当前位置:网站首页>【Copy攻城狮日志】飞浆学院强化学习7日打卡营-学习笔记
【Copy攻城狮日志】飞浆学院强化学习7日打卡营-学习笔记
2022-08-04 05:30:00 【语歆】
本文首次发表于公众号-[胡琦],是作者在飞桨深度学习学院和世界冠军团队科老师从零实践深度学习的一些学习感悟。主要整理这7天来的学习笔记,7天
深入一门新技术很难,但仅仅只是稍微了解一下,7天时间远远足够!【文末福利:领取免费算力卡】

↑开局一张图,故事全靠编。
我常常会扪心自问,一个连本行工作都干不好的人,还有时间去捣鼓别的领域,去“学习”别的领域的新知识?然鹅,自诩为“Copy攻城狮”的我,膨胀到像
学一波AI,不求结果,为了兴趣愿意去尝试,哪怕到头来竹篮打水一场空。于是,机缘巧合通过齐老师了解到Baidu的AIStuio以及此次飞浆的实战入门课。
国际惯例,免费的午餐实际上并非真正的面试,如同HuaweiCloud的AI训练营推广ModelArts,这次的课也是为了推广飞浆。当然,对于AI小白来说,这些
都是非常不错的工具,里面的学习资源也非常丰富,废话不多说,马上开启Copy之路!
前言
几天的课下来,我发现还是啥也不会,除了认识到为啥叫“炼丹”,其他的感觉看电影一样,过了就忘了具体的细节。于是想整理一下这几天的资料,方便日后
再有兴趣的时候来好好查阅学习。当看到前置课程需要掌握大量的数学基础和Python基础,我内心是拒绝的,真的不知道怎么高效地学习,幸好课程作业只要
简单的复制粘贴就能拿80分甚至刚开始就能拿100分,这也许成了我能坚持这几天的唯一原因–没有太大的挫败感。先来看看有哪些前置的知识需要掌握吧!
光数学基础这点,就有好几十个定义、公式、结论,比如导数和微积分的概念、泰勒公式、克莱姆法则……,毕竟无论是深度学习还是机器学习都离不开大量的数学原理和公式推导。记得以前去听一些人工智能相关专题的讲座,台上的大佬都会搬出一些数学公式推导和一些统计数据,台下的我到现在依旧是一愣一愣的,“少壮不努力老大徒伤悲!”。其次,还需掌握一些基础的Python知识,如基础关键字和语法、常用的数据结构、循环、函数、面向对象编程等,尽管我作为资深【Copy攻城狮】,有过一定的编程经历,但是Python还是第一接触,还是花了不少时间跟着教程敲了敲。另外,就是工具的学习,如PaddlePaddle快速入门、Notebook使用。这里还是要重点提下百度AIStudio平台,这是一个学习AI的好地方,之前有参加齐伟老师的《数据准备和特征工程》的课,于是了解到这个集课程、实践、比赛、考试认证于一体的AI学习平台,听说很多高校都在用,用过的都说好。更有AI学习地图,让我的每次努力多有收获–翔实的学习路线,完善的学-赛-用的学习体系,实战应用项目,将所学转化为生产力,真香!接下来看看本次训练营学习的具体内容吧!
