当前位置:网站首页>美团二面:Redis与MySQL双写一致性如何保证?
美团二面:Redis与MySQL双写一致性如何保证?
2022-08-04 23:21:00 【倾听铃的声】
前言
有位朋友去美团面试,他说被问到Redis与MySQL双写一致性如何保证? 这道题其实就是在问缓存和数据库在双写场景下,一致性是如何保证的?本文将跟大家一起来探讨如何回答这个问题。

谈谈一致性
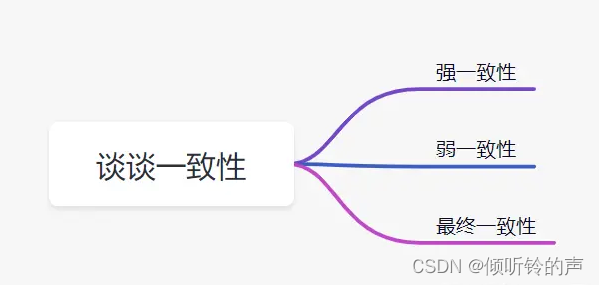
一致性就是数据保持一致,在分布式系统中,可以理解为多个节点中数据的值是一致的。
- 强一致性:这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往对系统的性能影响大
- 弱一致性:这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态
- 最终一致性:最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一个数据一致的状态。这里之所以将最终一致性单独提出来,是因为它是弱一致性中非常推崇的一种一致性模型,也是业界在大型分布式系统的数据一致性上比较推崇的模型
三个经典的缓存模式
缓存可以提升性能、缓解数据库压力,但是使用缓存也会导致数据不一致性的问题。一般我们是如何使用缓存呢?有三种经典的缓存模式:
- Cache-Aside Pattern
- Read-Through/Write through
- Write behind
Cache-Aside Pattern
Cache-Aside Pattern,即旁路缓存模式,它的提出是为了尽可能地解决缓存与数据库的数据不一致问题。
Cache-Aside读流程
Cache-Aside Pattern的读请求流程如下:
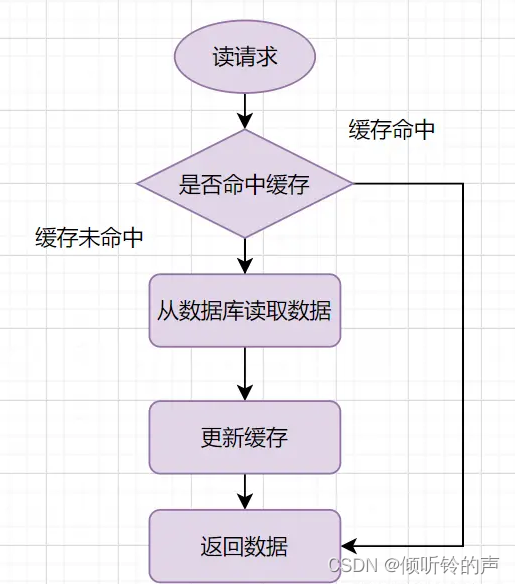
- 读的时候,先读缓存,缓存命中的话,直接返回数据
- 缓存没有命中的话,就去读数据库,从数据库取出数据,放入缓存后,同时返回响应。
Cache-Aside 写流程
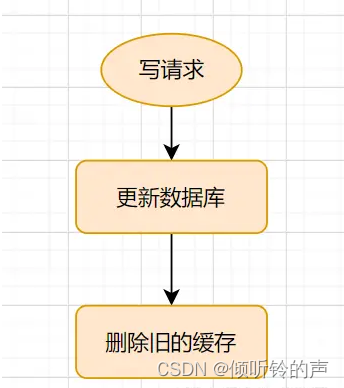
Cache-Aside Pattern的写请求流程如下:
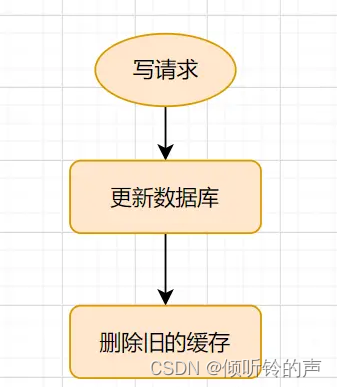
更新的时候,先更新数据库,然后再删除缓存。
Read-Through/Write-Through(读写穿透)
Read/Write Through模式中,服务端把缓存作为主要数据存储。应用程序跟数据库缓存交互,都是通过抽象缓存层完成的。
Read-Through
Read-Through的简要流程如下

- 从缓存读取数据,读到直接返回
- 如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
这个简要流程是不是跟Cache-Aside很像呢?其实Read-Through就是多了一层Cache-Provider,流程如下:

