当前位置:网站首页>3.爬虫之Scrapy框架1安装与使用
3.爬虫之Scrapy框架1安装与使用
2022-07-31 13:20:00 【Python_21.】
1. Scrapy框架
1.1 介绍
Scrapy是一个开源和协作框架, 可以用于数据挖掘, 监测, 自动化测试, 获取API所有返回的数据或网络爬虫.
Scrapy是基于twisted框架开发的, twisted是一个流行的事件驱动的python网络框架,
使用非阻塞(异步)代码实现并发.
1.2 框架图
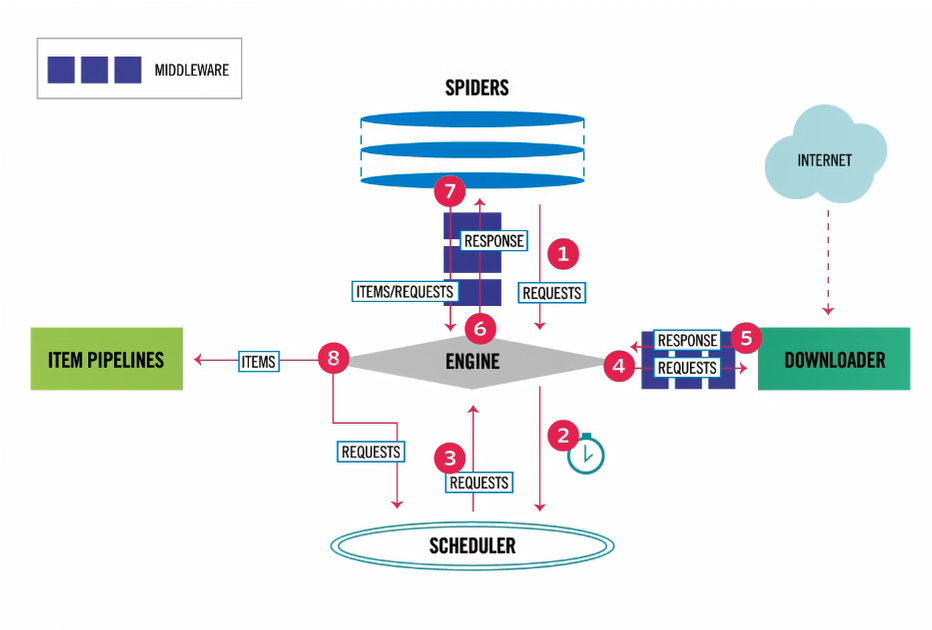
1.3 执行流程
* 1. 爬虫(SPIDERS)中包装成requests对象给引擎(ENGINE).
SPIDERS(爬虫) 只要用于解析数据与发送请求(可以有多个请求).
* 2. 引擎接受到requests对象, 转发到调度器(SCHEDULER).
* 3. 调度器(SCHEDULER)是一个队列(深度优先爬取, 广度优先爬取), 请求排队在经过处理, 返回到调度器中.
* 4. 调度器(SCHEDULER)经过中间件转发到下载器(DOWNLOADER), 下载器中在发送request请求.
* 5. 下载器中得到response响应, 在经过中间件到引擎.
* 6. 引擎得到response经过中间件转发到爬虫解析数据(解析结果是一个网址或数据).
* 7. 爬虫进过中间见转发到引擎
* 8. 引擎判断接受的requesrs对象则再次重复上面步骤, 如果是ITEMS则转发到项目管道(ITEM PIPELINES),
项目管道中对数据进行存储(一个文件可以保存到不同的位置).
1.4 五大组件
五大组件:
1. 引擎: 负责控制数据的流向
2. 调度器: 决定下一个要抓取的网址(集合去重)
3. 下载器: 下载网页内容, 并将网页内容返回到引擎. 下载器是建立在twisted高效的异步模型上.
4. 爬虫: 开发人员自定义的类, 用来解析response, 并且提取items, 获取再次发送requests.
5. 项目管道: 在items被提取后负责处理它们, 主要包括清理, 验证, 持久化操作(写入到数据库)等.
