当前位置:网站首页>Deep learning -yolov5 introduction to actual combat click data set training
Deep learning -yolov5 introduction to actual combat click data set training
2022-07-06 05:23:00 【Eleven elder sister】
Catalog
One 、 Environmental preparation
yolov5 Is the main role : Given a data set that has been marked 》 run yolov5 The code gets a target detection model 》 Choose a picture or video and give it to yolov5 Code ,yolov5 The code can automatically recognize and distinguish the target body
It is recommended that the blogger's Video Script install the environment hand in hand to train recognition , Or look directly at The blogger's blog has tutorials
Native configuration : Win11,Anaconda(python3.7),GTX3050,cuda11.1,pytorch1.8, yolov5, It is recommended to check your computer first cuda Version information :
open cmd Window type nvidia-smisee , Or by NVIDIA Control panel see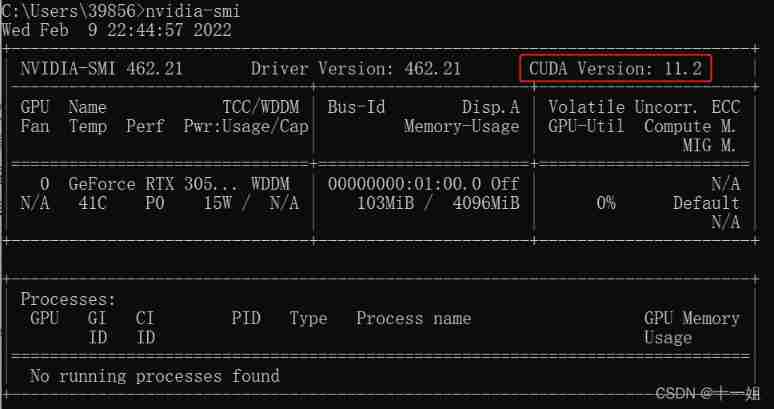
pytorch Environmental preparation : First of all, there are anconda, Then open the cmd Execute the order as follows ( Corresponding to the configuration above ), For example, search
# CUDA 11.1open cuda Each version corresponds to the installation command search , If you encounter problems, you can see the installation steps in this articleconda create --p=D:\Programmer\Captcha_env python=3.7 activate D:\Programmer\Captcha_env conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 -c pytorch -c conda-forgedownload yolov5, Download the compressed package address , Then decompress it
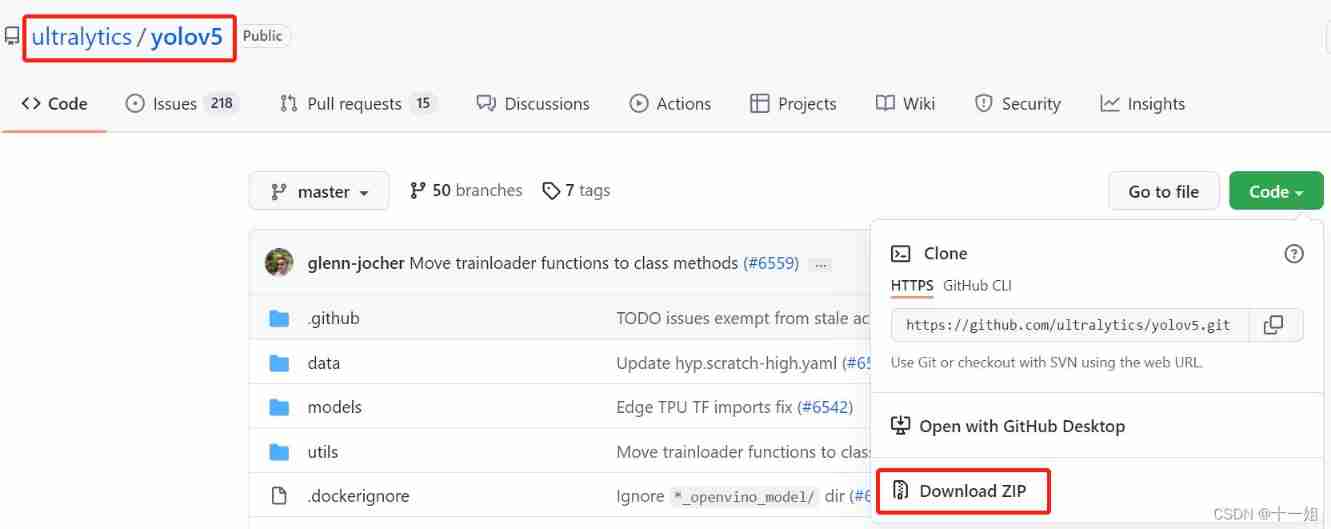
yolov5 relevant python Dependent package installation : stay yolov5-master Open in the current directory cmd window , Then enter the previously built virtual environment, such as