Read-Through实际只是在Cache-Aside之上进行了一层封装,它会让程序代码变得更简洁,同时也减少数据源上的负载。
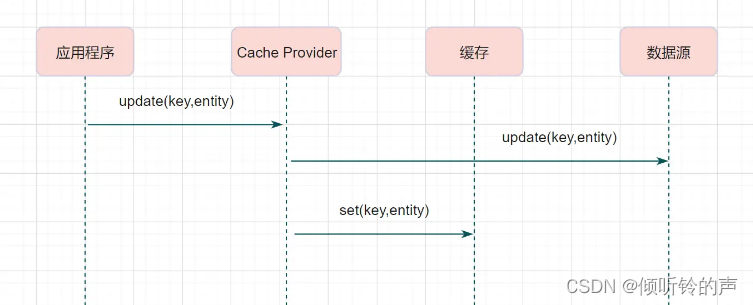
Write-Through
Write-Through模式下,当发生写请求时,也是由缓存抽象层完成数据源和缓存数据的更新,流程如下:
Write behind (异步缓存写入)
Write behind跟Read-Through/Write-Through有相似的地方,都是由Cache Provider来负责缓存和数据库的读写。它两又有个很大的不同:Read/Write Through是同步更新缓存和数据的,Write Behind则是只更新缓存,不直接更新数据库,通过批量异步的方式来更新数据库。
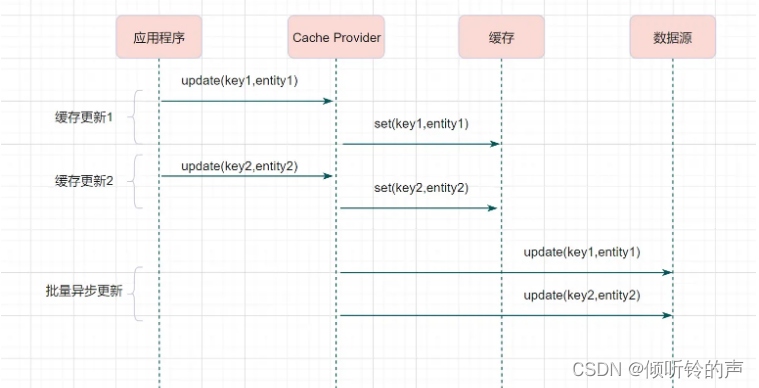
这种方式下,缓存和数据库的一致性不强,对一致性要求高的系统要谨慎使用。但是它适合频繁写的场景,MySQL的InnoDB Buffer Pool机制就使用到这种模式。
操作缓存的时候,删除缓存呢,还是更新缓存?
一般业务场景,我们使用的就是Cache-Aside模式。 有些小伙伴可能会问, Cache-Aside在写入请求的时候,为什么是删除缓存而不是更新缓存呢?
我们在操作缓存的时候,到底应该删除缓存还是更新缓存呢?我们先来看个例子:
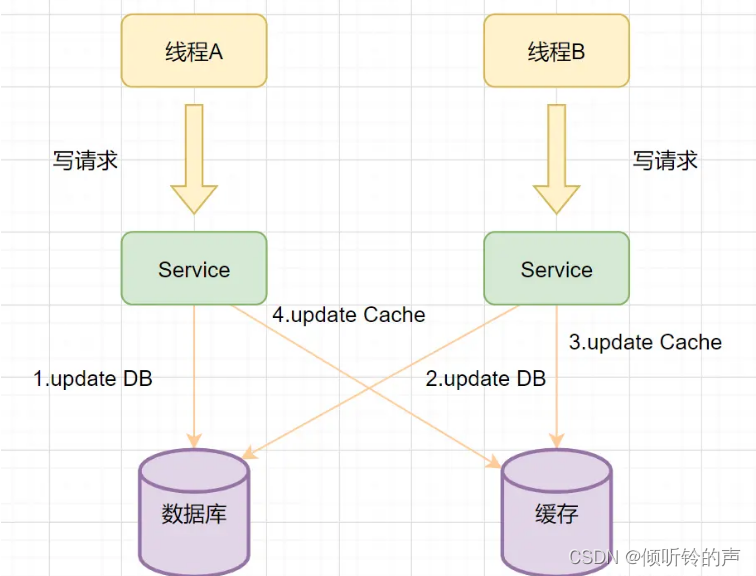
- 线程A先发起一个写操作,第一步先更新数据库
- 线程B再发起一个写操作,第二步更新了数据库
- 由于网络等原因,线程B先更新了缓存
- 线程A更新缓存。
这时候,缓存保存的是A的数据(老数据),数据库保存的是B的数据(新数据),数据不一致了,脏数据出现啦。如果是删除缓存取代更新缓存则不会出现这个脏数据问题。
更新缓存相对于删除缓存,还有两点劣势:
- 如果你写入的缓存值,是经过复杂计算才得到的话。更新缓存频率高的话,就浪费性能啦。
- 在写数据库场景多,读数据场景少的情况下,数据很多时候还没被读取到,又被更新了,这也浪费了性能呢(实际上,写多的场景,用缓存也不是很划算了)
双写的情况下,先操作数据库还是先操作缓存?
Cache-Aside缓存模式中,有些小伙伴还是有疑问,在写入请求的时候,为什么是先操作数据库呢?为什么不先操作缓存呢?
假设有A、B两个请求,请求A做更新操作,请求B做查询读取操作。
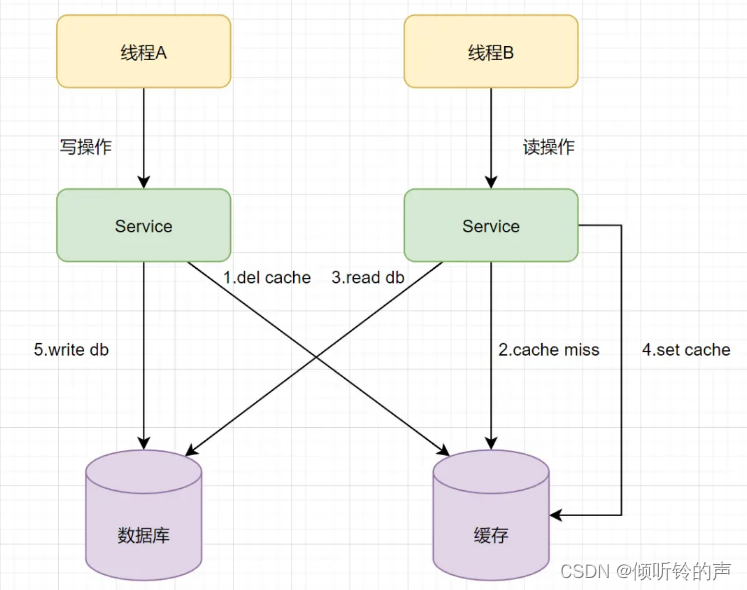
- 线程A发起一个写操作,第一步del cache
- 此时线程B发起一个读操作,cache miss
