当前位置:网站首页>Chapter III principles of MapReduce framework
Chapter III principles of MapReduce framework
2022-07-06 16:36:00 【Can't keep the setting sun】
3.1 MapReduce Calculation model
MapReduce The calculation model is mainly composed of three stages :Map、Shuffle、Reduce.
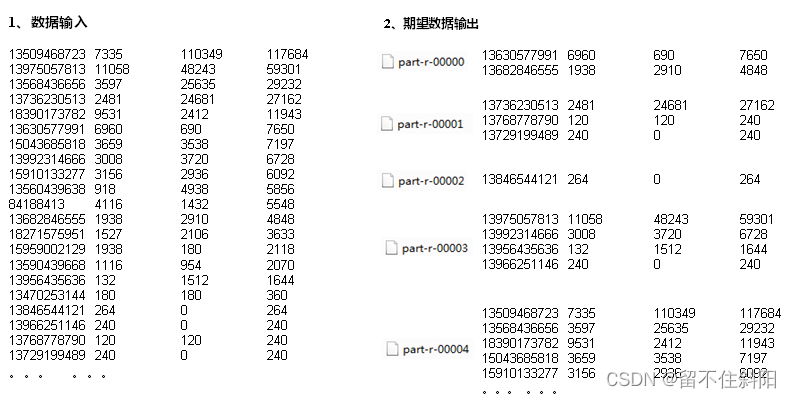
Map Mapping , Responsible for data processing 、 distribution , Convert the original data into key value pairs ;Reduce It's a merger , Will have the same key It's worth it value After processing, a new key value pair is output as the final result . In order to make Reduce It can be processed in parallel Map Result , Must be right Map The output of is sorted and segmented , Then give it to the corresponding Reduce, And this one will Map The output is further collated and handed over to Reduce The process of Shuffle. Whole MR The general process of is as follows .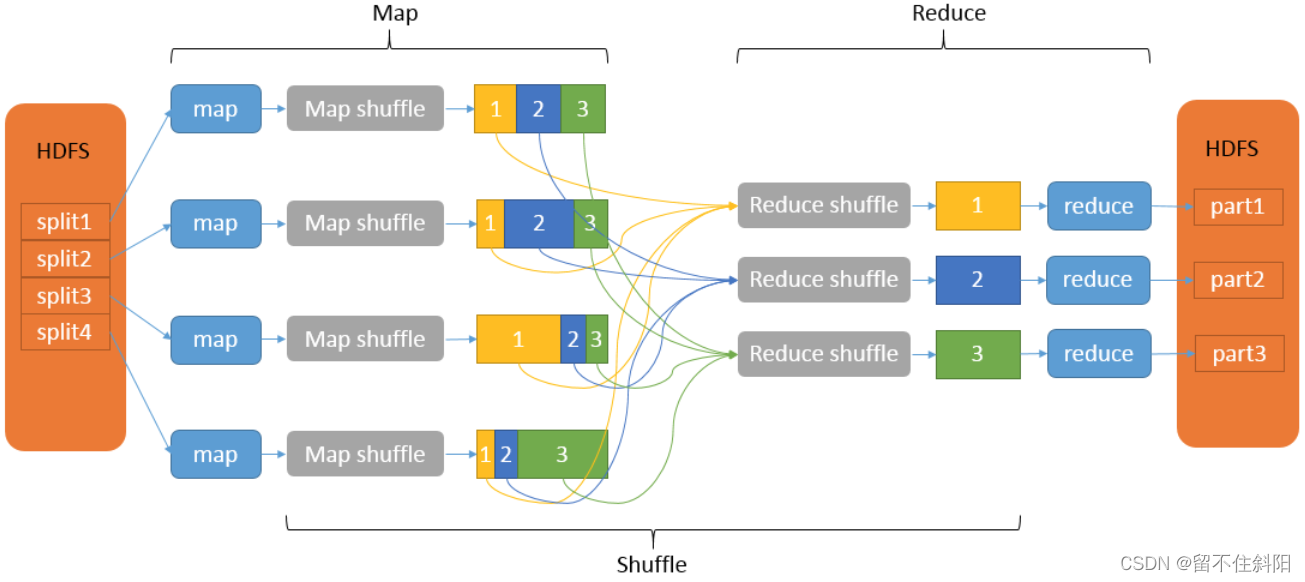
Map and Reduce The operation needs to define the corresponding Mapper Classes and Reducer class , To complete the required simplification 、 Merge operation , and shuffle The system automatically realizes , understand shuffle The specific process can write a more efficient Mapreduce Program .
Shuffle The process is contained in Map and Reduce Both ends , namely Map shuffle and Reduce shuffle
3.2 MapReduce Workflow
1. Flow diagram 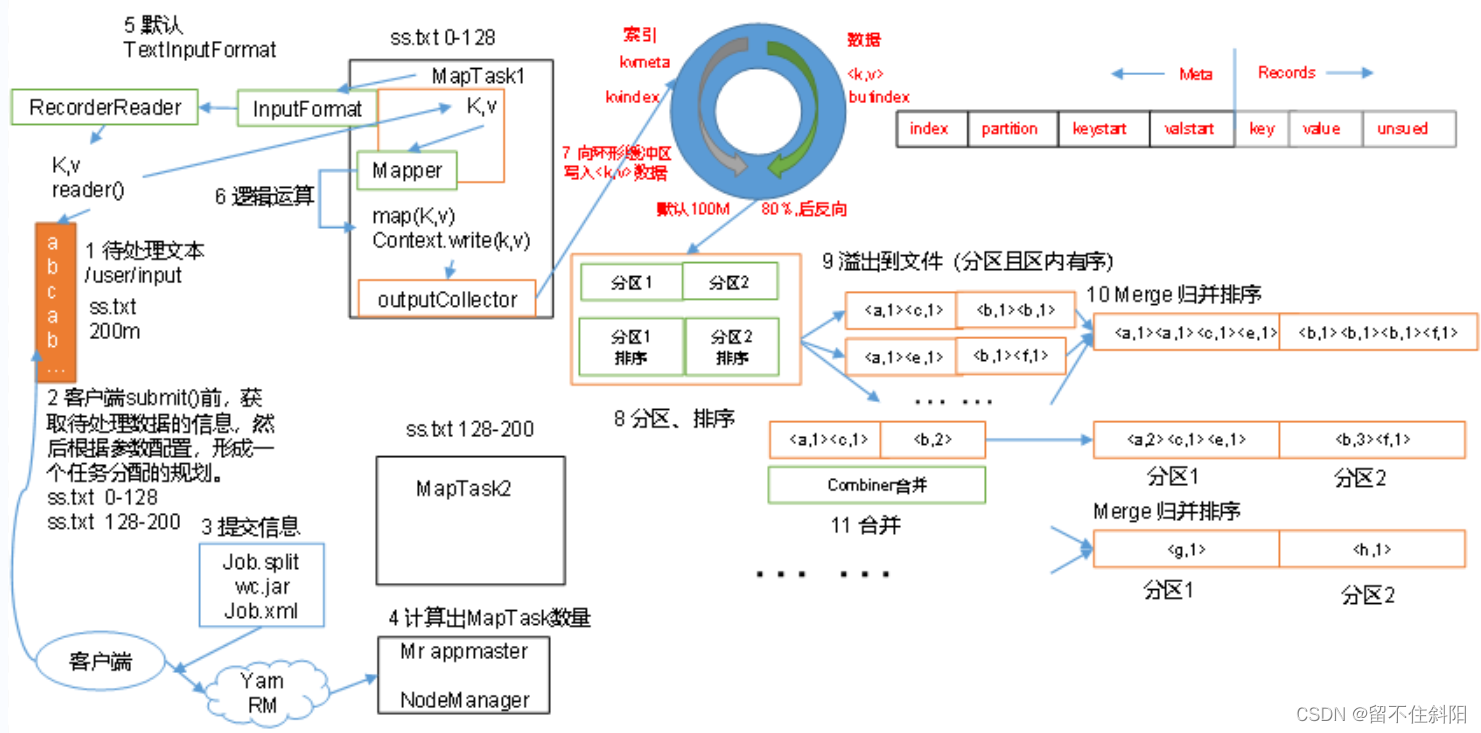
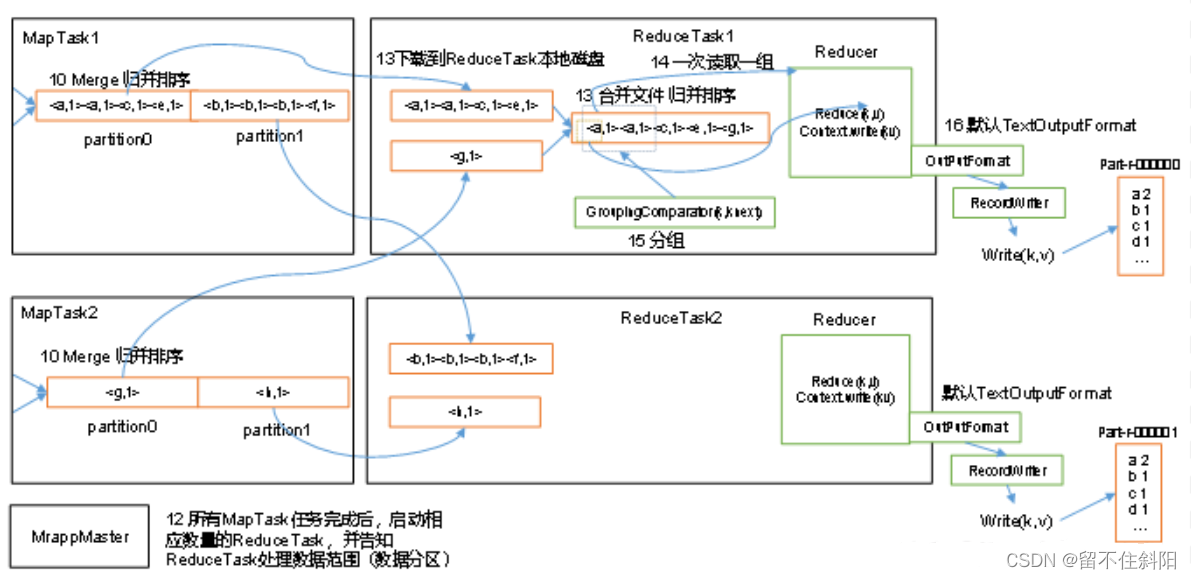
2. Detailed explanation of process
The above process is the whole MapReduce The whole workflow , however Shuffle The process is just from the 7 Step to step 16 End of step , Specifically Shuffle The process is explained in detail , as follows :
(1) MapTask collect map() Method output kv Yes , Put in memory buffer
(2) Overflow local disk file from memory buffer , Multiple files may overflow
(3) Multiple overflow files will be merged into large ones
(4) In the process of overflow and merger , Call the Partitioner Partitioning and targeting key Sort
(5) ReduceTask According to your partition number , Go to each MapTask Take the corresponding result partition data on the machine
(6) ReduceTask Will get to the same partition from different sources MapTask Results file for ,ReduceTask These files will be merged again ( Merge sort )
(7) After merging into large documents ,Shuffle And that's the end of the process , Back in ReduceTask Logical operation process of ( Take a key value pair from a file Group, Call user-defined reduce() Method )
3. Be careful
Shuffle Buffer size in affects MapReduce Program execution efficiency , In principle , Larger buffer , disk io Less times , The faster the execution .
The size of the buffer can be adjusted by parameters , Parameters :mapreduce.task.io.sort.mb Default 100M.
4. Source code parsing process 
3.3 MapTask Working mechanism
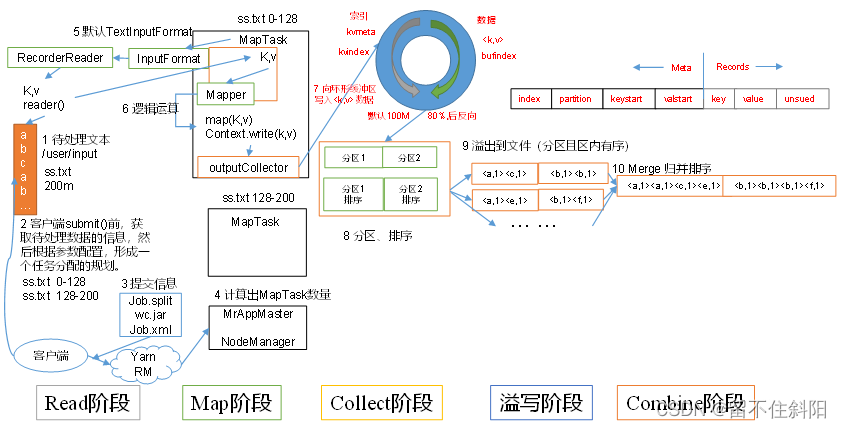
(1) Read Stage :MapTask Written by users RecordReader, From input InputSplit We can analyze them one by one key/value.
(2) Map Stage : This stage is mainly to analyze the key/value To be written by users map() Function processing , And produce a series of new key/value.
(3) Collect Collection phase : Written by users map() Function , When the data processing is completed , Generally called OutputCollector.collect() Output results . Inside the function , It will generate key/value Partition ( call Partitioner), And write to a ring memory buffer .
(4) Spill Stage : That is, over writing , When the ring buffer is full ,MapReduce Write data to local disk , Generate a temporary file . Before writing data to local disk , First, sort the data ( Quick sort ), And merge the data if necessary 、 Compression and other operations .
Overflow stage details :
( One ) step 1: utilize Fast sorting algorithm Sort the data in the ring buffer , First according to Partition Number to sort , And then according to key Sort . After sorting , Data is aggregated in partitions , And all data in the same partition are in accordance with key Orderly .
( Two ) step 2: Write the data in each partition to the temporary file according to the partition number from small to large output/spillN.out(N Indicates the current number of overflows ) in . If the user has set Combiner, Before writing the file , Perform a merge operation on the data in each partition .
( 3、 ... and ) step 3: Write meta information of partition data to memory index data structure SpillRecord in , The offset of the meta information of each partition included in the temporary file 、 Data size before and after compression . If the current memory index size exceeds 1MB, Then write the memory index to the file output/spillN.out.index in .
(5) Combine Stage : When all data processing is completed ,MapTask Merge all temporary files once , To ensure that only one data file will be generated in the end , And save to file output/file.out in , At the same time, the corresponding index file is generated output/file.out.index.