activate D:\Programmer\Captcha_env, Then install the dependenciespip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/activate D:\Programmer\Captcha_env pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn
Two 、yolov5 A brief introduction to the code
- See here for a more detailed introduction , Or this article
- Recommend 2 Half an hour video nanny introduces the meaning of code parameters
1、yolov5 In the code train.py
- stay yolov5 In the code , Our training mainly runs
train.pyfile , The test mainly runsdetect.pyfile ; So as long asPrepare a data set, Then change the main configuration of these two files as shown in the figure, such as which data set path to train or test , Picture size, etc , Then the process is finished .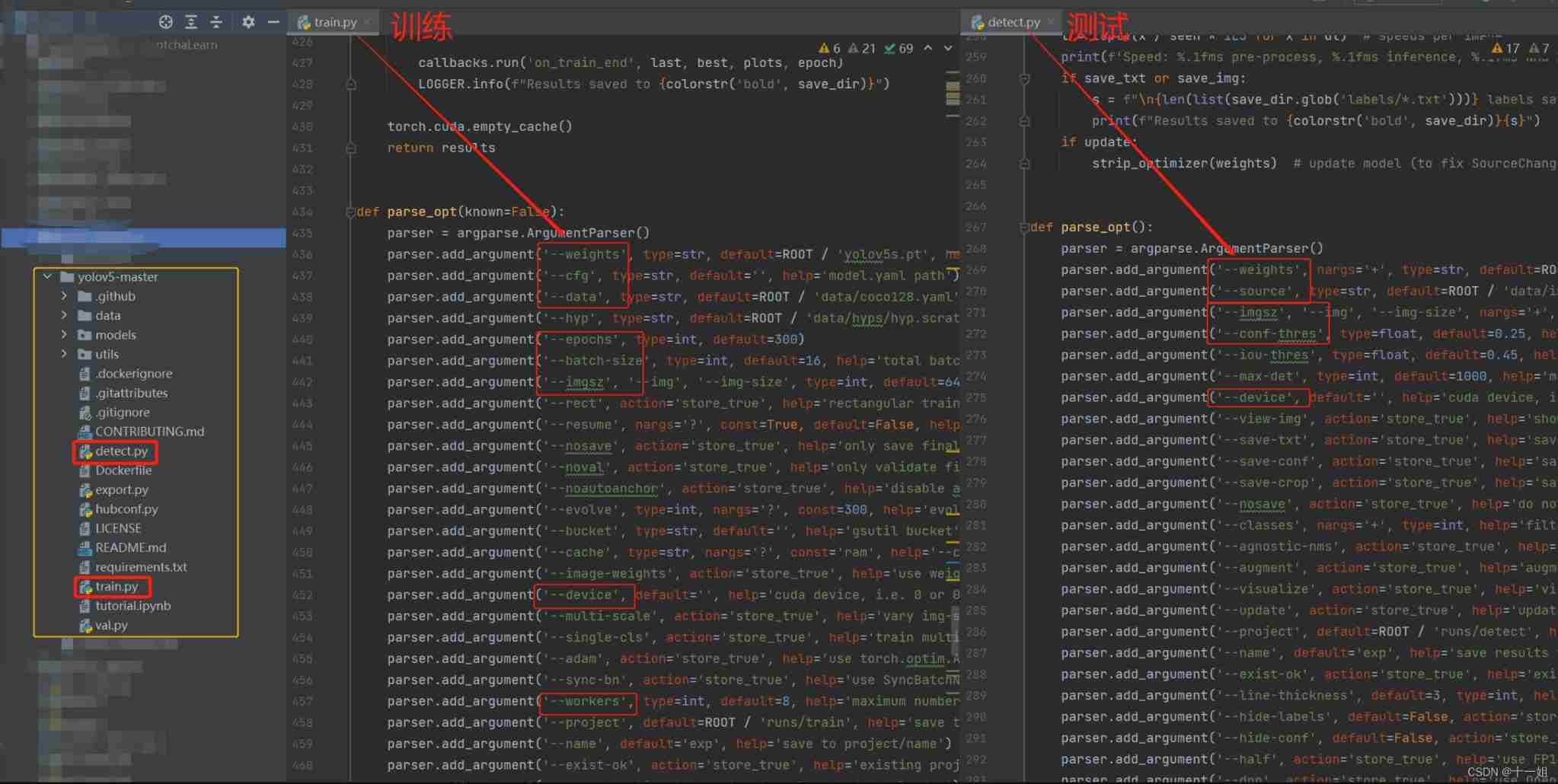
- yolov5 Code
train.pyIntroduction to important parameters of :
train.pyParameters ofweightsBrief introduction : Specify the weight model , Such as :yolov5s.pt / yolov5m / yolov5l/ yolov5x( It can be understood as s Small ,m Medium ,l Large ,xl Big size , The corresponding detection speed is from fast to slow , But the accuracy is from low to high )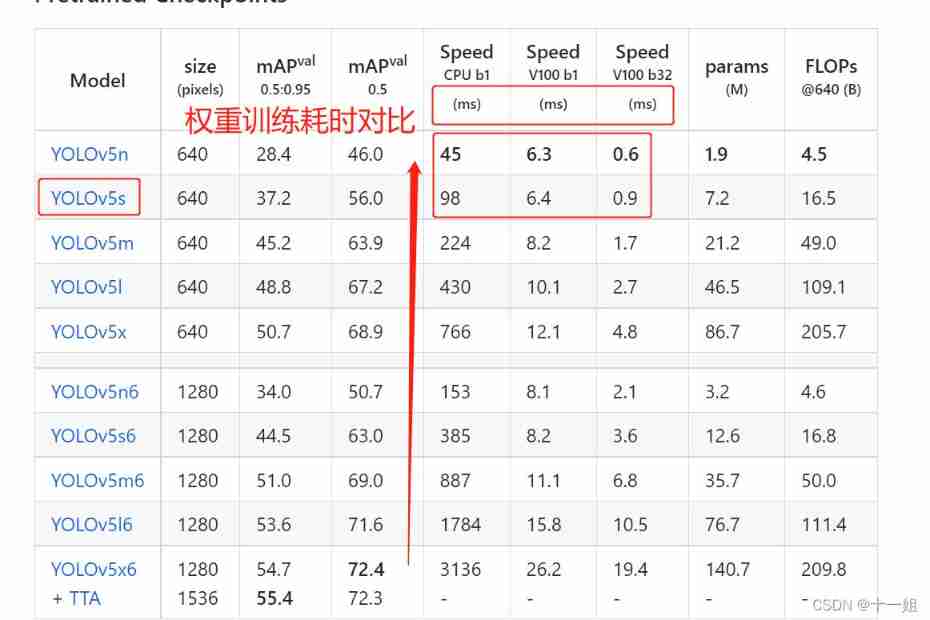
2、yolov5 In the code detect.py
- yolov5 Code
detect.pyIntroduction to important parameters of :
3、yolov5 Data set file format for code preparation
- yolov5 The custom preparation format of the data set to be trained is generally as follows : Three parts
Training set + Verification set +.yaml To configure, among images There are marked pictures under the folder ,labels All are yolo Format .txt file ,images And labels There is one-to-one correspondence in , Only the suffix is different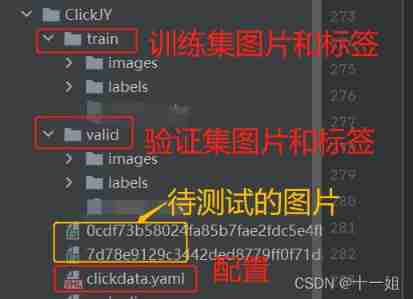
