当前位置:网站首页>lnx 高效搜索引擎、FastDeploy 推理部署工具箱、AI前沿论文 | ShowMeAI资讯日报 #07.04
lnx 高效搜索引擎、FastDeploy 推理部署工具箱、AI前沿论文 | ShowMeAI资讯日报 #07.04
2022-07-04 14:04:00 【ShowMeAI】

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
{kind=link}
1.工具&框架

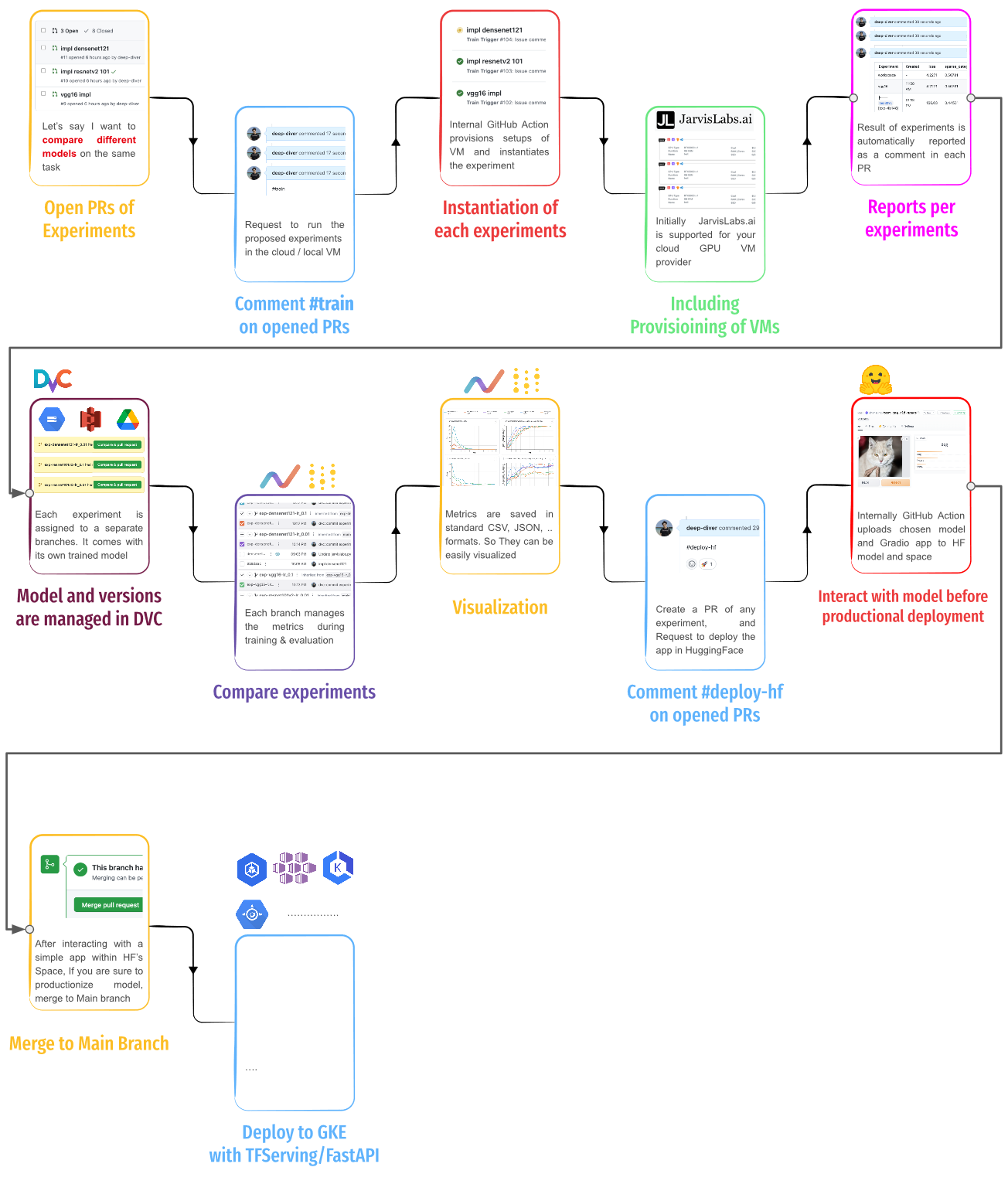
工具:Git Based MLOps:用Git / GitHub实现MLOps
这个项目展示了如何在 Git/GitHub 中实现 MLOps。 为了实现这一目标,该项目大量利用了 DVC、DVC Studio、DVCLive 等工具,并展示了构建的详细流程。