One 、 summary
Purpose : Be more familiar with disk and basic operation of disk
Two 、 file system
2.1、 The composition of the hard disk
Distinguish from the media in which data is stored , Hard disk can be divided into mechanical hard disk (Hard Disk Drive, HDD) And SSDs (Solid State Disk, SSD), Mechanical hard disk uses magnetic disk to store data , The solid-state drive stores data through flash memory particles
Mechanical hard disk mainly consists of disk 、 head 、 Main shaft and transmission shaft , Data is stored on disk .
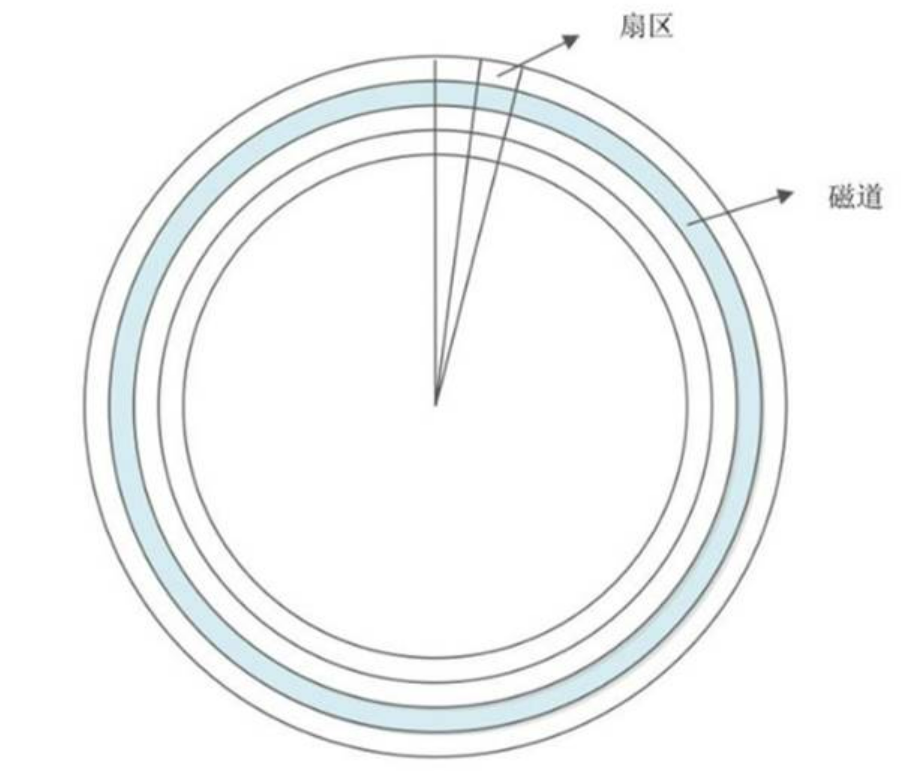
- What is a track ? Each disk has many concentric circles in logic , The outermost concentric circle is 0 Magnetic track . We will Each concentric circle is called a track ( Be careful , Tracks are just logical structures , There are no real concentric circles on the disk ). The track density of hard disk is very high , There are usually thousands of tracks on one side . But adjacent tracks are not next to each other , This is because the magnetization units are too close to each other and will affect each other .
- And what is sector ? The sector is actually very vivid , You've all seen folding paper fans , The paper fan is semicircular or fan-shaped when opened , But this fan is formed by the combination of each fan bone . On disk, each concentric circle is a track , A dividing line is produced radially from the center of the circle ( Fan bone ), Divide each track equally into several arc segments , Each arc segment is a sector . The size of each sector is fixed , by 512Byte. A sector is also the smallest storage unit of a disk . The capacity of hard disk is getting larger and larger , In order to reduce the amount of data , So the new high-capacity hard disk has 4KByte Sector design of
- What is a cylinder ? If a hard disk is made up of multiple disks , Each disk is divided into an equal number of tracks , Then all disks are numbered from the outside to the inside , The outermost one is 0 Magnetic track . Tracks with the same number form a cylinder , This cylinder is called the cylinder of the disk
The size of the hard disk is to use " Number of heads x Cylinders x sector number x Size of each sector " This formula is used to calculate . among , Number of heads (Heads) Indicates how many heads a hard disk has , It can also be understood that a hard disk has several disks , And then multiplied by the 2; Cylinders (Cylinders) Indicates how many tracks each disk has ; sector number (Sectors) Indicates how many sectors are on each track ; The size of each sector is generally 512Byte.
There are many sectors in the outer circle , So if the data is written in the outer ring , The amount of data that can be read and written in a circle is certainly more than that in the inner circle ! Therefore, data reading and writing usually starts from the outer circle to the inside ! This is the default value !
Transmission interface :SAS Interface 、SATA Interface 、USB Interface 、(IDE And SCSI , These two are replaced by the previous )
The biggest difference between SSDs and traditional mechanical hard disks is that they no longer use disks for data storage , And memory chip is used for data storage . There are two kinds of storage chips for SSDs : One is using flash memory as the storage medium ; The other is to adopt DRAM As a storage medium . At present, the most commonly used solid-state hard disk is flash memory
In recent years, when testing the performance of disks , There is a very special unit , It is called the number of read and write operations per second (Input/Output Operations PerSecond, IOPS)! The larger the number , It means that the number of operations is high , Of course, the performance is very good !
- A sector (Sector) Is the smallest physical storage unit , And according to the different disk design , At present, there are mainly 512Bytes And 4K Two formats ;
- Form sectors into a circle , That is the cylinder (Cylinder);
- In the early stage, the cylinder was the smallest partition unit , Nowadays, partitions usually use sectors as the minimum partition unit ( Every sector has its number , It's like a seat );
- There are two main formats of partition table , One is more restrictive MBR Partition table , One is newer and less restrictive GPT Partition table .
- MBR In the partition table , The first sector is the most important , There are :(1) Main boot area (Master boot record, MBR) And partition table (partition table), among MBR occupy 446 Bytes, and partition table Then possession 64 Bytes.
- GPT In addition to the large expansion of the number of partitions in the partition table , The supported disk capacity can also exceed 2TB
- /dev/sd[a-p][1-128]: Is the disk file name of the physical disk ;
- /dev/vd[a-d][1-128]: Is the disk file name of the virtual disk
2.2、 File System Basics
Because the file attributes set by each operating system / Permissions are different , The data needed to store these files , Therefore, you need to format the partition , To become something that the operating system can use “ File system format (filesystem), After the partition, you need to format it (format), Then the operating system can use this file system
In the traditional application of disk and file system , A partition can only be formatted as a file system , So we can say a filesystem It's just one. partition. But thanks to the use of new technology , For example, we often hear LVM With software disk array (software raid), These techniques can format a partition into multiple file systems ( for example LVM), It can also synthesize multiple partitions into a file system (LVM, RAID), A mountable data is a file system instead of a partition
Linux File permissions of the operating system (rwx) And file properties ( The owner 、 group 、 Time parameters, etc ). File systems usually store the data of these two parts in different blocks , Permissions and properties are placed in inode in , As for the actual data, put it in data block In block . in addition , There is also a super block (superblock) It records the whole information of the whole file system , Include inode And block Total amount 、 Usage quantity 、 Surplus, etc .
- superblock: Record this filesystem The overall message , Include inode/block Total amount 、 Usage quantity 、 Surplus quantity , And file system format and related information ;
- inode: Record file properties , One file occupies one inode, At the same time, record the data of this file block number ;
- block: Content of actual record file , If the file is too large , Will take up more than one block .
2.3、EXT2 file system
The file system will... From the beginning inode And block Planned out , Unless reformatted ( Or make use of resize2fs Wait for instructions to change the file system size ), otherwise inode And block Once fixed, it will not change .
Ext2 When formatting, the file system is basically divided into multiple block groups (block group) Of , Each block group has its own inode/block/superblock System .