During file consolidation ,MapTask Merge by partition . For a partition , It's going to use multiple rounds of recursive merging . Every round of consolidation mapreduce.task.io.sort.factor( Default 10) File , And add the generated files back to the list to be merged , After sorting files ( Merge sort ), Repeat the above process , Until you finally get a big file .
Let each MapTask Finally, only one data file is generated , It can avoid the overhead of random reading caused by opening a large number of files at the same time and reading a large number of small files at the same time .
Map End related properties 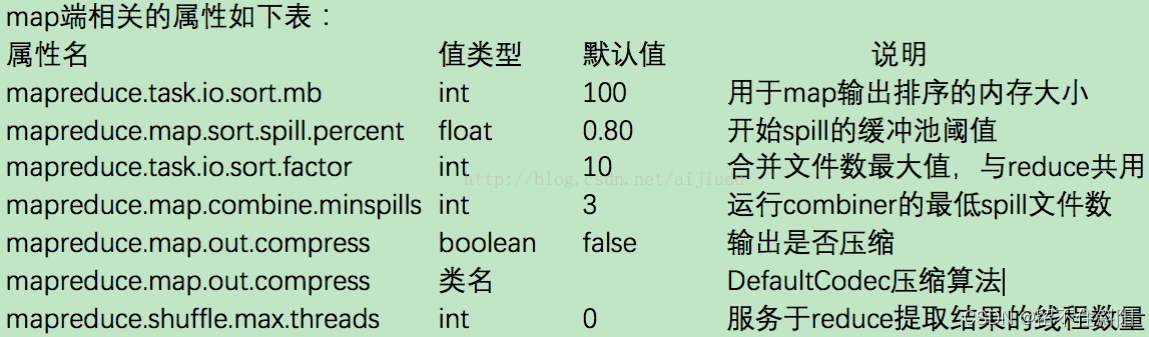
mapreduce.tasktracker.http.threads And mapreduce.reduce.shuffle.parallelcopies difference
mapreduce.tasktracker.http.threads Represent each TaskTracker Can provide 40( Default ) individual http Thread to serve reducer( hypothesis reducer There are 50 individual ,MapTask The output file may contain 50 Partition data , So there may be 50 individual reducer At the same time, pull the data , This parameter limits the... Of pulling data reducer Number )
mapreduce.reduce.shuffle.parallelcopies It means a reducer Can simultaneously from 5( Default ) individual map End access data
3.4 Map Shuffle
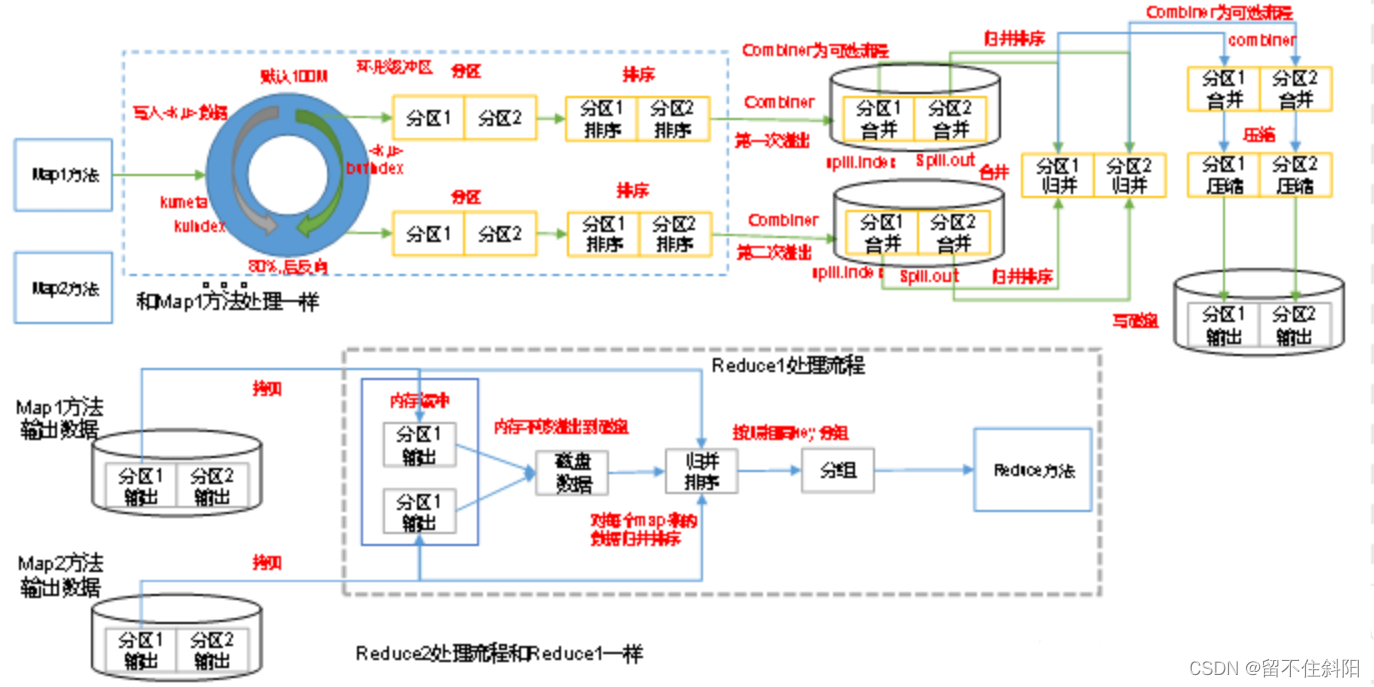
stay Map Terminal shuffle The process is right Map Partition the results of 、 Sort 、 Division , Then it will belong to the same division ( Partition ) The output of is merged and written on disk , Finally, you get a file with orderly partitions . Partition order means map The output key value pairs are arranged by partition , Have the same partition Key value pairs of values are stored together , The key value pairs in each partition are pressed key Values are arranged in ascending order ( Default ), The process is as follows 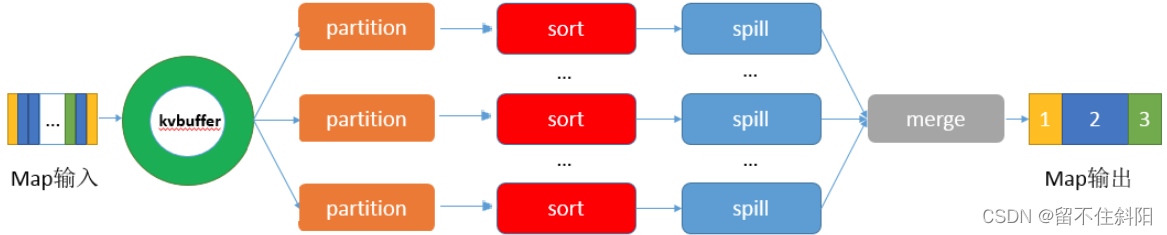
3.4.1 Collector Ring buffer
3.4.1.1. Ring buffer function
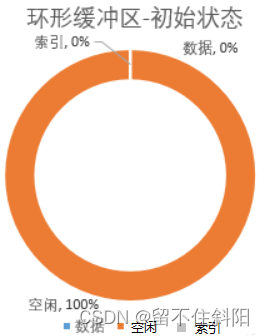
The ring buffer is divided into three pieces , The free zone 、 Data area 、 Index area . The initial position is called “ The equator ”, It's the position of the white line on the ring . In the initial state , Both data and index are 0, All spaces are idle .
mapreduce.task.io.sort.mb, Default 100M, It can be set slightly larger , But not too big , Because of every spilt Just 128M.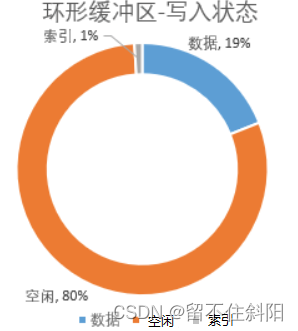
When the ring buffer is written , There's a detail : Data is written from the right side of the equator , Indexes ( Every time you apply 4kb) It starts from the left side of the equator . This design is very interesting , Such two documents are different , They don't interfere with each other .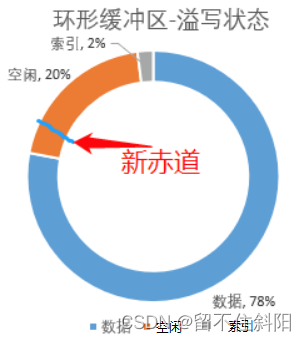
When the data and index occupy space mapreduce.map.sort.spill.percent When setting the proportion of parameters ( Default 80%, This is the tuning parameter ), There will be two actions :
(1) Sort the written data in place , And put the sorted data and index spill Go to disk ;
(2) In idle 20% In the region , Recalculate a new Equator , Then write data on the right side of the new Equator , Write index on the left ;
(3) When 20% It's full. , But last time 80% Before the data is written to the disk , The program will panding once , etc. 80% When the space is free, continue to write .
3.4.1.2. Ring buffer structure
Map The output result of is from collector To deal with the , Every Map The task constantly outputs key value pairs to a ring data structure constructed in memory . Ring data structure is used to use memory space more effectively , Put as much data as possible in memory .
Ring buffer , This data structure is actually a byte array byte[], It's called Kvbuffer, But it's not just data , And put some index data , There is an area for index data Kvmeta Another name for .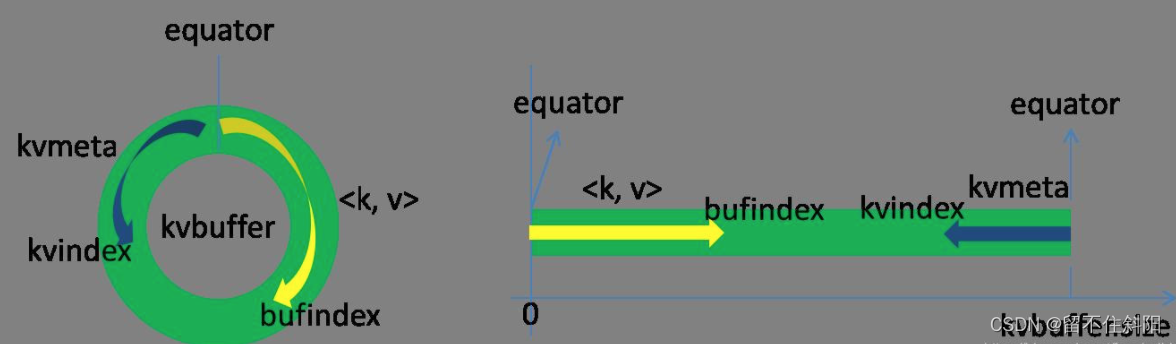
The data area and index data area are in Kvbuffer Middle is two adjacent areas that do not overlap , Use a dividing point to divide the two , The demarcation point is not eternal , But every time Spill It'll be updated later . The initial demarcation point is 0, The storage direction of data is upward growth , The storage direction of index data is downward growth .
Kvbuffer The pointer to bufindex( That is, the storage direction of data ) It's growing up all the time , such as bufindex The initial value is 0, One Int Type key After you've written ,bufindex Grow to 4,
One Int Type value After you've written ,bufindex Grow to 8.(int Type of data possession 4 Bytes )
The index is kvbuffer Index of key value pairs in , It's a quadruple , Include :value Starting position 、key Starting position 、partition value 、value The length of , Take up four Int length ,Kvmeta The pointer Kvindex Four jumps down at a time “ lattice ”, And then fill up the data of four tuples one by one .
such as Kvindex The initial position is -4( byte ), When the first key value pair is written ,(Kvindex+0) To store in value Starting position 、(Kvindex+1) To store in key Starting position 、(Kvindex+2) To store in partition Value 、(Kvindex+3) To store in value The length of , then Kvindex Jump to the -8 Location , After the second key value pair and index are written ,Kvindex Jump to the -12 Location .
About Spill Trigger conditions , That is to say Kvbuffer To what extent do you want to start Spill. If you put Kvbuffer Don't start until you have nothing left Spill, that Map The task requires waiting Spill You cannot continue writing data until you have made space available ; If Kvbuffer Just to a certain extent , such as 80% It started when I was young Spill, That's in Spill At the same time ,Map The task can continue to write data , If Spill Fast enough ,Map There may be no need to worry about free space . Balance the two interests and choose the greater one , Generally choose the latter .Spill The threshold of can pass mapreduce.map.sort.spill.percent, The default is 0.8.
Spill This important process is made up of Spill Thread commitment ,Spill The thread from Map Task received “ command ” After that, I began to work formally , The work done is called SortAndSpill, It's not just Spill, stay Spill There was a controversial Sort.
3.4.2 Partition
about map Each key value pair output , The system will give a partition,partition The default value is calculated key Of hash The value is right Reduce task Take the mold to obtain . If a key value is right partition The value is 0, It means that this key value pair will be given to the first Reducer Handle .
3.4.3 Sort
When Spill After triggering ,SortAndSpill The first Kvbuffer According to the data in partition Values and key Sort two keywords in ascending order ( Quick sort ), Moving only index data , The ranking result is Kvmeta The data in the is in accordance with partition Gather together in units of , same partition In accordance with key Ascending .
