当前位置:网站首页>[point cloud processing paper crazy reading classic version 9] - pointwise revolutionary neural networks
[point cloud processing paper crazy reading classic version 9] - pointwise revolutionary neural networks
2022-07-03 09:08:00 【LingbinBu】
Pointwise-CNN: Pointwise Convolutional Neural Networks
Abstract
- problem : 3D The field of deep learning of data has attracted many people's attention , But based on CNN No one has noticed the point cloud learning of
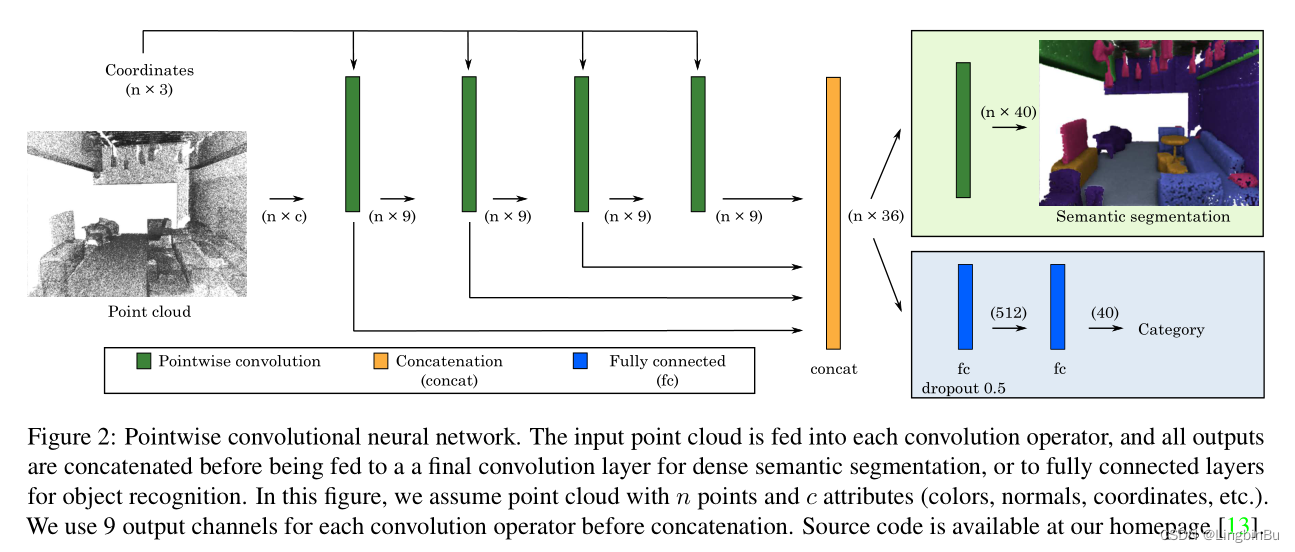
- Method : This paper presents a convolutional neural network for point cloud semantic segmentation and target recognition
- Technical details : point-wise convolution Operations can be used at each point & fully convolutional network
- Code :https://github.com/hkust-vgd/pointwise TensorFlow edition
Related work
equivariance And invariance What's the difference ?
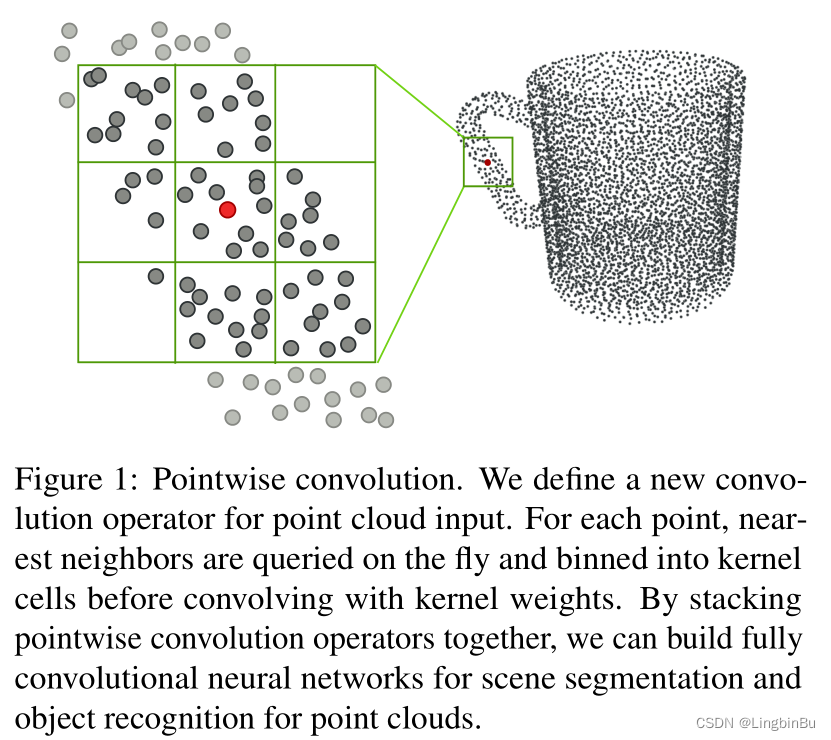
Pointwise Convolution
Convolution
One convolution kernel Take each point in the point cloud as the center .kernel Medium neighbor points It can be done to center point An impact . Every kernel There is one. size or radius, According to each convolution layer neighbor points Adjust the quantity of .pointwise convolution It can be expressed as :
x i ℓ = ∑ k w k 1 ∣ Ω i ( k ) ∣ ∑ p j ∈ Ω i ( k ) x j ℓ − 1 x_{i}^{\ell}=\sum_{k} w_{k} \frac{1}{\left|\Omega_{i}(k)\right|} \sum_{p_{j} \in \Omega_{i}(k)} x_{j}^{\ell-1} xiℓ=k∑wk∣Ωi(k)∣1pj∈Ωi(k)∑xjℓ−1
among , k k k Traverse kernel support All in sub-domains. Ω i ( k ) \Omega_{i}(k) Ωi(k) With a little i i i Centred kernel Of the k k k individual sub-domain. p i p_{i} pi Yes. i i i Coordinates of . ∣ ⋅ ∣ |\cdot| ∣⋅∣ yes sub-domain Number of all points in . w k w_{k} wk It's No k k k individual sub-domain Medium kernel The weight , x i x_{i} xi and x j x_{j} xj Indication point i i i and spot j j j Place the value of the , ℓ − 1 \ell-1 ℓ−1 and ℓ \ell ℓ Is the index of the input and output layers .