1.5 两大中间件
两大中间件:
1. 爬虫中间件: 位于爬虫与引擎之间, 只要工作室处理爬虫的输入requests和输出.(使用少)
2. 下载中间件: 位于引擎与下载器之间, 加代理头, 加头, 集成selenium.(使用多)
开发者只需要在固定的地方写固定的代码即可.
2. Scrapy安装与基本的使用
2.1 安装
* 在cmd命令窗口执行
命令: pip install scrapy

在windows上可能会出错.
1. pip3 install wheel
# 安装后, 便支持通过wheel文件安装软件
wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
2. pip3 install lxml
3. pip3 install pyopenssl
4. 下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
5. 执行pip3 install 下载目录\Twisted...
6. pip3 install pywin32
7. pip3 install scrapy
8. 测试scrapy命令安装,终端中输入: scrapy
* 如果不行在前面加上 py -m
在cmd命令窗口下安装会将scrapy添加到环境变量,
在PyCharm的Terminl下安装则不会将scrapy添加到环境变量, 需要添加py -m, 开头.
2.2 创建Scrapy项目
* 1. 创建项目命令: scrapy startproject 项目名 存放路径
PS P:\synchro\Project\pc3> scrapy startproject fisetscrapy P:\synchro\Project
New Scrapy project 'fisetscrapy', using template directory 'd:\python files\python38\lib\site-packages\scrapy\templates\project', created in:
P:\synchro\Project
You can start your first spider with:
cd P:\synchro\Project
scrapy genspider example example.com
* 2. 使用pycharm打开爬虫项目
* 3. 创建爬虫程序: scrapy genspider 爬虫名 爬取地址(https://可以省略)
在spiders目录下多出一个爬虫名.py的文件
PS P:\synchro\Project\pc3> scrapy genspider chouti https://dig.chouti.com/
Created spider 'chouti' using template 'basic' in module:
fisetscrapy.spiders.chouti
PS P:\synchro\Project\fisetscrapy> scrapy genspider baidu www.baidu.com
Spider 'baidu' already exists in module:
fisetscrapy.spiders.baidu
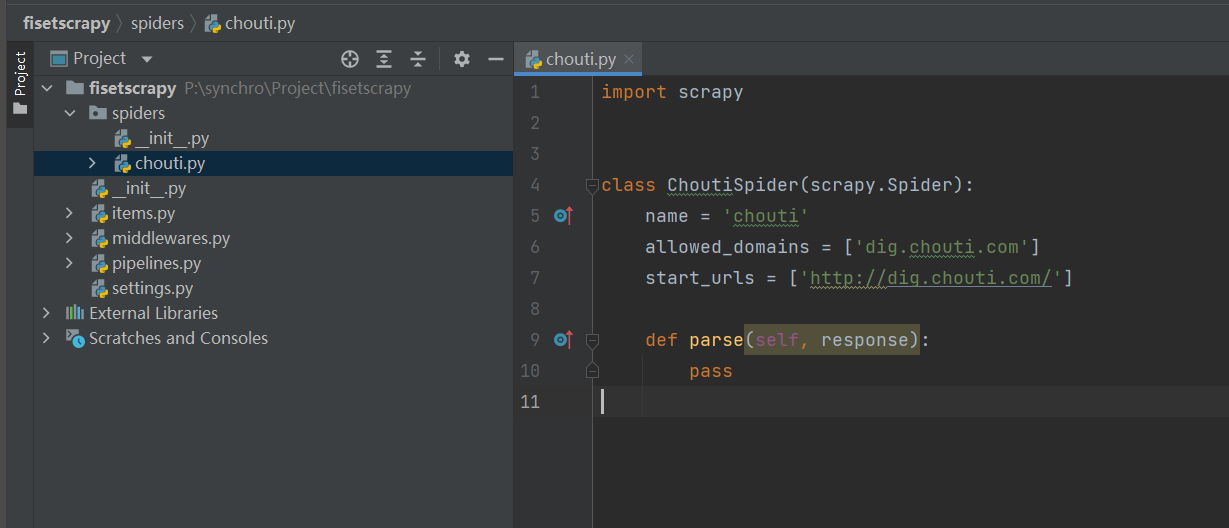
2.3 项目目录介绍
fisetscrapy 项目名
|--fisetscrapy 项目包
|--spiders 爬虫脚本包
|--__init__.py
|--chouti.py 自建爬虫脚本
|--baidu.py 自建爬虫脚本
|--__init__.py
|--items.py 类
|--main.py 执行爬虫脚本文件
|--middlewares.py 中间件(爬虫, 下载中间键)
|--pipelines.py 持久化相关
|--settings.py 配置文件
|--scrapy.cfg 上线配置
2.4 基本使用
爬虫脚本属性说明
allowed_domains 限制配置, 只解析设置的url下的地址, 网页中有其他网站的连接不会去解析.