- 线程B继续读DB,读出来一个老数据
- 然后线程B把老数据设置入cache
- 线程A写入DB最新的数据
酱紫就有问题啦,缓存和数据库的数据不一致了。缓存保存的是老数据,数据库保存的是新数据。因此,Cache-Aside缓存模式,选择了先操作数据库而不是先操作缓存。
缓存延时双删
有些小伙伴可能会说,不一定要先操作数据库呀,采用缓存延时双删策略就好啦?什么是延时双删呢?
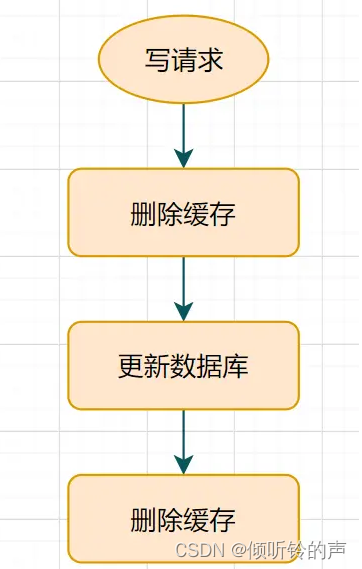
- 先删除缓存
- 再更新数据库
- 休眠一会(比如1秒),再次删除缓存。
这个休眠一会,一般多久呢?都是1秒?
这个休眠时间 = 读业务逻辑数据的耗时 + 几百毫秒。 为了确保读请求结束,写请求可以删除读请求可能带来的缓存脏数据。
删除缓存重试机制
不管是延时双删还是Cache-Aside的先操作数据库再删除缓存,如果第二步的删除缓存失败呢,删除失败会导致脏数据哦~
删除失败就多删除几次呀,保证删除缓存成功呀~ 所以可以引入删除缓存重试机制
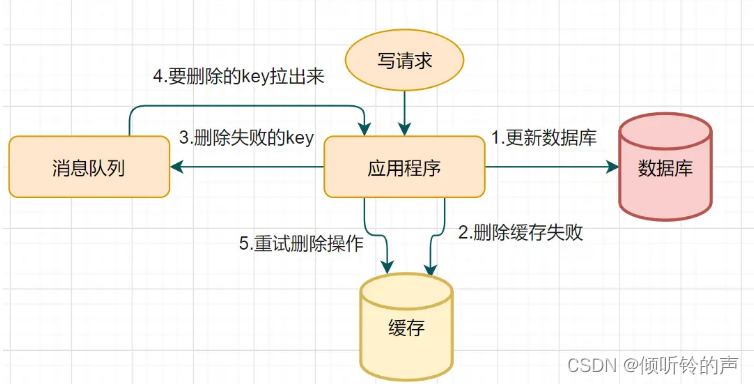
- 写请求更新数据库
- 缓存因为某些原因,删除失败
- 把删除失败的key放到消息队列
- 消费消息队列的消息,获取要删除的key
- 重试删除缓存操作
读取biglog异步删除缓存
重试删除缓存机制还可以,就是会造成好多业务代码入侵。其实,还可以通过数据库的binlog来异步淘汰key。
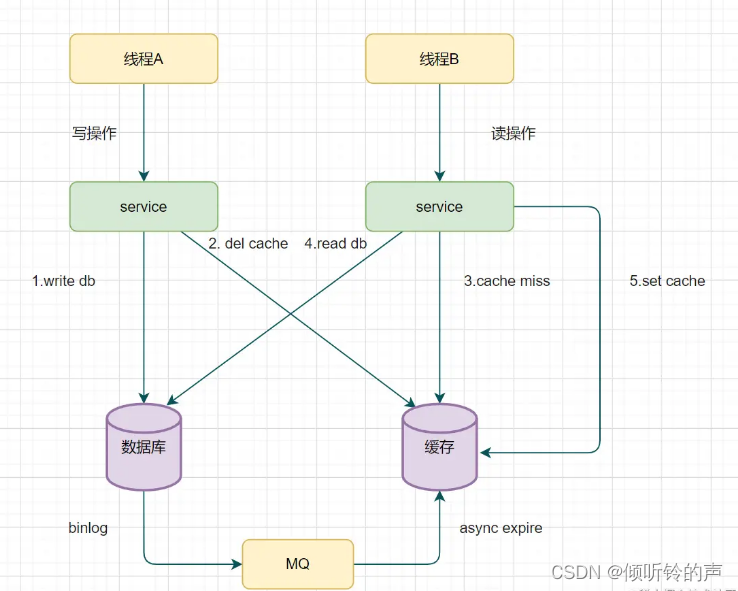
以mysql为例 可以使用阿里的canal将binlog日志采集发送到MQ队列里面,然后通过ACK机制确认处理这条更新消息,删除缓存,保证数据缓存一致性
边栏推荐
- 一点点读懂cpufreq(二)
- Controller层代码这么写,简洁又优雅!
- node中package解析、npm 命令行npm详解,node中的common模块化,npm、nrm两种方式查看源和切换镜像
- 特征工程资料汇总
- Basic web in PLSQL
- Service Mesh落地路径
- 小黑leetcode冲浪:94. 二叉树的中序遍历
- 零基础如何入门软件测试?再到测开(小编心得)
- [Cultivation of internal skills of string functions] strlen + strstr + strtok + strerror (3)
- Linux系统重启和停止Mysql服务教程
猜你喜欢
小黑leetcode之旅:95. 至少有 K 个重复字符的最长子串