Binding graph 1 Better understanding , Divide the area near the center into grids , The features in each grid are first added and then normalized with density , Finally, multiply by the convolution weight in the grid to get the characteristics of a grid , The features of multiple grids are added to obtain new features .
Gradient backpropagation
In order to ensure pointwise convolution Can be trained , It is necessary to calculate the input data and kernel Weight dependent gradient . Make L L L Is the loss function , The gradient associated with the input can be defined as :
∂ L ∂ x j ℓ − 1 = ∑ i ∈ Ω j ∂ L ∂ x i ℓ ∂ x i ℓ ∂ x j ℓ − 1 \frac{\partial L}{\partial x_{j}^{\ell-1}}=\sum_{i \in \Omega_{j}} \frac{\partial L}{\partial x_{i}^{\ell}} \frac{\partial x_{i}^{\ell}}{\partial x_{j}^{\ell-1}} ∂xjℓ−1∂L=i∈Ωj∑∂xiℓ∂L∂xjℓ−1∂xiℓ
Where the given point j j j, We traverse all of them neighbor points i i i. Following chain rule, ∂ L / ∂ x i ℓ \partial L / \partial x_{i}^{\ell} ∂L/∂xiℓ It's the upward layer of back propagation ℓ \ell ℓ Gradient of , ∂ x i ℓ / ∂ x j ℓ − 1 \partial x_{i}^{\ell} / \partial x_{j}^{\ell-1} ∂xiℓ/∂xjℓ−1 It can be written. :
∂ x i ℓ ∂ x j ℓ − 1 = ∑ k w k 1 ∣ Ω i ( k ) ∣ ∑ p j ∈ Ω i ( k ) 1 \frac{\partial x_{i}^{\ell}}{\partial x_{j}^{\ell-1}}=\sum_{k} w_{k} \frac{1}{\left|\Omega_{i}(k)\right|} \sum_{p_{j} \in \Omega_{i}(k)} 1 ∂xjℓ−1∂xiℓ=k∑wk∣Ωi(k)∣1pj∈Ωi(k)∑1
Similarly , And kernel Weight dependent gradients can be obtained by traversing all points i i i Define :
∂ L ∂ w k = ∑ i ∂ L ∂ x i ℓ ∂ x i ℓ ∂ w k \frac{\partial L}{\partial w_{k}}=\sum_{i} \frac{\partial L}{\partial x_{i}^{\ell}} \frac{\partial x_{i}^{\ell}}{\partial w_{k}} ∂wk∂L=i∑∂xiℓ∂L∂wk∂xiℓ
among :