start_urls 爬取的地址, 返回的页面数据被, parse方法的的response参数接收.
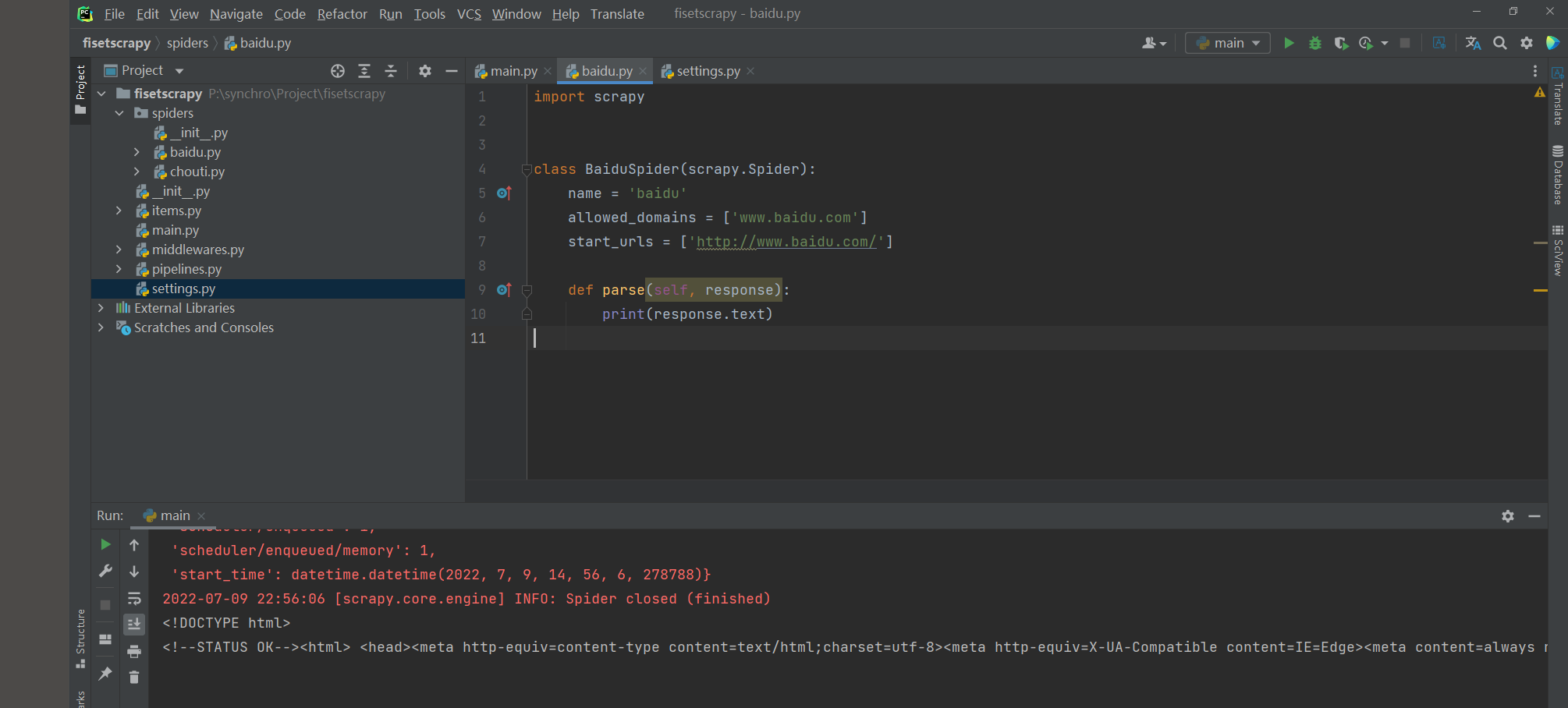
* 1. 修改爬虫脚本代码
import scrapy
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['dig.chouti.com']
start_urls = ['http://dig.chouti.com/']
def parse(self, response):
# 展示获取的网页信息
print(response.text)
* 2. 命令运行代码
带运行日志: scrapy crawl 爬虫程序名
不带运行日志: scrapy crawl 爬虫程序名 --nolog
* 没有运行日志错误就不展示了...