强化学习(RL)初印象
首先从概念谈起,强化学习(Reinforcement learning,简称RL)是机器学习(Machine Learning,简称ML)中的一个领域,强调如何基于环境而行动以获取最大化的预期利益。核心思想包括智能体anget在环境environment中学习,根据环境的状态state(或者观测到的observation),执行动作action,并根据环境的反馈reward来指导更好的动作。总结一下就是分为两部分agent、environment和三要素state(observation)、action和reward。以游戏Flappy Bird为例,小鸟就是强化学习的智能体agent,整个游戏背景就是环境environment,当前小鸟的位置就是状态state,小鸟上下移动就是动作action,得分就是反馈reward。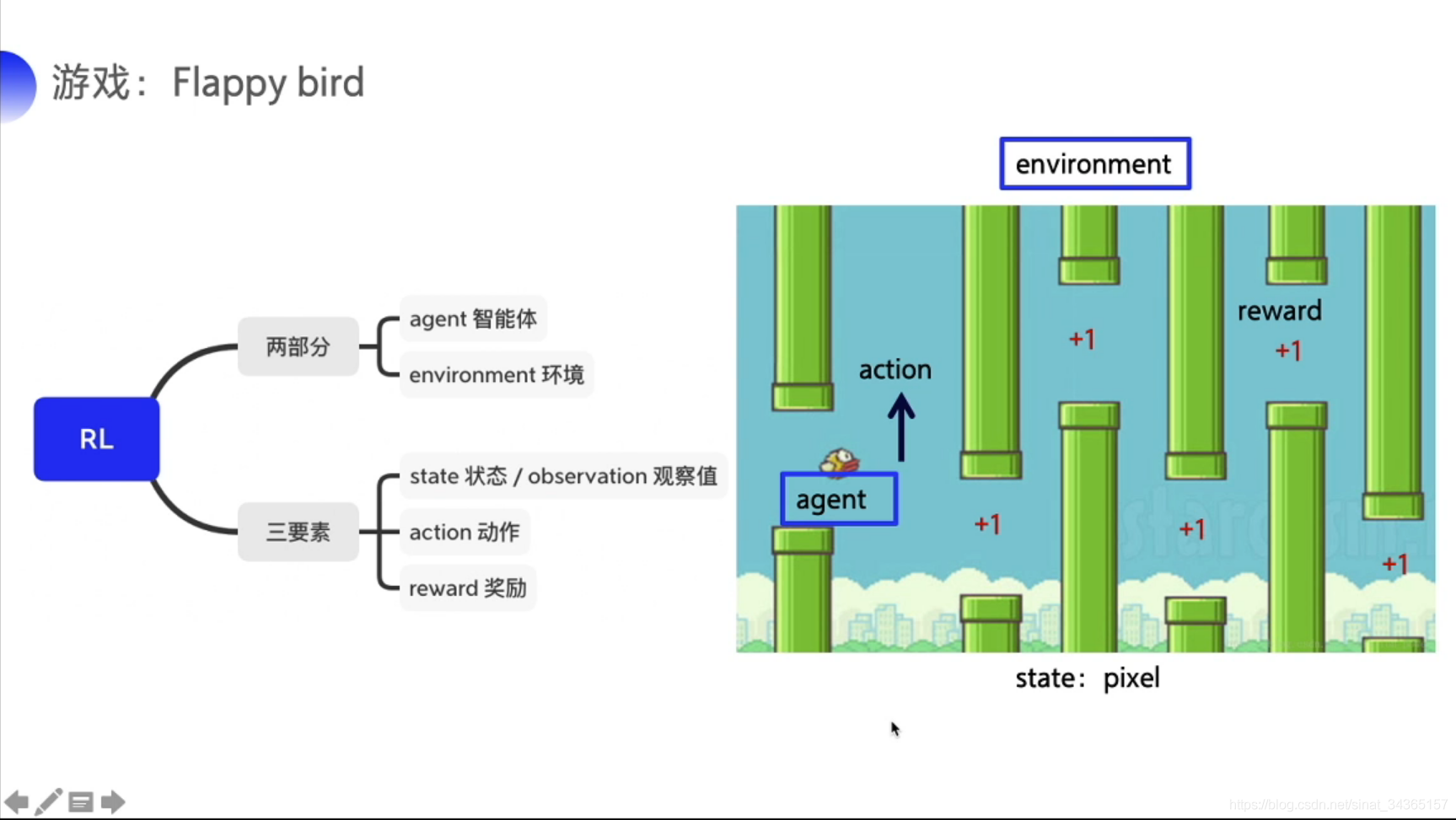
那强化学习有什么用呢?通过课程我了解到强化学习的应用很广泛,如游戏(打过人机吗?)、机器人控制(机械臂、自动驾驶、四驱飞行器等)、用户交互(推荐、广告、自然语言处理NLP等)、交通(拥堵管理等)、资源调度(物流、带宽等)、金融(投资组合、股票买卖等)。对于我而言为什么学习强化学习?一是想简单;了解一下AI,二是想实践一个简单的Demo进行运用。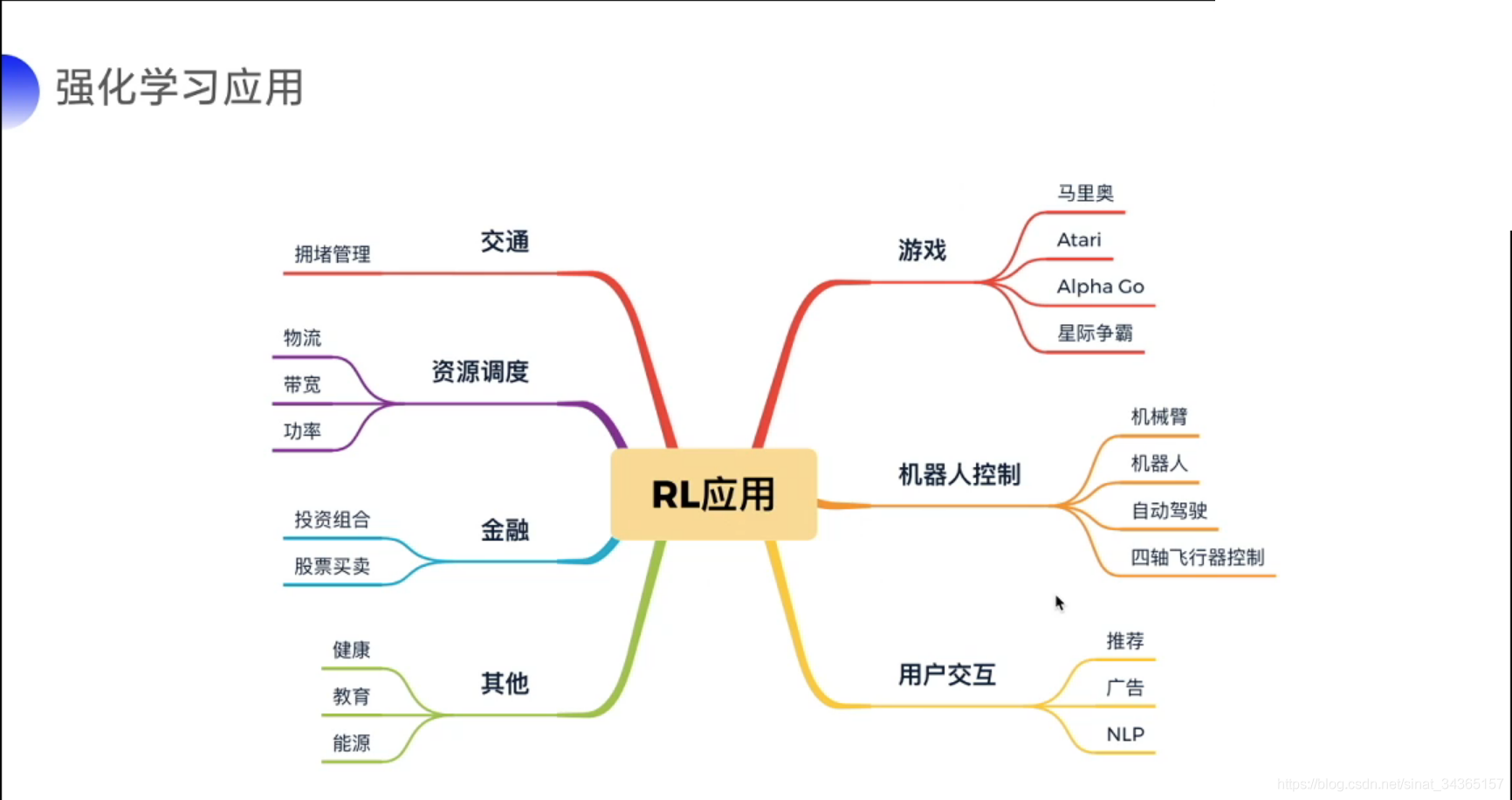