3.4.4 Spill
Spill Thread for this Spill Procedure to create a disk file : From all the local directories, rotate to find the directory that can store such a large space , After finding it, create a file similar to “spill12.out” The file of .Spill Threads are sequenced according to Kvmeta One by one partition Write the data to this file , One partition Write the corresponding data in sequence after writing partition, Until all the partition End of traversal . One partition The corresponding data in the file is also called segment (segment). In this process, if the user configures combiner class , Then I will call before writing combineAndSpill(), After further merging the results, write .Combiner Will optimize MapReduce The middle result of , So it's used many times throughout the model .Combiner The output of is Reducer The input of ,Combiner Never change the final calculation .
be-all partition The corresponding data is put in this file , Although it is stored in sequence , But how do you know something directly partition The starting location in this file ? The powerful index is coming out again . There is a triplet that records something partition The index of the corresponding data in this file : The starting position 、 Raw data length 、 Length of compressed data , One partition Corresponds to a triple . Then the index information is stored in memory , If you can't put it in memory , The subsequent index information needs to be written to the disk file : From all the local directories, rotate to find the directory that can store such a large space , After finding it, create a file similar to “spill12.out.index” The file of , The index data is not only stored in the file , Also stores the crc32 The verification data of .spill12.out.index Not necessarily on disk , If memory ( Default 1M Space ) If you can fit it in the memory , Even if... Is created on disk , and spill12.out The files are not necessarily in the same directory . every time Spill The process will generate at least one out file , Sometimes it also generates index file ,Spill The number of times is also stamped in the file name . The corresponding relationship between the index file and the data file is shown in the following figure :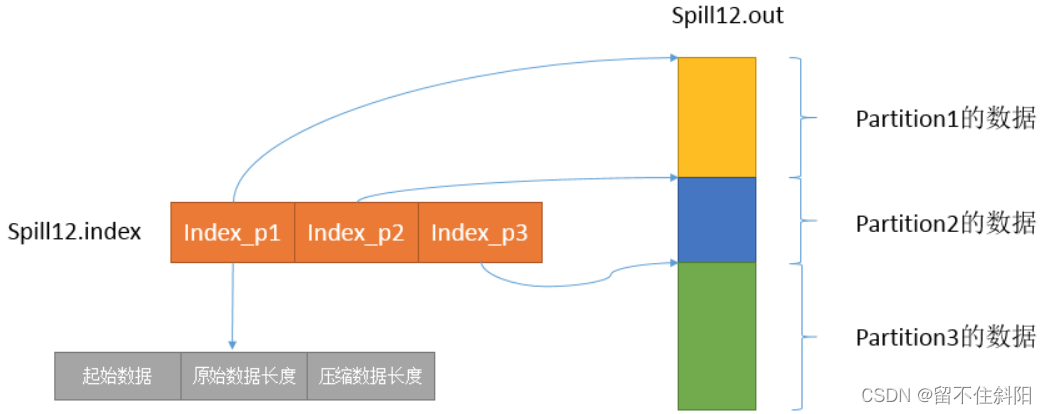
stay Spill Threads are in full swing SortAndSpill While working ,Map The task will not be stopped , Instead, they are outputting data without any history .Map Or write the data to kvbuffer in , That's the question : Just keep your head down and follow bufindex The pointer grows upwards ,kvmeta Just follow Kvindex Grow down , Keep the starting position of the pointer unchanged and continue running , Or find another way ? If you keep the starting position of the pointer unchanged , Soon bufindex and Kvindex We met , It is troublesome to restart after meeting or move the memory , Not an option .Map take kvbuffer The middle of the remaining space in , Set this position as the new dividing point ,bufindex The pointer moves to this dividing point ,Kvindex Moving to this dividing point -16 Location , Then the two can place data in harmony according to their own established trajectory , When Spill complete , After the space is vacated , You don't need to make any changes to move on .
Map The task always writes the output data to the disk , Even if the amount of output data is very small, it can all be installed in the memory , In the end, the data will be brushed onto the disk .
3.4.5 Merge
Map If the task outputs a large amount of data , It may be done several times Spill,out Document and Index Files can produce a lot of , Distributed on different disks . Finally, these files are merged merge The process comes on stage .
Merge How does the process know what happens Spill Where are the files ? Scan from all local directories to generate Spill file , Then store the path in an array .Merge How do you know the process Spill The index information of ? It is also scanned from all local directories Index file , Then store the index information in a list . Before Spill Why not store this information directly in memory during the process , Why do you need to do more scanning ? especially Spill Index data of , Before, when the memory exceeded the limit, the data was written to the disk , Now I have to read these data from the disk , Put it into more memory . The reason why it is unnecessary , Because at this time kvbuffer This large memory user is no longer used , Recyclable , So there is memory space for these data .( For local tyrants with large memory space , Use memory to save these two io The steps are worth considering .)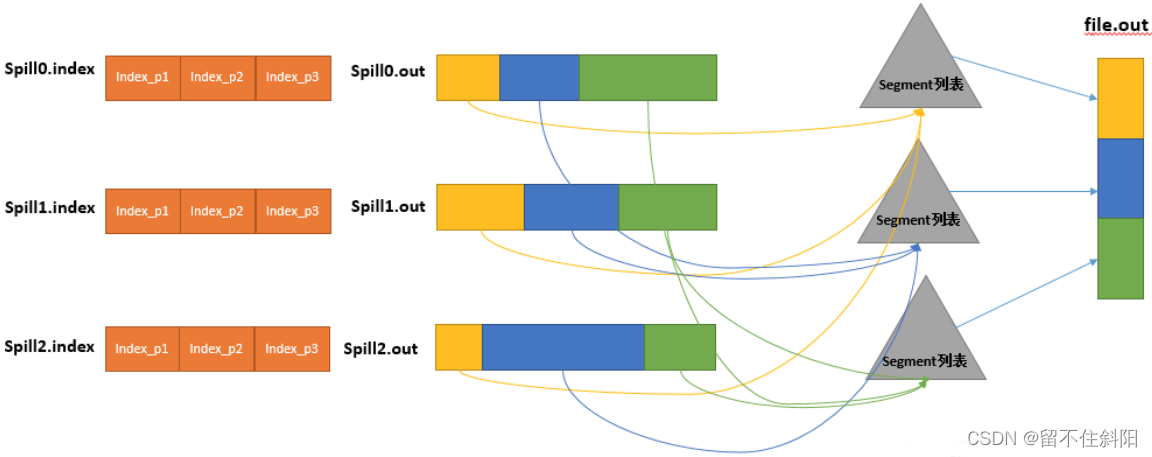
And then to merge The process creates a process called file.out And a file called file.out.Index File to store the final output and index , One partition One partition For merge output . For a partition Come on , Query this... From the index list partition All corresponding index information , Each corresponding segment is inserted into the segment list . That's it partition Corresponding to a segment list , Record all Spill The corresponding one in the file partition The file name of that data 、 The starting position 、 Length, etc. .
And then to this partition All the corresponding segment A merger , The goal is to merge into one segment. When this partition There are many segment when , Will merge in batches : First from segment Take the first batch out of the list , With key Put keywords in the smallest heap , Then take the smallest output from the smallest heap each time and put it into a temporary file , In this way, this batch of segments is merged into a temporary segment , Add it back to segment In the list ; Again from segment Take the second batch out of the list, merge and output it to a temporary segment, Add it to the list ; It's going back and forth , Until the rest of the paragraph is a batch , Output to the final file . The final index data is still output to Index In file .
3.5 Reduce Shuffle
3.5.1 ReduceTask Working mechanism
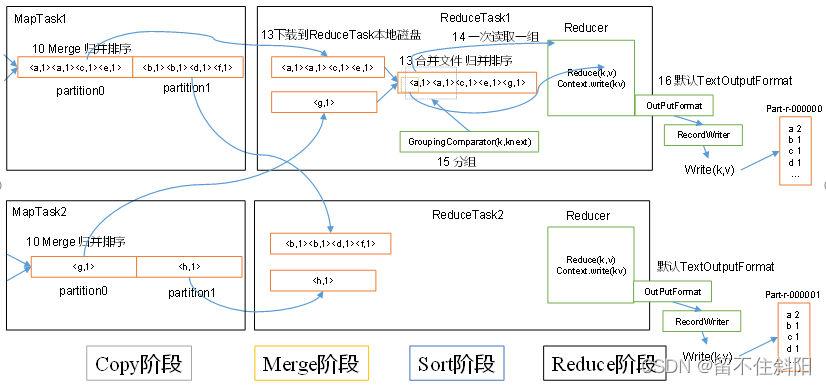
(1) Copy Stage
because Job Every one of map Will be based on reduce(n) Number divides the data into n individual partition, therefore map The intermediate result of may contain each reduce Part of the data that needs to be processed . therefore , In order to optimize the reduce Execution time of ,hadoop etc. Job One of the first map After the end , be-all reduce Start trying to finish map Download the reduce Corresponding partition Part of the data , therefore map and reduce It's a cross , In fact, that is shuffle.Reduce The task passed HTTP To each Map Task drag ( download ) The data it needs ( Network transmission ),Reducer How to know which machines to go to get data ? once map After the task is completed , The father will be notified by regular heartbeat TaskTracker Status has been updated ,TaskTracker Further inform JobTracker( These notifications are made in the heartbeat mechanism ).reduce A thread of will periodically send a message to JobTracker inquiry , Until all the data is extracted , The data is reduce After taking it away ,map The machine will not delete the data immediately , This is to prevent reduce The task failed and needs to be redone . therefore map The output data is deleted after the whole job is completed .
reduce Process startup data copy Threads (Fetcher), adopt HTTP Mode request map task Where TaskTracker obtain map task Output file for . because map There are usually many , So to one reduce Come on , Downloading can also be done in parallel from multiple map download , How many are there at the same time Mapper Download data ? This parallelism can be achieved by mapreduce.reduce.shuffle.parallelcopies(default5) adjustment . By default , Every Reducer There will only be 5 individual map The end parallel download thread is from map Next data , If a period of time Job Accomplished map Yes 100 One or more , that reduce At most, you can only download it at the same time 5 individual map The data of , So this parameter is more suitable map Many cases with relatively fast completion are reduced greatly , advantageous to reduce Get your own data faster . stay Reducer With good memory and network , This parameter can be increased ;
reduce Each download thread of is downloading a map Data time , Maybe because of that map The machine where the intermediate result is located has an error , Or the intermediate result file is missing , Or the network is broken instantly , such reduce The download of may fail , therefore reduce The download thread of will not wait endlessly , After a certain time, the download still fails , Then the download thread will give up this download , And then try to download it from another place ( Because this time map May run again ).reduce The maximum download time of the download thread can be through mapreduce.reduce.shuffle.read.timeout(default180000 millisecond ) Adjusted . If the network itself in the cluster environment is the bottleneck , Then users can avoid by increasing this parameter reduce The download thread is misjudged as failed . Generally, this parameter will be increased , This is the best practice of enterprise level .
(2) Merge Sort Stage
there merge and map Terminal merge It's like , Only the buffer is different map End copy The values come from .Copy The data will be put into the memory buffer first , Then when the memory buffer usage reaches a certain level spill disk . The buffer size here is larger than map The end is more flexible , It's based on JVM Of heap size Set up . This memory size control is not like map You can also go through mapreduce.map.sort.spill.percent To set , But through another parameter mapreduce.reduce.shuffle.input.buffer.percent(default 0.7f The source code is dead ) To set up , This parameter is actually a percentage , namely reduce Of shuffle Stage memory buffer , The maximum usage is :0.7 × maxHeap of reduce task.JVM Of heapsize Of 70%. Memory to disk merge The start threshold of can pass mapreduce.reduce.shuffle.merge.percent(default 0.66) To configure . in other words , If it's time to reduce task Maximum heap Usage quantity ( Usually by mapreduce.admin.reduce.child.java.opts To set up , For example, set to -Xmx1024m) A certain proportion is used to cache data . By default ,reduce Will use its heap size Of 70% To cache data in memory . hypothesis mapreduce.reduce.shuffle.input.buffer.percent by 0.7,reduce task Of max heapsize by 1G, Then the memory used for downloading data cache is about 700MB about . this 700M Of memory , Follow map The same , You don't have to wait until it's full to brush the disk , But when this 700M Has been used to a certain extent ( Usually a percentage ), Will start to brush the disk ( Before brushing the disk, I will do sort merge). The threshold of this limit can also be determined by parameters mapreduce.reduce.shuffle.merge.percent(default 0.66) To set . And map The end is similar to , This is also the process of over writing , In this process, if Combiner, It will also be activated , Then many overflow files are generated on the disk . such merge The way it works all the time , Until there is no map The end of the data , Then start disk to disk merge How to generate the final file ,merge Will merge and sort . commonly Reduce It's one side copy On one side sort, namely copy and sort The two stages overlap rather than completely separate . Final Reduce shuffle The process outputs an overall ordered block of data .
merge There are three forms
(1) Memory to memory (memToMemMerger)
Hadoop It defines one MemToMem Merge , This kind of merge will be in memory map Output merge , Then write to memory . This merge is closed by default , Can pass mapreduce.reduce.merge.memtomem.enabled(default:false) open , When map The output file reaches mapreduce.reduce.merge.memtomem.threshold when , Trigger this merge .
(2) In the memory Merge(inMemoryMerger)/ Memory to disk
When the buffer data reaches the configured threshold , These data are merged in memory 、 Write to machine disk . The threshold is 2 Type of configuration :
Configure memory ratio : Mentioned earlier reduce JVM Part of the heap memory is used to store data from map Output of task , On this basis, configure a ratio to start merging data . Assumed for storage map The output memory is 500M,mapreduce.reduce.shuffle.merge.percent Configure to 0.66, When the data in memory reaches 330M When , Will trigger merge write .
To configure map Output quantity : adopt
mapreduce.reduce.merge.inmem.thresholdTo configure . In the process of merging , It will sort the merged files globally . If the job is configured Combiner, Will run combine function , Reduce the amount of data written to disk .
(3) On disk Merge(onDiskMerger)
stay copy In the process of continuously writing the data to the disk , A background thread will merge these files into larger 、 Orderly file . If map The output result of is compressed , In the process of consolidation , You need to decompress it in memory before merging . The merger here is only to reduce the workload of the final merger , That is, they are still copying map When the output , Start a part of the merger . The merging process will also perform global sorting ( Merge sort ).
In the final disk Merge, When all map After the output is copied , All the data is finally merged into a whole orderly file , As reduce Task input . The merger process is carried out round by round , The final round of consolidation results are directly pushed to reduce As input , Save a round trip of disk operation . Last ( all map The output is copied to reduce after ) To merge map The output may come from files written to disk after merging , It may also come to the memory buffer , Write to memory at the end map The output may not reach the threshold to trigger merging , So it's still in memory .
Each round of consolidation does not necessarily consolidate the average number of files , The guiding principle is to minimize the amount of data written to disk during the entire consolidation process , In order to achieve this goal , You need to merge as much data as possible in the final round of consolidation , Because the last round of data is directly used as reduce The input of , No need to write to disk and read . Therefore, the number of files in the final round of consolidation is maximized , That is, the value of the merge factor , adopt mapreduce.task.io.sort.factor(default:10) To configure the .