There is a boot sector at the front of the file system (boot sector), This boot sector can be installed with boot management program ,
1、data block ( Data blocks )
stay Ext2 Supported in the file system block The size is 1K, 2K And 4K Just three . Formatting
when block The size is fixed , And each block They all have numbers , To facilitate inode Records of

- In principle, ,block The size and quantity of can't be changed after formatting ( Unless reformatted );
- Every block Only one file of data can be placed in ;
- Bearing on the , If the file is larger than block Size , One file will take up more than one block Number ;
- Bearing on the , If the file is less than block , Then block The remaining capacity of can no longer be used ( Disk space is wasted )
2、inode table (inode form )
inode The recorded file data includes at least the following :
- The access mode of the file (read/write/excute);
- The owner and group of the file (owner/group);
- The capacity of the file ;
- The time when the file was created or the state changed (ctime);
- Last read time (atime);
- Last modified time (mtime);
- A flag that defines the characteristics of a file (flag), Such as SetUID...;
- The real content of the document points to (pointer);
- Every inode The size is fixed to 128 Bytes ( new ext4 And xfs Can be set to 256 Bytes);
- Each file takes only one inode nothing more ;
- Bearing on the , So the file system can create as many files as inode The quantity is related to ;
- When the system reads a file, it needs to find inode, And analyze inode Whether the recorded permissions and users are consistent with , If it matches, it can start the actual reading block The content of
inode Record block The area of the number is defined as 12 Direct , An indirect , A double indirect and a triple indirect recording area

- 12 It's a direct reference to : 12*1K=12K
Because it points directly to , So a total of 12 Pen to record , Therefore, the total amount is as shown above ;
- indirect : 256*1K=256K
Each stroke block The recording of the number will take 4Bytes, therefore 1K The size of can be recorded 256 Pen to record , Therefore, the file size that can be recorded indirectly is as above ;
- Double indirect : 2562561K=2562K
first floor block Will specify 256 A second floor , Each second layer can specify 256 Numbers , So the total amount is as above ;
- Third, indirect : 256256256*1K=2563K
first floor block Will specify 256 A second floor , Each second layer can specify 256 Third floor , Each third layer can specify 256 Numbers , Therefore, the total amount is as
On ;
Total : Will be directly 、 indirect 、 Double indirect 、 3. Indirect aggregation , obtain 12 + 256 + 256*256 + 256*256*256 (K) = 16GB
3、Superblock ( Super block )
Mainly record the following information :
block And inode Total amount ;
Unused and used inode / block Number ;
block And inode Size (block by 1, 2, 4K,inode by 128Bytes or 256Bytes);
filesystem Mount time of 、 The last time data was written 、 Last disk inspection (fsck) Information about the file system, such as the time of ;
One valid bit The number , If this file system is mounted , be valid bit by 0 , If not mounted , be valid bit by 1 .
4、Filesystem Description ( File system description )
Describe each block group The beginning and the end of block number , And explain each section (superblock, bitmap, inodemap,data block) Between which block Between the numbers
5、block bitmap ( Block comparison table )
from block bitmap What can we know block It's empty. , Therefore, our system can quickly find the available space to deal with files , Delete block It's also
6、inode bitmap (inode Comparison table )
And block bitmap It's a similar function , It's just block bitmap Records are used and unused block number , as for inode bitmap Record the used and unused inode number
2.4、 Relationship with directory tree
stay Linux When creating a directory under the file system , The file system allocates a inode With at least one block Give the directory . among ,inode Record the permissions and properties of the directory , And can record the assigned piece block number ; and block Is the file name recorded in this directory and the space occupied by the file name inode Number data
Since the directory tree is read from the root directory , Therefore, the system can find the mount point through the mount information inode number , At this point, you can get the root directory inode Content , And according to this inode Read the root block File name data in , Read the correct file name down layer by layer
2.5、EXT2、EXT3、EXT4 File access and journaling file system
Suppose we want to add a new file , At this point, the behavior of the file system is :
First, determine whether the user has w And x Authority , If there are any, we can add ;
according to inode bitmap Find unused inode number , And the new file permissions / Attribute write ;
according to block bitmap Find something that is not in use block number , And write the actual data to block in , And updated inode Of block Point to data ;
Write the inode And block Data synchronization update inode bitmap And block bitmap, And update the superblock The content of .
Generally speaking , We will inode table And data block It's called data storage area , As for others, for example superblock、 block bitmap And inodebitmap Such sections are called metadata ( Mediation data ) , because superblock, inode bitmap And block bitmap The data of is constantly changing , Every time I add 、 remove 、 Editing may affect the data of these three parts , Therefore, it is called intermediary data
Log file system (Journaling filesystem)
Avoid file system inconsistencies , Therefore, it is proposed that the log is a file system ( Something similar )
get set : When the system wants to write a file , First, the information of a file to be written will be recorded in the log recording block ;
Actual write : Start writing file permissions and data ; Start updating metadata The data of ;
end : Complete data and metadata After the update of , Complete the recording of the file in the log recording block
Such a journaling file system is EXT3 and EXT4 Default in
2.6、XFS file system
EXT The current troublesome part of the family : Most widely supported , But formatting is super slow
xfs It is a journaling file system , Almost all Ext4 Some functions of file system , xfs Can have ! The main plan is divided into three parts , A data area (data section)、 A file system active login area (log section) And a real-time operation area (realtime section).
1、 Data area (data section)
The data area is just like what we talked about before ext Like the family , Include inode/data block/superblock Data such as , Are placed in this block . This data area is related to ext The family's block group similar , It is also divided into multiple storage area groups (allocation groups) To place the data required by the file system separately . Each storage group contains
- (1) Of the entire file system superblock
- (2) Management mechanism of surplus space
- (3)inode Distribution and tracking of . this
Outside ,inode And block When the system needs to be used , This is the dynamic configuration , So the formatting action is super fast ! in addition , And ext The difference between families is , xfs Of block And inode There are many different capacities to set ,block The capacity can be determined by 512Bytes ~ 64K Deployment , however ,Linux Under the environment of , Due to memory control ( Paging file pagesize The capacity of ), Therefore, the highest available block The size is 4K nothing more !
2、 File system active login area (log section)
Login area this area is mainly used to record changes in the file system , Actually, it's a bit like a log area ! Changes to the document will be recorded here , Until the change is completely written into the data area , The record will be terminated .
3、 Real time operation area (realtime section)
When there is a file to be created ,xfs I will find one or several in this section extent block , Put the file in this block , Wait until the allocation is completed , Write it back to data section Of inode And block Go to ! This extent The size of the block must be specified first when formatting , The minimum is 4K Up to 1G. Generally, disks other than disk arrays default to 64K Capacity , And with a similar disk array stripe Under the circumstances , Then suggest extent Set to and stripe The same size is better . This extent Better not move , Because it may affect the performance of physical disks
2.7、 Mount and unmount the file system
A single file system should not be mounted repeatedly at different mount points ( Catalog ) in ;
Single directory should not mount multiple file systems repeatedly ;
Directory to be mount point , In theory, it should be empty directory
/etc/filesystems: The priority of the system specified test mount file system type ;
/proc/filesystems:Linux The file system type that the system has loaded
have access to mount and umount Command to mount and uninstall , See the relevant order for details
Boot mount :/etc/fstab
root directory / It must be mounted ﹐ And it has to be before the others mount point Be mounted in .
Other mount point Must be a created directory ﹐ Can be specified arbitrarily ﹐ But we must abide by the principle of system directory architecture (FHS)
all mount point At the same time ﹐ You can only mount once .
all partition At the same time ﹐ You can only mount once .