yolo The format label is txt File format: The file name is the same as the corresponding picture name , Except that the suffix is changed to .txtOne line for each goal , If the whole picture has no goal, there is no need to have txt file , Or empty file
` The format of each line is 5 Parameters :class_num( Classified index , such as 0 On behalf of wearing masks ,1 The representative doesn't wear a mask ), after 4 The column is x_center/image_width、y_center/image_height、width/image_width、height/image_height, The value range is 0 ~ 1
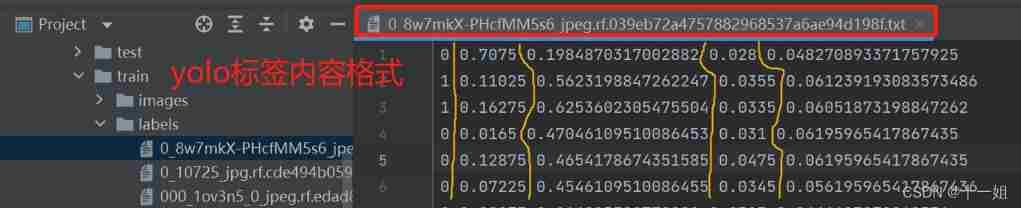
among class_num The value is 0 to total_class - 1, As shown in the following figure, there are four values x_center Relative to the picture axis is 0.48,y_center Relative to the picture axis is 0.63,width The width of the picture is 0.69, height The height of the picture is 0.71; The reason why image values are normalized , Because there are many sizes of training pictures , In this way, it can be unified through normalization

.yaml Configuration file for: It mainly specifies the image path for training and verification , And classification quantity and name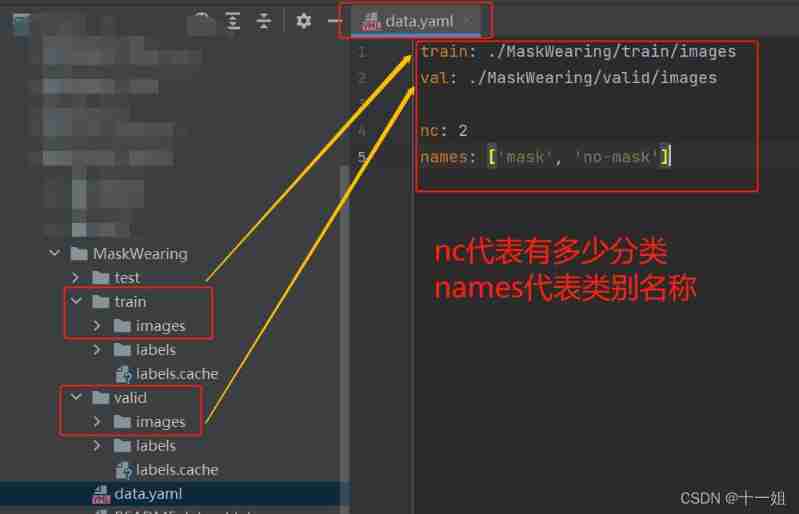
3、 ... and 、 A tiny test identification case
- Test with the existing model on the official website yolov5 Is it working : open pychram
Direct operation detect.py file(detect.py file : Use the pre trained model for prediction and recognition test , Such as yolov5s.pt Model ) - During operation, it will
Automatically download one yolov5s.pt Model, If you can't download it , You can connect directly to this connection Weight model download , and train.py In the same directory ; thenAutomatic identification data/images Two pictures in the directory, And thenAutomatically generate a new folder runs>detect>exp Used to store the identified results.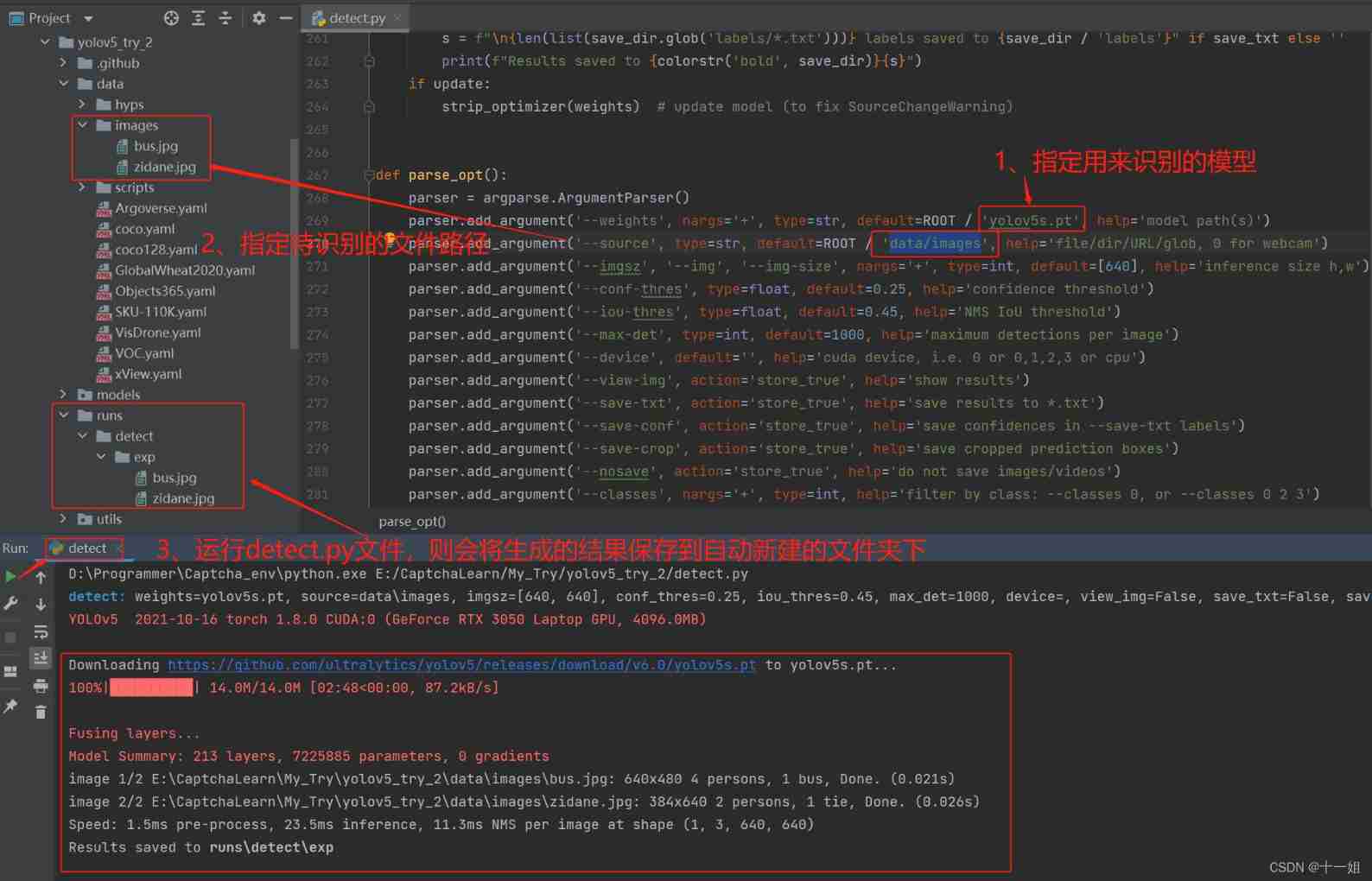