(3) Reduce Stage
When reducer Will all map Correspond to yourself partition After the data download of , Will begin to really reduce The calculation phase . because reduce It must also consume memory when calculating , While reading reduce When data is needed , Memory is also needed as buffer,reduce What percentage of memory is needed as reducer Read already sort Good data buffer size ?? By default 0, in other words , By default ,reduce It's all about reading and processing data from the disk . It can be used mapreduce.reduce.input.buffer.percent(default 0.0)( Source code MergeManagerImpl.java:674 That's ok ) To set up reduce The cache of . If this parameter is greater than 0, Then a certain amount of data will be cached in memory and sent to reduce, When reduce Computing logic consumes very little memory , A portion of the memory can be used to cache data , It can improve the speed of calculation . So by default, data is read from disk , If the memory is big enough , Be sure to set this parameter so that reduce Read data directly from the cache , It's a little Spark Cache The feeling of ;
Reduce Stage , The frame is for each of the grouped input data <key, (list of values)> Call once on reduce(WritableComparable,Iterator, OutputCollector, Reporter) Method .Reduce The output of the task is usually through the call OutputCollector.collect(WritableComparable,Writable) Write to the file system .Reducer The output of is not sorted .
Reduce End related properties 
3.5.2 Set up ReduceTask Parallelism ( Number )
ReduceTask The degree of parallelism also affects the whole Job Execution concurrency and efficiency of , But with MapTask The concurrency number of is determined by the number of slices ,ReduceTask The quantity can be set directly and manually
// The default value is 1, Manually set to 4
job.setNumReduceTasks(4);
1. experiment : test ReduceTask More or less appropriate
(1) Experimental environment :1 individual Master node ,16 individual Slave node :CPU 8GHZ, Memory 2G
(2) The experimental conclusion :
change ReduceTask ( The amount of data is 1GB)
MapTask =16
| ReduceTask | 1 | 5 | 10 | 15 | 16 | 20 | 25 | 30 | 45 | 60 |
|---|---|---|---|---|---|---|---|---|---|---|
| Total time | 892 | 146 | 110 | 92 | 88 | 100 | 128 | 101 | 145 | 104 |
2. matters needing attention
(1) ReduceTask=0, It means that there is no Reduce Stage , The number of output files and Map The number is the same ;
(2) ReduceTask The default value is 1, So the number of output files is 1 individual ;
(3) If the data is not evenly distributed , It could be in Reduce Phase produces data skew ;
(4) ReduceTask Quantity is not set arbitrarily , Also consider the business logic requirements , In some cases , Global summary results need to be calculated , There is only one 1 individual ReduceTask;
(5) Exactly how many ReduceTask, It depends on the performance of the cluster ;
(6) If the number of partitions is not 1, however ReduceTask by 1, Execute partition process or not . The answer is : Do not perform partition process . because MapTask Source code , The premise of partition execution is to judge first ReduceNum Whether the number is greater than 1, No more than 1 Definitely not .
3.5.3 mapreduce in partition Quantity and reduce task Quantity affects the result
(1) situation 1:Partition The number of 1,reduce The number of 3.
Set up reduce The number of 3
Job.setNumReduceTasks(3);
Set up partition The number of 1, The return value is 0
public class MyPartitioner extends HashPartitioner<MyKey, DoubleWritable> {
// The shorter the execution time, the better
public int getPartition(MyKey key, DoubleWritable value, int numReduceTasks){
// return (key.getYear()-1949)%numReduceTasks;
return 0;
}
}
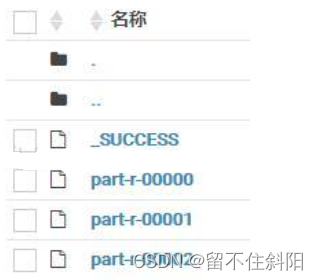
Results output 3 File , But only part-r-00000 There are content , The other two are 0 byte .
(2) situation 2:Partition The number of 1, Return value 5,reduce The number of 3.
Set up reduce The number of 3
Job.setNumReduceTasks(3);
Set up partition The number of 1, The return value is 5
public class MyPartitioner extends HashPartitioner<MyKey, DoubleWritable> {
// The shorter the execution time, the better
public int getPartition(MyKey key, DoubleWritable value, int numReduceTasks){
// return (key.getYear()-1949)%numReduceTasks;
return 5;
}
}
Results output 3 File , All for 0 byte .
(3) situation 3:Partition The number of 1, Return value 1,reduce The number of 3.
The result is output 3 File , But only part-r-00001 Valuable .
(4) situation 4:Partition The number of 3, Return value 0、1、2,reduce The number of 2.
If 1<ReduceTask The number of <partition Count , There is a part of partition data without place , Meeting Exception; If ReduceTask The number of =1, It doesn't matter MapTask How many partition files are output by the end , It's all up to this one ReduceTask, In the end, only one result file will be generated part-r-00000
summary : The number of generated files is determined by reduce Quantity determination , The file to which the value is output is determined by partition The return value determines , The correctness of the output value is determined by partition Quantity and return value determine . Generally speaking, how many partition How many reduce.
3.6 InputFormat data input
3.6.1 Slicing and MapTask Parallelism determination mechanism
1. Question elicitation
MapTask Decision of parallelism of Map Stage task processing concurrency , And then affect the whole Job Processing speed of .
reflection :1G The data of , start-up 8 individual MapTask, It can improve the concurrent processing ability of cluster . that 1K The data of , And start 8 individual MapTask, Will cluster performance be improved ?MapTask Is the more parallel tasks the better ? What factors affect MapTask Parallelism ?
2.MapTask Parallelism determination mechanism
Data blocks :Block yes HDFS Physically, divide the data into pieces .
Data slicing : Data slicing is just a logical way of slicing input , It does not slice the disk for storage .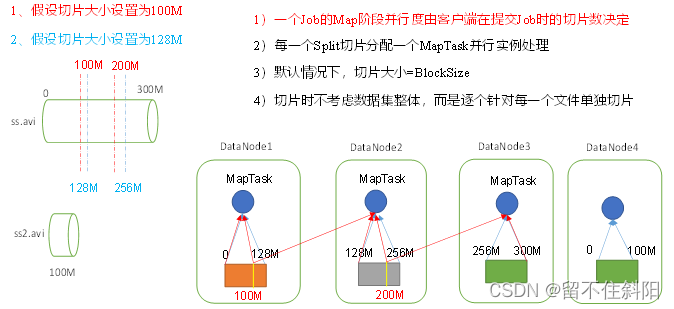
3.6.2 Job Submit process source code and slice source code details
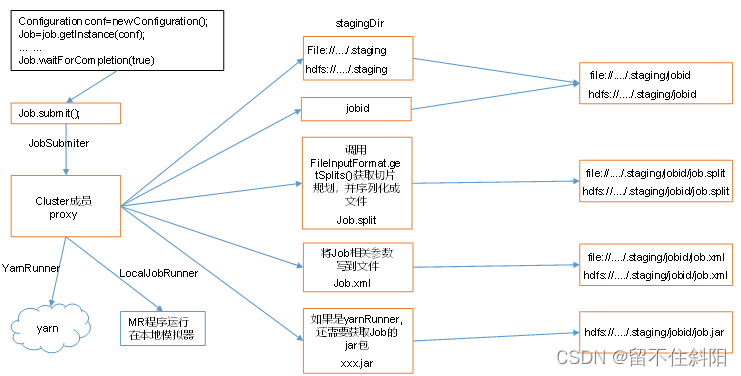
1.Job Detailed source code of submission process
waitForCompletion()
submit();
// 1 Establishing a connection
connect();
// 1) Create submission Job Agent for
new Cluster(getConfiguration());
// (1) Local judgment yarn Or remote
initialize(jobTrackAddr, conf);
// 2 Submit job
submitter.submitJobInternal(Job.this, cluster)
// 1) Create a Stag route
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2) obtain jobid, And create Job route
JobID jobId = submitClient.getNewJobID();
// 3) Copy jar Packet to cluster
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4) Computed slice , Generate slice plan file
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5) towards Stag Path write XML The configuration file
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6) Submit Job, Return to submission status
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
2.FileInputFormat Slice source code analysis (input.getSplits(job))
(1) The program first finds the directory of data storage ;
(2) Start traversal processing ( Planning slices ) Every file in the directory ;
(3) Traverse the first file ss.txt;
a. Get file size fs.sizeOf(ss.txt)
b. Calculate slice size
computeSplitSize(Math.max(minSize, Math.min(maxSize,blocksize)))=blocksize=128M
c. By default , Slice size =blocksize
d. Start slicing , Form the first slice :ss.txt-0:128M, The second slice ss.txt-128M:256M, Third slice ss.txt-256M:300M ( At each slice , We should judge whether the rest of the cut is larger than the block 1.1 times , No more than 1.1 And then you divide a slice )
e. Write the slice information to a slice Planning File ;
f. The core of the whole slicing process is getSplit() Method ;
g.InputSplit Only the metadata information of the slice is recorded , For example, starting position 、 Length and node list, etc .
(4) Submit slice planning file to YARN On ,YARN Upper MrAppMaster It can be calculated and opened according to the slice planning file MapTask Number
3.6.3 FileInputFormat Slicing mechanism
Slicing mechanism
- Simply slice according to the content length of the file ;
- Slice size , Default equal to Block size ;
- The whole dataset is not considered when slicing , Instead, slice each file individually ;
case analysis
(1) There are two files for input data
file1.txt 320M
file2.txt 10M
(2) after FileInputFormat After the slicing mechanism operation of , The resulting slice information is as follows
file1.txt.split1 0~128
fle1.txt.split2 128~256
file1.txt.split3 256~300
file2.txt.split1 0~10
The formula for calculating the slice size in the source code
Math.max(minSize, Math.min(maxSize, blockSize))
mapreduce.input.fileinputformat.split.minsize The default value is 1mapreduce.input.fileinputformat.split.maxsize The default value is Long.MAXValue, So by default , Slice size =blockSize
Slice size settings
- maxSize( Slice maximum ): If the parameter is adjusted to a ratio blockSize Small , It makes the slice smaller , And it is equal to the value of the configured parameter ;
- minSize( Slice minimum ): If the parameter is adjusted to a ratio blockSize Big , Then we can make the slice compare with blockSize Big ;
Get slice information API
// Get the file name of the slice
String name = inputSplit.getPath().getName();
// According to the type of document , Get slice information
FileSplit inputSplit = (FileSplit) context.getInputSplit();
3.6.4 CombineTextInputFormat Slicing mechanism
Frame default TextInputFormat Slicing mechanism is to slice tasks according to file planning , No matter how small the file is , It's going to be a single slice , I'll give it to one MapTask, So if you have a lot of small files , There will be a lot of MapTask, Extremely inefficient .
1. Application scenarios
CombineTextInputFormat For scenes with too many small files , It can logically plan multiple small files into a slice , such , Multiple small documents can be handed over to one MapTask Handle .
2. Virtual storage slice maximum setting
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
Be careful : The maximum value of virtual storage slice should be set according to the actual small file size .
3. Slicing mechanism
The process of generating slices includes : Virtual stored procedure and slicing procedure .
(1) Virtual stored procedure
Will input all file sizes in the directory , And setMaxInputSplitSize Value comparison , If not greater than the maximum value set , Logically divide a block . If the input file is greater than the set maximum and more than twice , Then cut a piece at the maximum value ; When the remaining data size exceeds the set maximum value and is not greater than the maximum value 2 times , In this case, the files are divided into 2 Virtual storage blocks ( Prevent too small slices ).
for example setMaxInputSplitSize The value is 4M, Input file size is 8.02M, Then it is logically divided into one 4M. The remaining sizes are 4.02M, If according to 4M Logical division , Will appear 0.02M Small virtual storage files for , So the rest 4.02M File segmentation (2.01M and 2.01M) Two documents .
(2) Slicing process
(a) Determine whether the file size of virtual storage is greater than setMaxInputSplitSize value , Greater than or equal to form a single slice .
(b) Merge with the next virtual storage file if it is not greater than , Form a slice together .
(c) Test examples : Yes 4 Small file sizes are 1.7M、5.1M、3.4M as well as 6.8M These four little documents , After virtual storage 6 File block , The sizes are :
1.7M,(2.55M、2.55M),3.4M as well as (3.4M、3.4M)
It will eventually form 3 A slice , The sizes are :
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
3.6.5 CombineTextInputFormat Case study
1. demand
Merge a large number of input small files into one slice for unified processing .
(1) input data
Get ready 4 Small file
(2) expect
Expecting a slice processing 4 File
2. Implementation process
(1) Do nothing , function 1.8 Chaste WordCount Case program , The number of observation sections is 4.
number of splits: 4
(2) stay WordcountDriver Add the following code to , Run the program , And observe that the number of running slices is 3.
Add the following code to the driver class
// If not set InputFormat, It defaults to TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
// Virtual storage slice maximum setting 4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
Run if 3 A slice .
number of splits: 3
(3) stay WordcountDriver Add the following code to , Run the program , And observe that the number of running slices is 1.
Add the following code to the driver
// If not set InputFormat, It defaults to TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
// Virtual storage slice maximum setting 20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
Run if 1 A slice .
number of splits: 1
3.6.6 FileInputFormat Implementation class
reflection : Running MapReduce The program , The input file formats include : Line based log files 、 Binary format file 、 Database table, etc . that , For different data types ,MapReduce How to read these data ?
FileInputFormat Common interface implementation classes include :TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat And customization InputFormat etc. .
1.TextInputFormat
TextInputFormat By default FileInputFormat Implementation class , Read each record by line .
- key key Is the offset of the starting byte that stores the line in the entire file , LongWritable type .
- value value It's the content of this line , Does not include any line terminators ( Line breaks and carriage returns ),Text type .
such as , A fragment contains the following 4 Text records .
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
Each record is represented by the following key / It's worth it
(0,Rich learning form)
(19,Intelligent learning engine)
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
2.KeyValueTextInputFormat
Each line is a record , Split by separator key,value. You can set the separator by setting it in the driver class
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, "\t")
The default separator is tab(\t).
for example , Input is an input that contains 4 Pieces of records . among ——> It means a ( In the horizontal direction ) tabs .
line1 ——>Rich learning form
line2 ——>Intelligent learning engine
line3 ——>Learning more convenient
line4 ——>From the real demand for more close to the enterprise
Each record is represented by the following key value pairs
(line1,Rich learning form)
(line2,Intelligent learning engine)
(line3,Learning more convenient)
(line4,From the real demand for more close to the enterprise)
The key at this time key Is that each line is placed before the tab Text Sequence .
3.NLineInputFormat
If you use NlineInputFormat, For each map Process processing InputSplit No longer press Block Block to divide , Instead, press NlineInputFormat Number of rows specified N To differentiate . The total number of rows in the input file /N= Slice count , If you don't divide , Slice count = merchant +1.
for example , On the surface of the above 4 Line input is an example
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
If N yes 2, Then each input slice contains two lines , Turn on 2 individual MapTask.