* 3. 右键运行
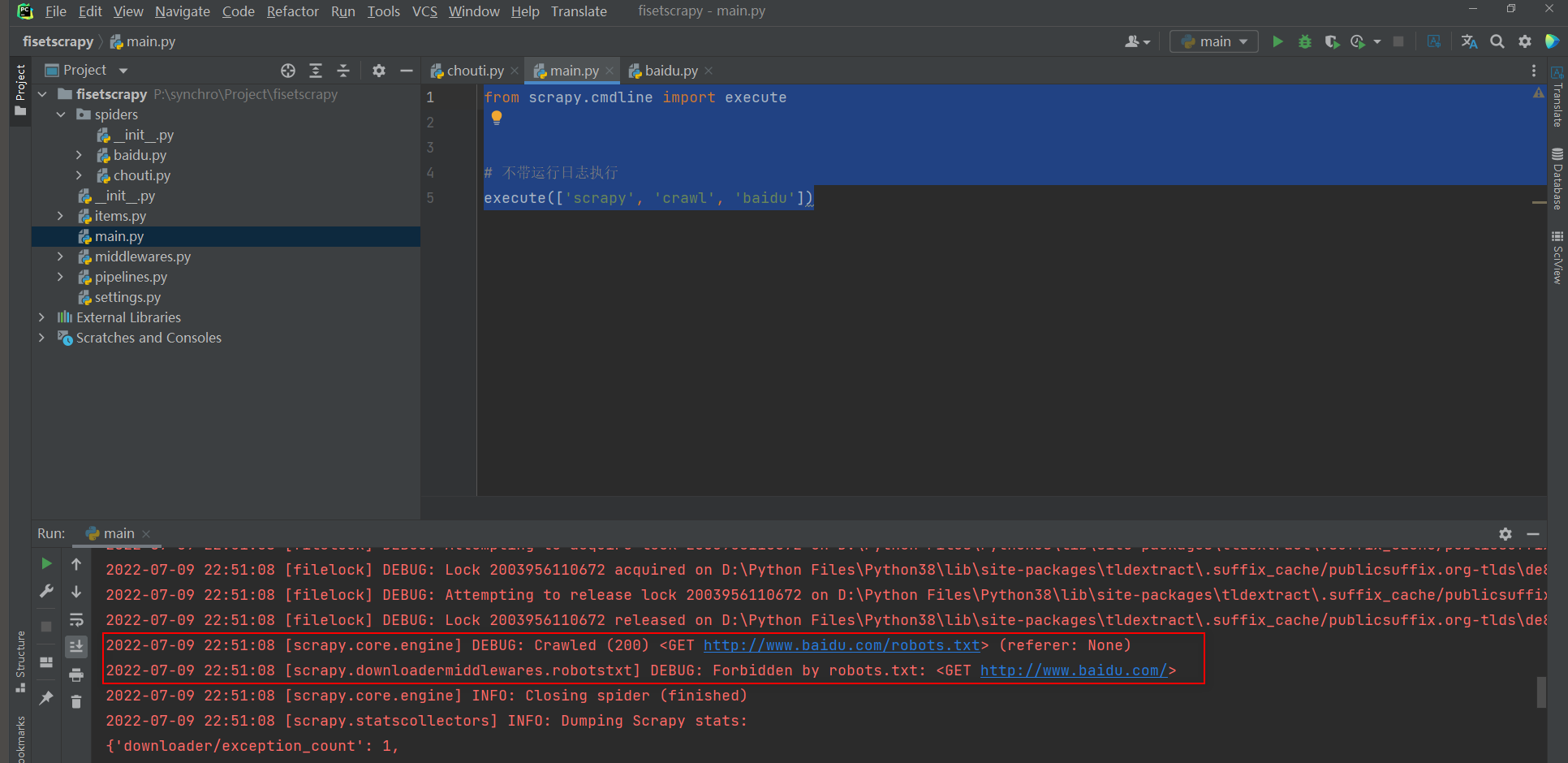
在项目目录下创建一个py文件(例 main.py), 在文件输入以下代码, 右击运行此代码,
from scrapy.cmdline import execute
# execute(['命令', '参数', '运行的爬虫程序', '额外参数'])
# 带运行日志执行
# execute(['scrapy', 'crawl', 'chouti'])
# 不带运行日志执行
execute(['scrapy', 'crawl', 'chouti', '--nolog'])
# 执行多个排着写即可
# execute(['scrapy', 'crawl', 'xxx', '--nolog'])
* 4. 爬取信息默认遵循网站的爬虫协议
from scrapy.cmdline import execute
# 爬取百度网页信息, 不爬虫协议不予许爬取, 执行这个脚本获取不到任何信息
execute(['scrapy', 'crawl', 'baidu'])
* 5. 不遵循爬虫协议, 修改settings配置配置文件.
# settings.py
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
* 6. 再次执行爬虫脚本, 获取到网页信息
边栏推荐
- The cluster of safe mode
- Introduction to using NPM
- ERROR 1819 (HY000) Your password does not satisfy the current policy requirements
- The use of C# control CheckBox
- C# 中的Async 和 Await 的用法详解
- What should I do if selenium is reversed?
- Six Stones Programming: No matter which function you think is useless, people who can use it will not be able to leave, so at least 99%
- Golang - gin - pprof - use and safety
- [Niu Ke brush questions - SQL big factory interview questions] NO3. E-commerce scene (some east mall)
- 阿里三面:MQ 消息丢失、重复、积压问题,怎么解决?
猜你喜欢