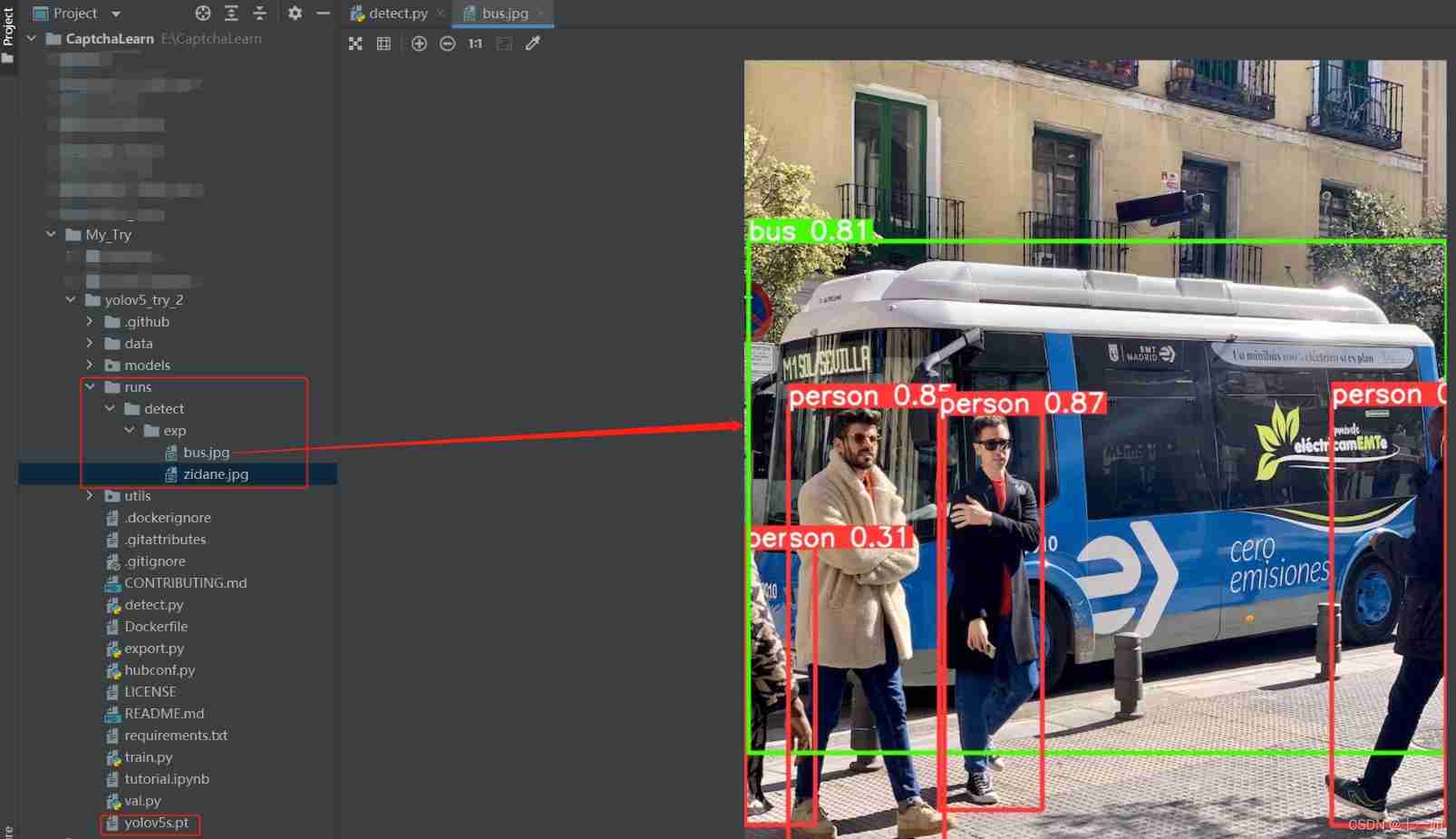
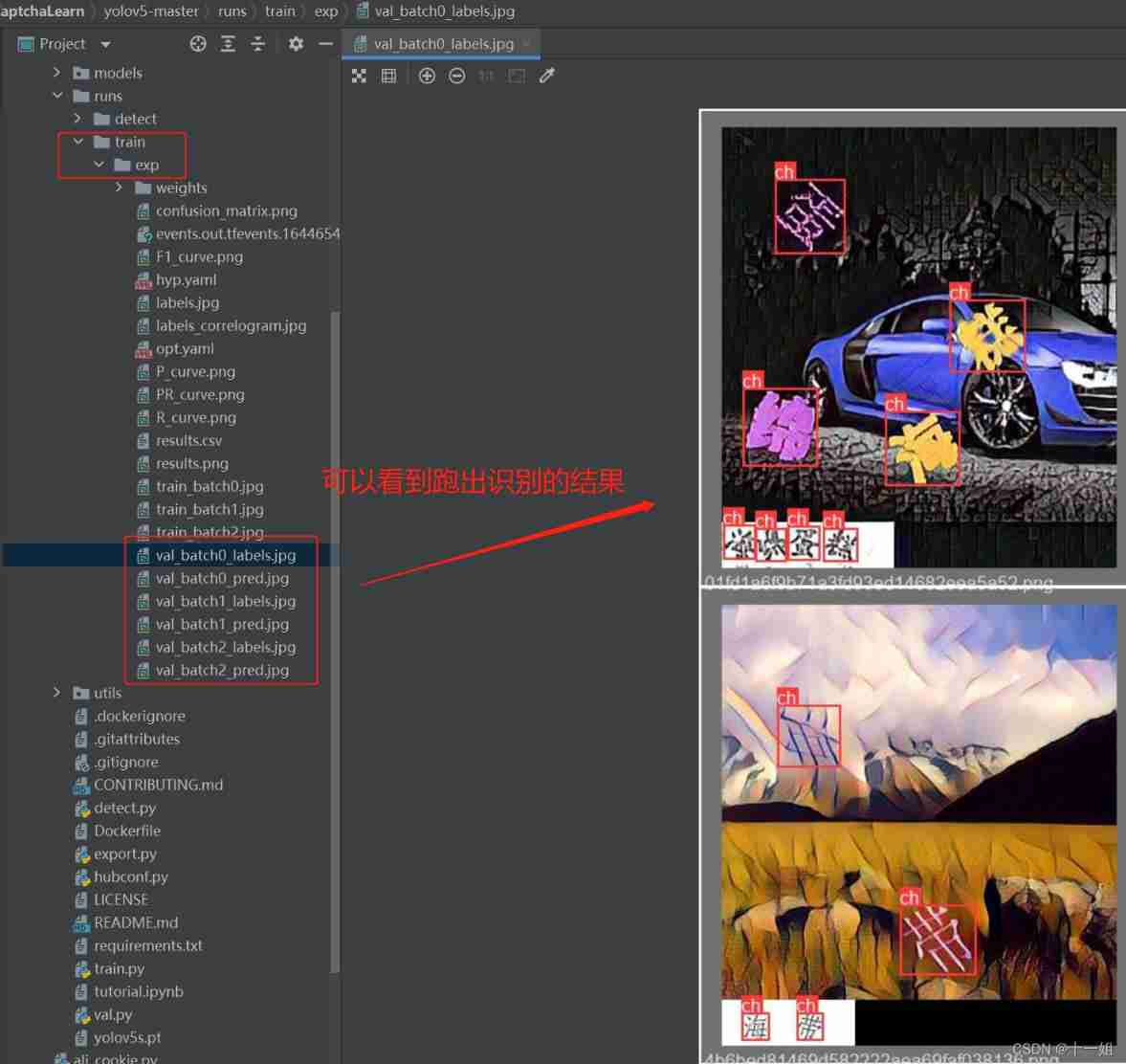
- Here is runs>detect>exp Identification results under the folder , The target has been automatically identified as bus still person, And marked
Four 、 Open data sets 【 masks 】 Train and identify cases
Open data sets roboflow network , There are many data sets , I downloaded the data set of masks here , The picture is about 149 Zhang ; Other public datasets DataCastle network , Jishi network , Others, etc
First of all, we Download the mask data set A marked data set is decompressed and stored in
I created a new folder MaskWearing, The directory of this folder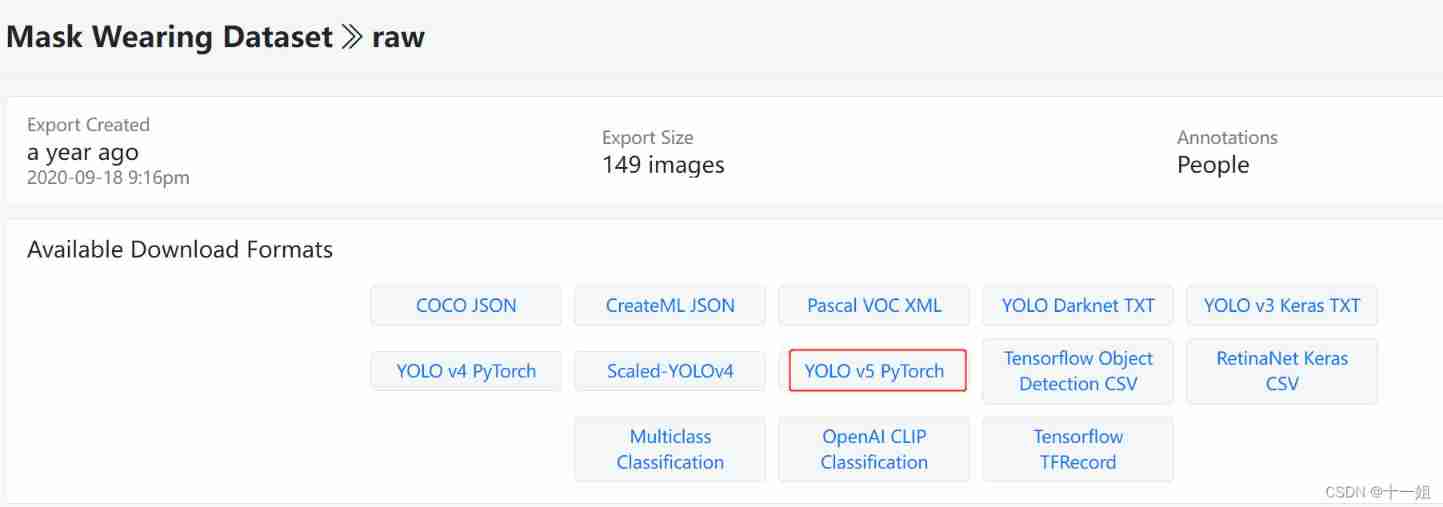
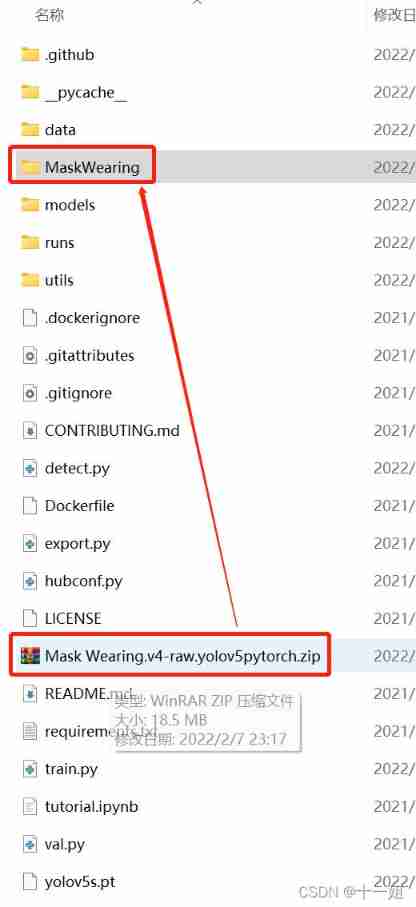
MaskWearing Data set introduction : The main
Yes 3 individual : Data set of training pictures , Verify the data set of the picture , as well as data.yaml To configure. among images Folders are for pictures ,labels Under the folder is yolo Format .txt Label file ,images Folders and labels The contents of the folder are one-to-one correspondence , The file names are all the same , The suffix is different .data.yaml The configuration file is described in detail below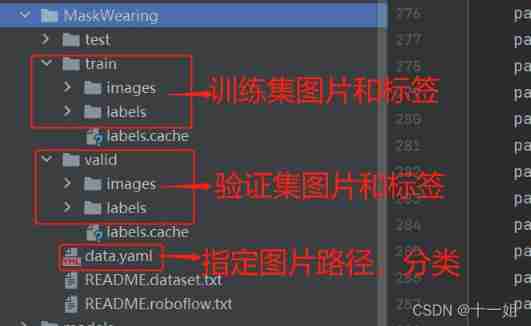
change yaml File configuration : Pictured
data.yaml Correct the storage path of data set, among train It refers to the path of the image file to be trained , and val It refers to the image path to be verified , and nc representative 2 A classification ,names Represents the name corresponding to the two classifications ; be based on yolov5s.pt The training will be modifiedyolov5s.yaml Inside nc classification, according to data.yaml Of nc Modify the classification quantity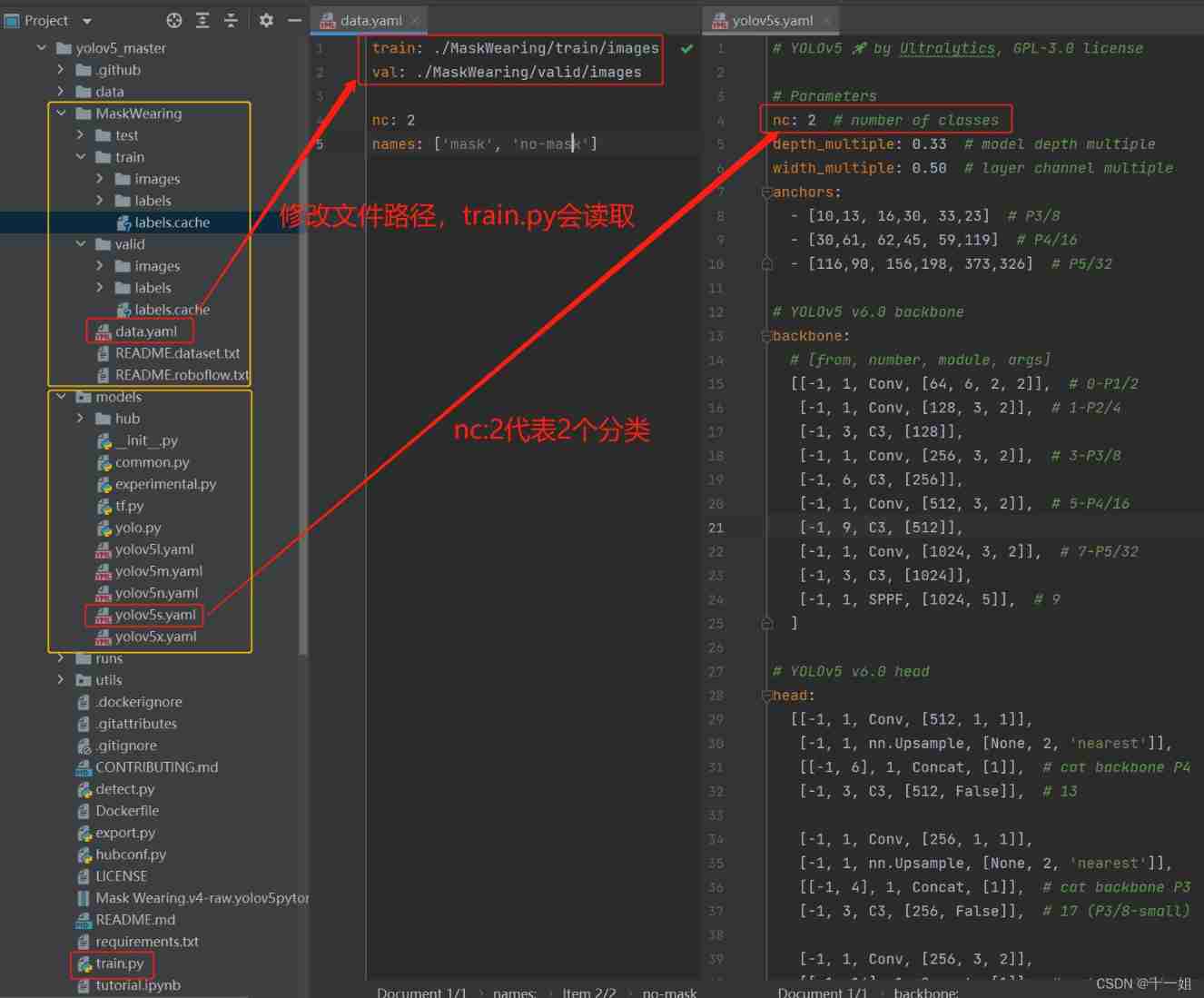