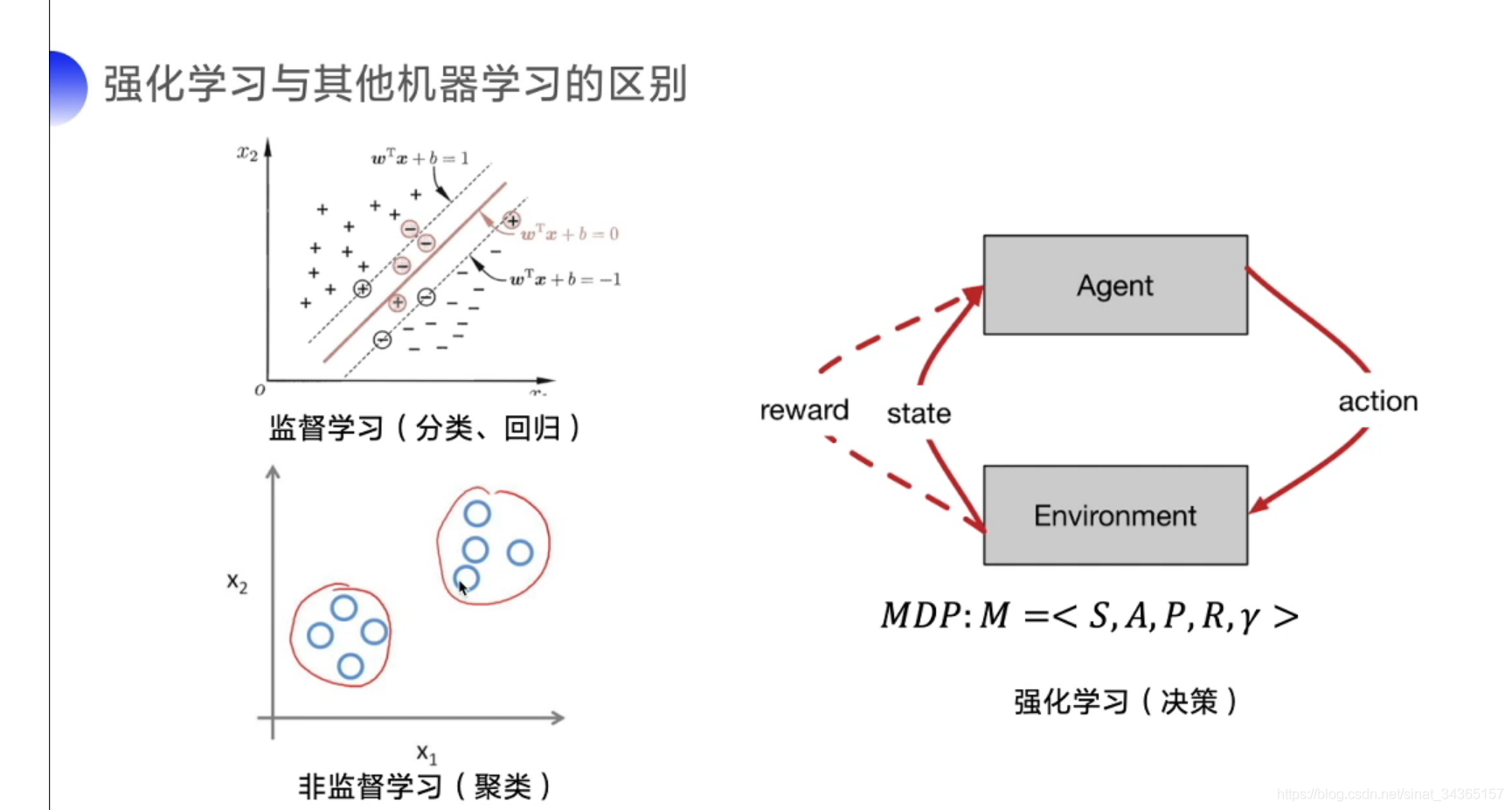
下面两张图简要说明强化学习与其他机器学习的关系和区别,个人认为强化学习需要在与环境交互中学习和寻找最佳决策方案,相比监督学习处理认知问题而言,强化学习处理决策问题。强化学习通过不断的试错探索,吸取经验和教训,持续不断的优化策略,从环境中拿到更好的反馈,强化学习有两种学习方案:基于价值(value-based)、基于策略(policy-based)。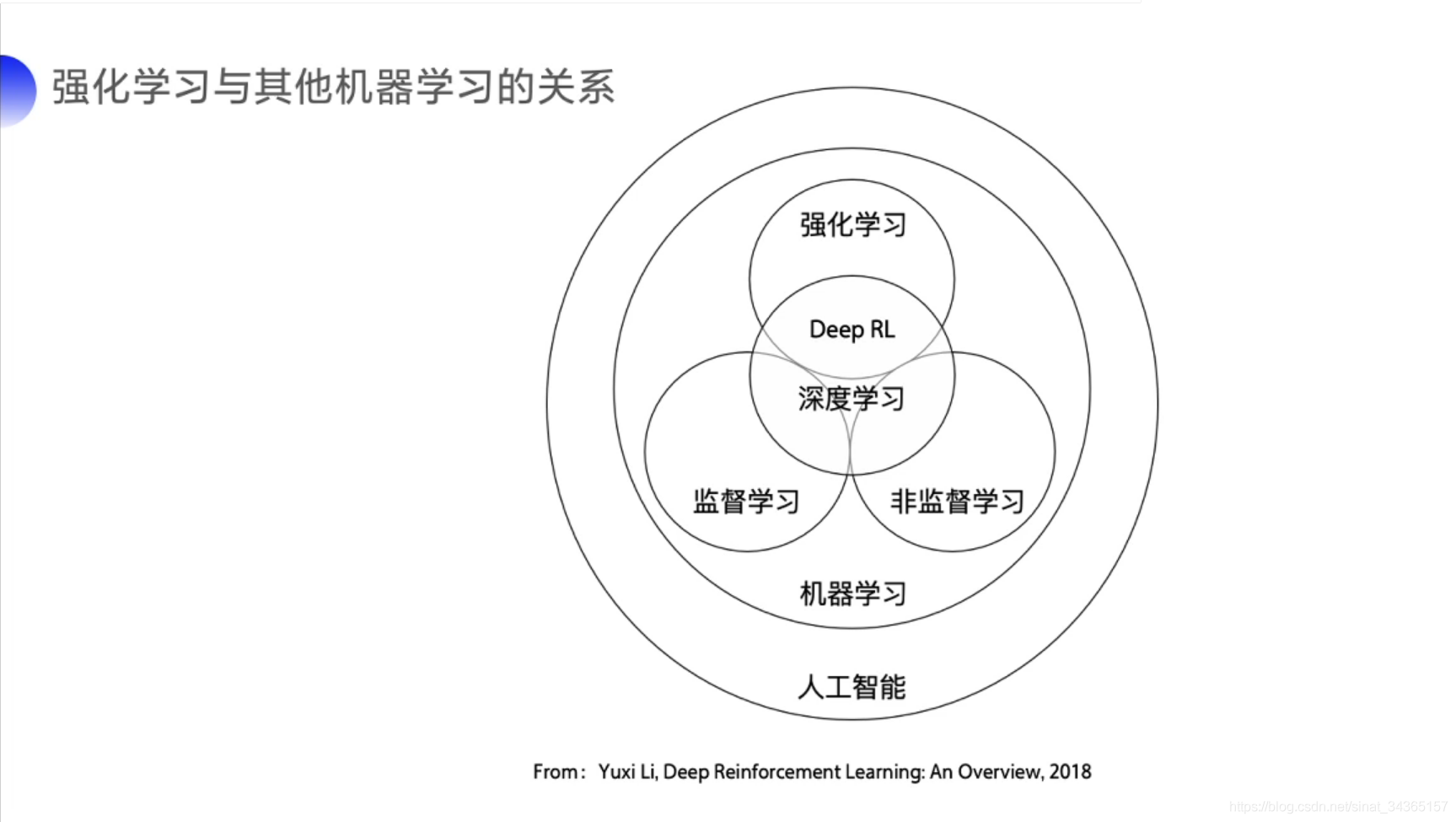
强化学习中经典的算法有Q-learning、Sarsa、DQN、Policy Gradient、A3C、DDPG、PPO;强化学习环境分为离散控制场景(输出动作可数)、连续控制场景(输出动作值不可数)。这里推荐强化学习的经典环境库GYM和强化学习框架PARL。
基于表格型方法求解RL
具体知识点可查看从零实践强化学习之基于表格型方法求解RL(PARL),讲到了强化学习MDP四元组< S(state状态), A(action动作), P(probability状态转移概率), R(reward奖励) >,讲到了未知环境的强化学习Model-free试错探索(机器学习取代人被狗熊咬死的惨剧),进而提到状态动作价值Q表格、强化概念、Temporal Difference时序差分等。然后就需要接触到Sarsa算法和Q-learning。