∂ x i ℓ ∂ w k = 1 ∣ Ω i ( k ) ∣ ∑ p j ∈ Ω i ( k ) x j ℓ − 1 \frac{\partial x_{i}^{\ell}}{\partial w_{k}}=\frac{1}{\left|\Omega_{i}(k)\right|} \sum_{p_{j} \in \Omega_{i}(k)} x_{j}^{\ell-1} ∂wk∂xiℓ=∣Ωi(k)∣1pj∈Ωi(k)∑xjℓ−1
This article uses convolution kernels The size is 3 × 3 × 3 3 \times 3 \times 3 3×3×3, Every kernel The weights of points in the cell are the same .
And in volumes The convolution in is different , The network in this article does not pooling, Don't use pooling The reason for this is :
- There is no need to lower and upper sample the point cloud , When the point cloud is mapped to a high-dimensional space , Down sampling and up sampling are troublesome
- The search operation of adjacent points only needs to be established once
Point order
stay PointNet in , The input point cloud is disordered , The subsequent processing process will learn symmetric functions for processing .
In our approach , The input point cloud has a specific order ,XYZ or Morton curve. stay object recognition Tasks , The order of points will affect the final global eigenvector . stay semantic segmentation, The order doesn't matter .
`A-trous convolution
introduce stride Parameters , You can extend the kernel size , So as to expand the perception domain , There is no need to deal with too many points in convolution . This significantly improves the speed without sacrificing the accuracy demonstrated in our experiments .
Point attributes
For easier implementation convolution operator, The coordinates of points and others are stored respectively attributes ( Color 、 The normal vector 、 Or other high-dimensional features output from the previous layer ). No matter how deep the layers are , The coordinates of points can be used for the search of adjacent points .
experiment
Semantic segmentation
S3DIS dataset:
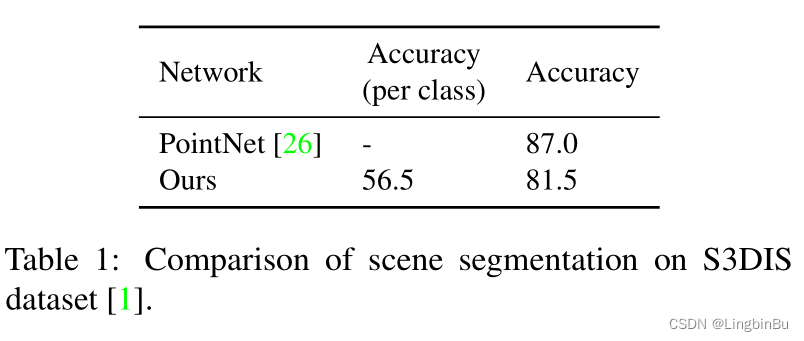
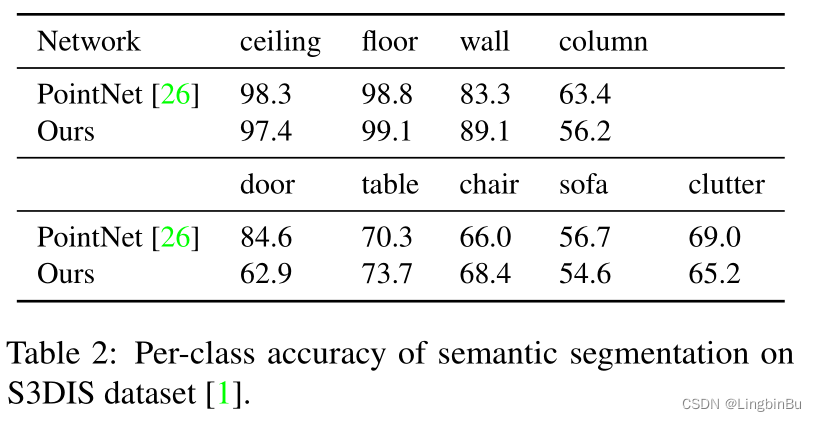