modify train.py Parameters and then start training: The training mainly modifies the following parameters , After running, it will automatically generate runs>train>exp>weights Folder , One will be generated under the folderbest.ptWeight modelweights: Select the model weight , Such as :yolov5s.pt / yolov5m / yolov5l( It can be understood as s Small ,m Medium ,l Large , The corresponding detection speed is from fast to slow , But the accuracy is from low to high )cfg: Specify the location of the model configuration file, such as models/yolov5s.yamldata: Specify your own dataset configuration file location, such as ./MaskWearing/data.yamlepochs: Specify the number of training rounds , The default initial setting is 300, For example, the data set of this mask 149 A picture , I started setting 3 The trained model is not effective , The test did not frame the mask correctly , Set to 10 Then the target is recognized normally , So adjust according to the actual situationbatchsize: according to GPU Set the size of the video memory , It's usually 2 Multiple , I set up here 4img-size: The size of the image resolution reduced or enlarged , Default 640, Adjust according to the world
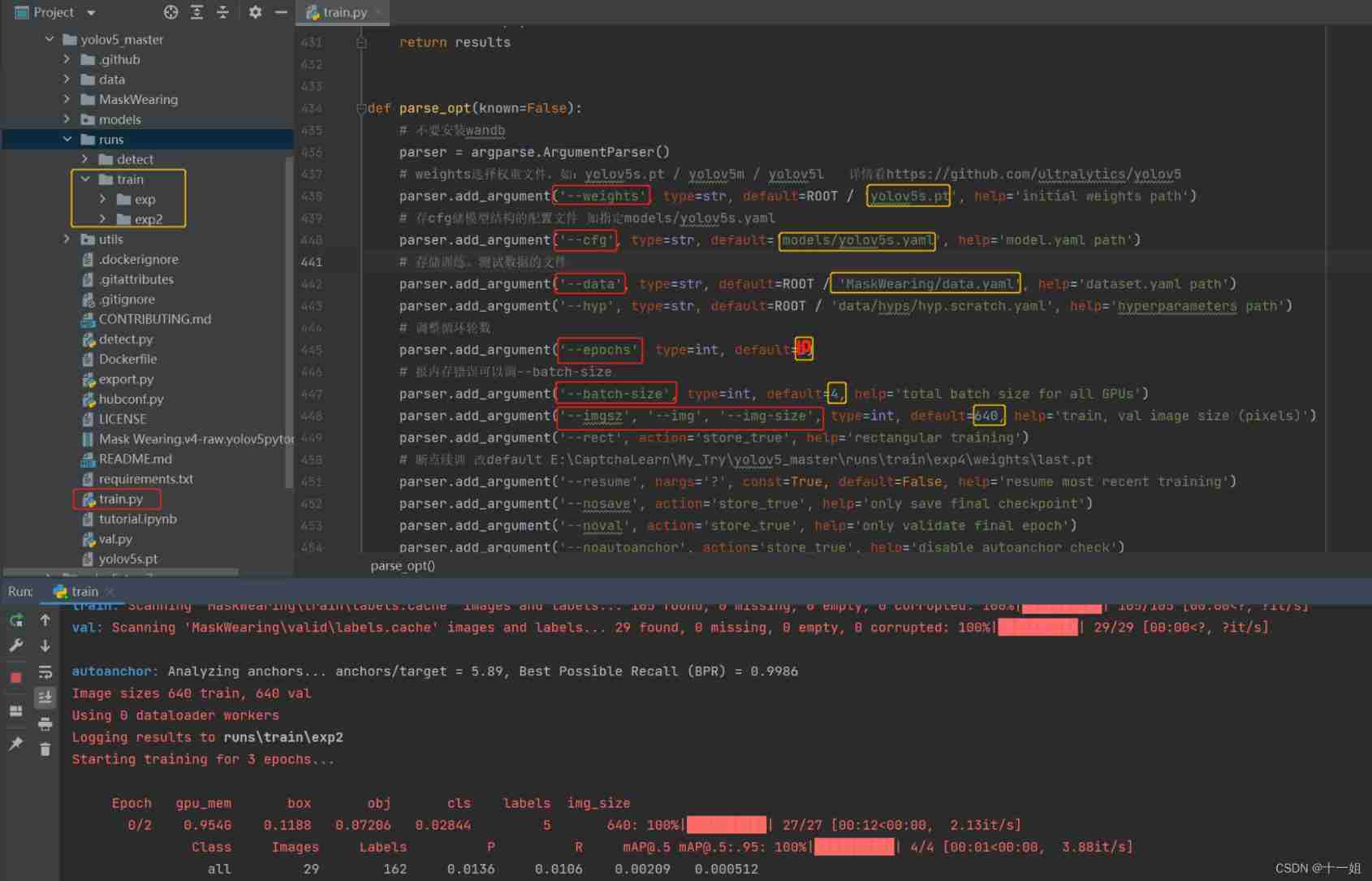
If you make a mistake
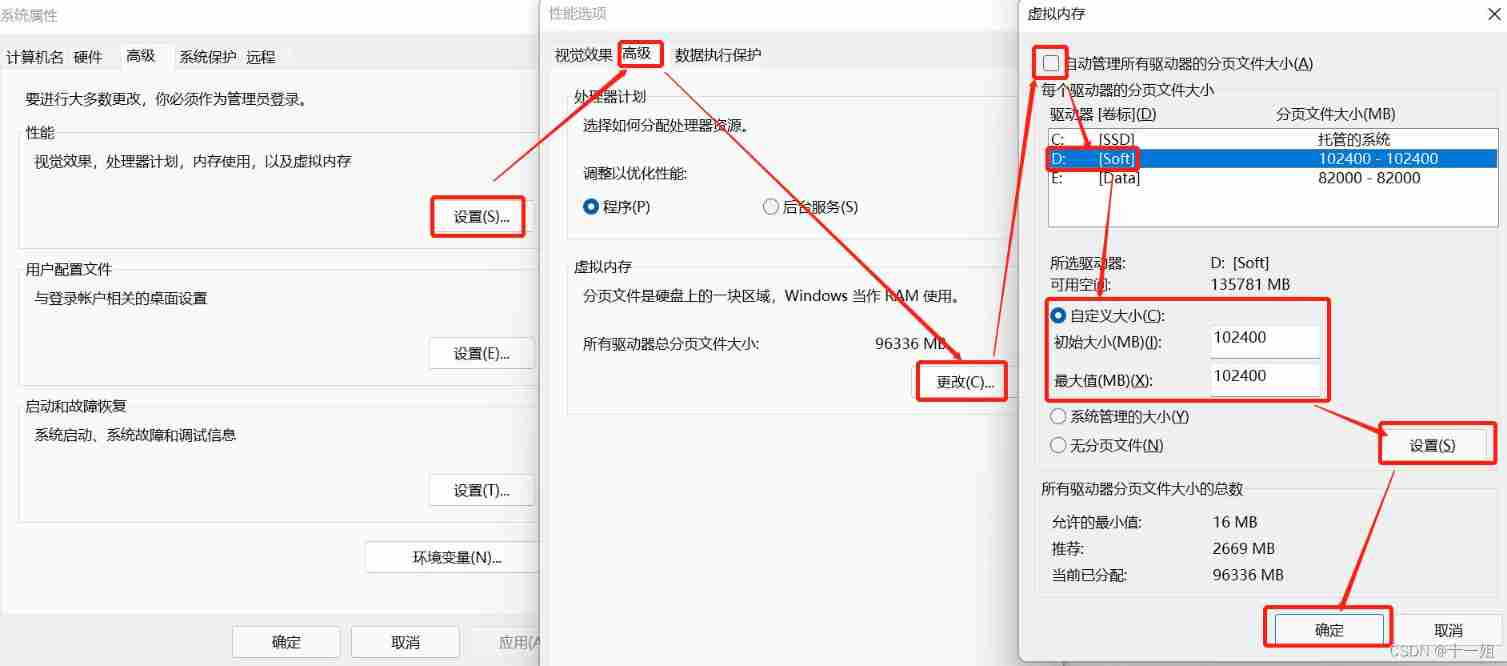
OSError: [WinError 1455] The page file is too small , Unable to complete operation ., be Look at this article to solve , Search directly to view advanced system settings , Then process according to the picture , Restart the computer after saving ; If this setting still reports an error and does not solve the problem , First restore it to the previous default state of automatically managing all drives , After saving the application , Reopen it again and press the image again .
