当前位置:网站首页>【信息检索导论】第七章搜索系统中的评分计算
【信息检索导论】第七章搜索系统中的评分计算
2022-07-02 06:25:00 【lwgkzl】
1. 总述
本章主要解决以下问题:
- 对于千亿级别的文档,为每一个询问对文档库进行排序是不现实的,如果快速的检索出某个询问最相关的topk个文档呢?
- 除了query与document的相似度之外,对文档进行排序的过程是否还需要其他指标? 如何综合这些指标呢
- 一个完整的信息检索系统需要包括哪些模块?
- 向量空间模型是否支持通配符查询?
2. 快速评分与排序
本章主要介绍一些启发式的方法,用来快速的找到符合与某个询问较为相关的K个文档,找到的文档中并非完全包含最相关topk,但我们会返回与真实topk分数接近的K个文档。
a. 索引去除优化:
只考虑包含询问中多个查询项的文档, 或者只考虑包含词项超过一定idf阈值的文档。
b. 胜者表
对倒排表中的每个词项, 找到与该此项最相关的t个文档, 然后在之后的查询中,对于每个词项只考虑t个打分最高的文档,即对于一个查询, 我们只需要在该查询包含的词项对应的 N* t个文档中选出topk即可,其中N为该查询包含的词项数目。
c. 文档的静态得分
结合胜者表使用, 可以通过文档的静态评分作为每个词项选择前t个文档的依据。 其中文档的静态评分代表文档的质量, 如网站用户对该网站的评价等。如下图所示: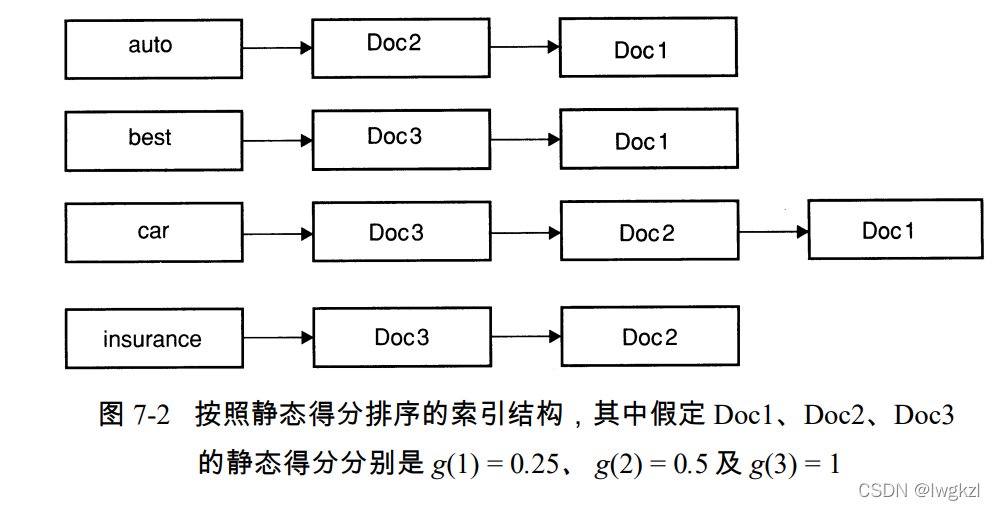
d. 簇剪枝
利用文档向量进行聚类运算, 然后通过选出 ( N ) \sqrt(N) (N)个聚类中心,期望上是每个聚类中会包含 ( N ) \sqrt(N) (N)个文档,其中 N为文档数目。然后选择离query最近的聚类中心作为候选项, 在这 ( N ) \sqrt(N) (N)个文档中选择topk个离query最近的文档。
3. 信息检索系统的组成
a. 层次化索引:
如上图所示, 通过分数划分成不同的层级,检索的时候从上往下检索,直到找到K个候选文档为止。
b. 词项邻近性:
查询中的词项在文档中的距离越近,该文档的评分应该越高。至于如何去评定词项临近的分数, 需要使用机器学习的内容。
c. 评分函数的计算:
同上, 综合为一个文档打分,需要考虑静态分数, query与文档的相似度, 词项临近性等多种因素, 根据应用的不同偏重性, 可以制定手工规则来综合为文档进行打分, 也可以将以上的分数都看做特征,然后将这些特征输入到机器学习模型做打分。
d. 信息检索系统的组成:
在文档端: 索引建立到非精确检索
在用户端: 从拼写纠正到检索, 到通过机器学习算法来对文档进行排序打分。
4. 向量空间模型对各种查询操作的支持
a. 布尔查询
显然向量空间模型可以支持单个词项的布尔查询,但多个词项组合的布尔查询表达式,由向量空间模型这种累加分数的方式不太容易实现。
b. 通配符查询
可以将通配符先进行解析,解析出通配符可能代表的查询词项,然后将所有可能的词项作为候选query去查询, 最后综合所有query的查询结果。 因此向量空间模型可以解决
c. 短语查询:
由于向量空间模型不考虑短语之中各个词项的相对位置,因此向量空间模型不适用于短语查询。
5. 小结
- 对于千亿级别的文档,为每一个询问对文档库进行排序是不现实的,如果快速的检索出某个询问最相关的topk个文档呢?
答: 使用启发式算法,如胜者表,分层索引的方法,找到相对较好的topk个文档。 - 除了query与document的相似度之外,对文档进行排序的过程是否还需要其他指标? 如何综合这些指标呢。
答: 存在很多其他指标,如文档的静态评分, 词项近邻分数等,最后可以通过人工规则或者机器学习的手段综合评分。 - 一个完整的信息检索系统需要包括哪些模块?
答: 见图3.d - 向量空间模型是否支持通配符查询?
答: 支持。
6. 思维导图

