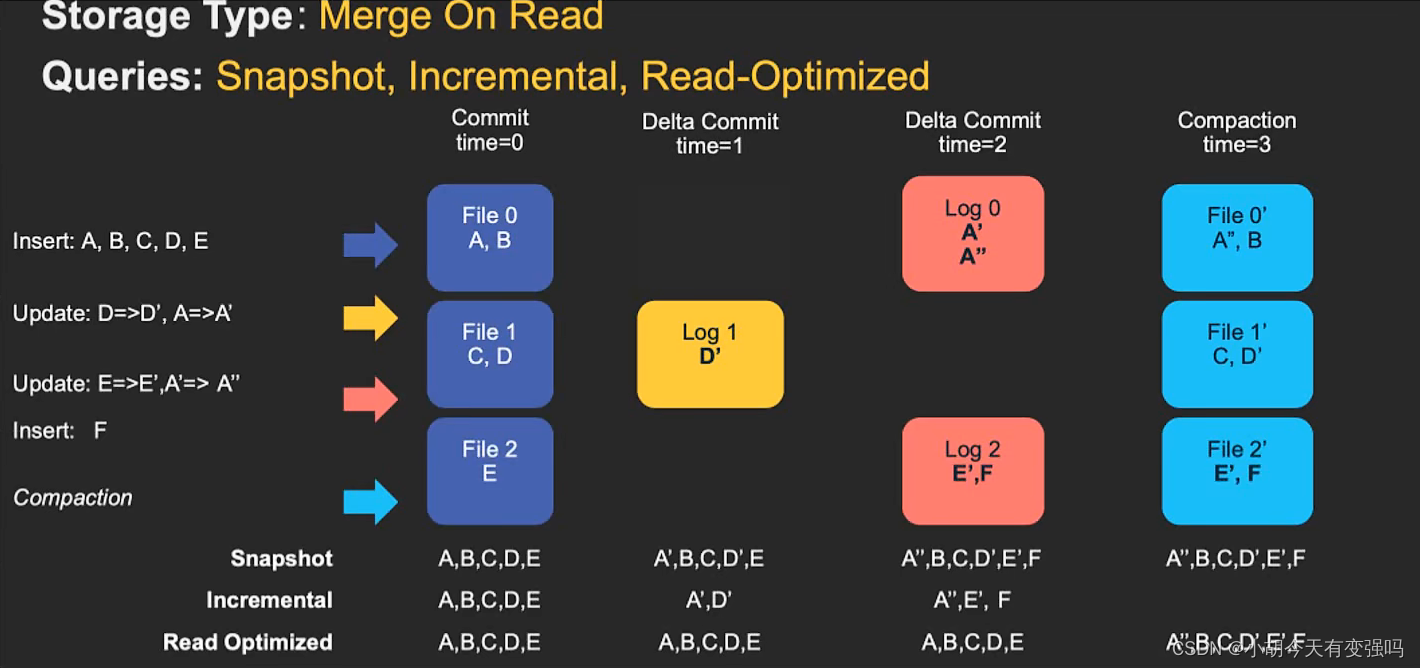
- 优点:由于写入数据先写delta log,且delta log较小,所以写入成本较低;
- 缺点:需要定期合并整理compact,否则碎片文件较多。读取性能较差,因为需要将delta log和老数据文件合并。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l0BefQh8-1654996918970)(C:\Users\Husheng\Desktop\大数据框架学习\image-20220611220831540.png)]](/img/fe/90c9838ed2c92a972c212de70d683b.png)
MOR表是COW表的升级版,它使用列式(parquet)与行式(avro)文件混合的方式存储数据。在更新记录时,类似 NoSQL中的LSM-Tree更新。
(1)更新:在更新记录时,仅更新到增量文件(Avro)中,然后进行异步(或同步)的compaction,最后创建列式文件( parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以追加的模式写入增量文件中。
(2)读取:在读取数据集时,需要先将增量文件与旧文件进行合并,然后生成列式文件成功后,再进行查询。
3.3.3.3 COW vs MOR