(0,Rich learning form)
(19,Intelligent learning engine)
the other one mapper The last two lines are received
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
The keys and values here are the same as TextInputFormat It's the same generation .
3.6.7 KeyValueTextInputFormat Use cases
1. demand
Count the number of lines with the same first word in each line in the input file .
(1) input data
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
(2) Expected result data
banzhang 2
xihuan 2
2. Demand analysis 
3. Code implementation
(1) To write Mapper class
package com.test.mapreduce.KeyValueTextInputFormat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class KVTextMapper extends Mapper<Text, Text, Text, LongWritable>{
// 1 Set up value
LongWritable v = new LongWritable(1);
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
// banzhang ni hao
// 2 Write
context.write(key, v);
}
}
(2) To write Reducer class
package com.test.mapreduce.KeyValueTextInputFormat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class KVTextReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0L;
// 1 Summary statistics
for (LongWritable value : values) {
sum += value.get();
}
v.set(sum);
// 2 Output
context.write(key, v);
}
}
(3) To write Driver class
package com.test.mapreduce.keyvaleTextInputFormat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class KVTextDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// Set cut character
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");
// 1 obtain job object
Job job = Job.getInstance(conf);
// 2 Set up Driver, relation mapper and reducer
job.setJarByClass(KVTextDriver.class);
job.setMapperClass(KVTextMapper.class);
job.setReducerClass(KVTextReducer.class);
// 3 Set up map Output kv type
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4 Set the final output kv type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 5 Set input and output data path
FileInputFormat.setInputPaths(job, new Path(args[0]));
// Format input
job.setInputFormatClass(KeyValueTextInputFormat.class);
// 6 Set the output data path
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 Submit job
job.waitForCompletion(true);
}
}
3.6.8 NLineInputFormat Use cases
1. demand
Count the number of each word , Specify how many slices to output according to the number of lines in each input file . This case requires every three lines to be placed in a slice .
(1) input data
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang banzhang ni hao
xihuan hadoop banzhang
(2) Expected output data
Number of splits:4
2. Demand analysis 
3. Code implementation
(1) To write Mapper class
package com.test.mapreduce.nline;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class NLineMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
private Text k = new Text();
private LongWritable v = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 Get a row
String line = value.toString();
// 2 cutting
String[] splited = line.split(" ");
// 3 Cycle writing
for (int i = 0; i < splited.length; i++) {
k.set(splited[i]);
context.write(k, v);
}
}
}
(2) To write Reducer class
package com.test.mapreduce.nline;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class NLineReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0l;
// 1 Summary
for (LongWritable value : values) {
sum += value.get();
}
v.set(sum);
// 2 Output
context.write(key, v);
}
}
(3) To write Driver class
package com.test.mapreduce.nline;
import java.io.IOException;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class NLineDriver {
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
// I / O path needs to be set according to the actual I / O path on my computer
args = new String[] {
"e:/input/inputword", "e:/output1" };
// 1 obtain job object
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 7 Set up each slice InputSplit Divided into three records
NLineInputFormat.setNumLinesPerSplit(job, 3);
// 8 Use NLineInputFormat Number of processing records
job.setInputFormatClass(NLineInputFormat.class);
// 2 Set up Driver, relation mapper and reducer
job.setJarByClass(NLineDriver.class);
job.setMapperClass(NLineMapper.class);
job.setReducerClass(NLineReducer.class);
// 3 Set up map Output kv type
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4 Set the final output kv type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 5 Set input and output data path
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 Submit job
job.waitForCompletion(true);
}
}
4. test
(1) input data
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang banzhang ni hao
xihuan hadoop banzhang
(2) Slices of output , As shown in the figure 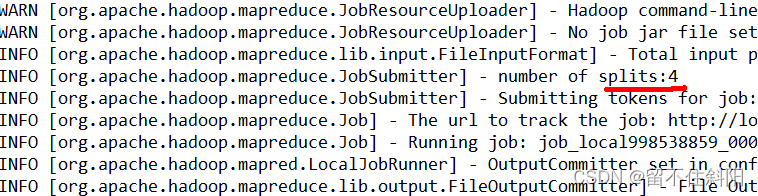
3.6.9 Customize InputFormat
In enterprise development ,Hadoop The frame comes with InputFormat Type cannot satisfy all application scenarios , You need to customize it InputFormat To solve practical problems .
Customize InputFormat Steps are as follows
- Customize a class inheritance FileInputFormat;
- rewrite RecordReader, Read a complete file at a time and encapsulate it as KV;
- Use when outputting SequenceFileOutPutFormat Export merge file ;
3.6.10 Customize InputFormat Case study
No matter what HDFS still MapReduce, It's very inefficient when dealing with small files , But it is hard to avoid the scenario of dealing with a large number of small files , here , We need solutions . You can customize InputFormat Merge small files .
1. demand
Merge multiple small files into one SequenceFile file (SequenceFile File is Hadoop Used to store binary forms key-value File format for ),SequenceFile There are multiple files stored in it , The form of storage is file path + The name is key, The content of the document is value.
(1) input data
one.txt two.txt three.txt
(2) Expected output file format
part-r-00000
2. Demand analysis
Customize a class inheritance FileInputFormat
- rewrite isSplitable() Method , return false No cutting ;
- rewrite createRecordReader(), Create custom RecordReader object , And initialization ;
rewrite RecordReader, Read a complete file at a time and encapsulate it as KV
- use IO The stream reads one file at a time and outputs it to value in , Because it is impossible to divide , Finally, all the files are encapsulated in value in ;
- Get file path + name , And set up key;
Set up Driver
// Set the input InputForMat
job.setInputFormatClass(WholeFileInputFormat.class);
// Set output OutputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
3. Program realization
(1) Customize InputFromat
package com.test.mapreduce.inputformat;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
// Define class inheritance FileInputFormat
public class WholeFileInputformat extends FileInputFormat<Text, BytesWritable>{
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
WholeRecordReader recordReader = new WholeRecordReader();
recordReader.initialize(split, context);
return recordReader;
}
}
(2) Customize RecordReader class
package com.test.mapreduce.inputformat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class WholeRecordReader extends RecordReader<Text, BytesWritable>{
private Configuration configuration;
private FileSplit split;
private boolean isProgress= true;
private BytesWritable value = new BytesWritable();
private Text k = new Text();
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
this.split = (FileSplit)split;
configuration = context.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (isProgress) {
// 1 Define cache
byte[] contents = new byte[(int)split.getLength()];
FileSystem fs = null;
FSDataInputStream fis = null;
try {
// 2 Get file system
Path path = split.getPath();
fs = path.getFileSystem(configuration);
// 3 Reading data
fis = fs.open(path);
// 4 Read file contents
IOUtils.readFully(fis, contents, 0, contents.length);
// 5 Output file content
value.set(contents, 0, contents.length);
// 6 Get file path and name
String name = split.getPath().toString();
// 7 Set output key value
k.set(name);
} catch (Exception e) {
}finally {
IOUtils.closeStream(fis);
}
isProgress = false;
return true;
}
return false;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return k;
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
}
}
(3) To write SequenceFileMapper Class processing flow
package com.test.mapreduce.inputformat;
import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class SequenceFileMapper extends Mapper<Text, BytesWritable, Text, BytesWritable>{
@Override
protected void map(Text key, BytesWritable value, Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
(4) To write SequenceFileReducer Class processing flow
package com.test.mapreduce.inputformat;
import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SequenceFileReducer extends Reducer<Text, BytesWritable, Text, BytesWritable> {
@Override
protected void reduce(Text key, Iterable<BytesWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, values.iterator().next());
}
}
(5) To write SequenceFileDriver Class processing flow
package com.test.mapreduce.inputformat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
public class SequenceFileDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// I / O path needs to be set according to the actual I / O path on my computer
args = new String[] {
"e:/input/inputformat", "e:/output1" };
// 1 obtain job object
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 Set up jar Package storage location 、 Associate custom mapper and reducer
job.setJarByClass(SequenceFileDriver.class);
job.setMapperClass(SequenceFileMapper.class);
job.setReducerClass(SequenceFileReducer.class);
// 7 Set the input inputFormat
job.setInputFormatClass(WholeFileInputformat.class);
// 8 Set output outputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
// 3 Set up map The output of kv type
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
// 4 Set the kv type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
// 5 Set I / O path
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 Submit job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
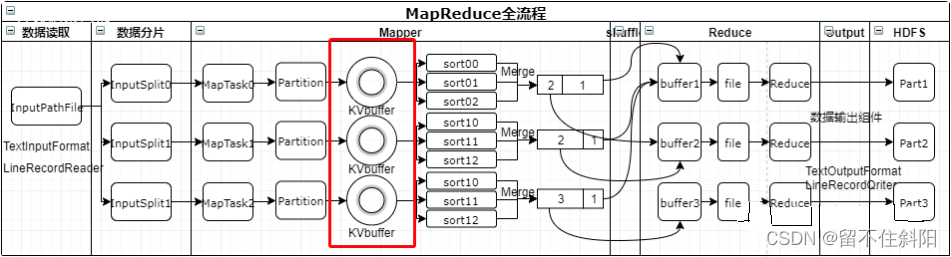
3.7 Shuffle Mechanism
3.7.1 Shuffle Mechanism
Map After method ,Reduce The data processing before the method is called Shuffle, As shown in the figure .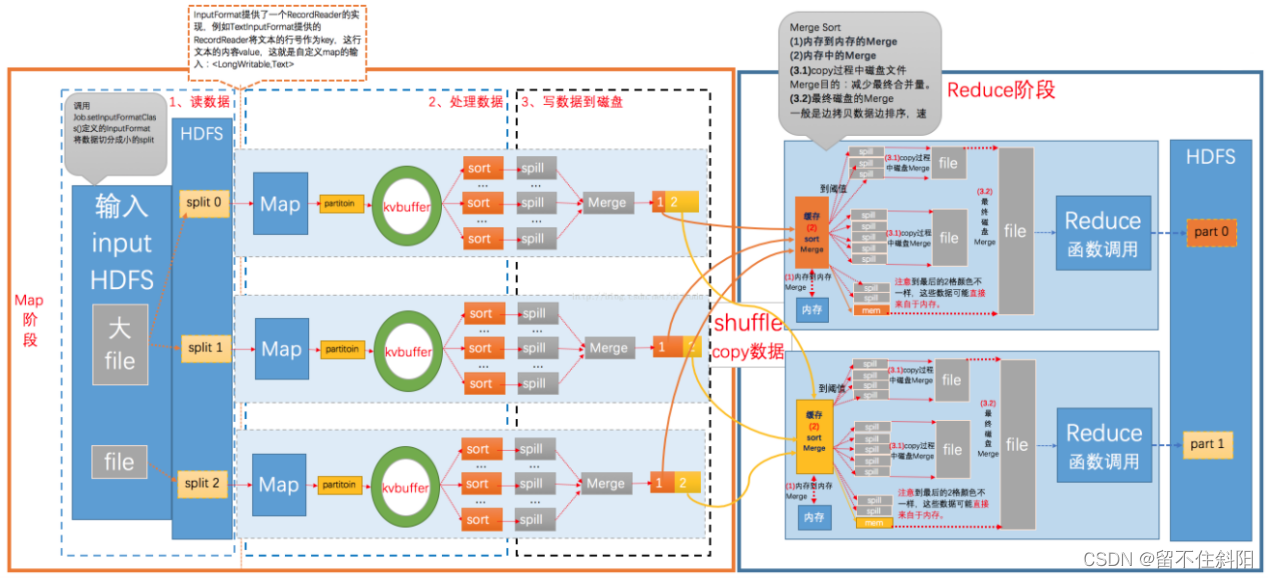
3.7.2 Partition Partition
Why partition ?
It is required to output the statistical results to different files according to conditions ( Partition ). such as : Press the statistical results
Output to different files according to the place where the mobile phone belongs to different provinces ( Partition )
Default partition Partition
/** Source code :numReduceTasks If it is equal to 1 Not going getPartition Method numReduceTasks: The default is 1 */
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
The default partition is based on key Of hashCode Yes reduceTasks The number is modular . Users can't control which key Which partition to store to
Custom partition
Custom class inheritance Partitioner, rewrite getPartition() Method .
/** This method returns a different partition Value , Thus, the number of partitions is controlled 、 Premise is numReduceTasks It's not equal to 1 KV: yes Map Output */
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 1 Get the top three phone numbers
String preNum = key.toString().substring(0, 3);
int partition = 4;
// 2 Determine which province
if ("136".equals(preNum)) {
partition = 0;
}else if ("137".equals(preNum)) {
partition = 1;
}else if ("138".equals(preNum)) {
partition = 2;
}else if ("139".equals(preNum)) {
partition = 3;
}
return partition;
}
}
stay Driver Set in partition
job.setPartitionerClass(CustomPartitioner.class);
Customize partition after , To customize partitioner Set the corresponding number of reduce task
job.setNumReduceTasks(5);
summary
- If reduceTask The number of > getPartition Number of results , A few more empty output files will be generated part-r-000xx;
- If 1 < reduceTask The number of < getPartition Number of results , There is a part of partition data without place , Meeting Exception;
- If reduceTask The number of = 1, It doesn't matter mapTask How many partition files are output by the end , It's all up to this one reduceTask, In the end, only one result file will be generated part-r-00000;
for example : Suppose the number of custom partitions is 5, be
(1) job.setNumReduceTasks(1); It's going to work , It just produces an output file
(2) job.setNumReduceTasks(2); Will report a mistake
(3) job.setNumReduceTasks(6); Greater than 5, The program will work , An empty file will be generated
3.7.3 Partition Partition case
1. demand
Output the statistical results to different files according to different provinces where the mobile phone belongs ( Partition )
(1) input data phone_data.txt
1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200
2 13846544121 192.196.100.2 264 0 200
3 13956435636 192.196.100.3 132 1512 200
4 13966251146 192.168.100.1 240 0 404
5 18271575951 192.168.100.2 www.atguigu.com 1527 2106 200
6 84188413 192.168.100.3 www.atguigu.com 4116 1432 200
7 13590439668 192.168.100.4 1116 954 200
8 15910133277 192.168.100.5 www.hao123.com 3156 2936 200
9 13729199489 192.168.100.6 240 0 200
10 13630577991 192.168.100.7 www.shouhu.com 6960 690 200
11 15043685818 192.168.100.8 www.baidu.com 3659 3538 200
12 15959002129 192.168.100.9 www.atguigu.com 1938 180 500
13 13560439638 192.168.100.10 918 4938 200
14 13470253144 192.168.100.11 180 180 200
15 13682846555 192.168.100.12 www.qq.com 1938 2910 200
16 13992314666 192.168.100.13 www.gaga.com 3008 3720 200
17 13509468723 192.168.100.14 www.qinghua.com 7335 110349 404
18 18390173782 192.168.100.15 www.sogou.com 9531 2412 200
19 13975057813 192.168.100.16 www.baidu.com 11058 48243 200
20 13768778790 192.168.100.17 120 120 200
21 13568436656 192.168.100.18 www.alibaba.com 2481 24681 200
22 13568436656 192.168.100.19 1116 954 200
(2) Expected output data
cell-phone number 136、137、138、139 They start with a separate one 4 In a file , Put the other beginning in one file .
2. Demand analysis
Add one more ProvincePartitioner Partition
136 Partition 0
137 Partition 1
138 Partition 2
139 Partition 3
Other Partition 4
Set up Driver class
// Specify custom data partition
job.setPartitionerClass(ProvincePartitioner.class)
// At the same time, the corresponding number of reduce task
job.setNumReduceTasks(5)
3. Add a partition class
package com.test.mapreduce.flowsum;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
// 1 Get the top three phone numbers
String preNum = key.toString().substring(0, 3);
int partition = 4;
// 2 Determine which province
if ("136".equals(preNum)) {
partition = 0;
}else if ("137".equals(preNum)) {
partition = 1;
}else if ("138".equals(preNum)) {
partition = 2;
}else if ("139".equals(preNum)) {
partition = 3;
}
return partition;
}
}
4. Add custom data partition settings and ReduceTask Set up
package com.test.mapreduce.flowsum;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowsumDriver {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
// I / O path needs to be set according to the actual I / O path on my computer
args = new String[]{
"e:/output1","e:/output2"};
// 1 Get configuration information , perhaps job Object instances
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 Specify the jar Local path of the package
job.setJarByClass(FlowsumDriver.class);
// 3 Specify this business job To be used mapper/Reducer Business class
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
// 4 Appoint mapper Of output data kv type
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 5 Specifies the kv type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 8 Specify custom data partition
job.setPartitionerClass(ProvincePartitioner.class);
// 9 At the same time, the corresponding number of reduce task
job.setNumReduceTasks(5);
// 6 Appoint job The directory of the original input file of
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 take job Related parameters configured in , as well as job Used java Class where jar package , Submit to yarn To run
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.7.4 WritableComparable Sort
1. Sorting overview
The order is MapReduce One of the most important operations in the framework .
MapTask and ReduceTask All data will be key Sort . The operation belongs to Hadoop Default behavior of . Data in any application is sorted , And whether or not it's logically necessary .
The default sort is in dictionary order , And the method to realize the sorting is Quick sort .
Default ReduceTask The number of 1.
2. Sorting time
about MapTask, It will temporarily put the result of processing into the ring buffer , When the ring buffer utilization reaches a certain threshold , Then do a quick sort of the data in the buffer , And write these ordered data to disk , And when the data is processed , It merges and sorts all the files on the disk .
about ReduceTask, It comes from every MapTask Remote copy of the corresponding data file on , If the file size exceeds a certain threshold , The overflow is written on the disk , Otherwise it's stored in memory . If the number of files on disk reaches a certain threshold , A merge sort is performed to generate a larger file ; If the size or number of files in memory exceeds a certain threshold , After a merge, overflow the data to disk . When all the data is copied ,ReduceTask Merge and sort all data on memory and disk at one time .
Default ReduceTask The number of 1.
3. Sorting classification
- Partial sorting ,MapReduce Sort the data set according to the key of the input record , Ensure the internal order of each output file ;
- Total sort , The final result is only one file , And the documents are in order . The operation to realize this method is to set only one ReduceTask. But this method is very inefficient in dealing with large files , Because one machine processes all the files , Completely lost MapReduce The parallel architecture provided .
- Auxiliary sort (GroupingComparator), stay Reduce End to key Sort , Receiving key by bean Object time , Want one or more fields to be the same ( All fields are different ) Of key Go to the same reduce When the method is used , You can use group sorting .
- Two order , In the custom sort process , If compareTo The judgment conditions in are two , That is, secondary sorting .
4. Custom sort WritableComparable
bean Object as key transmission , Need to achieve WritableComparable Interface rewriting compareTo Method , You can sort .
@Override
public int compareTo(FlowBean o) {
int result;
// According to the total flow , Reverse order
if (sumFlow > bean.getSumFlow()) {
result = -1;
}else if (sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
3.7.5 WritableComparable Sort cases ( Total sort )
1. demand
According to the case 2.3 The results are sorted again for the total flow .
(1) input data
Raw data The data after the first processing
phone_data.txt part-r-0000
(2) Expected output data
13509468723 7335 110349 117684
13736230513 2481 24681 27162
13956435636 132 1512 1644
13846544121 264 0 264
......
2. Demand analysis 
3. Code implementation
(1) FlowBean The object is in demand 1 The comparison function is added on the basis of
package com.test.mapreduce.sort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class FlowBean implements WritableComparable<FlowBean> {
private long upFlow;
private long downFlow;
private long sumFlow;
// When deserializing , Need reflection to call null parameter constructor , So there must be
public FlowBean() {
super();
}
public FlowBean(long upFlow, long downFlow) {
super();
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
/** * Serialization method * @param out * @throws IOException */
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
/** * Deserialization method Note that the order of deserialization is exactly the same as that of serialization * @param in * @throws IOException */
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
@Override
public int compareTo(FlowBean bean) {
int result;
// According to the total flow , Reverse order
if (sumFlow > bean.getSumFlow()) {
result = -1;
}else if (sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
}
(2) To write Mapper class
package com.test.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowCountSortMapper extends Mapper<LongWritable, Text, FlowBean, Text>{
FlowBean bean = new FlowBean();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 Get a row
String line = value.toString();
// 2 Intercept
String[] fields = line.split("\t");
// 3 Encapsulated object
String phoneNbr = fields[0];
long upFlow = Long.parseLong(fields[1]);
long downFlow = Long.parseLong(fields[2]);
bean.set(upFlow, downFlow);
v.set(phoneNbr);
// 4 Output
context.write(bean, v);
}
}
(3) To write Reducer class
package com.test.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FlowCountSortReducer extends Reducer<FlowBean, Text, Text, FlowBean>{
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// Cyclic output , Avoid the same total flow
for (Text text : values) {
context.write(text, key);
}
}
}
(4) To write Driver class
package com.test.mapreduce.sort;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowCountSortDriver {
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException {
// I / O path needs to be set according to the actual I / O path on my computer
args = new String[]{
"e:/output1","e:/output2"};
// 1 Get configuration information , perhaps job Object instances
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 Specify the jar Local path of the package
job.setJarByClass(FlowCountSortDriver.class);
// 3 Specify this business job To be used mapper/Reducer Business class
job.setMapperClass(FlowCountSortMapper.class);
job.setReducerClass(FlowCountSortReducer.class);
// 4 Appoint mapper Of output data kv type
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
// 5 Specifies the kv type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 6 Appoint job The directory of the original input file of
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 take job Related parameters configured in , as well as job Used java Class where jar package , Submit to yarn To run
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.7.6 WritableComparable Sort cases ( Intra regional ranking )
1. demand
Each province's mobile number output file is required to be sorted internally according to the total traffic .
2. Demand analysis
Based on the previous requirement , Add custom partition class , The division is set according to the cell phone number of the province .
3. Case study
(1) Add custom partition class
package com.test.mapreduce.sort;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class ProvincePartitioner extends Partitioner<FlowBean, Text> {
@Override
public int getPartition(FlowBean key, Text value, int numPartitions) {
// 1 Get the top three mobile phone numbers
String preNum = value.toString().substring(0, 3);
int partition = 4;
// 2 Set the partition according to the mobile phone number
if ("136".equals(preNum)) {
partition = 0;
}else if ("137".equals(preNum)) {
partition = 1;
}else if ("138".equals(preNum)) {
partition = 2;
}else if ("139".equals(preNum)) {
partition = 3;
}
return partition;
}
}
(2) Add partition class to driver class
// Load custom partition class
job.setPartitionerClass(ProvincePartitioner.class);
// Set up Reducetask Number
job.setNumReduceTasks(5);
3.7.7 Combiner Merge
Combiner The merger is Hadoop A method of frame optimization , because Combiner Consolidation reduces the IO transmission .
(1) combiner yes MR In the program Mapper and Reducer A component other than .
(2) combiner The parent class of a component is Reducer.
(3) combiner and reducer The difference is the location of the operation
Combiner It's in every MapTask The node is running ;
Reducer Receive global ownership Mapper Output result of ;
(4) combiner The meaning of this is for every MapTask Local summary of the output of , To reduce network traffic .
(5) combiner The premise of application is not to affect the final business logic , and ,combiner Output kv It should be with reducer The input of kv Types should be matched .
Customize Combiner Implementation steps
Customize a Combiner Inherit Reducer, rewrite Reduce Method
public class WordcountCombiner extends Reducer<Text, IntWritable, Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 Summary operation
int count = 0;
for(IntWritable v :values){
count += v.get();
}
// 2 Write
context.write(key, new IntWritable(count));
}
}
stay Job Set in driver class
job.setCombinerClass(WordcountCombiner.class);
3.7.8 Combiner Merger cases
1. demand
For each MapTask Local summary of the output of , To reduce the network transmission, i.e Combiner function .
(1) data input
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
(2) Expected output data
expect :Combine More input data , Merge on output , Output data reduction .
2. Demand analysis 
3. Scheme 1
(1) Add one more WordcountCombiner Class inheritance Reducer
package com.test.mr.combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1 Summary
int sum = 0;
for(IntWritable value :values){
sum += value.get();
}
v.set(sum);
// 2 Write
context.write(key, v);
}
}
(2) stay WordcountDriver Specified in the driver class Combiner
// Specify the need to use combiner, And which class to use as combiner The logic of
job.setCombinerClass(WordcountCombiner.class);
4. Option two
take WordcountReducer As Combiner stay WordcountDriver Specified in the driver class
// Specify the need to use Combiner, And which class to use as Combiner The logic of
job.setCombinerClass(WordcountReducer.class);
Run the program , As shown in the figure 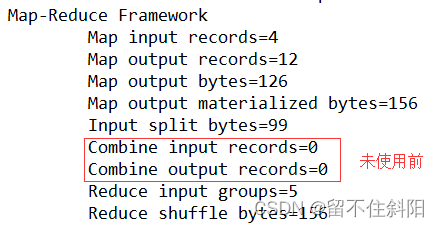

3.7.9 GroupingComparator grouping ( Auxiliary sort )
Yes Reduce Stage data is grouped by one or more fields .
Group sort steps
(1) Custom class inheritance WritableComparator
(2) rewrite compare() Method
@Override
public int compare(WritableComparable a, WritableComparable b) {
// Business logic of comparison
return result;
}
(3) Create a construct to pass the class of the comparison object to the parent class
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
3.7.10 GroupingComparator Group case
1. demand
There are the following order data , We need to find out the most expensive goods in each order .
| Order id | goods id | Clinch a deal amount |
|---|---|---|
| 0000001 | Pdt_01 | 222.8 |
| 0000001 | Pdt_02 | 33.8 |
| 0000002 | Pdt_03 | 522.8 |
| 0000002 | Pdt_04 | 122.4 |
| 0000002 | Pdt_05 | 722.4 |
| 0000003 | Pdt_06 | 232.8 |
| 0000003 | Pdt_02 | 33.8 |
(1) Expected output data
1 222.8
2 722.4
3 232.8
2. Demand analysis
(1) utilize “ Order id And transaction amount ” As key, Can be Map All order data read by the stage is based on id Ascending sort , If id Sort the same amount in descending order , Send to Reduce.
(2) stay Reduce End utilization GroupingComparator Will order id same kv Aggregate into groups , The first item is the most expensive item in the order , As shown in the figure .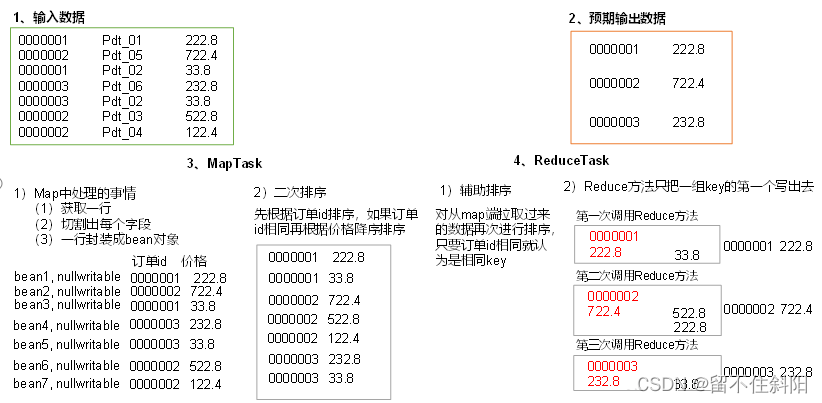
3. Code implementation
(1) Define order information OrderBean class
package com.test.mapreduce.order;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class OrderBean implements WritableComparable<OrderBean> {
private int order_id; // Order id Number
private double price; // Price
public OrderBean() {
super();
}
public OrderBean(int order_id, double price) {
super();
this.order_id = order_id;
this.price = price;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(order_id);
out.writeDouble(price);
}
@Override
public void readFields(DataInput in) throws IOException {
order_id = in.readInt();
price = in.readDouble();
}
@Override
public String toString() {
return order_id + "\t" + price;
}
public int getOrder_id() {
return order_id;
}
public void setOrder_id(int order_id) {
this.order_id = order_id;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
// Two order
@Override
public int compareTo(OrderBean o) {
int result;
if (order_id > o.getOrder_id()) {
result = 1;
} else if (order_id < o.getOrder_id()) {
result = -1;
} else {
// Price in reverse order
result = price > o.getPrice() ? -1 : 1;
}
return result;
}
}
(2) To write OrderSortMapper class
package com.test.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
OrderBean k = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 Get a row
String line = value.toString();
// 2 Intercept
String[] fields = line.split("\t");
// 3 Encapsulated object
k.setOrder_id(Integer.parseInt(fields[0]));
k.setPrice(Double.parseDouble(fields[2]));
// 4 Write
context.write(k, NullWritable.get());
}
}
(3) To write OrderSortGroupingComparator class
package com.test.mapreduce.order;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderGroupingComparator extends WritableComparator {
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean aBean = (OrderBean) a;
OrderBean bBean = (OrderBean) b;
int result;
if (aBean.getOrder_id() > bBean.getOrder_id()) {
result = 1;
} else if (aBean.getOrder_id() < bBean.getOrder_id()) {
result = -1;
} else {
result = 0;
}
return result;
}
}
(4) To write OrderSortReducer class
package com.test.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
(5) To write OrderSortDriver class
package com.test.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class OrderDriver {
public static void main(String[] args) throws Exception, IOException {
// I / O path needs to be set according to the actual I / O path on my computer
args = new String[]{
"e:/input/inputorder" , "e:/output1"};
// 1 Get configuration information
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 Set up jar Package load path
job.setJarByClass(OrderDriver.class);
// 3 load map/reduce class
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
// 4 Set up map Output data key and value type
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
// 5 Set the key and value type
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
// 6 Set input data and output data path
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 8 Set up reduce The end group
job.setGroupingComparatorClass(OrderGroupingComparator.class);
// 7 Submit
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.8 MapReduce And Mapper class ,Reducer Functions in class
Mapper There are setup(),map(),cleanup() and run() Four ways . among setup() It is generally used for some map() Preparations before ,map() Generally undertake the main processing work ,cleanup() It is the closing work, such as closing the file or executing map() After K-V Distribution, etc .run() The method provides setup->map->cleanup Execution template for .
stay MapReduce in ,Mapper Read data from an input slice , And then pass by Shuffle and Sort Stage , Distribute data to Reducer, stay Map End sum Reduce The end may use the set Combiner A merger , This is in Reduce Go ahead .Partitioner Control each K-V Yes, which one should be distributed reducer[Job There may be more than one reducer],Hadoop By default HashPartitioner,HashPartitioner Use key Of hashCode Yes reducer The quantity of is obtained by taking the mold .
Mapper class 4 A function
protected void setup(Mapper.Context context) throws IOException,InterruptedException //Called once at the beginning of the task
protected void cleanup(Mapper.Context context)throws IOException,InterruptedException //Called once at the end of the task.
protected void map(KEYIN key, VALUEIN value Mapper.Context context)throws IOException,InterruptedException
{
context.write((KEYOUT) key,(VALUEOUT) value);
}
//Called once for each key/value pair in the input split. Most applications should override this, but the default is the identity function.
public void run(Mapper.Context context)throws IOException,InterruptedException
{
setup(context);
while(context.nextKeyValue())
{
map(context.getCurrentKey(),context.getCurrentValue(),context)
}
cleanup(context);
}
//Expert users can override this method for more complete control over the execution of the Mapper.
Execution order :setup —> map/run ----> cleanup
Reducer Class 4 A function
protected void setup(Mapper.Context context) throws IOException,InterruptedException //Called once at the beginning of the task
protected void cleanup(Mapper.Context context)throws IOException,InterruptedException //Called once at the end of the task.
protected void reduce(KEYIN key, VALUEIN value Reducer.Context context)throws IOException,InterruptedException
{
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}
}
//This method is called once for each key. Most applications will define their reduce class by overriding this method. The default implementation is an identity function.
public void run(Reducer.Context context)throws IOException,InterruptedException
{
setup(context);
while (context.nextKey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
// If a back up store is used, reset it
((ReduceContext.ValueIterator(context.getValues().iterator())).resetBackupStore();
}
cleanup(context);
}
}
//Advanced application writers can use the run(org.apache.hadoop.mapreduce.Reducer.Context) method to control how the reduce task works
Execution order :setup —> map/run ----> cleanup
3.9 OutputFormat Data output
3.9.1OutputFormat Interface implementation class
OutputFormat yes MapReduce Base class for output , All implementation MapReduce The output formatted classes are implemented OutputFormat Interface .
Text output TextOutputFormat
The default output format is TextOutputFormat, It writes each record as a line of text . Its keys and values can be of any type , because TextOutputFormat call toString() Method to convert them into strings
SequenceFileOutputFormat
take SequenceFileOutputFormat Output as a follow-up MapReduce Task input , This is a good output format , Because of its compact format , It's easy to compress .
Customize OutputFormat
According to the needs of users , Custom implementation output .
3.9.2 Customize OutputFormat
To control the output path and output format of the final file , You can customize OutputFormat.
for example , In one MapReduce According to the different data in the program , Output two kinds of results to different directories , Such flexible output requirements can be customized OutputFormat To achieve .
Customize OutputFormat step
(1) Customize a class inheritance FileOutputFormat.
(2) rewrite RecordWriter, How to rewrite the output data write().
3.9.3 Customize OutputFormat Case study
1. demand
Filter the input log journal , contain test The website output to e:/test.log, It doesn't contain test The website output to e:/other.log.
(1) input data log.txt
http://www.baidu.com
http://www.google.com
http://cn.bing.com
http://www.test.com
http://www.sohu.com
http://www.sina.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sindsafa.com
(2) Expected output data
test.log
http://www.test.com
other.log
http://cn.bing.com
http://www.baidu.com
http://www.google.com
http://www.sin2a.com
http://www.sin2desa.com
http://www.sina.com
http://www.sindsafa.com
http://www.sohu.com
2. Case practice
(1) To write FilterMapper class
package com.test.mapreduce.outputformat;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FilterMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// Write
context.write(value, NullWritable.get());
}
}
(2) To write FilterReducer class
package com.test.mapreduce.outputformat;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class FilterReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
Text k = new Text();
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
// 1 Get a row
String line = key.toString();
// 2 Splicing
line = line + "\r\n";
// 3 Set up key
k.set(line);
// 4 Output
context.write(k, NullWritable.get());
}
}
(3) Customize a OutputFormat class
package com.test.mapreduce.outputformat;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FilterOutputFormat extends FileOutputFormat<Text, NullWritable>{
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
// Create a RecordWriter
return new FilterRecordWriter(job);
}
}
(4) To write RecordWriter class
package com.test.mapreduce.outputformat;
import java.io.IOException;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
public class FilterRecordWriter extends RecordWriter<Text, NullWritable> {
FSDataOutputStream testOut = null;
FSDataOutputStream otherOut = null;
public FilterRecordWriter(TaskAttemptContext job) {
// 1 Get file system
FileSystem fs;
try {
fs = FileSystem.get(job.getConfiguration());
// 2 Create output file path
Path testPath = new Path("e:/test.log");
Path otherPath = new Path("e:/other.log");
// 3 Create output stream
testOut = fs.create(testPath);
otherOut = fs.create(otherPath);
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void write(Text key, NullWritable value) throws IOException, InterruptedException {
// Judge whether it includes “test” Output to different files
if (key.toString().contains("test")) {
testOut.write(key.toString().getBytes());
} else {
otherOut.write(key.toString().getBytes());
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
// close resource
IOUtils.closeStream(testOut);
IOUtils.closeStream(otherOut); }
}
(5) To write FilterDriver class
```java
package com.test.mapreduce.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FilterDriver {
public static void main(String[] args) throws Exception {
// I / O path needs to be set according to the actual I / O path on my computer
args = new String[] {
"e:/input/inputoutputformat", "e:/output2" };
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FilterDriver.class);
job.setMapperClass(FilterMapper.class);
job.setReducerClass(FilterReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// To set the custom output format component to job in
job.setOutputFormatClass(FilterOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
// Although we customized outputformat, But because of our outputformat Inherited from fileoutputformat
// and fileoutputformat To output a _SUCCESS file , therefore , You have to specify an output directory here
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
3.10 Join Multiple applications
3.10.1 Reduce Join
Map End main work : For different tables or files key/value, Label records from different sources . Then use the connection field as key, The rest and the new logo as value, Finally, output .
Reduce End main work : stay Reduce End as connection field key The grouping of has been completed , Only the records from different files need to be in each group ( stay Map The stage has been marked ) Separate , And then finally merge .
3.10.2 Reduce Join Case study
1. demand
Order data sheet t_order
id pid amount
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6
Commodity information table t_product
pid pname
01 millet
02 Huawei
03 gree
According to the data in the commodity information table pid Merge into order data table .
Table final data form
id pname amount
1001 millet 1
1004 millet 4
1002 Huawei 2
1005 Huawei 5
1003 gree 3
1006 gree 6
2. Demand analysis
By using association conditions as Map Output key, Meet the requirements of two tables Join Conditional data and carry the file information of the data source , To the same ReduceTask, stay Reduce Data concatenation in , As shown in the figure .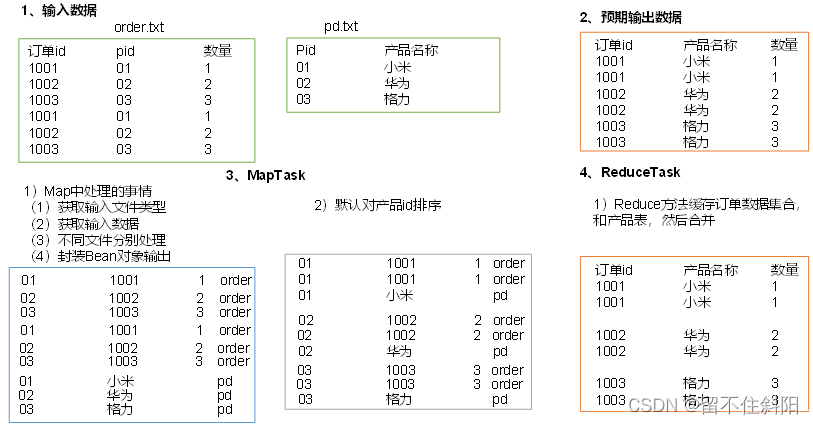
3. Code implementation
(1) Create a combined product and order Bean class
package com.test.mapreduce.table;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class TableBean implements Writable {
private String order_id; // Order id
private String p_id; // product id
private int amount; // Product quantity
private String pname; // The product name
private String flag; // Label of table
public TableBean() {
super();
}
public TableBean(String order_id, String p_id, int amount, String pname, String flag) {
super();
this.order_id = order_id;
this.p_id = p_id;
this.amount = amount;
this.pname = pname;
this.flag = flag;
}
public String getFlag() {
return flag;
}
public void setFlag(String flag) {
this.flag = flag;
}
public String getOrder_id() {
return order_id;
}
public void setOrder_id(String order_id) {
this.order_id = order_id;
}
public String getP_id() {
return p_id;
}
public void setP_id(String p_id) {
this.p_id = p_id;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(order_id);
out.writeUTF(p_id);
out.writeInt(amount);
out.writeUTF(pname);
out.writeUTF(flag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.order_id = in.readUTF();
this.p_id = in.readUTF();
this.amount = in.readInt();
this.pname = in.readUTF();
this.flag = in.readUTF();
}
@Override
public String toString() {
return order_id + "\t" + pname + "\t" + amount + "\t" ;
}
}
(2) To write TableMapper class
package com.test.mapreduce.table;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean>{
String name;
TableBean bean = new TableBean();
Text k = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 1 Get input file slice
FileSplit split = (FileSplit) context.getInputSplit();
// 2 Get the input file name
name = split.getPath().getName();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 Get input data
String line = value.toString();
// 2 Different files are processed separately
if (name.startsWith("order")) {
// Order form processing
// 2.1 cutting
String[] fields = line.split("\t");
// 2.2 encapsulation bean object
bean.setOrder_id(fields[0]);
bean.setP_id(fields[1]);
bean.setAmount(Integer.parseInt(fields[2]));
bean.setPname("");
bean.setFlag("order");
k.set(fields[1]);
}else {
// Product table processing
// 2.3 cutting
String[] fields = line.split("\t");
// 2.4 encapsulation bean object
bean.setP_id(fields[0]);
bean.setPname(fields[1]);
bean.setFlag("pd");
bean.setAmount(0);
bean.setOrder_id("");
k.set(fields[0]);
}
// 3 Write
context.write(k, bean);
}
}
(3) To write TableReducer class
package com.test.mapreduce.table;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TableReducer extends Reducer<Text, TableBean, TableBean, NullWritable> {
@Override
protected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException {
// 1 Ready to store a collection of orders
ArrayList<TableBean> orderBeans = new ArrayList<>();
// 2 Get ready bean object
TableBean pdBean = new TableBean();
for (TableBean bean : values) {
if ("order".equals(bean.getFlag())) {
// The order sheet
// Copy each order data to the collection
TableBean orderBean = new TableBean();
try {
BeanUtils.copyProperties(orderBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
orderBeans.add(orderBean);
} else {
// Product list
try {
// Copy the passed product table into memory
BeanUtils.copyProperties(pdBean, bean);
} catch (Exception e) {
e.printStackTrace();
}
}
}
// 3 The splicing of tables
for(TableBean bean:orderBeans){
bean.setPname (pdBean.getPname());
// 4 Write the data out
context.write(bean, NullWritable.get());
}
}
}
(4) To write TableDriver class
package com.test.mapreduce.table;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TableDriver {
public static void main(String[] args) throws Exception {
// 0 Reconfigure according to your computer path
args = new String[]{
"e:/input/inputtable","e:/output1"};
// 1 Get configuration information , perhaps job Object instances
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 Specify the jar Local path of the package
job.setJarByClass(TableDriver.class);
// 3 Specify this business job To be used Mapper/Reducer Business class
job.setMapperClass(TableMapper.class);
job.setReducerClass(TableReducer.class);
// 4 Appoint Mapper Of output data kv type
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TableBean.class);
// 5 Specifies the kv type
job.setOutputKeyClass(TableBean.class);
job.setOutputValueClass(NullWritable.class);
// 6 Appoint job The directory of the original input file of
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 take job Related parameters configured in , as well as job Used java Class where jar package , Submit to yarn To run
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
4. test
Run program to view results
1001 millet 1
1001 millet 1
1002 Huawei 2
1002 Huawei 2
1003 gree 3
1003 gree 3
5. summary
shortcoming : This way The operation of merging is in Reduce Stages to complete , When a table has a lot of content ,Reduce Too much processing pressure at the end ,Map The computing load of nodes is very low , Low resource utilization , And in a large number of data in Reduce Stage summary ,Reduce Data skew is easy to be generated in the stage .
Solution :Map End to achieve data consolidation .( Can be in Map The operation realized in the stage is Map Phase realization )
3.10.3 Map Join
1. Use scenarios
Map Join For a very small table 、 A big scene with a watch .
2. advantage
reflection : stay Reduce End processing too many tables , Very prone to data skew . What do I do ?
stay Map End cache multiple tables , Advance business logic , This increase Map End business , Reduce Reduce Pressure of end data , Minimize data skew .
3. Specific measures : use DistributedCache
(1) stay Mapper Of setup Stage , Read file to cache collection .
(2) Load cache in driver function .
// Cache normal files to Task Operation node .
job.addCacheFile(new URI("file://e:/cache/pd.txt"));
3.10.4Map Join Case study
1. demand
Order data sheet t_order
id pid amount
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6
Commodity information table t_product
pid pname
01 millet
02 Huawei
03 gree
According to the data in the commodity information table pid Merge into order data table .
The final data form
id pname amount
1001 millet 1
1004 millet 4
1002 Huawei 2
1005 Huawei 5
1003 gree 3
1006 gree 6
2. Demand analysis
MapJoin It is applicable to the case that there are small tables in the associated table .
3. Implementation code
(1) First add the cache file to the driver module
package test;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class DistributedCacheDriver {
public static void main(String[] args) throws Exception {
// 0 Reconfigure according to your computer path
args = new String[]{
"e:/input/inputtable2", "e:/output1"};
// 1 obtain job Information
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 Set load jar Package path
job.setJarByClass(DistributedCacheDriver.class);
// 3 relation map
job.setMapperClass(DistributedCacheMapper.class);
// 4 Set the final output data type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 5 Set I / O path
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 Load cache data
job.addCacheFile(new URI("file:///e:/input/inputcache/pd.txt"));
// 7 Map End Join You don't have to Reduce Stage , Set up reduceTask The number of 0
job.setNumReduceTasks(0);
// 8 Submit
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
(2) Read cached file data
package test;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class DistributedCacheMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Map<String, String> pdMap = new HashMap<>();
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
// 1 Get cached files
URI[] cacheFiles = context.getCacheFiles();
String path = cacheFiles[0].getPath().toString();
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), "UTF-8"));
String line;
while(StringUtils.isNotEmpty(line = reader.readLine())){
// 2 cutting
String[] fields = line.split("\t");
// 3 Cache data into collections
pdMap.put(fields[0], fields[1]);
}
// 4 Shut off flow
reader.close();
}
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 Get a row
String line = value.toString();
// 2 Intercept
String[] fields = line.split("\t");
// 3 Get product id
String pId = fields[1];
// 4 Get the product name
String pdName = pdMap.get(pId);
// 5 Splicing
k.set(line + "\t"+ pdName);
// 6 Write
context.write(k, NullWritable.get());
}
}
3.11 Counter application
Hadoop Maintain several built-in counters for each job , To describe multiple indicators . for example , Some counters record the number of bytes and records processed , It enables the user to monitor the amount of input data that has been processed and the amount of output data that has been generated .
Counter API
(1) Count by enumeration
enum MyCounter{
MALFORORMED ,NORMAL}
Add... To the custom counter defined by enumeration 1.
context.getCounten(MyCounter.MALFORORMED).increment(1)
(2) Using counter groups 、 How to count counter names
context.getCounter(" courterGroup", "counter").increment(1);
Group name and counter name are optional , But better make sense .
(3) The counting results are viewed on the console after the program runs .
3.12 Data cleaning (ETL)
Running the core business MapReduce Before the program , It is often necessary to clean the data first , Clean up data that doesn't meet user requirements . The cleaning process often just needs to run Mapper Program , No need to run Reduce Program .
3.12.1 Data cleaning case - Simple analytic version
1. demand
The length of the field in the removal log is less than or equal to 11 Log .
(1) input data
web.log
(2) Expected output data
The field length of each line is greater than 11.
2. Demand analysis
Need to be in Map The stage filters and cleans the input data according to the rules .
3. Implementation code
(1) To write LogMapper class
package com.test.mapreduce.weblog;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 obtain 1 Row data
String line = value.toString();
// 2 Parsing log
boolean result = parseLog(line,context);
// 3 Log illegal exit
if (!result) {
return;
}
// 4 Set up key
k.set(line);
// 5 Writing data
context.write(k, NullWritable.get());
}
// 2 Parsing log
private boolean parseLog(String line, Context context) {
// 1 Intercept
String[] fields = line.split(" ");
// 2 Log length is greater than 11 Is legal
if (fields.length > 11) {
// System counter
context.getCounter("map", "true").increment(1);
return true;
}else {
context.getCounter("map", "false").increment(1);
return false;
}
}
}
(2) To write LogDriver class
package com.test.mapreduce.weblog;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogDriver {
public static void main(String[] args) throws Exception {
// I / O path needs to be set according to the actual I / O path on my computer
args = new String[] {
"e:/input/inputlog", "e:/output1" };
// 1 obtain job Information
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 load jar package
job.setJarByClass(LogDriver.class);
// 3 relation map
job.setMapperClass(LogMapper.class);
// 4 Set the final output type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// Set up reducetask The number is 0
job.setNumReduceTasks(0);
// 5 Sets the input and output paths
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 Submit
job.waitForCompletion(true);
}
}
3.12.2 Data cleaning case - Complex analytic version
1. demand
Yes Web Identify and segment the fields in the access log , Remove illegal records in the log . According to the cleaning rules , Output filtered data .
(1) input data
web.log
(2) Expected output data
Are legal data
2. Implementation code
(1) Define a bean, It is used to record the data fields in the log data
package com.test.mapreduce.log;
public class LogBean {
private String remote_addr;// Record the client's ip Address
private String remote_user;// Record the client user name , Ignore attributes "-"
private String time_local;// Record access time and time zone
private String request;// Record the requested url And http agreement
private String status;// Record request status ; Success is 200
private String body_bytes_sent;// Record the size of the body content sent to the client file
private String http_referer;// Used to record the links from that page
private String http_user_agent;// Record information about the client's browser
private boolean valid = true;// Judge whether the data is legal
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return time_local;
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(this.valid);
sb.append("\001").append(this.remote_addr);
sb.append("\001").append(this.remote_user);
sb.append("\001").append(this.time_local);
sb.append("\001").append(this.request);
sb.append("\001").append(this.status);
sb.append("\001").append(this.body_bytes_sent);
sb.append("\001").append(this.http_referer);
sb.append("\001").append(this.http_user_agent);
return sb.toString();
}
}
(2) To write LogMapper class
package com.test.mapreduce.log;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 obtain 1 That's ok
String line = value.toString();
// 2 Whether the parsing log is legal
LogBean bean = parseLog(line);
if (!bean.isValid()) {
return;
}
k.set(bean.toString());
// 3 Output
context.write(k, NullWritable.get());
}
// Parsing log
private LogBean parseLog(String line) {
LogBean logBean = new LogBean();
// 1 Intercept
String[] fields = line.split(" ");
if (fields.length > 11) {
// 2 Encapsulated data
logBean.setRemote_addr(fields[0]);
logBean.setRemote_user(fields[1]);
logBean.setTime_local(fields[3].substring(1));
logBean.setRequest(fields[6]);
logBean.setStatus(fields[8]);
logBean.setBody_bytes_sent(fields[9]);
logBean.setHttp_referer(fields[10]);
if (fields.length > 12) {
logBean.setHttp_user_agent(fields[11] + " "+ fields[12]);
}else {
logBean.setHttp_user_agent(fields[11]);
}
// Greater than 400,HTTP error
if (Integer.parseInt(logBean.getStatus()) >= 400) {
logBean.setValid(false);
}
}else {
logBean.setValid(false);
}
return logBean;
}
}
(3) To write LogDriver class
package com.test.mapreduce.log;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class LogDriver {
public static void main(String[] args) throws Exception {
// 1 obtain job Information
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 load jar package
job.setJarByClass(LogDriver.class);
// 3 relation map
job.setMapperClass(LogMapper.class);
// 4 Set the final output type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 5 Sets the input and output paths
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6 Submit
job.waitForCompletion(true);
}
}
3.13 MapReduce Development summary
Writing MapReduce The program , The following aspects need to be considered
Input data interface lnputFormat
(1) The default implementation class is :TextInputFormat
(2) TextInputFormat The functional logic of is : Read one line at a time , Then take the starting offset of the line as key, Line content as value return .
(3) KeyValueTextInputFormat Each line is a record , Split by separator key ,value. The default separator is tab.
(4) NlineInputFormat According to the specified number of lines N To slice .
(5) CombineTextInputFormat You can combine multiple small files into a single slice , Improve processing efficiency .
(6) Users can also customize lnputFormat.
Logic processing interface Mapper
Users implement three of these methods according to their business needs : map();setup();cleanup ();
Partitioner Partition
(1) There is a default implementation HashPartitioner, Logic is based on key Hash value and numReduces To return a partition number ; kexy.hashCode()&Integer.MAXVALUE%numReduces
(2) If there is a special business need , You can customize the partition .
Comparable Sort
(1) When using custom objects as key To output , It has to be realized WritableComparable Interface , Rewrite one of compareTo() Method .
(2) Partial sorting , Internal sorting of each final output file .
(3) Total sort , Sort all the data , Usually there is only one Reduce.
(4) Two order , There are two conditions for ranking .
Combiner Merge
Combiner Merging can improve the efficiency of program execution ,i Reduce Io transmission . However, it must not affect the original business processing results .
Reduce End grouping GroupingComparator
stay Reduce End to key Grouping . be applied to : Receiving key by bean Object time , Want one or more fields to be the same ( All fields are different ) Of key Go to the same reduce When the method is used , You can use group sorting .
Logic processing interface Reducer
Users implement three of these methods according to their business needs : reduce();setup(); cleanup ();
Output data interface OutputFormat
(1) The default implementation class is TextOutputFormat, The functional logic is : Put each one KV Yes , Output a line to the target text file .
(2) take SequenceFileOutputFormat Output as a follow-up MapReduce Task input , This is — A good output format , Because its format is tight i Gather together , It's easy to compress .
(3) Users can also customize outputFormat.
边栏推荐
- Li Kou: the 81st biweekly match
- Classic application of stack -- bracket matching problem
- (POJ - 3685) matrix (two sets and two parts)
- 读取和保存zarr文件
- 第一章 MapReduce概述
- Chapter 6 rebalance details
- Suffix expression (greed + thinking)
- Study notes of Tutu - process
- (POJ - 3579) median (two points)
- Codeforces Round #803 (Div. 2)A~C
猜你喜欢

Read and save zarr files
QT有关QCobobox控件的样式设置(圆角、下拉框,向上展开、可编辑、内部布局等)
Some problems encountered in installing pytorch in windows11 CONDA
分享一个在树莓派运行dash应用的实例。
QT模拟鼠标事件,实现点击双击移动拖拽等
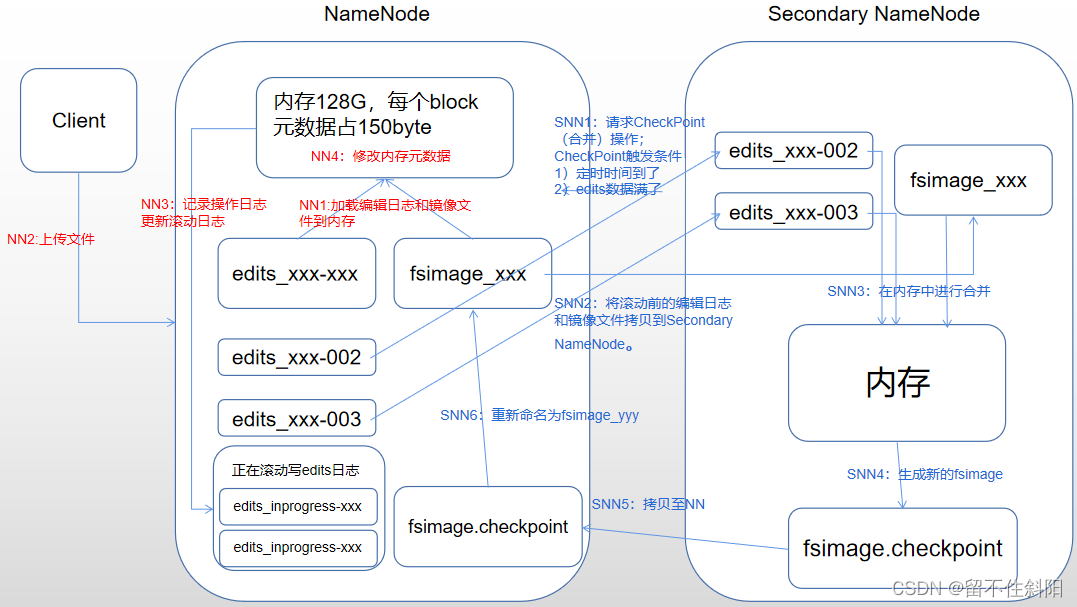
Chapter 5 namenode and secondarynamenode
第7章 __consumer_offsets topic
QT simulates mouse events and realizes clicking, double clicking, moving and dragging
解决Intel12代酷睿CPU单线程调度问题(二)
力扣:第81场双周赛
随机推荐
QT按钮点击切换QLineEdit焦点(含代码)
sublime text 代码格式化操作
Generate random password / verification code
业务系统兼容数据库Oracle/PostgreSQL(openGauss)/MySQL的琐事
js封装数组反转的方法--冯浩的博客
pytorch提取骨架(可微)
Double specific tyrosine phosphorylation regulated kinase 1A Industry Research Report - market status analysis and development prospect prediction
Remove the border when input is focused
(lightoj - 1323) billiard balls (thinking)
第5章 NameNode和SecondaryNameNode
(lightoj - 1354) IP checking (Analog)
Bisphenol based CE Resin Industry Research Report - market status analysis and development prospect forecast
Anaconda下安装Jupyter notebook
MariaDB的安装与配置
解决Intel12代酷睿CPU单线程只给小核运行的问题
China double brightening film (dbef) market trend report, technical dynamic innovation and market forecast
Spark的RDD(弹性分布式数据集)返回大结果集
Market trend report, technological innovation and market forecast of desktop electric tools in China
300th weekly match - leetcode
Codeforces Round #797 (Div. 3)无F