OPENCV学习DAY8

Pytorch分布式训练/多卡/多GPU训练DDP的torch.distributed.launch和torchrun
MySQL的JSON 数据类型1
【字符串函数内功修炼】strcpy + strcat + strcmp(一)
地面高度检测/平面提取与检测(Fast Plane Extraction in Organized Point Clouds Using Agglomerative Hierarchical Clu)

Bidding Announcement | Operation and Maintenance Project of Haina Baichuang Official Account

web3.js

Qt中的常用控件
Flutter启动流程(Skia引擎)介绍与使用
随机推荐
uniapp动态实现滑动导航效果demo(整理)
407. 接雨水 II
Pytorch分布式训练/多卡/多GPU训练DDP的torch.distributed.launch和torchrun
直接插入排序
Shell expect 实战案例
[Cultivation of internal skills of string functions] strncpy + strncat + strncmp (2)
功耗控制之DVFS介绍
Kernel函数解析之kernel_restart
I was rejected by the leader for a salary increase, and my anger rose by 9.5K after switching jobs. This is my mental journey
MYS-6ULX-IOT 开发板测评——使用 Yocto 添加软件包
Basic web in PLSQL
temp7777
[Paper Notes KDD2021] MixGCF: An Improved Training Method for Graph Neural Network-based Recommender Systems
@Async注解的作用以及如何实现异步监听机制
话题 | 雾计算和边缘计算有什么区别?
OPENCV学习DAY8
基于深度学习的路面坑洞检测(详细教程)
一点点读懂cpufreq(一)
4 - "PyTorch Deep Learning Practice" - Backpropagation
The market value of 360 has evaporated by 390 billion in four years. Can government and enterprise security save lives?