If you uninstall ﹐ You must first move the working directory to mount point( And its subdirectories ) outside
[[email protected] ~]# cat /etc/fstab
# Device Mount point filesystem parameters dump fsck
/dev/mapper/centos-root / xfs defaults 0 0
UUID=94ac5f77-cb8a-495e-a65b-2ef7442b837c /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
【 equipment /UUID etc. 】【 Mount point 】【 file system 】【 File system parameters 】【dump】【fsck】
First column : Disk device file name /UUID/LABEL name:
There are three main items of data that can be filled in this field :
Device file name of file system or disk , Such as /dev/vda2 etc. ( It is not recommended to use )
File system UUID name , Such as UUID=xxx
File system LABEL name , for example LABEL=xxx
The second column : Mount point (mount point)::
It's the mount point ! What is the mount point ? It must be a catalog ~ You know ! Forget the words , Please go back to the data earlier in this chapter and have a look !
The third column : File system of disk partition :
Allow the system to test the mount automatically when mounting manually , But in this file, we have to write to the file system manually ! Include xfs, ext4, vfat,reiserfs, nfs wait .
Column 4 : File system parameters

Column 5 : Can be dump Backup instruction function :
dump It's a backup instruction , But now there are too many backup solutions , So this project can be ignored ! Direct input 0 Just fine
Column 6 : Whether or not to fsck Check sector :
In the process of early startup , There will be a period of time to verify the local file system , See if the file system is complete (clean). However, this method is mainly used through fsck To do , We use now xfs File systems can't be applied , because xfs I will test myself , There is no need to do this extra action ! So fill it directly 0 Just fine
2.8、 Memory swap space swap establish
Partition : First use gdisk Partition a partition in your disk to the system as swap . because Linux Of gdisk By default, the partition's ID Set to Linux Of
file system , So you may have to set it up system ID Is it .
format : Use to create swap Format “mkswap Device file name ” You can format the partition into swap Format
Use : Finally, the swap Device start up , Method is :“swapon Device file name ”.
Observe : Finally through free And swapon -s Let's observe the memory usage with this instruction !
2.9、RAID
RAID-0 ( Equivalent mode , stripe): Best performance : More disks RAID-0 Performance will be better , Because the amount of data each satellite is responsible for is lower ,RAID-0 As long as any disk is damaged , stay RAID All the above data will be lost and unreadable
RAID-1 ( Mapping mode , mirror): Full backup : Let the same data , Save it completely on two disks , whole RAID Almost no capacity 50%
RAID 1+0,RAID 0+1:(1) Let two disks form RAID 1, And there are two sets of such settings ;(2) These two groups. RAID 1 Make another group RAID 0. This is it. RAID 1+0 Luo ! On the other hand ,RAID 0+1 It's about making it up RAID-0 Then the RAID-1 It means
RAID 5: Balance between performance and data backup :RAID5 At least three disks are required to form this type of disk array ,RAID 5 By default, only one disk can be damaged
Spare Disk: Prepare the function of the disk : When the disk of the disk array is damaged , You have to unplug the broken disk , Then change a new disk . After changing to a new disk and successfully starting the disk array , The disk array will start active reconstruction (rebuild) The original broken disk data is transferred to the new disk ! Then the data on your disk array is restored ! This is the advantage of disk array
spare disk One or more disks that are not included in the original disk array level , This disk is not usually used by the disk array , When any disk in the disk array is damaged , Then this one spare disk Will be actively pulled into the disk array , And remove the broken hard disk from the disk array ! Then immediately rebuild the data system . So your system can be safe and healthy forever ! It would be more perfect if your disk array supports hot plugging
Advantages of disk arrays
Data security and reliability : It doesn't mean network information security , But when the hardware ( Refers to the disk ) When damaged , Whether the data can be safely rescued or used ;
Read and write performance : for example RAID 0 Can enhance read and write performance , Let your system I/O Some have been improved ;
Capacity : Multiple disks can be combined , Therefore, a single file system can have considerable capacity .

close RAID
# 1. Uninstall and delete this in the configuration file first /dev/md0 Related settings :
[[email protected] ~]# umount /srv/raid
[[email protected] ~]# vim /etc/fstab
UUID=494cb3e1-5659-4efc-873d-d0758baec523 /srv/raid xfs defaults 0 0
# Delete this line ! Or it can be commented out !
# 2. Cover it first RAID Of metadata as well as XFS Of superblock, Just close /dev/md0 Methods
[[email protected] ~]# dd if=/dev/zero of=/dev/md0 bs=1M count=50
[[email protected] ~]# mdadm --stop /dev/md0
mdadm: stopped /dev/md0 <== No, please ! So it's closed !
[[email protected] ~]# dd if=/dev/zero of=/dev/vda5 bs=1M count=10
[[email protected] ~]# dd if=/dev/zero of=/dev/vda6 bs=1M count=10
[[email protected] ~]# dd if=/dev/zero of=/dev/vda7 bs=1M count=10
[[email protected] ~]# dd if=/dev/zero of=/dev/vda8 bs=1M count=10
[[email protected] ~]# dd if=/dev/zero of=/dev/vda9 bs=1M count=10
[[email protected] ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
unused devices: <none> <== See? ! There really are no array devices !
[[email protected] ~]# vim /etc/mdadm.conf
#ARRAY /dev/md0 UUID=2256da5f:4870775e:cf2fe320:4dfabbc6
# It's the same ! Delete him or annotate him !
2.10、 Logical volume management
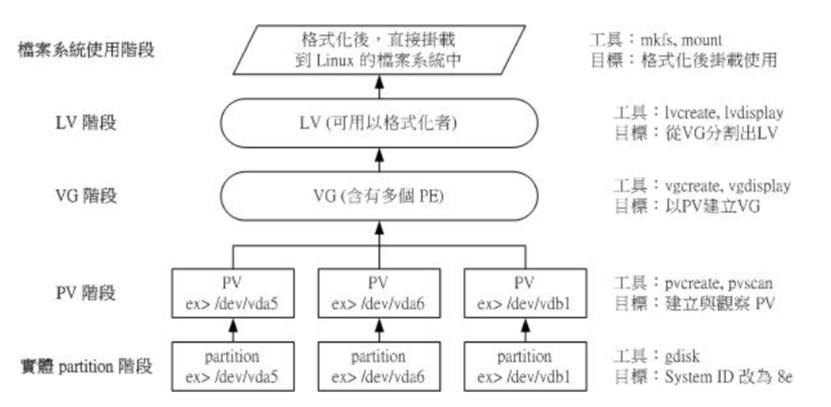
Physical Volume, PV, Physical scroll : We are actually partition ( or Disk) The system identification code needs to be adjusted (system ID) Become 8e (LVM The ID of ), Then go through pvcreate The order of turns him into LVM The bottom entity scroll (PV) , Only then can these PV To make use of ! adjustment system ID The way is through gdisk La !
Volume Group, VG, Scroll group : So-called LVM A big disk is a lot of PV Integrate into this VG That's it ! therefore VG Namely LVM Combined large disks !
Physical Extent, PE, Entity range block :LVM By default 4MB Of PE block , and LVM Of LV stay 32 The bit system can contain at most 65534 individual PE (lvm1 The format of )
Logical Volume, LV, Logical scroll : The final VG It will also be cut into LV, This LV It is a similar partition that can be formatted and used at last
Data is written into this LV when , How on earth did he write it into the hard disk ? ha-ha ! Good question ~ Actually , Depending on the writing mechanism , There are two ways :
Linear mode (linear): If I would /dev/vda1, /dev/vdb1 these two items. partition Add to VG among , And the whole VG only one LV when , So the so-called linear model is : When /dev/vda1 After the capacity of is used up ,/dev/vdb1 Hard disk will be used , This is also the model we suggest .
Staggered mode (triped): So what is interlaced pattern ? Very simple! , That is, I split a piece of data into two parts , Write separately /dev/vda1 And /dev/vdb1 It means , It feels a little like RAID 0 La ! In this way , One piece of data is written into two hard disks , Theoretically , The performance of reading and writing will be better .
