当前位置:网站首页>Crawl Douban to read top250 and import it into SqList database (or excel table)
Crawl Douban to read top250 and import it into SqList database (or excel table)
2022-06-26 18:12:00 【Little fox dreams of going to fairy tale town】
Climb and take Douban to read Top250, Import sqlist database ( or excel form ) in
For source code, please visit https://github.com/zhang020801/douban_bookTop250
One 、 Program source code
import re # Regular expressions
from bs4 import BeautifulSoup # Extract the data
import urllib.request,urllib.error # Request access to web page , Return to the web page source code
import xlwt # Save data to excel form
import sqlite3 # Save data to sqlist In the database
def main():
# Declare which pages to crawl
baseurl = "https://book.douban.com/top250?start="
# get data
datalist = getData(baseurl)
#print(datalist)
# Save the data
#savepath = " Douban studies Top250.xls"
dbpath = "book.db"
#saveData(datalist,savepath)
saveData2(datalist,dbpath)
# Regular expressions
findlink = re.compile(r'<a href="(.*?)" οnclick=".*?" title=".*?">') # Book links
findtitle = re.compile(r'<a href=".*?" οnclick=".*?" title="(.*?)">') # Book name
findimglink = re.compile(r'<img src="(.*?)" width="90"/>') # Cover link
findauthor = re.compile(r'<p class="pl">(.*?) / (.*?) / .*? / .*?/.*?</p>') # author / translator
findpress = re.compile(r'<p class="pl">.*? / .*? / (.*?) / .*?/.*?</p>') # Press.
findtime = re.compile(r'<p class="pl">.*? / .*? / .*? / (.*?) / .*?</p>') # Publication date
findmoney = re.compile(r'<p class="pl">.*? / .*? / .*? / .*? / (.*?)</p>') # Book price
findscore = re.compile(r'<span class="rating_nums">(.*?)</span>') # score
findpeople = re.compile(r'<span class="pl">.*?(.*?) People comment on .*?</span>',re.S) # Number of evaluators
findjieshao = re.compile(r'<span class="inq">(.*?)</span>') # Introduce
def getData(baseurl):
datalist = []
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url)
#print(html)
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('table',width="100%"):
item = str(item) # convert to str Format
#print(item)
data = []
title = re.findall(findtitle, item)[0]
#print(title)
data.append(title)
score = re.findall(findscore,item)[0]
#print(score)
data.append(score)
link = re.findall(findlink,item)[0]
#print(link)
data.append(link)
imglink = re.findall(findimglink,item)[0]
#print(imglink)
data.append(imglink)
author = re.findall(findauthor,item)
if len(author)==0:
author = re.findall(r'<p class="pl">(.*?) / .*? / .*?</p>',item)
author = author[0]
#print(author)
data.append(author)