Sarsa全称是state-action-reward-state’-action’,目的是学习特定的state下,特定action的价值Q,最终建立和优化一个Q表格,以state为行,action为列,根据与环境交互得到的reward来更新Q表格,更新公式为:
Sarsa在训练中为了更好的探索环境,采用ε-greedy方式来训练,有一定概率随机选择动作输出。
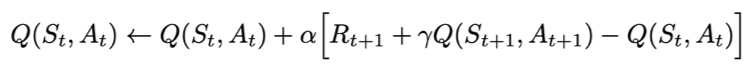
Q-learning也是采用Q表格的方式存储Q值(状态动作价值),决策部分与Sarsa是一样的,采用ε-greedy方式增加探索。
Q-learning跟Sarsa不一样的地方是更新Q表格的方式。
- Sarsa是on-policy的更新方式,先做出动作再更新。
- Q-learning是off-policy的更新方式,更新learn()时无需获取下一步实际做出的动作next_action,并假设下一步动作是取最大Q值的动作。
Q-learning的更新公式为:
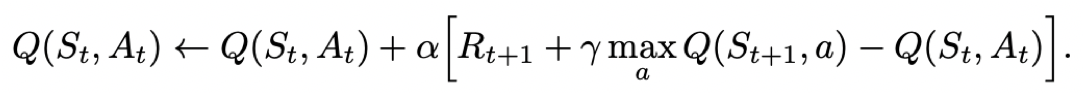
基于神经网络方法求解RL
具体知识点可查看从零实践强化学习之基于神经网络方法求解RL(PARL),讲到了函数逼近和神经网络。神经网络可以理解为一个黑盒,可以把输入x转为我们预期的输出y,如输入一张手写数字3的图片,输入数字3,输入一张猫的图片输出猫,输入房屋位置、面积等输出房价,然后会学习神经网络方法求解RL——DQN(Deep Q-Learning)。
本质上DQN还是一个Q-learning算法,更新方式一致。为了更好的探索环境,同样的也采用ε-greedy方法训练。
在Q-learning的基础上,DQN提出了两个技巧使得Q网络的更新迭代更稳定。
- 经验回放 Experience Replay:主要解决样本关联性和利用效率的问题。使用一个经验池存储多条经验s,a,r,s’,再从中随机抽取一批数据送去训练。
= 固定Q目标 Fixed-Q-Target:主要解决算法训练不稳定的问题。复制一个和原来Q网络结构一样的Target Q网络,用于计算Q目标值。
- 经验回放 Experience Replay:主要解决样本关联性和利用效率的问题。使用一个经验池存储多条经验s,a,r,s’,再从中随机抽取一批数据送去训练。
基于策略梯度求解RL
具体知识点可查看从零实践强化学习之基于策略梯度求解RL(PARL),讲到了随机策略与策略梯度。然后就是策略梯度方法求解RL——Policy Gradient。
