当前位置:网站首页>Hash table, hash function, bloom filter, consistency hash
Hash table, hash function, bloom filter, consistency hash
2022-07-04 23:28:00 【wrdoct】
List of articles
Preface
Hashtable 、 hash function 、 The bloon filter 、 Consistent Hashing .
One 、 Hashtable 、 hash function
The data stored in the hash table is key,value Type of , Hash function is also known as hash function .
For classic hash functions , It has the following 5 Some properties :
1、 The input field is infinite
2、 The output field is exhausted
3、 The input is the same, and the output must be the same
4、 When the input is different, the output may also be the same ( Hash collision )
5、 Different inputs will be evenly distributed in the output field ( Hash property of hash function )
Hashtable hash table(key,value) It's actually very simple , Is to put Key Through a fixed algorithm function, it is called hash function Convert to a integer , Then put the number Remainder the length of the array , The remainder result is treated as an array Subscript , take value Stored under the number Array space in .
And when you use a hash table for a query , Is to make it again Use hash function to convert key Convert to the corresponding array subscript , And locate in the space to get value, In this way , You can make full use of Positioning of arrays Able to locate data .
【 notes 】key The design of should be There are many kinds of guarantees , Make the low frequency 、 Intermediate frequency 、 There are quantities of high frequencies , In this way, it can be done according to the nature of the hash function Divide equally .
【 notes 】 for example , We have a 10TB Large files of exist on the distributed file system , Deposit is 100 Billion lines of string , And the strings are arranged out of order , Now we will count the repeated strings in this file .
hypothesis , We can call 100 Machine to calculate the file . that , Now how do we count repeated strings through hash function .
First , We need to separate these 100 machines from 0-99 Mark the number , Then we read the file line by line in the distributed file system ( Multiple machines read in parallel ), Calculated by hash function hashcode, What will be calculated hashcode Moyi 100, According to the simulated value , Store the line in the corresponding machine .
According to the properties of hash function , It's easy for us to see , The same string will be stored in the same machine .
Then we can go parallel 100 Taiwan machine , Calculate the corresponding data respectively , Greatly accelerate the speed of Statistics .
Be careful : this 10TB Documents are not divided equally 100GB, among 100 Taiwan machine , It's this 10TB In file Types of different strings , Divide equally To 100 Of the machines . If the data processed by a single machine is too large , You can follow the same method , Parallel multiple processes in one machine , Processing data .
Two 、 The bloon filter
If you want to Judge whether an element is in a set , The general idea is to save all the elements , And then through comparison to determine . But still You can use a hash table , Through a Hash Function maps an element to a bit array (Bit array) A point in . thus , We just need to see if this point is 1 You can see if it's in the collection . This is the basic idea of bloon filter .
The bloon filter :k A hash function calculates k Hash values , after modulus Black tracing ( The corresponding bits in the array Set as 1), Judgment is still k A hash function takes modulus to make judgment , Only all black ( Is full of 1) It belongs to , If one is white, it doesn't belong to . therefore It is possible to judge white as black , But it is impossible to judge black as white .
Three formulas :
n = sample size ;
p = Error rate ;
m = Optimal bit group size ;
k = Hash Select the optimal number of functions ;
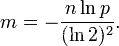
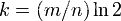
The algorithm mistakenly believes that a Originally not in the set The elements of It is detected as being in the set (False Positives), This probability ( Error rate p) Determined by the following formula :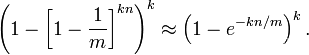
3、 ... and 、 Consistent Hashing
The above methods are Number of servers Take the mold , And the consistent hash algorithm is to 2^32 modulus .
Think of the 32nd power of two as a round , It's like a clock , The circle of a watch can be understood as being made by 60 A circle of points , And here we think of this circle as being made of 2^32 A circle of points , The schematic diagram is as follows :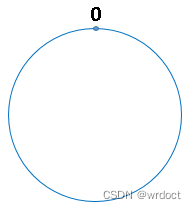
The point directly above the circle represents 0,0 The first point on the right represents 1, And so on ,2、3、4、5、6…… until 2^32-1 , in other words 0 The first point on the left represents 2^32-1.
We put this by 2 Of 32 A ring of points to the power of is called hash Ring .
After hashing the objects to be cached , Find the nearest one in the hash ring clockwise , As the home server of cache .
This is how the consistent hash algorithm works , Determine which server an object should be cached on , Map both the cache server and the cached object to hash On the ring in the future , Starting from the location of the cached object , The first server encountered in a clockwise direction , Is the server where the current object will be cached .
Because the cached object and the server hash The value after is fixed , therefore , With the server unchanged , An image must be cached on a fixed server .
that , The next time you want to access this image , Just use the same algorithm again , You can figure out which server this image is cached on , Go directly to the corresponding server to find the corresponding image .
边栏推荐
- Redis introduction complete tutorial: List explanation
- Observable time series data downsampling practice in Prometheus
- 45岁教授,她投出2个超级独角兽
- Jar batch management gadget
- After Microsoft disables the IE browser, open the IE browser to flash back the solution
- [graph theory] topological sorting
- Summary of wechat applet display style knowledge points
- 推荐收藏:跨云数据仓库(data warehouse)环境搭建,这货特别干!
- Tweenmax emoticon button JS special effect
- Paddleocr tutorial
猜你喜欢
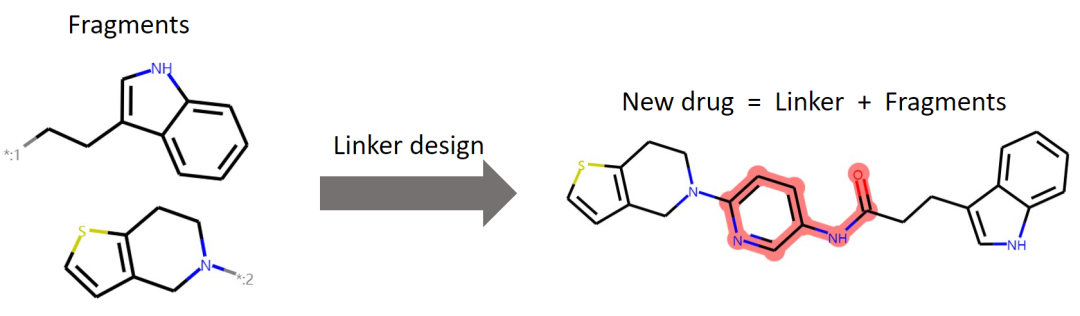
ICML 2022 | 3dlinker: e (3) equal variation self encoder for molecular link design
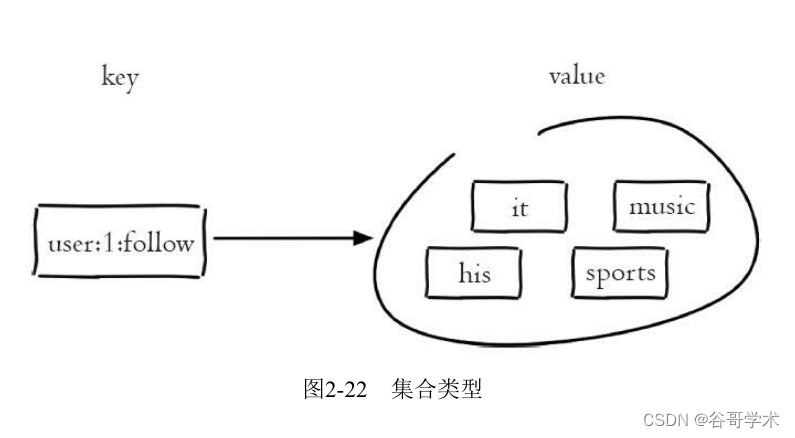
Redis introduction complete tutorial: Collection details