press = re.findall(findpress,item)
if len(press)==0:
press = re.findall(r'<p class="pl">.*? / (.*?) / .*? / .*?</p>',item)
if len(press)==0:
press = " "
else:press = press[0]
#print(press)
data.append(press)
time = re.findall(findtime,item)
if len(time)==0:
time = re.findall(r'<p class="pl">.*? / .*? / (.*?) / .*?</p>',item)
if len(time)==0:
time = " "
else:time = time[0]
#print(time)
data.append(time)
money = re.findall(findmoney,item)
if len(money)==0:
money = re.findall(r'<p class="pl">.*? / .*? / .*?/ (.*?)</p>',item)
if len(money)==0:
money = " "
else:money = money[0]
#print(money)
data.append(money)
people = re.findall(findpeople,item)
#people = people[0].replace(" ","")
people = people[0].replace("(\n ","")
#print(people)
data.append(people)
jieshao = re.findall(findjieshao,item)
if len(jieshao)==0:
jieshao = " "
jieshao = jieshao[0]
#print(jieshao)
data.append(jieshao)
datalist.append(data)
return datalist
def askURL(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.163Safari / 537.36"
}
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
def saveData(datalist,savepath):
print(" Start saving ...")
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet(' Douban studies Top250',cell_overwrite_ok=True)
col = (" Book name "," score "," Book links "," Cover image link "," author / translator "," Press. "," Publication date "," The price is "," Number of evaluators "," Brief introduction ")
for i in range(0,10):
sheet.write(0,i,col[i])
for i in range(0,250):
print(" The first %d strip "%(i+1))
data = datalist[i]
for j in range(0,10):
sheet.write(i+1,j,data[j])
book.save(savepath)
print(" Save complete ")
def saveData2(datalist,dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
# for index in range(len(data)):
# if index==1 or index==8:
# continue
# else:data[index] = '"' + data[index] + '"'
sql = ''' insert into book250( title,score,book_link,Img_link,author,press,time,money,num,jieshao) values ("%s","%s","%s","%s","%s","%s","%s","%s","%s","%s")'''%(data[0],data[1],data[2],data[3],data[4],data[5],data[6],data[7],data[8],data[9])
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
def init_db(dbpath):
sql = ''' create table book250 ( id integer primary key autoincrement, title varchar , score numeric , book_link text, Img_link text, author text, press text, time text, money text, num numeric , jieshao text ) '''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
if __name__ =="__main__":
main()
Two 、 Program run results
1) Import data into excel In the table 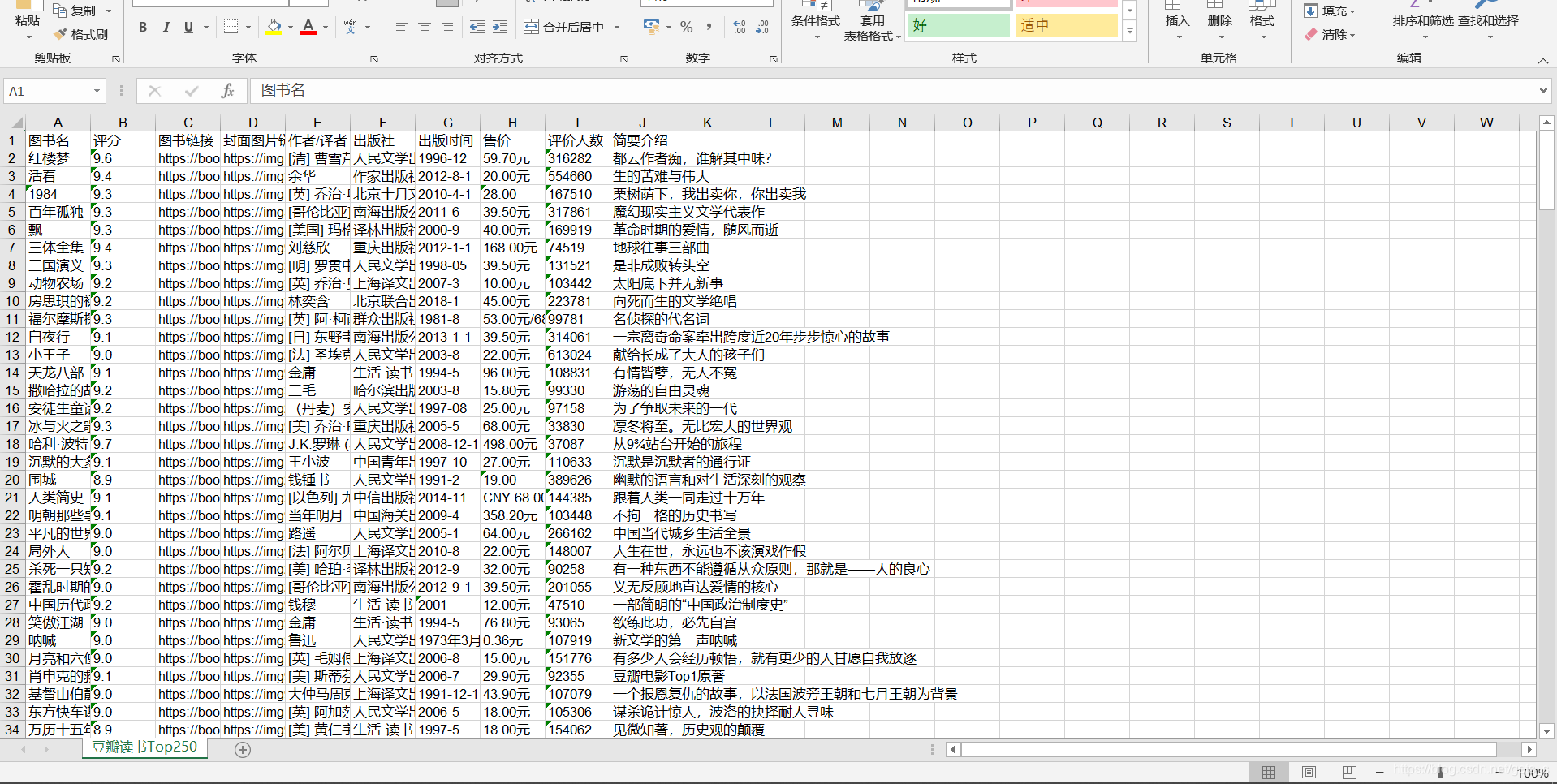