- 在强化学习中,有两大类方法,一种基于值(Value-based),一种基于策略(Policy-based)
- Value-based的算法的典型代表为Q-learning和SARSA,将Q函数优化到最优,再根据Q函数取最优策略。
- Policy-based的算法的典型代表为Policy Gradient,直接优化策略函数。
- 采用神经网络拟合策略函数,需计算策略梯度用于优化策略网络。
- 优化的目标是在策略π(s,a)的期望回报:所有的轨迹获得的回报R与对应的轨迹发生概率p的加权和,当N足够大时,可通过采样N个Episode求平均的方式近似表达。

- 优化目标对参数θ求导后得到策略梯度:
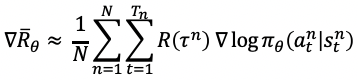
- 优化的目标是在策略π(s,a)的期望回报:所有的轨迹获得的回报R与对应的轨迹发生概率p的加权和,当N足够大时,可通过采样N个Episode求平均的方式近似表达。
- Policy Gradient实践代码
连续动作空间上求解RL
具体知识点可查看从零实践强化学习之连续动作空间上求解RL(PARL),个人理解连续动作空间是一些相对复杂的场景,如开车时方向盘的角度、机器人行走的动作,需要更加高级的算法来解决,如DDPG(Deep Deterministic Policy Gradient).