modify detect.py Parameters and then start testing recognition, It will be generated automatically after training runs>detect>exp Folder , There are recognition results under this folder , So far, training to test the small recognition demo Completedweight: Specify the location of the previously trained weight model filesource: Specify a single picture recognized by the detection , Or picture folder path , Or video path , Or the camera


5、 ... and 、 Label the dataset by yourself 【 Point selection 】 Train and identify cases
1、 utilize labelimg Annotation dataset generation yolo Format
- labelimg Is a data annotation tool , The following three formats can be marked :① VOC Label format , Save as xml file ,② yolo Label format , Save as txt file ,③ createML Label format , Save as json Format ; This annotation selects yolob Label format
- labelimg Installation :
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simpleactivate D:\Programmer\Captcha_env\ pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple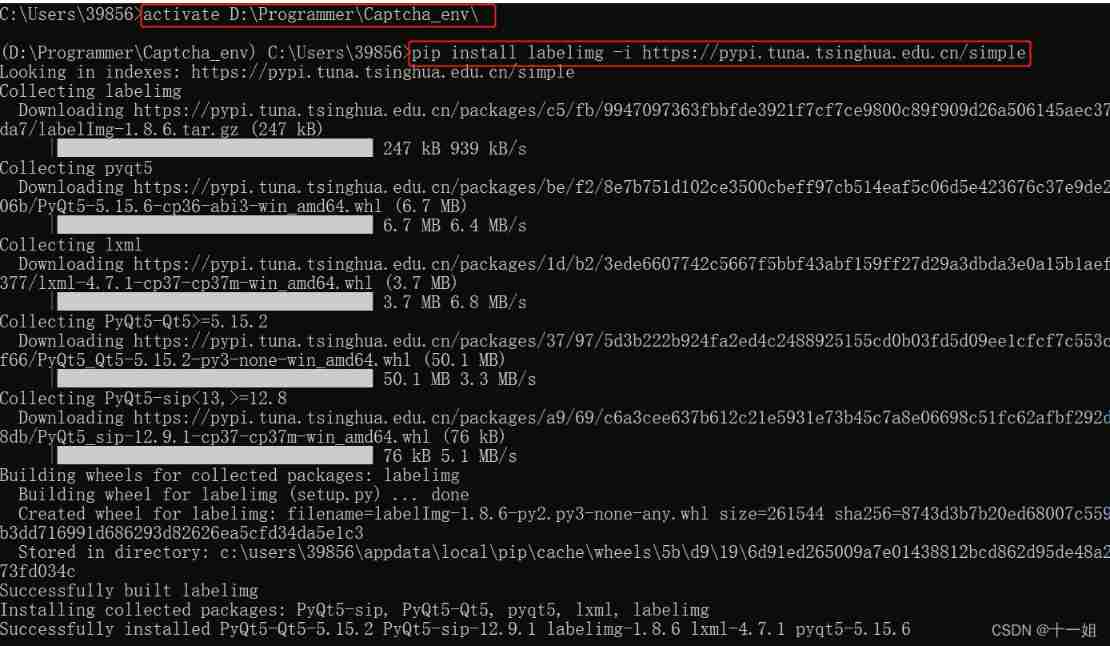
- newly build 2 A folder : One is for storing pictures images, One is for storing labels labels,cmd Continue to input
labelimgYou can enter the home page of the labelactivate D:\Programmer\Captcha_env\ labelimg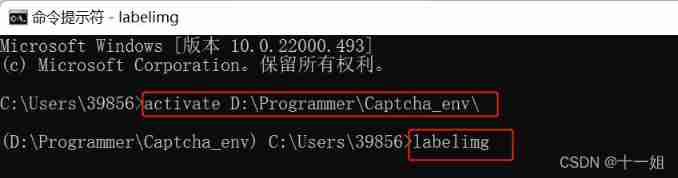
- Set according to the following picture , Remember to choose first
yoloFormat , Then start marking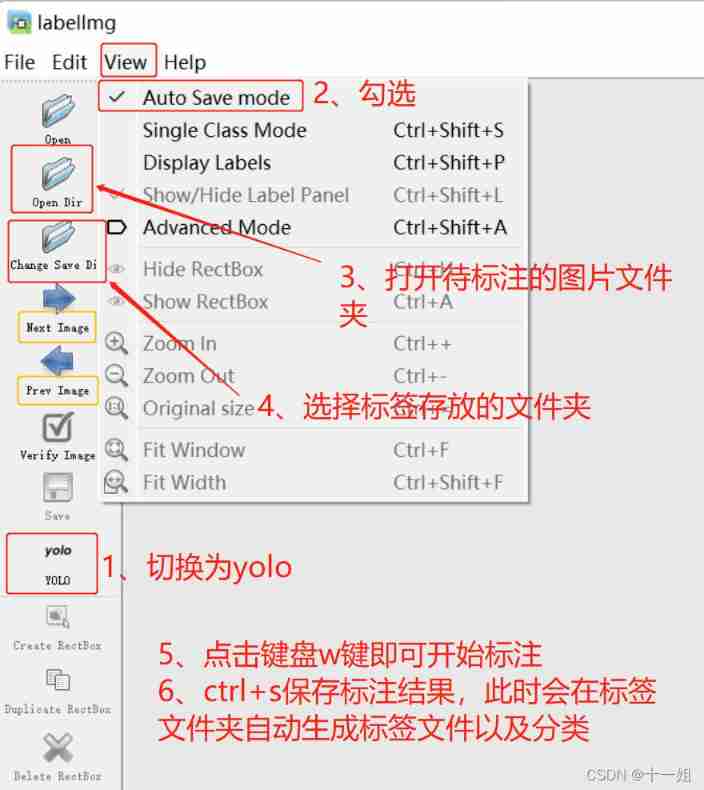
Be careful : Whether it's a labeled picture , Or the path , Or tag name , Try not to write Chinese , Otherwise, there will be unexpected mistakes , For example, it may not work all the time and report errors OSError: [WinError 1455] The page file is too small , even to the extent that pycharm Flashback, etc- Mark the prepared pictures as shown in the figure , Press
w keyYou can start marking , Then customize the label classification , You can also set the default classification on the right , After saving, the folder where you save the tag willAutomatic generation yolo Format .txt file, There is a generalclasses.txtThis will count all your category names according to the order in which the labels appear ; Then mark it
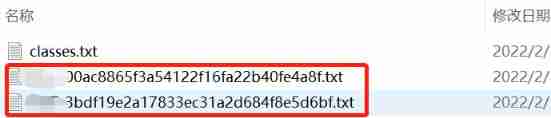