2) Import data into sqlist In the database 

边栏推荐
- RuntimeError: CUDA error: out of memory自己的解决方法(情况比较特殊估计对大部分人不适用)
- ROS查询话题具体内容常用指令
- DoS及攻擊方法詳解
- 清华&商汤&上海AI&CUHK提出Siamese Image Modeling,兼具linear probing和密集预测性能!
- How about opening a flush account? Is it safe? How to open a stock trading account
- ISO documents
- ZCMU--1367: Data Structure
- Handwritten promise all
- Plt How to keep show() not closed
- 让torch.cuda.is_available()从false变成true的一点经验
猜你喜欢
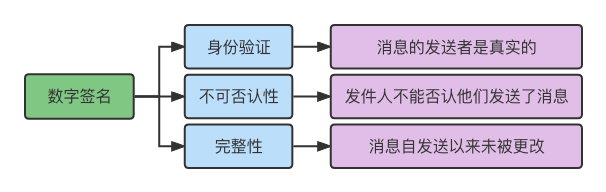
数字签名论述及生成与优点分析

transforms.RandomCrop()的输入只能是PIL image 不能是tensor

No manual prior is required! HKU & Tongji & lunarai & Kuangshi proposed self supervised visual representation learning based on semantic grouping, which significantly improved the tasks of target dete
你了解如何比较两个对象吗
IDEA收藏代码、快速打开favorites收藏窗口

MySQL download and configuration MySQL remote control

DoS及攻击方法详解
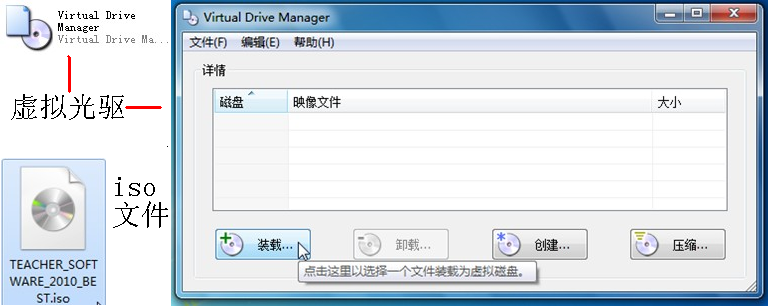
ISO文件

wm_concat()和group_concat()函数

Applet setting button sharing function
随机推荐
【QNX】命令
Solve the problem that each letter occupies a space in pycharm
in和exsits、count(*)查询优化
判断某个序列是否为栈的弹出序列
Concept and working principle of data encryption standard (DES)
DVD digital universal disc
ISO文件
Decision tree and random forest
JS cast
RSA加密解密详解
Idea collection code, quickly open favorites collection window
Detailed explanation of dos and attack methods
RSA概念详解及工具推荐大全 - lmn
Handwritten promise all
交叉编译环境出现.so链接文件找不到问题
JVM entry Door (1)
ZCMU--1367: Data Structure
Which securities company is better for a novice to open a stock trading account? How is it safer to speculate in stocks??
Analysis of deep security definition and encryption technology
LeetCode 128最长连续序列