3、 ... and 、 Disk related commands
3.1、dumpe2fs
Inquire about Ext family superblock Instructions for information
[[email protected] ~]# dumpe2fs [-bh] Device file name
Options and parameters :
-b : List the parts that remain as bad tracks ( It doesn't work !?)
-h : List only superblock The data of , No other section content will be listed !
Example : A piece of brother bird 1GB ext4 File system content
[[email protected] ~]# blkid <== This instruction can call out that the current system has formatted devices
/dev/vda1: LABEL="myboot" UUID="ce4dbf1b-2b3d-4973-8234-73768e8fd659" TYPE="xfs"
/dev/vda2: LABEL="myroot" UUID="21ad8b9a-aaad-443c-b732-4e2522e95e23" TYPE="xfs"
/dev/vda3: UUID="12y99K-bv2A-y7RY-jhEW-rIWf-PcH5-SaiApN" TYPE="LVM2_member"
/dev/vda5: UUID="e20d65d9-20d4-472f-9f91-cdcfb30219d6" TYPE="ext4" <== notice ext4 了 !
[[email protected] ~]# dumpe2fs /dev/vda5
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name: <none> # The name of the file system ( Not necessarily )
Last mounted on: <not available> # Last mounted directory location
Filesystem UUID: e20d65d9-20d4-472f-9f91-cdcfb30219d6
Filesystem magic number: 0xEF53 # At the top of the UUID by Linux Definition code of equipment
Filesystem revision #: 1 (dynamic) # At the bottom of the features For the characteristic data of the file system
Filesystem features: has_journal ext_attr resize_inode dir_index filetype extent 64bit
flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl # By default, the mounting parameters will be actively added during mounting
Filesystem state: clean # What is the status of this file system ,clean No problem.
Errors behavior: Continue
Filesystem OS type: LinuxInode count: 65536 # inode Total of
Block count: 262144 # block Total of
Reserved block count: 13107 # Reserved block total
Free blocks: 249189 # How many more block Quantity available
Free inodes: 65525 # How many more inode Quantity available
First block: 0
Block size: 4096 # Single block Capacity size of
Fragment size: 4096
Group descriptor size: 64
....( Middle ellipsis )....
Inode size: 256 # inode Capacity size of ! It's already 256 Oh !
....( Middle ellipsis )....
Journal inode: 8
Default directory hash: half_md4
Directory Hash Seed: 3c2568b4-1a7e-44cf-95a2-c8867fb19fbc
Journal backup: inode blocks
Journal features: (none)
Journal size: 32M # Journal Total recordable capacity of log data
Journal length: 8192
Journal sequence: 0x00000001
Journal start: 0
Group 0: (Blocks 0-32767) # First block block group Location
Checksum 0x13be, unused inodes 8181
Primary superblock at 0, Group descriptors at 1-1 # The main superblock Where it is !
Reserved GDT blocks at 2-128
Block bitmap at 129 (+129), Inode bitmap at 145 (+145)
Inode table at 161-672 (+161) # inode table Where it is !
28521 free blocks, 8181 free inodes, 2 directories, 8181 unused inodes
Free blocks: 142-144, 153-160, 4258-32767 # The next two lines show how much capacity is left
Free inodes: 12-8192
Group 1: (Blocks 32768-65535) [INODE_UNINIT] # Follow up with more others block group oh !
Group0 Occupied by block The number is from 0 To 32767 Number ,superblock In the first place 0 The no. block Within the block !
The file system description is described in 1 Number block in ;
block bitmap And inode bitmap It's in 129 And 145 Of block On the number .
as for inode table Distributed in 161-672 Of block In the number !
because (1) One inode Occupy 256 Bytes ,(2) All in all 672 - 161 + 1(161 In itself ) = 512 individual block Flowers in inode table On , (3) Every time
individual block The size is 4096 Bytes(4K). From these data, we can calculate inode There are 512 * 4096 / 256 = 8192 individual inode La !
This Group0 Currently available block Yes 28521 individual , Usable inode Yes 8181 individual ;
remainder inode The number is 12 Number to 8192 Number
3.2、xfs_info
[[email protected] ~]# xfs_info Mount point | Device file name
Sample a : Find the system /boot The file system under this mount point superblock Record
[[email protected] ~]# df -T /boot
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/vda2 xfs 1038336 133704 904632 13% /boot
# you 're right ! It can be seen that it is xfs File system ! Let's observe the content !
[[email protected] ~]# xfs_info /dev/vda2
1 meta-data=/dev/vda2 isize=256 agcount=4, agsize=65536 blks
2 = sectsz=512 attr=2, projid32bit=1
3 = crc=0 finobt=0
4 data = bsize=4096 blocks=262144, imaxpct=25
5 = sunit=0 swidth=0 blks
6 naming =version 2 bsize=4096 ascii-ci=0 ftype=0
7 log =internal bsize=4096 blocks=2560, version=2
8 = sectsz=512 sunit=0 blks, lazy-count=1
9 realtime =none extsz=4096 blocks=0, rtextents=0
The first 1 Inside the line isize refer to inode The capacity of , Everyone with a 256Bytes So big . as for agcount Is the storage area group mentioned above (allocationgroup) The number of , share 4 individual , agsize It means that each storage group has 65536 individual block . Cooperate with No 4 Yes block Set to 4K, Therefore, the capacity of the entire file system should be 4655364K So big !
The first 2 Inside the line sectsz Refers to the logical sector (sector) The capacity of is set to 512Bytes Such a big meaning .
The first 4 Inside the line bsize refer to block The capacity of , Every block by 4K It means , share 262144 individual block In this file system .
The first 5 Inside the line sunit And swidth With disk array stripe The correlation is high . When formatting this part, we will give an example to illustrate .
The first 7 Inside the line internal It refers to the location of the login area in the file system , Not an external device . And occupy 4K * 2560 individual block, A total of about 10M The capacity of .
The first 9 Inside the line realtime Area , Inside extent Capacity of 4K. However, it is not used at present
3.3、df
List the overall disk usage of the file system
[[email protected] ~]# df [-ahikHTm] [ Directory or filename ]
Options and parameters :
-a : List all file systems , Including system specific /proc Equal file system ;
-k : With KBytes Capacity display of each file system ;
-m : With MBytes Capacity display of each file system ;
-h : It's easy for people to read GBytes, MBytes, KBytes Self display in other formats ;
-H : With M=1000K replace M=1024K Carry mode of ;
-T : Together with partition Of filesystem name ( for example xfs) Also listed ;
-i : No disk capacity , And then inode Number to display
Sample a : All the filesystem List !
[[email protected] ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/centos-root 10475520 3409408 7066112 33% /
devtmpfs 627700 0 627700 0% /dev
tmpfs 637568 80 637488 1% /dev/shm
tmpfs 637568 24684 612884 4% /run
tmpfs 637568 0 637568 0% /sys/fs/cgroup
/dev/mapper/centos-home 5232640 67720 5164920 2% /home
/dev/vda2 1038336 133704 904632 13% /boot
# stay Linux Next, if df No options added , By default, all the
# ( File system without special memory and swap) Are subject to 1 KBytes Capacity to list !
# As for that /dev/shm Is a memory related mount , The size is half of the memory , Restart will lose data
Filesystem: Represents where the file system is located partition , So list the device names ;
1k-blocks: Explain that the following number unit is 1KB yo ! available -h or -m To change capacity ;
Used: seeing the name of a thing one thinks of its function , That's the used disk space !
Available: That is, the remaining disk space ;
Use%: That's the disk usage ! If the usage rate is as high as 90% When above , Better pay attention , So as not to cause system problems due to insufficient capacity !( For example, the most explosive /var/spool/mail This disk for mail )
Mounted on: It's the directory where the disk is mounted !( Mount it !)
There are many special file systems in the system . Those special file systems are almost always in memory , for example /proc This mount point . therefore , These special file systems will not occupy disk space !
because df Most of the data read is for an entire file system , Therefore, the reading range is mainly in Superblock The information in , So this command shows the results very quickly !