DDPG的提出动机其实是为了让DQN可以扩展到连续的动作空间。
DDPG借鉴了DQN的两个技巧:经验回放 和 固定Q网络。
DDPG使用策略网络直接输出确定性动作。
DDPG使用了Actor-Critic的架构。
总结
7天下来,我好像做了一场梦,梦醒时分什么都不记得了。虽然视频认真看了,代码认真Copy了,作业认真炼丹了,结果屡屡碰壁,直到放弃。回到最初的问题,我想大概是没有勇气面对现实–6年工作经验,4年前端开发,可只有1年的技术水准。也许,来强化学习并没有强化学习,罢了罢了,方向不对,再怎么训练都无法收敛!
最后,附上免费算力卡:
- 5a7ba445224144248231eed0e3348c10
- f9417acf24aa4e9fa37cfae461c0896d
- 1c65596a41e34920bf8a13e0aecd9718
领取方法很简单:访问https://aistudio.baidu.com/aistudio/coupon/manage,切换到邀请码验证tab,输入以上邀请码即可兑换,数量有限,先到先得!
边栏推荐
猜你喜欢
![[Deep Learning 21-Day Learning Challenge] 3. Use a self-made dataset - Convolutional Neural Network (CNN) Weather Recognition](/img/d0/3b8549b9704278e8ec1df03a90f80e.png)
[Deep Learning 21-Day Learning Challenge] 3. Use a self-made dataset - Convolutional Neural Network (CNN) Weather Recognition
![[Deep Learning 21 Days Learning Challenge] 2. Complex sample classification and recognition - convolutional neural network (CNN) clothing image classification](/img/5f/e5db59bdca19b275b2139020ebc6ea.png)
[Deep Learning 21 Days Learning Challenge] 2. Complex sample classification and recognition - convolutional neural network (CNN) clothing image classification

【CV-Learning】图像分类
TensorFlow2学习笔记:5、常用激活函数

【go语言入门笔记】12、指针

DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better 图像去模糊

【论文阅读】Multi-View Spectral Clustering with Optimal Neighborhood Laplacian Matrix

Qt日常学习
Pytorch问题总结
简单说Q-Q图;stats.probplot(QQ图)
随机推荐
Jupyter Notebook安装库;ModuleNotFoundError: No module named ‘plotly‘解决方案。
0, deep learning 21 days learning challenge 】 【 set up learning environment
度量学习(Metric learning)—— 基于分类损失函数(softmax、交叉熵、cosface、arcface)
yolov3 data reading (2)
YOLOV5 V6.1 详细训练方法
彻底搞懂箱形图分析
详解近端策略优化
【CV-Learning】卷积神经网络预备知识
yolov3数据读入(二)
PP-LiteSeg
tensorRT5.15 使用中的注意点
【论文阅读】Anchor-Free Person Search
lstm pipeline 过程理解(输入输出)
Lee‘s way of Deep Learning 深度学习笔记
2020-10-19
oracle的number与postgresql的numeric对比
postgresql中创建新用户等各种命令
Matplotlib中的fill_between;np.argsort()函数
【论文阅读】Further Non-local and Channel Attention Networks for Vehicle Re-identification
(TensorFlow) - detailed explanation of tf.variable_scope and tf.name_scope