Introduction to using NPM

IDEA can't find the Database solution
Architecture Camp | Module 8
![[CPU Design Practice] Simple Pipeline CPU Design](/img/83/e1dfedfe2b2cfe83a34f86e252caa7.jpg)
[CPU Design Practice] Simple Pipeline CPU Design

ERROR 2003 (HY000) Can‘t connect to MySQL server on ‘localhost3306‘ (10061)

Hard disk partition, expand disk C, no reshipment system, not heavy D dish of software full tutorial.

golang-gin-优雅重启
How to quickly split and merge cell data in Excel
PyQt5快速开发与实战 9.7 UI层的自动化测试
VU 非父子组件通信
随机推荐
Usage of += in C#
六石编程学:不论是哪个功能,你觉得再没用,会用的人都离不了,所以至少要做到99%
IDEA can't find the Database solution
IDEA版Postman插件Restful Fast Request,细节到位,功能好用
Ali on three sides: MQ message loss, repetition, backlog problem, how to solve?
Flutter keyboard visibility
SAP message TK 248 solved
八大排序汇总及其稳定性
P5019 [NOIP2018 提高组] 铺设道路
IDEA如何运行web程序
centos7安装mysql5.7
Solution for browser hijacking by hao360
深度剖析 Apache EventMesh 云原生分布式事件驱动架构
golang-gin-pprof-使用以及安全问题
Talk about the message display mechanism on the SAP product UI
selenium被反爬了怎么办?
基于神经网络的多柔性梁耦合结构振动控制
基于模糊预测与扩展卡尔曼滤波的野值剔除方法
JSP response对象简介说明
ASM module in SAP Ecommerce Cloud Spartacus UI and Accelerator UI