/dev/shm/ Catalog , In fact, it is the disk space virtualized by memory , Usually half of the total physical memory ! Because it is a disk simulated by memory , So when you create any data files under this directory , The access speed is very fast !( Working in memory ) however , Also because it is simulated by memory , Therefore, the size of this file system is different on each host , And the things you created will disappear the next time you boot up ! Because it's in memory !
3.4、du
Evaluate disk usage for file systems ( Commonly used in estimating the capacity of directory )
[[email protected] ~]# du [-ahskm] File or directory name
Options and parameters :
-a : List all file and directory capacities , Because only the number of files under the directory is counted by default .
-h : In a more readable capacity format (G/M) Show ;
-s : Just list the total , Instead of listing the capacity of each directory ;
-S : Exclude totals under subdirectories , And -s It's a little different .
-k : With KBytes List capacity display ;
-m : With MBytes List capacity display ;
Sample a : List all file sizes in the current directory
[[email protected] ~]# du
4 ./.cache/dconf <== Every directory will be listed
4 ./.cache/abrt
8 ./.cache
....( Middle ellipsis )....
0 ./test4
4 ./.ssh <== Include directories for hidden files
76 . <== This directory (.) The total amount occupied
# Direct input du When no options are added , be du Can analyze “ Current directory ”
# Disk space occupied by files and directories of . however , When actually displayed , Only directory capacity is displayed ( Without documents ),
# therefore . Many files in the directory are not listed , So the total number of directories is not equal to . The capacity of !
# Besides , The output value data is 1K Capacity unit of size .
In general use du -hs * Count the size of the first level subdirectory under the current directory
3.5、ln
Linux There are two kinds of linked files below , One is similar Windows The shortcut function of the file , It allows you to quickly link to the target file ( Or directory ); The other is through the file system inode Link to generate a new file name , Instead of generating new documents ! This is called entity link (hard link)
Hard Link ( Entity link , Hard link or actual link )
- Each file takes up one inode , The contents of the document are provided by inode To point to ;
- Want to read this file , You have to go through the filename of the directory record to point to the correct inode Number to read
- If you will any one “ file name ” Delete , Actually inode And block Are still there !
- hard link It's just... In a directory block Just write one more related data , It will not increase inode It won't consume block Number
- Can't cross Filesystem;
- You can't link Catalog
Symbolic Link ( A symbolic link , That is the shortcut )
ymbolic link Is to create a separate file , And this file will make the reading of data point to him link The file name of the file
[[email protected] ~]# ln [-sf] Source document Target file
Options and parameters :
-s : If you link without any parameters , That's it hard link, as for -s Namely symbolic link
-f : If When the target file exists , Take the initiative to directly remove the target file and then create !
Sample a : take /etc/passwd Copied to the /tmp below , And observe inode And block
[[email protected] ~]# cd /tmp
[[email protected] tmp]# cp -a /etc/passwd .
[[email protected] tmp]# du -sb ; df -i .
6602 . <== First pay attention to the capacity here !
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/mapper/centos-root 10485760 109748 10376012 2% /
# utilize du And df Let's check the current parameters ~ that du -sb Is to calculate the whole /tmp How many are there below Bytes Capacity !
3.6、lsblk
lsblk List all disks on the system
[[email protected] ~]# lsblk [-dfimpt] [device]
Options and parameters :
-d : List only the disk itself , Partition data for this disk is not listed
-f : Also list the file system names within the disk
-i : Use ASCII Segment output for , Don't use complex coding ( It's useful in some environments )
-m : At the same time, output the device in /dev The following permission data (rwx The data of )
-p : List the full file name of the device ! Not just the last names .
-t : List the detailed data of the disk device , Including disk queuing mechanism 、 The amount of data read and written in advance, etc
Sample a : List all disks under the system and partition information within the disk
[[email protected] ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 40G 0 disk # A whole disk
|-vda1 252:1 0 2M 0 part
|-vda2 252:2 0 1G 0 part /boot
`-vda3 252:3 0 30G 0 part
|-centos-root 253:0 0 10G 0 lvm / # stay vda3 Other file systems in
|-centos-swap 253:1 0 1G 0 lvm [SWAP]
`-centos-home 253:2 0 5G 0 lvm /home
- NAME: It's the file name of the device ! Will be omitted /dev Equal lead catalog !
- MAJ:MIN: In fact, the core devices are familiar with these two codes ! They are the main : Secondary equipment code !
- RM: Whether it is a removable device (removable device), Such as CD 、USB Disks, etc
- SIZE: Capacity, of course !
- RO: Whether it means read-only device
- TYPE: It's disk. (disk)、 Partition (partition) Or read only memory (rom) Equal output
- MOUTPOINT: This is the mount point mentioned in the previous chapter
3.7、blkid
List the UUID Equal parameter ,lsblk Already available -f To list file systems and devices UUID data
[[email protected] ~]# blkid
/dev/vda2: UUID="94ac5f77-cb8a-495e-a65b-2ef7442b837c" TYPE="xfs"
/dev/vda3: UUID="WStYq1-P93d-oShM-JNe3-KeDl-bBf6-RSmfae" TYPE="LVM2_member"
/dev/sda1: UUID="35BC-6D6B" TYPE="vfat"
/dev/mapper/centos-root: UUID="299bdc5b-de6d-486a-a0d2-375402aaab27" TYPE="xfs"
/dev/mapper/centos-swap: UUID="905dc471-6c10-4108-b376-a802edbd862d" TYPE="swap"
/dev/mapper/centos-home: UUID="29979bf1-4a28-48e0-be4a-66329bf727d9" TYPE="xfs"
3.8、parted
The partition type of the disk , You can also perform partition related operations
[[email protected] ~]# parted device_name print
Sample a : List /dev/vda Disk related data
[[email protected] ~]# parted /dev/vda print
Model: Virtio Block Device (virtblk) # Module name of the disk ( manufacturer )
Disk /dev/vda: 42.9GB # Total capacity of disk
Sector size (logical/physical): 512B/512B # Each logic of the disk / Physical sector capacity
Partition Table: gpt # Format of partition table (MBR/GPT)
Disk Flags: pmbr_boot
Number Start End Size File system Name Flags # The following is the partition data
1 1049kB 3146kB 2097kB bios_grub
2 3146kB 1077MB 1074MB xfs
3 1077MB 33.3GB 32.2GB lvm
[[email protected] ~]# parted [ equipment ] [ Instructions [ Parameters ]]
Options and parameters :
Command function :
New zoning :mkpart [primary|logical|extended] [ext4|vfat|xfs] Start end
Display partition :print
Delete partition :rm [partition]
Sample a : With parted List the partition table data of the current machine
[[email protected] ~]# parted /dev/vda print
Model: Virtio Block Device (virtblk) <== Disk interface and model
Disk /dev/vda: 42.9GB <== Disk file name and capacity
Sector size (logical/physical): 512B/512B <== Size of each sector
Partition Table: gpt <== yes GPT still MBR Partition
Disk Flags: pmbr_boot
Number Start End Size File system Name Flags
1 1049kB 3146kB 2097kB bios_grub
2 3146kB 1077MB 1074MB xfs
3 1077MB 33.3GB 32.2GB lvm
4 33.3GB 34.4GB 1074MB xfs Linux filesystem
5 34.4GB 35.4GB 1074MB ext4 Microsoft basic data
6 35.4GB 36.0GB 537MB linux-swap(v1) Linux swap
[ 1 ] [ 2 ] [ 3 ] [ 4 ] [ 5 ] [ 6 ]
Number: This is the partition number ! for instance ,1 Number means /dev/vda1 It means ;
Start: What is the starting location of the partition on this disk MB It's about ? Interesting ! He uses capacity as a unit !
End: What is the end location of this partition on this disk MB It's about ?
Size: From the analysis of the above two , Get the capacity of this partition ;
File system: Analyze the meaning of possible file system types !