边栏推荐
- 離線數倉和bi開發的實踐和思考
- Sqli-labs customs clearance (less1)
- ORACLE 11G利用 ORDS+pljson来实现json_table 效果
- The first quickapp demo
- Explain in detail the process of realizing Chinese text classification by CNN
- ssm人事管理系统
- JS countdown case
- view的绘制机制(三)
- Oracle EBS数据库监控-Zabbix+zabbix-agent2+orabbix
- 使用Matlab实现:弦截法、二分法、CG法,求零点、解方程
猜你喜欢
SSM二手交易网站
在php的开发环境中如何调取WebService?

The boss said: whoever wants to use double to define the amount of goods, just pack up and go

ORACLE EBS中消息队列fnd_msg_pub、fnd_message在PL/SQL中的应用

ORACLE EBS 和 APEX 集成登录及原理分析

Oracle EBS数据库监控-Zabbix+zabbix-agent2+orabbix
使用MAME32K进行联机游戏

Oracle apex Ajax process + dy verification

第一个快应用(quickapp)demo

CSRF attack
随机推荐
php中的二维数组去重
2021-07-19c CAD secondary development creates multiple line segments
sparksql数据倾斜那些事儿
2021-07-05c /cad secondary development create arc (4)
Basic knowledge of software testing
CRP implementation methodology
sqli-labs通关汇总-page2
软件开发模式之敏捷开发(scrum)
php中在二维数组中根据值返回对应的键值
PXC high availability cluster summary
[leetcode question brushing day 35] 1060 Missing element in ordered array, 1901 Find the peak element, 1380 Lucky number in matrix
RMAN增量恢复示例(1)-不带未备份的归档日志
Oracle EBS数据库监控-Zabbix+zabbix-agent2+orabbix
图解Kubernetes中的etcd的访问
sqli-labs通關匯總-page2
JSP intelligent community property management system
Oracle segment advisor, how to deal with row link row migration, reduce high water level
SQLI-LABS通關(less6-less14)
Take you to master the formatter of visual studio code
Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK