当前位置:网站首页>SPSS uses kmeans, two-stage clustering and RFM model to study the behavior law data of borrowers and lenders in P2P network finance
SPSS uses kmeans, two-stage clustering and RFM model to study the behavior law data of borrowers and lenders in P2P network finance
2022-07-26 08:07:00 【Extension Research Office】
Full text link :http://tecdat.cn/?p=27831
The source of the original text is : The official account of the tribal public
With P2P The transaction volume of online financial platforms surged , Its transaction data cannot be fully and effectively utilized . Introduce cluster analysis into P2P In the management of online financial platform , Cluster analysis technology is used to analyze P2P Analyze the existing data of online financial platform , And then for the borrower 、 The service provided by the payer and the manager becomes P2P New issues faced by the network financial platform in the development process .
In view of the above problems and needs , This paper hopes to apply clustering analysis technology to P2P Online financial platform to explore the behavior law of borrowers and lenders , Thus, it is beneficial to the construction and development of the platform .
Clustering analysis
Definition of cluster analysis
Clustering analysis , It is an important research content in knowledge discovery , It is also called group analysis class , Simply put, it is a collection of elements with similar characteristics . clustering , It is to gather the elements with high similarity , Final , Form several subsets .
Algorithm and process of cluster analysis
Clustering algorithm is the main embodiment of the superiority of clustering technology , Scalability of the algorithm 、 Ability to handle different attributes 、 Clustering ability for arbitrary shapes 、 Processing ability of noise data 、 Insensitive to the order of input records 、 High dimensional 、 Constraint based clustering, interpretability and usability can measure the quality of the algorithm .
Division method : The partition method is to divide a given large amount of data into multiple groups or clusters according to certain rules or different partition methods , among , Each group or cluster generally contains at least one set of data , Different types of data can only belong to different groups , There are obvious differences between each group .
Hierarchical approach : Hierarchical method for clustering analysis is to divide the data into several groups to form a tree structure , It can also be divided into top-down splitting algorithm and bottom-up condensing algorithm according to different ways of constructing numbers .
Density based approach : This method refers to the method of continuous clustering through the density of adjacent local areas exceeding a certain threshold , in other words , Each given region will contain a certain number of points , Thus, some outliers can be filtered out through this method , Improve the efficiency of data analysis .
Typical clustering analysis process generally includes data ( Or called samples or patterns ) Get ready 、 Feature selection and feature extraction 、 Proximity calculation 、 clustering ( Or grouping )、 Evaluate the effectiveness of clustering results .
Cluster analysis process :
- Data preparation process : That is, data preprocessing , Including feature standardization and dimension reduction .
- Feature selection process : Select the most effective feature from the initial feature and store it in the vector .
- Feature extraction process : Through the transformation of the selected features, a new prominent feature is formed .
- clustering ( Or grouping ): First, select a certain distance function of the appropriate feature type ( Or construct a new distance function ) Measure the closeness ; Then perform clustering or grouping .
- Evaluation of clustering results : It refers to the evaluation of clustering results . If the result is satisfactory , It's over ; If you are not satisfied, you need to adjust the above “ feature extraction ” link , Until satisfied .
Cluster analysis of borrower behavior
Research data description
The data in this paper comes from the historical transaction information in the platform background database , Including loan related information and lender information .

The status of platform loans is divided into : The audit failed 、 Stream label ( It refers to that the bidding period of a loan list has expired , But the loan was not fully raised , That is, the loan failed )、 Successful borrowing ( It means that the loan is full , The loan relationship has been established ).
After data screening , The samples of the final study include 999 Loan list . among ,248 There are articles that fail to pass the audit ;209 The bar is the flow mark ;542 Successful loan ,169 The loan has been repaid . The total amount of successful transactions reached 3090.93 Ten thousand yuan .

chart : Sample data composition
According to the overall research data , The proportion of loans that failed to pass the examination reached 24.8%, The proportion of flow indicators reaches 20.9%, Only 54.3%, It can be seen that the loan success rate needs to be improved .
The purpose of cluster analysis
because P2P The online lending platform has a low threshold 、 Features such as less restrictions , This tends to exacerbate P2P The risk of online lending , therefore , Its credit system construction is very important . Its credit system is to determine the borrower's credit score according to the borrower's authentication information and the loan repayment situation , According to credit points, it is divided into AA、A、B、C、D、E、HR Seven credit ratings , among AA Class represents the highest credit rating , It means that the borrower is active in lending on the platform and has good credit , Low credit risk ; Then gradually decrease ,HR Class indicates the lowest credit rating 、 Borrowers with high credit risk .
Model design of cluster analysis
Borrower's overall data statistics
This paper extracts 923 There are no duplicate and valid borrower information .923 Among the borrowers AA Level only 1 position , and A Level also only 1 position , and B Class and C There are relatively many classes , Most of all D、E、HR Class accounts for 98%.

As can be seen from the table , Among the borrowers AA、A、B、C、D、E、HR7 The number of successful loans per capita of class is greater than the number of standard loans per capita . Generally speaking, the average value , The lower the borrower's credit rating , The average number of flow marks will gradually increase , The average number of successful loans will gradually decrease . From this we can see that , The higher the credit rating of the borrower , The higher the probability of successful borrowing . But in E Class borrowers , In case of special circumstances , The average number of successful borrowings of its borrowers is greater than D Class borrowers , The average number of stream marks is less than D Class borrowers , thus , It can be seen that the classification is unreasonable . On the other hand , In terms of cardinality , Due to the high credit rating AA、A、B、C The base of class I borrowers is small , Although the loan success rate is very high , But the total number of borrowings is far less than E、HR Class borrowers . This explains , The higher the credit rating, the more successful the loan will be , And the lower the credit rating, the less successful the loan will be . The higher the credit rating with Ding Jie , The number of successes and failures of borrowers will be higher, and the conclusion is similar .
Data preparation and clustering variable selection
Through the integration of borrower information in the data source , Get user activity data , Including the user's borrowing times 、 Number of successful borrowings 、 Credit rating 、 Total loan amount and other information . In order to understand the different behavior patterns and characteristics of platform users , Here, the borrower is selected ID Number 、 Average borrowing limit 、 Total number of borrowings 、 Loan success times 、 Credit rating 、 Lend points ( The lending points obtained by the borrower as the lender ) As a clustering variable .
Application and implementation of clustering analysis
This article USES the SPSS Yes 923 Cluster analysis on the data of effective borrowers . among , Select credit rating as the classification variable , Because the sample data has both continuous variables and classified variables , therefore , This paper uses two-stage clustering . And SPSS Provided in KMeans The difference between clustering method and hierarchical clustering analysis is , The two-stage clustering method uses log maximum likelihood estimation to measure the distance between classes , And according to Schwarz Bayes criterion (BIC) or Akaike Information rules (AIC) And other indicators automatically determine the optimal number of clusters .
utilize SPSS The clustering process is as follows :
- Import data files into SPSS in .
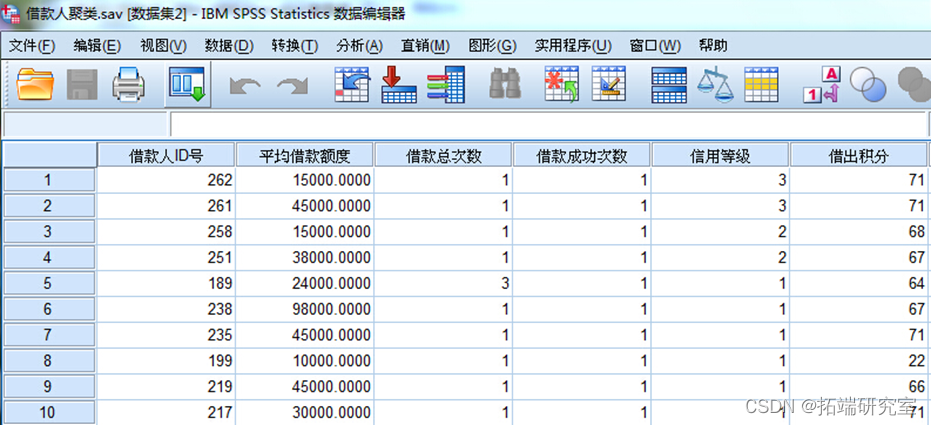
Click on “ confirm ” Button , Get the results , Here's the picture .

chart The result of second-order cluster analysis

adopt SPSS Two stage clustering method , Borrowers are divided into 4 class , give the result as follows :
The composition and characteristics of each category of users are shown in the table :

It can be concluded from the table , The two-stage cluster analysis does not completely classify borrowers according to the credit rating set by the platform itself , Instead, it digs out more accurate behavior information of borrowers .
In the first category ,HR The proportion of graded borrowers is the largest ,D、E second , The total borrowing times of such borrowers are 4 Highest in class , But the average borrowing limit 、 The number of successful loans and lending points are 4 The lowest class , It can be seen that although this type of borrower is more active on the platform, its degree of trust is very low , There is a serious risk of fraud .
In the second category , D Borrowers with class a credit rating account for 100%, Although the average loan amount and the total number of loans are not the highest , However, its loan success times and loan points are the highest among the four categories , It can be seen that , Although such borrowers are not very active on the platform as borrowers , However, the proportion of full standard loans issued by it is very high , And they are often active on the platform as lenders .
Cluster analysis of lender behavior
The purpose of cluster analysis
This paper uses the method of cluster analysis , Yes P2P In the online lending platform, lenders segment customers , So as to find out the category of lenders , In the end P2P There is a reasonable and accurate classification of lenders in the online lending platform .
Customer segmentation
be based on RFM Analysis of customer classification principle of the model
There are many methods of customer segmentation , But the final criterion to measure whether the method is suitable should be the accuracy of the segmentation results and the matching degree with the enterprise management .
RFM Model is one of the commonly used methods of customer segmentation , As a quantitative analysis model , It is generally used for prediction and analysis before implementing marketing activities . among ,R(recenty) Last consumption , It refers to the time interval between the latest consumption and the current date , Theoretically speaking , The closer the customer spent last time , The more likely you are to respond to the goods or services provided immediately ;F(frequency) Consumption frequency , It refers to a certain period of time , The number of times customers spend , Usually , The more customers spend , The more loyal you are , That means we can have more market share by increasing the number of customers' consumption ;M(monetary) Consumption amount , It refers to a certain period of time , The total amount of customer consumption , Consumption amount is the pillar of all data rate reports , You can also verify “ Pareto's law ”—— company 80% The income comes from 20% Customers , Through the consumption amount, we can see which are the key customers , Contribute the most to the turnover of the company .
according to P2P Characteristics of online lending platform , take RFM The indicators should be changed accordingly , As shown in the table .

be based on K-Means Customer classification of clustering algorithm
K-Means Clustering method , Also known as K- Mean clustering method is widely used in clustering algorithm based on partition .K-Means The algorithm is based on the number of categories entered k value , All objects in cluster analysis are divided into k Groups , There is a high similarity between objects in each group . This article takes K-Means Clustering is a tool , Weighted RFM For measure , by P2P Lenders are classified in the online lending platform , The basic idea is :
1) take RFM The third index is standardized , Before weighting, the data needs to be standardized . use Ri、Fi、Mi Respectively refers to the standardized lender i Of R、F、M value .
also ,Ri=(RM-R)/(RM- RN),Fi=(F-FN)/(FM-FN),Mi=(M-MN)/(MM-MN) (1)
among ,RM、 RN Among the lenders R Maximum and minimum values of ,FM、FN Among the lenders F Maximum and minimum values of ,MM、MN Sub table for lenders M Maximum and minimum values of .
2) Determine the number of clustering groups k.
3) Weight the indicators , And make use of K-Means Clustering method to get k Class lenders .
4) For each type of lender RFM Mean and total RFM Compare the mean , Finally, determine the customer type of each type of lender .
The application of clustering analysis in the customer segmentation of lenders
This paper extracts 500 Borrower information that is not repeated and valid . Relevant important data are shown in the table below .

Use K-means When clustering the mean , You need to judge the number of clusters in advance .RFM In the model , The classification of lenders' customers is through each customer category RFM Average and total RFM Compare the average value to determine , And the comparison of a single indicator can only have 2 In this case : Greater than ( be equal to ) Or less than the average , So there may be 2×2×2=8 Species category , therefore , In this paper, the number of clusters is determined as 8 individual . First , According to the formula (1) For lenders R、F、M Values are normalized , Then use SPSS19.0 Software for standardized lenders R、F、M Value for K-Means Clustering analysis .
Finally get 8 Type of lender , And will 8 Lender like R、F、M Mean and total R、F、M Mean comparison , among “↑” Is greater than the average ,“↓” Is less than the average , The results are as follows .

Discussion on the user training strategy of the platform
Now , At home P2P Online lending platforms are developing rapidly , But most of them ignore the part of user training , Especially for lenders . The platform has not formed a perfect and effective mechanism and strategy in user training , In a short time , It may not reflect the importance of user training , But it is likely to cause the loss of high-quality users for a long time .
Through the cluster analysis of front-end borrowers, we can see , There are some key development customers among the borrowers , It may not have a high credit rating, but it borrows a lot on the platform and can repay on time , Such borrowers can be regarded as key development targets , Provide them with some encouragement and preferential policies . For high-quality borrowers that already exist on the platform , We can launch corresponding loan projects according to their actual needs .

The most popular insights
1.R Language k-Shape Algorithm stock price time series clustering
4.r Language iris iris Hierarchical clustering of data sets
5.Python Monte Carlo K-Means Cluster practice
6. use R Mining and clustering website comment text
9.R Language based Keras Deep learning image classification based on small data sets
边栏推荐
- Why is Google's internal tools not suitable for you?
- 这是一张图片
- Understand microservices bit by bit
- 2022-07-13 group 5 Gu Xiangquan's learning notes day06
- Exam summary on June 27, 2022
- Burp Suite-第一章 Burp Suite 安装和环境配置
- Rewriting and overloading
- es6中函数默认参数、箭头函数、剩余参数-讲解
- The idea of stack simulating queue
- The difference between throw and throws?
猜你喜欢

How WPS sets page headers page by page

要不你给我说说什么是长轮询吧?
FTP service

No valid host was found when setting up openstack to create an instance There are not enough hosts available. code:500
Lnmp+wordpress to quickly build a personal website

MySQL implementation plan

Shardingjdbc pit record

Excel file reading and writing (creation and parsing)

Burp suite Chapter 7 how to use burp scanner

A tutorial for mastering MySQL database audit characteristics, implementation scheme and audit plug-in deployment
随机推荐
The difference between LinkedList and ArrayList
Command line execution and test report generation of JMeter performance test
Understand microservices bit by bit
Rewriting and overloading
R language foundation
2022-07-14 group 5 Gu Xiangquan's learning notes day07
Software engineering -- dental clinic -- demand analysis
Network ()
PHP environment deployment
为啥谷歌的内部工具不适合你?
A tutorial for mastering MySQL database audit characteristics, implementation scheme and audit plug-in deployment
NFS service and Samba service deployment
Recurrence of strtus2 historical vulnerability
Team members participate in 2022 China multimedia conference
Exam summary on July 13, 2022
【 fastjson1.2.24反序列化漏洞原理代码分析】
If the thread crashes, why doesn't it cause the JVM to crash? What about the main thread?
Add traceid to the project log
JSP built-in object (implicit object)
Summary of API method