Name: Just as gdisk Of System ID The meaning of .
3.9、gdisk/fdisk
MBR Partition table please use fdisk Partition , GPT Partition table please use gdisk Partition
[[email protected] ~]# gdisk Equipment name
Example : From the previous section lsblk Output , We know that the system has a /dev/vda, Please observe the partition and related data of the disk
[[email protected] ~]# gdisk /dev/vda <== If you look carefully, , Don't add numbers !
GPT fdisk (gdisk) version 0.8.6
Partition table scan:
MBR: protective
BSD: not present
APM: not present
GPT: present
Found valid GPT with protective MBR; using GPT. <== eureka GPT The partition table !
Command (? for help): <== Here you can enter the command action , You can press the question mark (?) To view the available instructions
Command (? for help): ?
b back up GPT data to a file
c change a partition's name
d delete a partition # Delete a partition
i show detailed information on a partition
l list known partition types
n add a new partition # Add a partition
o create a new empty GUID partition table (GPT)
p print the partition table # Print out the partition table ( Commonly used )
q quit without saving changes # Leave without storage gdisk
r recovery and transformation options (experts only)
s sort partitions
t change a partition's type code
v verify disk
w write table to disk and exit # Leave after storage partition operation gdisk
x extra functionality (experts only)
? print this menu
Command (? for help):
It should pass lsblk or blkid Find the disk first , Reuse parted /dev/xxx print To find out the internal partition table type , Then use gdisk or fdisk To the operating system
fdisk Follow gdisk It is used in almost the same way ! Just a use of ? As instruction prompt data , A use m As a reminder, that's all
3.10、partprobe
to update Linux Core partition table information , After partitioning, you can use this command to update
[[email protected] ~]# partprobe [-s] # You may not add -s ! Then no message will appear on the screen !
[[email protected] ~]# partprobe -s # However, it is suggested to add -s clearer !
/dev/vda: gpt partitions 1 2 3 4 5 6
[[email protected] ~]# lsblk /dev/vda # Actual disk partition status
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 252:0 0 40G 0 disk
|-vda1 252:1 0 2M 0 part
|-vda2 252:2 0 1G 0 part /boot
|-vda3 252:3 0 30G 0 part
| |-centos-root 253:0 0 10G 0 lvm /
| |-centos-swap 253:1 0 1G 0 lvm [SWAP]
| `-centos-home 253:2 0 5G 0 lvm /home
|-vda4 252:4 0 1G 0 part
|-vda5 252:5 0 1G 0 part
`-vda6 252:6 0 500M 0 part
[[email protected] ~]# cat /proc/partitions # Core partition record
major minor #blocks name
252 0 41943040 vda
252 1 2048 vda1
252 2 1048576 vda2
252 3 31461376 vda3
252 4 1048576 vda4
252 5 1048576 vda5
252 6 512000 vda6
# Now the core has correctly caught the partition parameters !
3.11、mkfs.xfs
establish xfs file system , So what we use is mkfs.xfs This instruction
[[email protected] ~]# mkfs.xfs [-b bsize] [-d parms] [-i parms] [-l parms] [-L label] [-f] \
[-r parms] Equipment name
Options and parameters :
About the unit : Now just talk about “ The number ” when , If no unit is added, it is Bytes value , It can be used k,m,g,t,p ( A lowercase letter ) Wait to explain
What's more special is s This unit , It refers to sector Of “ Number ” oh !
-b : It's followed by block Capacity , May by 512 To 64k, However, the maximum capacity is limited to Linux Of 4k oh !
-d : It's important to connect the back data section Related parameter value of , The main values are :
agcount= The number : Setting requires several storage groups (AG), Usually with CPU of
agsize= The number : Every AG Set to how much capacity means , Usually agcount/agsize Just select one setting
file : refer to “ The formatted device is a file, not a device ” It means !( For example, virtual disk )
size= The number :data section The capacity of , That is, you can not use up all the equipment capacity
su= The number : When there is RAID when , that stripe Meaning of value , And the following sw Use it with
sw= The number : When there is RAID when , Number of disks used to store data ( The backup disk and backup disk must be deducted )
sunit= The number : And su Quite a , But the unit uses “ How many? sector(512Bytes size )” It means
swidth= The number : Namely su*sw The numerical , But in order to “ How many? sector(512Bytes size )” To set up
-f : If there is already a file system in the device , You need to use this -f To force formatting !
-i : And inode There are more relevant settings , The main setting values are :
size= The number : The minimum is 256Bytes The biggest is 2k, General reservation 256 It's enough !
internal=[0|1]:log Whether the device is built-in ? The default is 1 built-in , If you want to use external equipment , Use the following settings
logdev=device :log The meaning of the device is the device connected later , Need to set up internal=0 Only then can !
size= The number : Specify the capacity of this login area , It's usually the smallest 512 individual block, about 2M That's all !
-L : Followed by the header name of this file system Label name It means !
-r : Appoint realtime section Relevant setting values of , Common are :
extsize= The number : That's what matters extent The number , Generally, there is no need to set , But there are RAID when ,
It's best to set it up with swidth The same value is better ! The minimum is 4K The maximum is 1G .
Example : Partition the previous section /dev/vda4 Formatted as xfs file system
[[email protected] ~]# mkfs.xfs /dev/vda4
meta-data=/dev/vda4 isize=256 agcount=4, agsize=65536 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0 finobt=0
data = bsize=4096 blocks=262144, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# Soon it's over ! All use default values ! More importantly inode And block The numerical
[[email protected] ~]# blkid /dev/vda4
/dev/vda4: UUID="39293f4f-627b-4dfd-a
3.12、mkfs.ext4
Formatted as ext4 file system
[[email protected] ~]# mkfs.ext4 [-b size] [-L label] Equipment name
Options and parameters :
-b : Set up block Size , Yes 1K, 2K, 4K The capacity of ,
-L : Followed by the header name of the device .
Example : take /dev/vda5 Formatted as ext4 file system Tips
[[email protected] ~]# mkfs.ext4 /dev/vda5
mke2fs 1.42.9 (28-Dec-2013)
Filesystem label= # Show Label name
OS type: Linux
Block size=4096 (log=2) # every last block Size
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks # Follow RAID The correlation is high
65536 inodes, 262144 blocks # A total of inode/block The number of
13107 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=268435456
8 block groups # share 8 individual block groups oh !
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376
Allocating group tables: done
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
[[email protected] ~]# dumpe2fs -h /dev/vda5
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name: <none>
Last mounted on: <not available>
Filesystem UUID: 3fd5cc6f-a47d-46c0-98c0-d43b072e0e12
....( Middle ellipsis )....
Inode count: 65536
Block count: 262144
Block size: 4096
Blocks per group: 32768
Inode size: 256
Journal size: 32M
3.13、xfs_repair
Handle XFS file system , When there is xfs This command is required only when the file system is disordered ! therefore , It's best not to use this instruction
[[email protected] ~]# xfs_repair [-fnd] Equipment name
Options and parameters :
-f : The latter device is actually a file rather than a physical device
-n : Simply checking does not modify any data in the file system ( It's just checking )
-d : It is usually used under single person maintenance mode , For the root directory (/) Check and repair ! It's dangerous ! Don't use it casually
Example : Check the newly created /dev/vda4 file system
[[email protected] ~]# xfs_repair /dev/vda4
Phase 1 - find and verify superblock...
Phase 2 - using internal log
Phase 3 - for each AG...
Phase 4 - check for duplicate blocks...
Phase 5 - rebuild AG headers and trees...
Phase 6 - check inode connectivity...