2、 Standardization of data set format
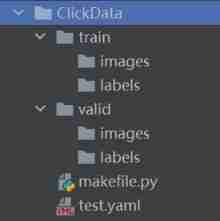
First, create an empty folder , New inside
make_file.pyas follows , After running, it will automatically generate some necessary folder paths, such as images,labels, .yaml; Then copy the marked pictures and labels into the corresponding folders ;.yaml The file configuration is set according to your specific situation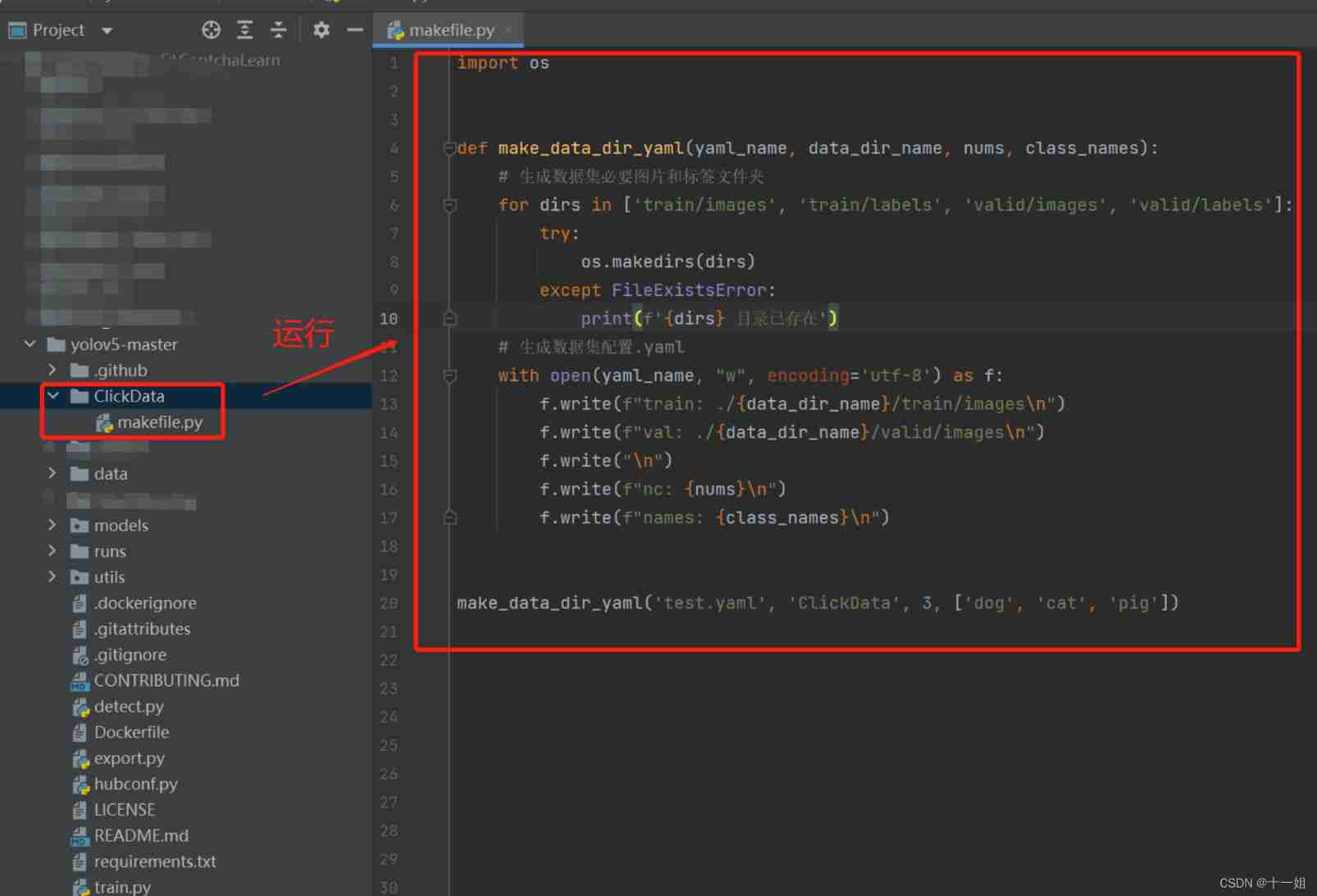
import os def make_data_dir_yaml(yaml_name, data_dir_name, nums, class_names): # Generate the necessary image and label folders for the dataset for dirs in ['train/images', 'train/labels', 'valid/images', 'valid/labels']: try: os.makedirs(dirs) except FileExistsError: print(f'{ dirs} directory already exists ') # Generate dataset configuration .yaml with open(yaml_name, "w", encoding='utf-8') as f: f.write(f"train: ./{ data_dir_name}/train/images\n") f.write(f"val: ./{ data_dir_name}/valid/images\n") f.write("\n") f.write(f"nc: { nums}\n") f.write(f"names: { class_names}\n") make_data_dir_yaml('test.yaml', 'ClickData', 3, ['dog', 'cat', 'pig'])
3、 Training and test identification
train.pyThe training is changed as follows , Focus on--data, The path is changed to your own data set .yaml file , Other configurations will be adjusted according to the actual situation , See Table 2 above for the specific parameter meanings ; And then run train.py Started training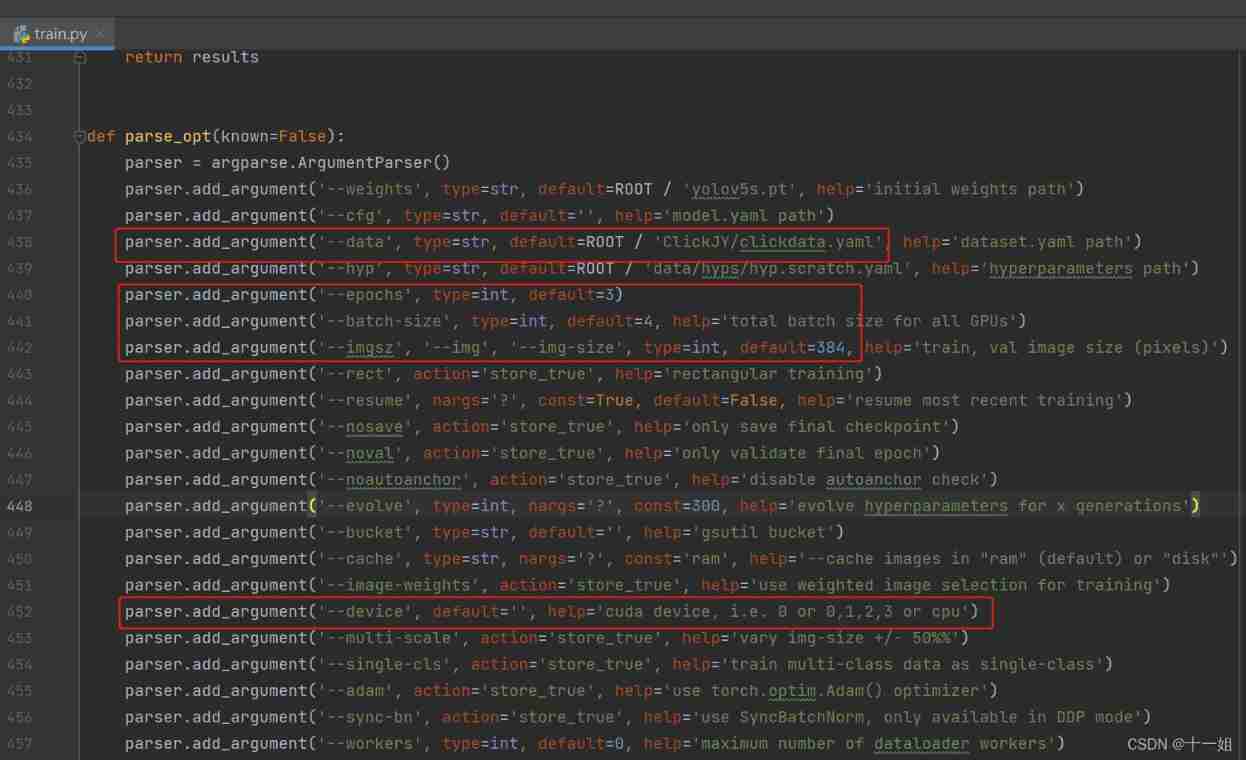
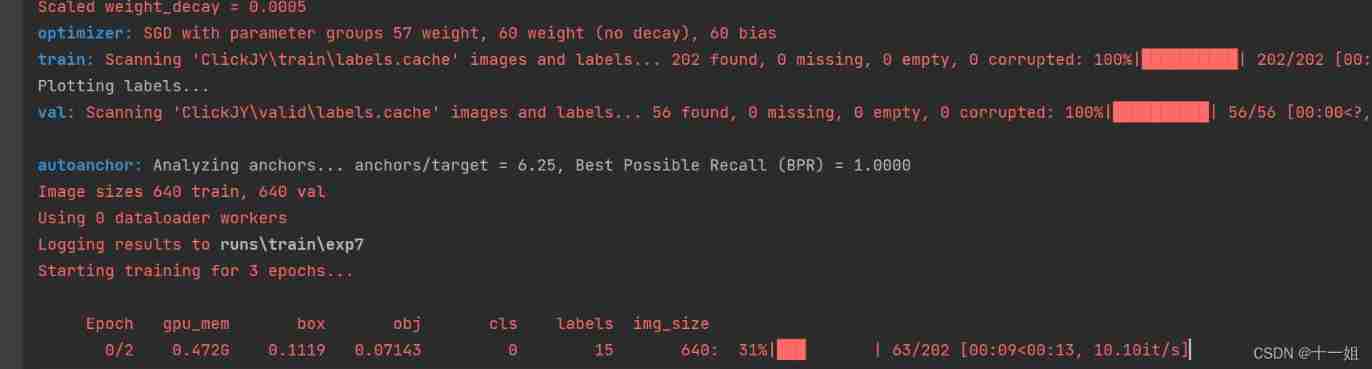
After the training, the results will be automatically generated to runs/train/exp Under the folder , The video 7 minute ~10 Minutes away Will introduce the folder where the training results are generated runs/train/exp The meaning of each document
detect.pyIdentify the picture to be tested , Change several configurations as follows , Focus on--weights and --sourceThese two configurations , Choose a well trained weight model , Choose a picture to be tested , And then run , Eventually it will be yolov5-master/runs/detect/exp Test results will be automatically generated under the path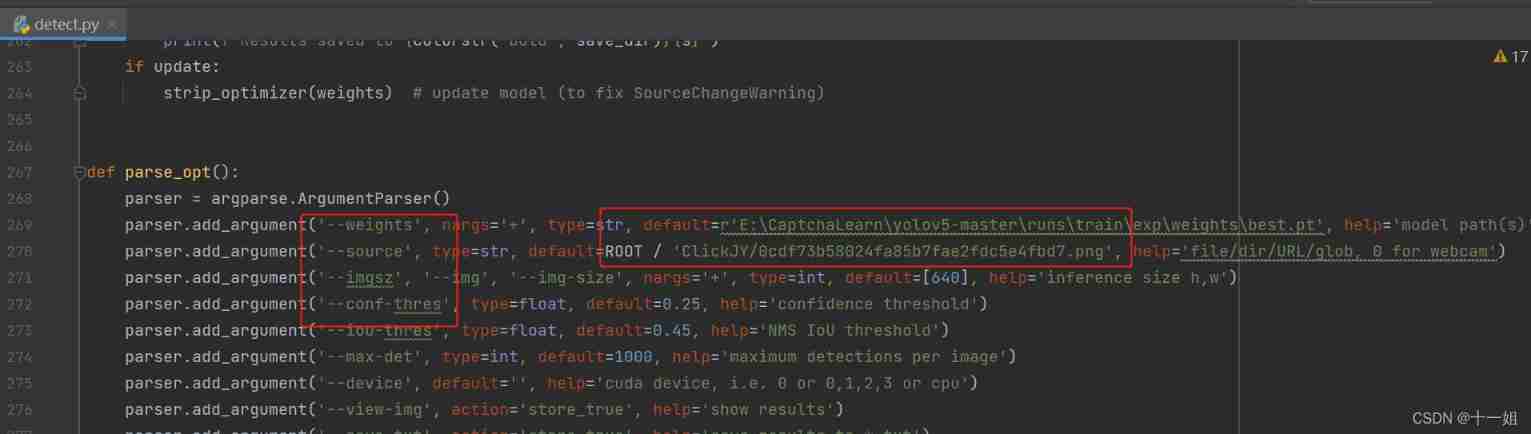

val.py: Verify the weight file separately , The time-consuming display of pictures and the accuracy of recognition are here 0.187 A relatively low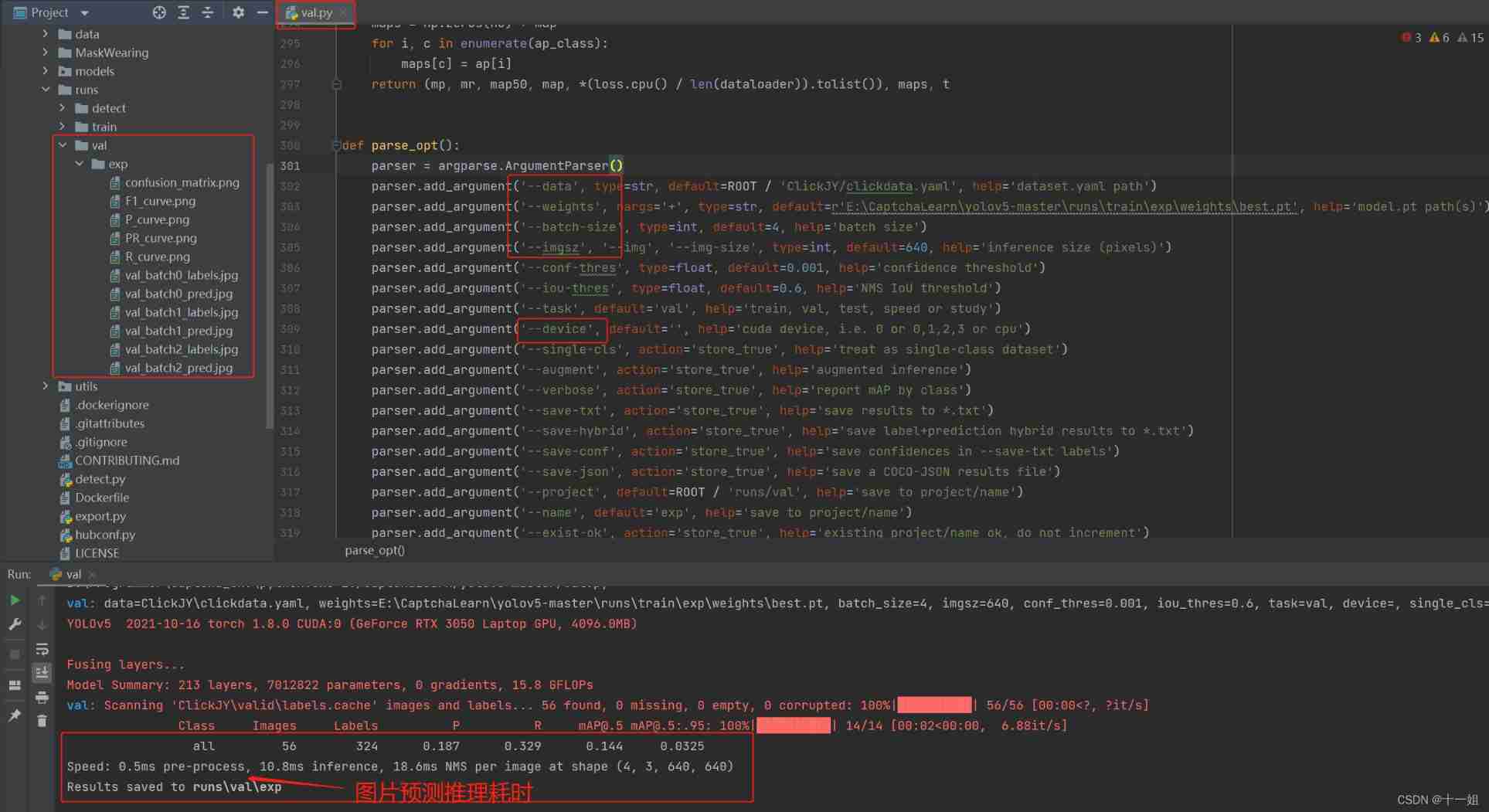