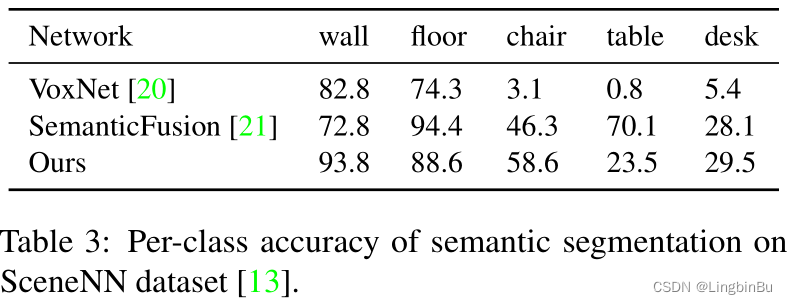
SceneNN dataset:

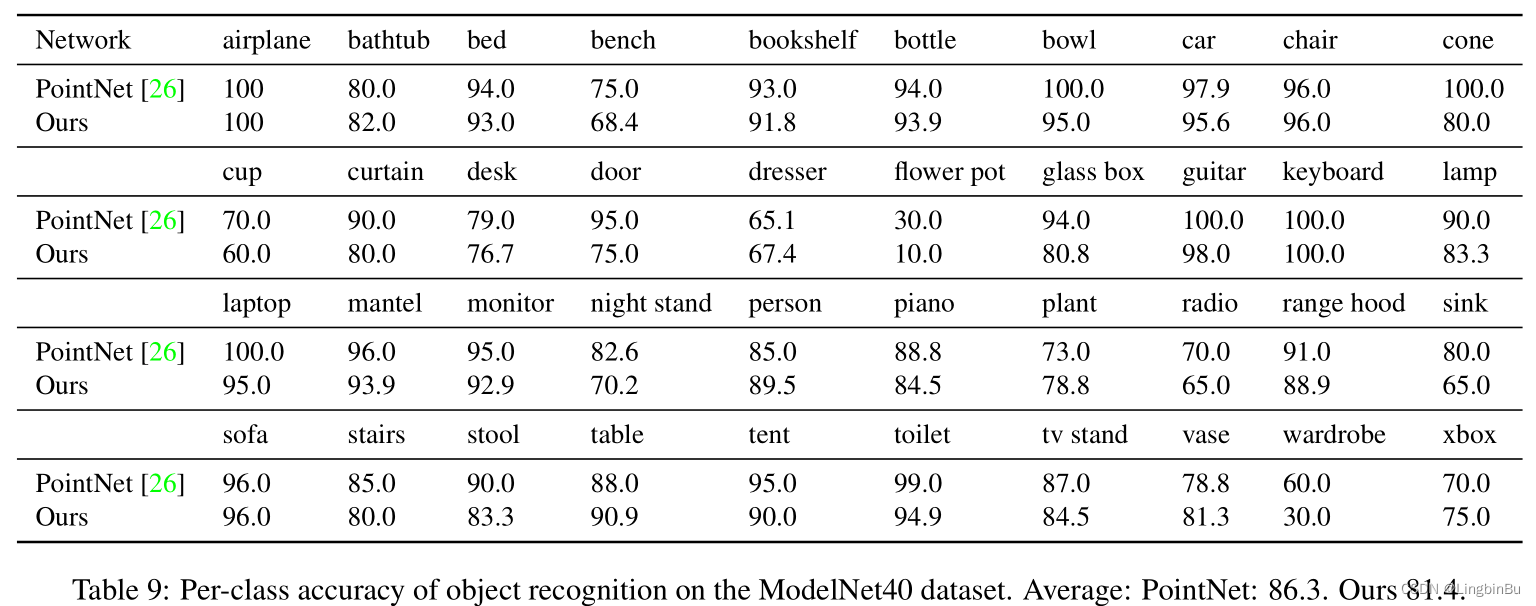
Object recognition



Convergence

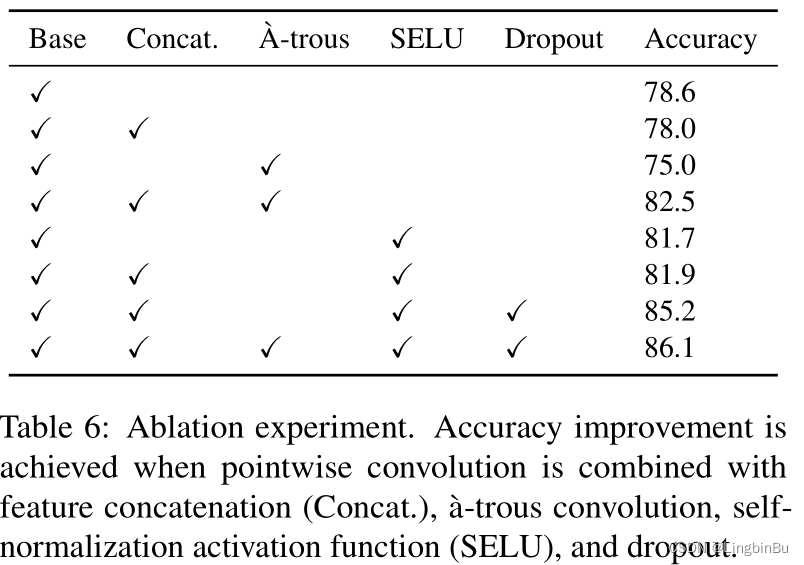
Ablation experiments
Point order & Neighborhood radius

Morton curve Method will make the storage of points in memory very close
Deeper networks

Running time
Intel Core i7 6900K with 16 threads:
- forward convolution 1.272 seconds
- backward propagation 2.423 seconds
NVIDIA TITAN X speed up 10%
Layer visualization

边栏推荐
- <, < <,>, > > Introduction in shell
- Binary tree traversal (first order traversal. Output results according to first order, middle order, and last order)
- Instant messaging IM is the countercurrent of the progress of the times? See what jnpf says
- Debug debugging - Visual Studio 2022
- Six dimensional space (C language)
- LeetCode 1089. Duplicate zero
- Common penetration test range
- dried food! What problems will the intelligent management of retail industry encounter? It is enough to understand this article
- Binary tree sorting (C language, int type)
- Summary of methods for counting the number of file lines in shell scripts
猜你喜欢
【点云处理之论文狂读经典版11】—— Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling

Low code momentum, this information management system development artifact, you deserve it!
AcWing 787. Merge sort (template)