Phase 7 - verify and correct link counts...
done
# share 7 An important inspection process ! The detailed process introduction can man xfs_repair that will do !
Example : Check the original system /dev/centos/home file system
[[email protected] ~]# xfs_repair /dev/centos/home
xfs_repair: /dev/centos/home contains a mounted filesystem
xfs_repair: /dev/centos/home contains a mounted and writable filesystem
fatal error -- couldn't initialize XFS library
3.14、fsck.ext4
Handle EXT4 file system fsck It's a comprehensive instruction , If it's against ext4 Words , Recommended direct use fsck.ext4 It's better to detect
[[email protected] ~]# fsck.ext4 [-pf] [-b superblock] Equipment name
Options and parameters :
-p : When the file system is being repaired , If you need to reply y In the action of , Automatic recovery y To continue the repair action .
-f : Compulsory inspection ! Generally speaking , If fsck No unclean My flag , Will not take the initiative to enter
Detailed inspection , If you want to force fsck Enter the detail inspection , You have to add -f Flag !
-D : Optimize the configuration of directories under the file system .
-b : Followed by superblock The location of ! Generally speaking, this option is not used . But if yours superblock When damaged for some reason ,
With this parameter, you can use the data backed up in the file system superblock To try to rescue . Generally speaking ,superblock Backup in :
1K block Put it in 8193, 2K block Put it in 16384, 4K block Put it in 32768
Example : Find out what you just created /dev/vda5 Another piece of superblock, And based on it, the detection system
[[email protected] ~]# dumpe2fs -h /dev/vda5 | grep 'Blocks per group'
Blocks per group: 32768
# It seems that everyone block The group will have 32768 individual block, So the second superblock It should be in 32768 On !
# because block The number is 0 It began to be numbered !
[[email protected] ~]# fsck.ext4 -b 32768 /dev/vda5
e2fsck 1.42.9 (28-Dec-2013)
/dev/vda5 was not cleanly unmounted, check forced.
Pass 1: Checking inodes, blocks, and sizes
Deleted inode 1577 has zero dtime. Fix<y>? yes
Pass 2: Checking directory structurePass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
/dev/vda5: ***** FILE SYSTEM WAS MODIFIED ***** # The file system has been modified , So there will be a warning !
/dev/vda5: 11/65536 files (0.0% non-contiguous), 12955/262144 blocks
# What a coincidence ! Brother bird uses this method to test the system , I happen to encounter a problem with the file system ! Therefore, there can be more explanation directions !
# When the file system goes wrong , It will ask you to choose whether to repair ~ If the repair is as shown above , Press down y that will do !
# Eventually the system will tell you , The file system has been changed , Pay attention to the meaning of the project !
3.15、mount
[[email protected] ~]# mount -a
[[email protected] ~]# mount [-l]
[[email protected] ~]# mount [-t file system ] LABEL='' Mount point
[[email protected] ~]# mount [-t file system ] UUID='' Mount point # Brother bird recently suggested this way !
[[email protected] ~]# mount [-t file system ] Device file name Mount point
Options and parameters :
-a : As per profile /etc/fstab All unmounted disks are mounted
-l : Simple input mount The currently mounted information will be displayed . add -l Can be added Label name !
-t : You can add a file system type to specify the type to mount . common Linux Support types are :xfs, ext3, ext4,
reiserfs, vfat, iso9660( Disc format ), nfs, cifs, smbfs ( The last three are network file system types )
-n : By default , The system will write the actual mount in real time /etc/mtab in , To facilitate the operation of other programs .
But in some cases ( For example, single person maintenance mode ) In order to avoid problems, I will deliberately not write . You have to use it now -n Options .
-o : Some additional parameters can be added when mounting ! For example, account number 、 password 、 Read and write permissions, etc :
async, sync: Does this file system use synchronous writes (sync) Or asynchronous (async) Of
Memory mechanism , Please refer to the file system operation mode . The default is async.
atime,noatime: Whether to revise the read time of the file (atime). For the sake of performance , Available at certain times noatime
ro, rw: Mount file system as read-only (ro) Or read and write (rw)
auto, noauto: Allow this filesystem Be subjected to mount -a Automatically mount (auto)
dev, nodev: Whether to allow this filesystem On , You can create device files ? dev Is allowed
suid, nosuid: Whether to allow this filesystem contain suid/sgid File format ?
exec, noexec: Whether to allow this filesystem Have executable on binary file ?
user, nouser: Whether to allow this filesystem Let any user execute mount ? Generally speaking ,
mount have only root Can be done , But release user Parameters , Then you can
commonly user It can also partition Conduct mount .
defaults: The default value is :rw, suid, dev, exec, auto, nouser, and async
remount: Re mount , This is a system error , Or when updating parameters , It is useful to !
3.16、umount
[[email protected] ~]# umount [-fn] Device file name or mount point
Options and parameters :
-f : Force uninstall ! It can be used in similar network file system (NFS) In the case of unreadable ;
-l : Unmount the file system now , Than -f They were stronger !
-n : Not updated /etc/mtab Uninstall in case of .
3.17、mdadm
[[email protected] ~]# mdadm --detail /dev/md0
[[email protected] ~]# mdadm --create /dev/md[0-9] --auto=yes --level=[015] --chunk=NK \
> --raid-devices=N --spare-devices=N /dev/sdx /dev/hdx...
Options and parameters :
--create : Create for RAID The option to ;
--auto=yes : Decide to create the following software disk array device , or /dev/md0, /dev/md1...
--chunk=Nk : Determine the of this device chunk size , It can also be regarded as stripe size , It's usually 64K or 512K.
--raid-devices=N : Use several disks (partition) As a disk array device
--spare-devices=N : Use several disks as backup (spare) equipment
--level=[015] : Set the level of this group of disk arrays . A lot of support , However, it is recommended to use 0, 1, 5 that will do
--detail : Details of the disk array device that follows
[[email protected] ~]# mdadm --manage /dev/md[0-9] [--add equipment ] [--remove equipment ] [--fail equipment ]
Options and parameters :
--add : The following devices will be added to this md in !
--remove : The following equipment will be transferred from this md Remove
--fail : The following devices will be set to an error state
3.18、 Logical volume related commands

3.19、dd
https://www.cnblogs.com/yuanqiangfei/p/9138625.html
dd: Copy a file in a block of a specified size , And perform the specified transformation at the same time of copying .
Be careful : The place where the number is specified ends with the following characters , Multiply by the corresponding number :b=512;c=1;k=1024;w=2
Parameter annotation :
1. if= file name : Input file name , Default to standard input . That is, specify the source file .< if=input file >
2. of= file name : Output file name , Default to standard output . I.e. designated purpose document .< of=output file >
3. ibs=bytes: Read in at a time bytes Bytes , That is, to specify a block size of bytes Bytes .
obs=bytes: One output bytes Bytes , That is, to specify a block size of bytes Bytes .
bs=bytes: Also set read in / The output block size is bytes Bytes .
4. cbs=bytes: One conversion bytes Bytes , That is, specify the conversion buffer size .
5. skip=blocks: Skip from the beginning of the input file blocks Block and start copying .
6. seek=blocks: Skip from the beginning of the output file blocks Block and start copying .
Be careful : Usually only valid if the output file is disk or tape , That is, backup to disk or tape is valid .
7. count=blocks: Just copy blocks Block , The size of the block is equal to ibs Number of bytes specified .
8. conv=conversion: Convert the file with the specified parameters .
ascii: transformation ebcdic by ascii
ebcdic: transformation ascii by ebcdic
ibm: transformation ascii by alternate ebcdic
block: Convert each line to a length of cbs, Fill in the insufficient part with space
unblock: Make each line the length of cbs, Fill in the insufficient part with space
lcase: Convert uppercase characters to lowercase characters
ucase: Convert lowercase characters to uppercase characters
swab: Exchange each pair of bytes of input
noerror: Don't stop when something goes wrong
notrunc: Do not truncate the output file
sync: Fill each input block to ibs Bytes , Empty the insufficient part (NUL) Character complement .