So far, the whole process is almost over , You can also continue to optimize, such as the output coordinates of the recognition results
边栏推荐
- F12 solve the problem that web pages cannot be copied
- Detailed summary of SQL injection
- Rce code and Command Execution Vulnerability
- 算法-- 爬楼梯(Kotlin)
- 关于Unity Inspector上的一些常用技巧,一般用于编辑器扩展或者其他
- Configuration file converted from Excel to Lua
- Postman assertion
- The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
- UCF (summer team competition II)
- Hyperledger Fabric2. Some basic concepts of X (1)
猜你喜欢
【OSPF 和 ISIS 在多路访问网络中对掩码的要求】
Cve-2019-11043 (PHP Remote Code Execution Vulnerability)
自建DNS服务器,客户端打开网页慢,解决办法
![[leetcode16] the sum of the nearest three numbers (double pointer)](/img/99/a167b0fe2962dd0b5fccd2d9280052.jpg)
[leetcode16] the sum of the nearest three numbers (double pointer)

pix2pix:使用条件对抗网络的图像到图像转换
![[classic example] binary tree recursive structure classic topic collection @ binary tree](/img/39/0319c4be43716f927b9d98d89f7655.jpg)
[classic example] binary tree recursive structure classic topic collection @ binary tree
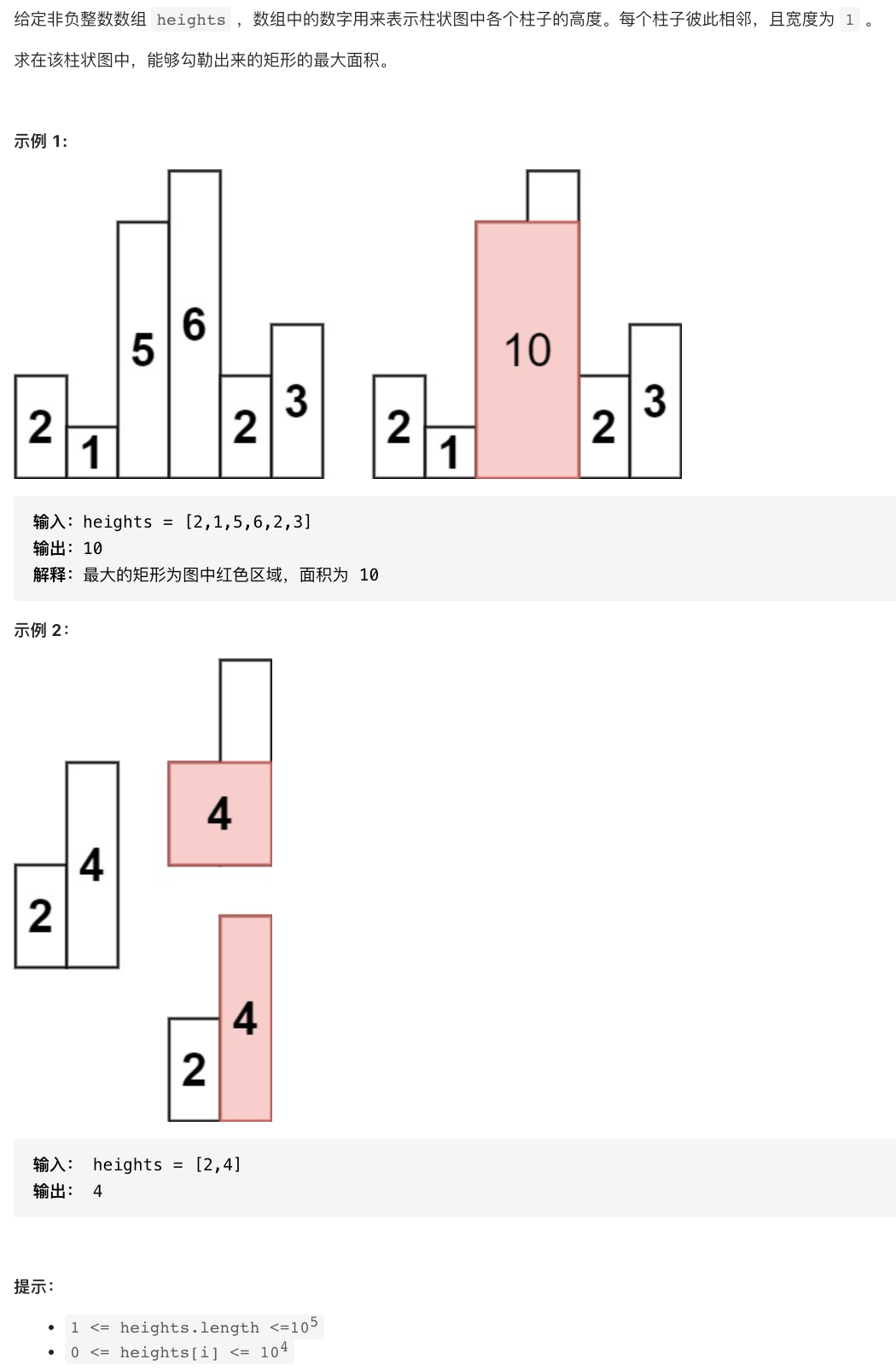
剑指 Offer II 039. 直方图最大矩形面积
Questions d'examen écrit classiques du pointeur

February 12 relativelayout
GAMES202-WebGL中shader的编译和连接(了解向)
随机推荐
C Advanced - data storage (Part 1)
UCF (2022 summer team competition I)
Building intelligent gray-scale data system from 0 to 1: Taking vivo game center as an example
Graduation design game mall
Unity gets the width and height of Sprite
Ora-01779: the column corresponding to the non key value saving table cannot be modified
Oracle deletes duplicate data, leaving only one
[untitled]
01. 开发博客项目之项目介绍
Talking about the type and function of lens filter
2022 half year summary
【华为机试真题详解】统计射击比赛成绩
Sorting out the knowledge points of multicast and broadcasting
UCF (summer team competition II)
The ECU of 21 Audi q5l 45tfsi brushes is upgraded to master special adjustment, and the horsepower is safely and stably increased to 305 horsepower
Driver development - hellowdm driver
Cuda11.1 online installation
MySQL time processing
關於Unity Inspector上的一些常用技巧,一般用於編輯器擴展或者其他
图数据库ONgDB Release v-1.0.3