OSEK标准ISO_17356汇总介绍
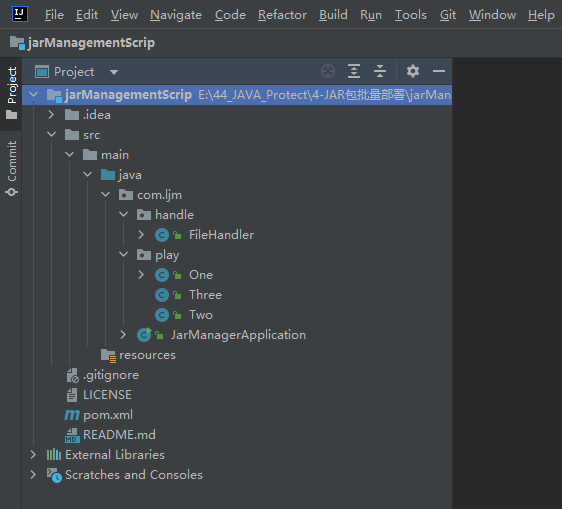
Jar batch management gadget
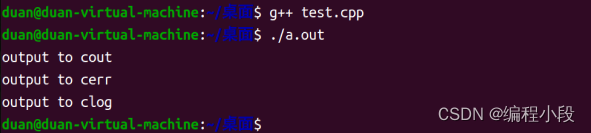
The difference between cout/cerr/clog
Redis: redis message publishing and subscription (understand)

MariaDB的Galera集群-双主双活安装设置

45 year old professor, she threw two super unicorns
Qualcomm WLAN framework learning (30) -- components supporting dual sta

Combien de temps faut - il pour obtenir un certificat PMP?
随机推荐
CTF competition problem solution STM32 reverse introduction
ScriptableObject
JS 3D explosive fragment image switching JS special effect
如何在外地外网电脑远程公司项目?
时间 (计算)总工具类 例子: 今年开始时间和今年结束时间等
A complete tutorial for getting started with redis: redis usage scenarios
[JS] - [sort related] - Notes
How to reduce the stock account Commission and stock speculation commission? Is it safe to open an online account
法国学者:最优传输理论下对抗攻击可解释性探讨
The input of uniapp is invalid except for numbers
Editplus-- usage -- shortcut key / configuration / background color / font size
Principle of lazy loading of pictures
MP advanced operation: time operation, SQL, querywapper, lambdaquerywapper (condition constructor) quick filter enumeration class
取得PMP證書需要多長時間?
[Taichi] change pbf2d (position based fluid simulation) of Taiji to pbf3d with minimal modification
快解析内网穿透帮助企业快速实现协同办公
[graph theory] topological sorting
Redis introduction complete tutorial: List explanation
MariaDB's Galera cluster application scenario -- multi master and multi active databases
HMS core unified scanning service