3.20、fio
https://www.cnblogs.com/raykuan/p/6914748.html
stay fio Download from the official website fio-2.1.10.tar file , After decompressing ./configure、make、make install It can be used later fio 了 ( Be careful : This command does not operate on the file system with existing data )
filename=/dev/emcpowerb Support file system or bare device ,-filename=/dev/sda2 or -filename=/dev/sdb
direct=1 The test process bypasses the machine's own buffer, Make the test results more realistic
rw=randwread Test random reading I/O
rw=randwrite Test randomly written I/O
rw=randrw Test a random mix of write and read I/O
rw=read Test sequential reading I/O
rw=write The test sequence is written I/O
rw=rw Test the sequence of mixed write and read I/O
bs=4k A single io The block file size of is 4k
bsrange=512-2048 ditto , Determine the size range of data blocks
size=5g This test file size is 5g, Every time 4k Of io To test
numjobs=30 This test thread is 30
runtime=1000 Test time is 1000 second , If you don't write, you'll always 5g File Division 4k Every time I finish writing
ioengine=psync io Engine USES pync The way , If you want to use libaio engine , need yum install libaio-devel package
rwmixwrite=30 In mixed read-write mode , Write to account for 30%
group_reporting About displaying results , Summarize the information of each process. In addition
lockmem=1g Use only 1g Memory for testing
zero_buffers use 0 Initialize system buffer
nrfiles=8 Number of files generated per process
Test scenarios :
100% Random ,100% read , 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100read_4k
100% Random ,100% Write , 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100write_4k
100% The order ,100% read ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100read_4k
100% The order ,100% Write ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100write_4k
100% Random ,70% read ,30% Write 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=randrw_70read_4k
bw= Average IO bandwidth
iops=IOPS
runt= Thread run time
slat= Submission delay
clat= Completion delay
lat= response time
bw= bandwidth
cpu= utilization
IO depths=io queue
IO submit= Single IO Submit to submit IO Count
IO complete=Like the above submit number, but for completions instead.
IO issued=The number of read/write requests issued, and how many of them were short.
IO latencies=IO Distribution of completion delay
io= How many... Were executed in total size Of IO
aggrb=group Total bandwidth
minb= Minimum . Average bandwidth .
maxb= Maximum average bandwidth .
mint=group The shortest running time of a thread in .
maxt=group The maximum running time of a thread in the .
ios= all group All in all IO Count .
merge= All in all IO Consolidated number .
ticks=Number of ticks we kept the disk busy.
io_queue= The total time spent in the queue .
util= Disk utilization
3.21、iostat
https://blog.csdn.net/qq_20332637/article/details/82146753
yum install sysstat
cpu Property value description :
%user:CPU Percentage of time in user mode .
%nice:CPU In the belt NICE Value of the percentage of time in user mode .
%system:CPU Percentage of time in system mode .
%iowait:CPU The percentage of time to wait for I / O to complete .
%steal: When the hypervisor maintains another virtual processor , fictitious CPU The percentage of unconscious waiting time .
%idle:CPU Percentage of free time .
remarks :
If %iowait The value of is too high , Indicates that the hard disk exists I/O bottleneck
If %idle High value , Express CPU More free
If %idle When the value is high but the system response is slow , May be CPU Waiting to allocate memory , You should increase the memory capacity .
If %idle The value is continuously lower than 10, indicate CPU Processing power is relatively low , The most needed resource in the system is CPU.
cpu Property value description :
tps: Number of transfers per second for this device
kB_read/s: Slave devices per second (drive expressed) Amount of data read ;
kB_wrtn/s: Devices per second (drive expressed) Amount of data written ;
kB_read: Total data read ;
kB_wrtn: The total amount of data written

[[email protected] /]# iostat -xd 3
Linux 3.8.13-16.2.1.el6uek.x86_64 (rac01-node01) 05/27/2017 _x86_64_ (40 CPU)
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.05 0.75 2.50 0.50 76.59 69.83 48.96 0.00 1.17 0.47 0.14
scd0 0.00 0.00 0.02 0.00 0.11 0.00 5.25 0.00 21.37 20.94 0.05
dm-0 0.00 0.00 2.40 1.24 75.88 69.83 40.00 0.01 1.38 0.38 0.14
dm-1 0.00 0.00 0.02 0.00 0.14 0.00 8.00 0.00 0.65 0.39 0.00
sdc 0.00 0.00 0.01 0.00 0.11 0.00 10.20 0.00 0.28 0.28 0.00
sdb 0.00 0.00 0.01 0.00 0.11 0.00 10.20 0.00 0.15 0.15 0.00
sdd 0.00 0.00 0.01 0.00 0.11 0.00 10.20 0.00 0.25 0.25 0.00
sde 0.00 0.00 0.01 0.00 0.11 0.00 10.20 0.00 0.14 0.14 0.00
- rrqms: How many read requests are related to this device per second Merge 了 ( When system calls need to read data ,VFS Send the request to each FS, If FS It is found that different read requests read the same Block The data of ,FS Will merge this request Merge)
- wrqm/s: How many write requests are related to this device per second Merge 了 .
- rsec/s:The number of sectors read from the device per second.
- wsec/s:The number of sectors written to the device per second.
- rKB/s:The number of kilobytes read from the device per second.
- wKB/s:The number of kilobytes written to the device per second.
- avgrq-sz: Average request sector size ,The average size (in sectors) of the requests that were issued to the device.
- avgqu-sz: Is the average length of the request queue . without doubt , The shorter the queue, the better ,The average queue length of the requests that were issued to the device.
- await: every last IO The average processing time of a request ( The units are microseconds in milliseconds ). So this could be interpreted as IO Response time of , General terrestrial system IO Response time should be below 5ms, If it is greater than 10ms It's bigger . This time includes queue time and service time , in other words , In general ,await Greater than svctm, The smaller the difference between them , The shorter the queue time , Otherwise, the greater the difference , The longer the queue , There's something wrong with the system .
- svctm: Represents the average per device I/O Service time of operation ( In Milliseconds ). If svctm The value of is equal to await Very close to , Almost none I/O wait for , Disk performance is good . If await Is much higher than svctm Value , said I/O The queue is too long , Applications running on the system will slow down .
- %util: All processing in statistical time IO Time , Divided by the total statistical time . for example , If the statistical interval 1 second , The device has 0.8 Seconds in the treatment of IO, and 0.2 Seconds to spare , So the device's %util = 0.8/1 = 80%, So this parameter indicates how busy the device is , In a general way , If the parameter is 100% It indicates that the disk device is close to full load ( Of course if you have multiple disks , Even if %util yes 100%, Because of the concurrency of the disk , So disk usage is not necessarily a bottleneck ).
3.22、iotop
https://www.cnblogs.com/yinzhengjie/p/9934260.html
yum -y install iotop
Description of each parameter :
-o, --only Just show that it's producing I/O Process or thread of . In addition to transmitting ginseng , You can press... During operation o take effect .
-b, --batch Non interactive mode , It's usually used for logging .
-n NUM, --iter=NUM Set the number of times to monitor , Default infinite . Useful in non interactive mode .
-d SEC, --delay=SEC Set the interval of each monitoring , Default 1 second , Accept non shaping data, such as 1.1.
-p PID, --pid=PID Specify the process to monitor / Threads .
-u USER, --user=USER Specifies to monitor a user generated I/O.
-P, --processes Show only processes , Default iotop Show all threads .
-a, --accumulated Show cumulative I/O, Not bandwidth .
-k, --kilobytes Use kB Company , Not a friendly unit . In non interactive mode , Scripting is useful .
-t, --time Add a time stamp , Non interactive mode .
-q, --quiet The first few lines are prohibited , Non interactive mode . There are three ways to specify .
-q Show column names only on first monitoring
-qq Never show column names .
-qqq Never show I/O Summary .
Interactive keys :
and top Command similar ,iotop It also supports the following interactive keys .
left and right Direction key : Change the order .
r: Reverse sorting .
o: Switch to options --only.
p: Switch to --processes Options .
a: Switch to --accumulated Options .
q: sign out .
i: Change the priority of a thread .