How to check whether the disk is in guid format (GPT) or MBR format? Judge whether UEFI mode starts or legacy mode starts?
常见渗透测试靶场

【点云处理之论文狂读前沿版8】—— Pointview-GCN: 3D Shape Classification With Multi-View Point Clouds

网络安全必会的基础知识

数字化转型中,企业设备管理会出现什么问题?JNPF或将是“最优解”

Excel is not as good as jnpf form for 3 minutes in an hour. Leaders must praise it when making reports like this!

20220630学习打卡
随机推荐
Phpstudy 80 port occupied W10 system
What are the stages of traditional enterprise digital transformation?
PHP function date (), y-m-d h:i:s in English case
<, < <,>, > > Introduction in shell
Shell script kills the process according to the port number
TP5 multi condition sorting
【点云处理之论文狂读前沿版8】—— Pointview-GCN: 3D Shape Classification With Multi-View Point Clouds
LeetCode 508. 出现次数最多的子树元素和
Binary tree traversal (first order traversal. Output results according to first order, middle order, and last order)
PHP mnemonic code full text 400 words to extract the first letter of each Chinese character
How to use Jupiter notebook
【点云处理之论文狂读经典版14】—— Dynamic Graph CNN for Learning on Point Clouds
精彩回顾|I/O Extended 2022 活动干货分享
Convert video to GIF
22-06-27 Xian redis (01) commands for installing five common data types: redis and redis
Vscode connect to remote server
Slice and index of array with data type
Digital statistics DP acwing 338 Counting problem
Divide candy (circular queue)
Gaussian elimination acwing 883 Gauss elimination for solving linear equations