3.3 数据写操作流程
在Hudi数据湖框架中支持三种方式写入数据:UPSERT(插入更新)、INSERT(插入)和BULK INSERT(写排序)。
(1)UPSERT:默认行为,数据先通过 index 打标(INSERT/UPDATE),有一些启发式算法决定消息的组织以优化文件的大小;
(2)INSERT:跳过 index,写入效率更高;
(3)BULK_INSERT:写排序,对大数据量的 Hudi 表初始化友好,对文件大小的限制 best effort(写 HFile)。
3.3.1 UPSERT 写流程
- Copy On Write
- 第一步、先对 records 按照 record key 去重;
- 第二步、首先对这批数据创建索引 (HoodieKey => HoodieRecordLocation);通过索引区分哪些 records 是 update,哪些 records 是 insert(key 第一次写入);
- 第三步、对于 update 消息,会直接找到对应 key 所在的最新 FileSlice 的 base 文件,并做 merge 后写新的 base file (新的 FileSlice);
- 第四步、对于 insert 消息,会扫描当前 partition 的所有 SmallFile(小于一定大小的 base file),然后 merge 写新的 FileSlice;如果没有 SmallFile,直接写新的 FileGroup + FileSlice;
- Merge On Read类型表
- 第一步、先对 records 按照 record key 去重(可选)
- 第二步、首先对这批数据创建索引 (HoodieKey => HoodieRecordLocation);通过索引区分哪些 records 是 update,哪些 records 是 insert(key 第一次写入)
- 第三步、如果是 insert 消息,如果 log file 不可建索引(默认),会尝试 merge 分区内最小的 base file (不包含 log file 的 FileSlice),生成新的 FileSlice;如果没有 base file 就新写一个 FileGroup + FileSlice + base file;如果 log file 可建索引,尝试 append 小的 log file,如果没有就新写一个 FileGroup + FileSlice + base file
- 第四步、如果是 update 消息,写对应的 file group + file slice,直接 append 最新的 log file(如果碰巧是当前最小 的小文件,会 merge base file,生成新的 file slice)log file 大小达到阈值会 roll over 一个新的
3.3.2 INSERT 写流程
- Copy On Write
- 第一步、先对 records 按照 record key 去重(可选);
- 第二步、不会创建 Index;
- 第三步、如果有小的 base file 文件,merge base file,生成新的 FileSlice + base file,否则直接写新的 FileSlice + base file;
- Merge On Read
- 第一步、先对 records 按照 record key 去重(可选);
- 第二步、不会创建 Index;
- 第三步、如果 log file 可索引,并且有小的 FileSlice,尝试追加或写最新的 log file;如果 log file 不可索引,写一 个新的 FileSlice + base file
边栏推荐
- 【点云处理之论文狂读经典版10】—— PointCNN: Convolution On X-Transformed Points
- CSDN markdown editor help document
- Banner - Summary of closed group meeting
- [graduation season | advanced technology Er] another graduation season, I change my career as soon as I graduate, from animal science to programmer. Programmers have something to say in 10 years
- 网络安全必会的基础知识
- STM32F103 can learning record
- 常见渗透测试靶场
- What are the stages of traditional enterprise digital transformation?
- Linxu learning (4) -- Yum and apt commands
- Data mining 2021-4-27 class notes
猜你喜欢

CSDN markdown editor help document

On February 14, 2022, learn the imitation Niuke project - develop the registration function

教育信息化步入2.0,看看JNPF如何帮助教师减负,提高效率?

Wonderful review | i/o extended 2022 activity dry goods sharing
Vscode编辑器右键没有Open In Default Browser选项

低代码前景可期,JNPF灵活易用,用智能定义新型办公模式

图像修复方法研究综述----论文笔记

LeetCode 438. 找到字符串中所有字母异位词

LeetCode 515. Find the maximum value in each tree row
![[point cloud processing paper crazy reading classic version 7] - dynamic edge conditioned filters in revolutionary neural networks on Graphs](/img/0a/480f1d1eea6f2ecf84fd5aa96bd9fb.png)
[point cloud processing paper crazy reading classic version 7] - dynamic edge conditioned filters in revolutionary neural networks on Graphs
随机推荐
Digital statistics DP acwing 338 Counting problem
The "booster" of traditional office mode, Building OA office system, was so simple!
Excel is not as good as jnpf form for 3 minutes in an hour. Leaders must praise it when making reports like this!
【点云处理之论文狂读经典版9】—— Pointwise Convolutional Neural Networks
Explanation of the answers to the three questions
MySQL installation and configuration (command line version)
How to check whether the disk is in guid format (GPT) or MBR format? Judge whether UEFI mode starts or legacy mode starts?
2022-1-6 Niuke net brush sword finger offer
[kotlin learning] classes, objects and interfaces - define class inheritance structure
LeetCode 871. 最低加油次数
Build a solo blog from scratch
Using variables in sed command
[point cloud processing paper crazy reading classic version 13] - adaptive graph revolutionary neural networks
[graduation season | advanced technology Er] another graduation season, I change my career as soon as I graduate, from animal science to programmer. Programmers have something to say in 10 years
Principles of computer composition - cache, connection mapping, learning experience
Introduction to the usage of getopts in shell
Education informatization has stepped into 2.0. How can jnpf help teachers reduce their burden and improve efficiency?
What is an excellent fast development framework like?
【点云处理之论文狂读经典版7】—— Dynamic Edge-Conditioned Filters in Convolutional Neural Networks on Graphs
【Kotlin学习】类、对象和接口——带非默认构造方法或属性的类、数据类和类委托、object关键字