所有产品均由 iterative.ai、Google Drive、Jarvislabs.ai 和 HuggingFace Hub 构建。
GitHub: https://github.com/codingpot/git-mlops
工具:lnx - Rust写的高效搜索引擎
lnx 的构建结合tokio-rs 、超 Web 框架与 tantivy 搜索引擎的原始计算能力,构成了高效的引擎系统。
这使得lnx能够同时对成千上万的文档插入进行毫秒级索引(不再等待事情被索引!)每个索引事务和处理搜索的能力,就像它只是哈希表上的另一个查找一样
GitHub: https://github.com/lnx-search/lnx
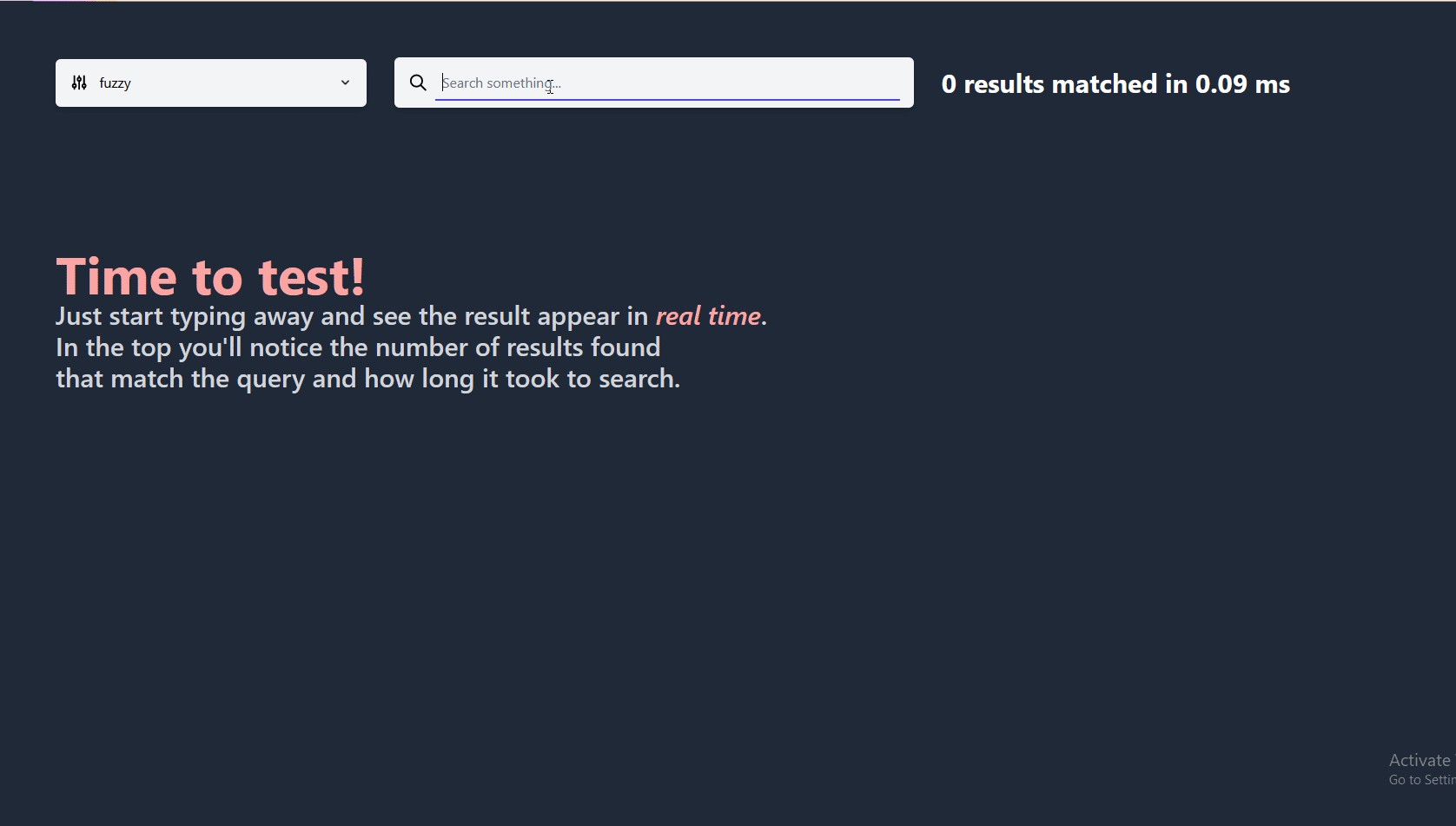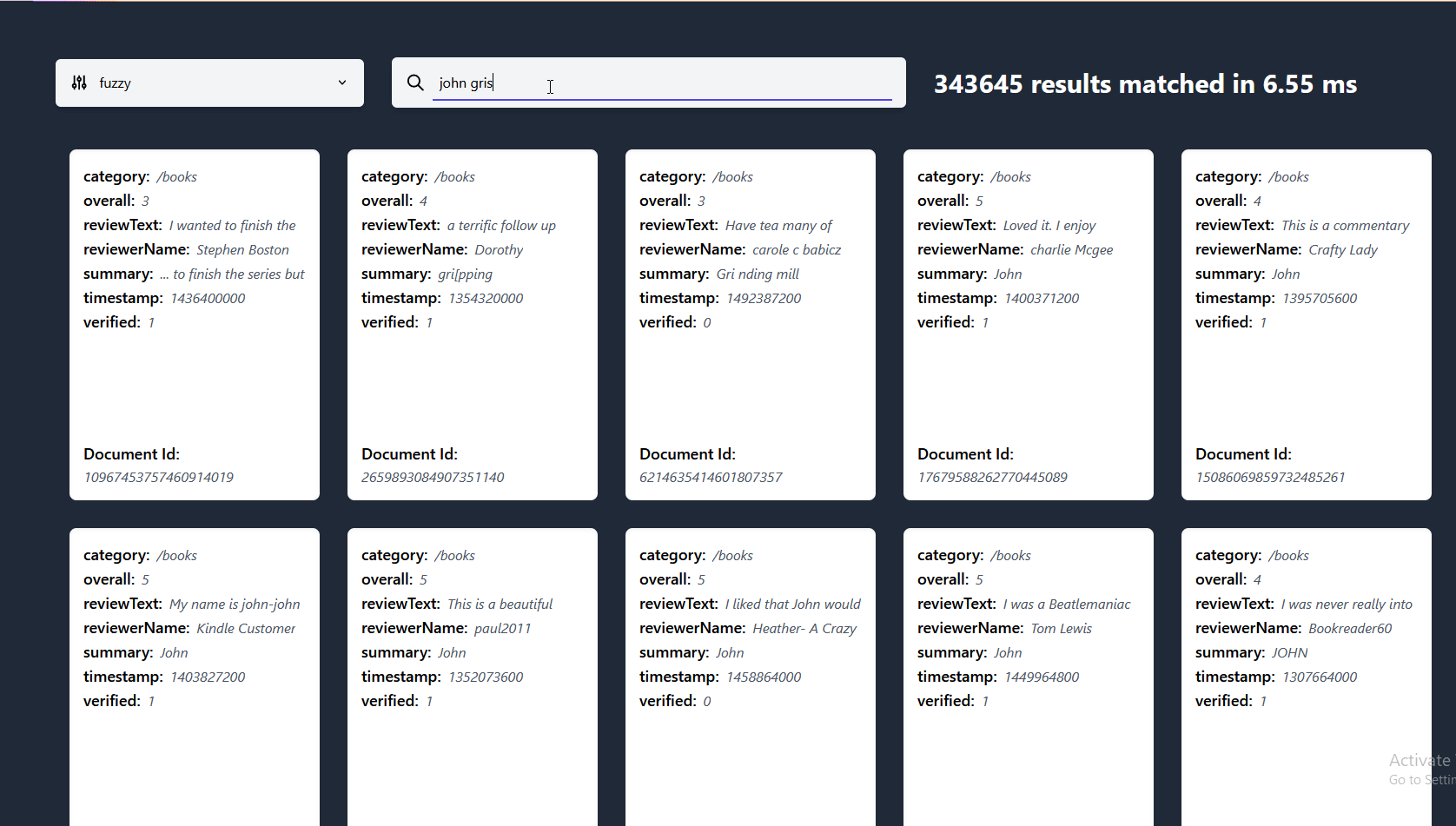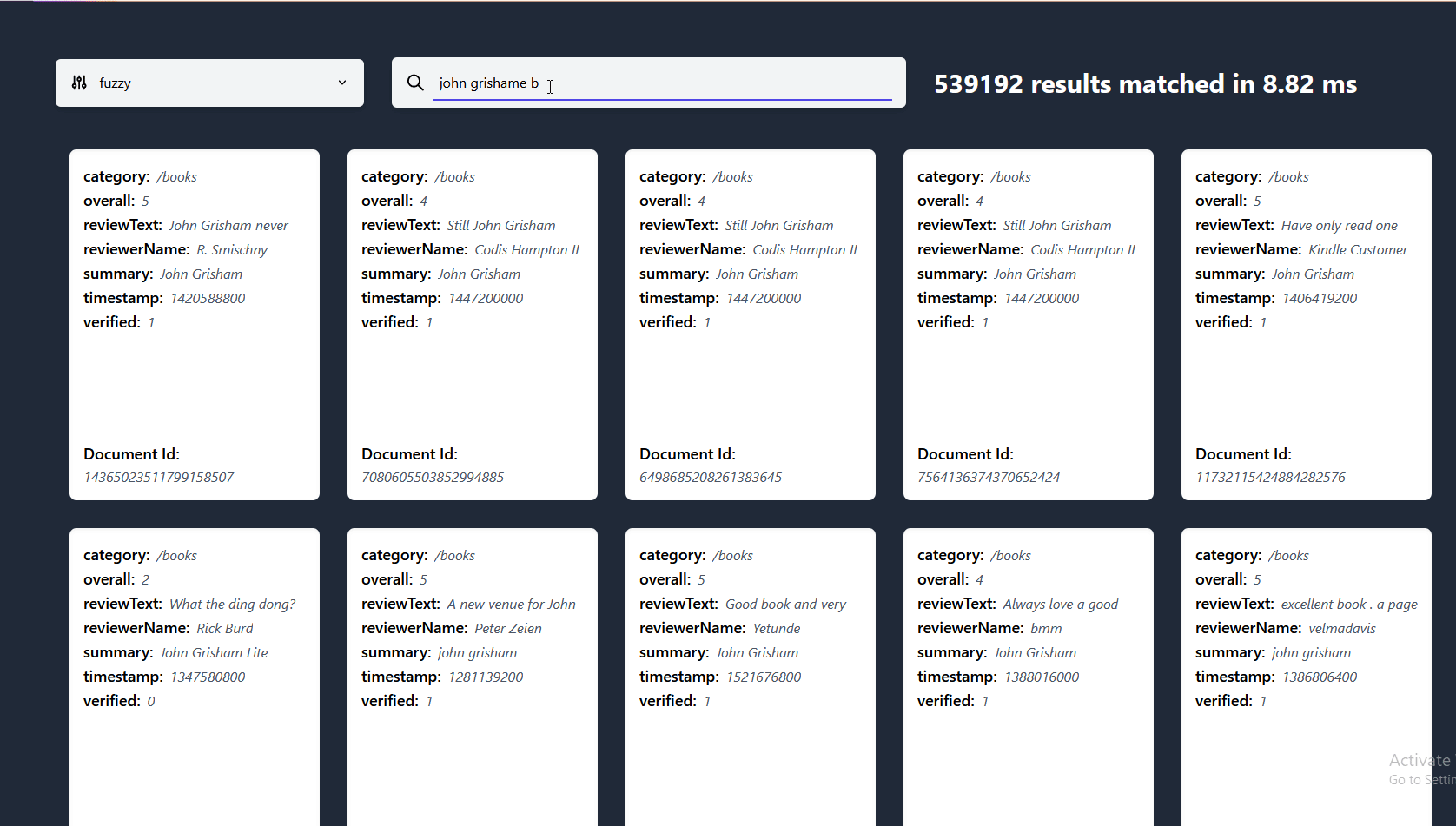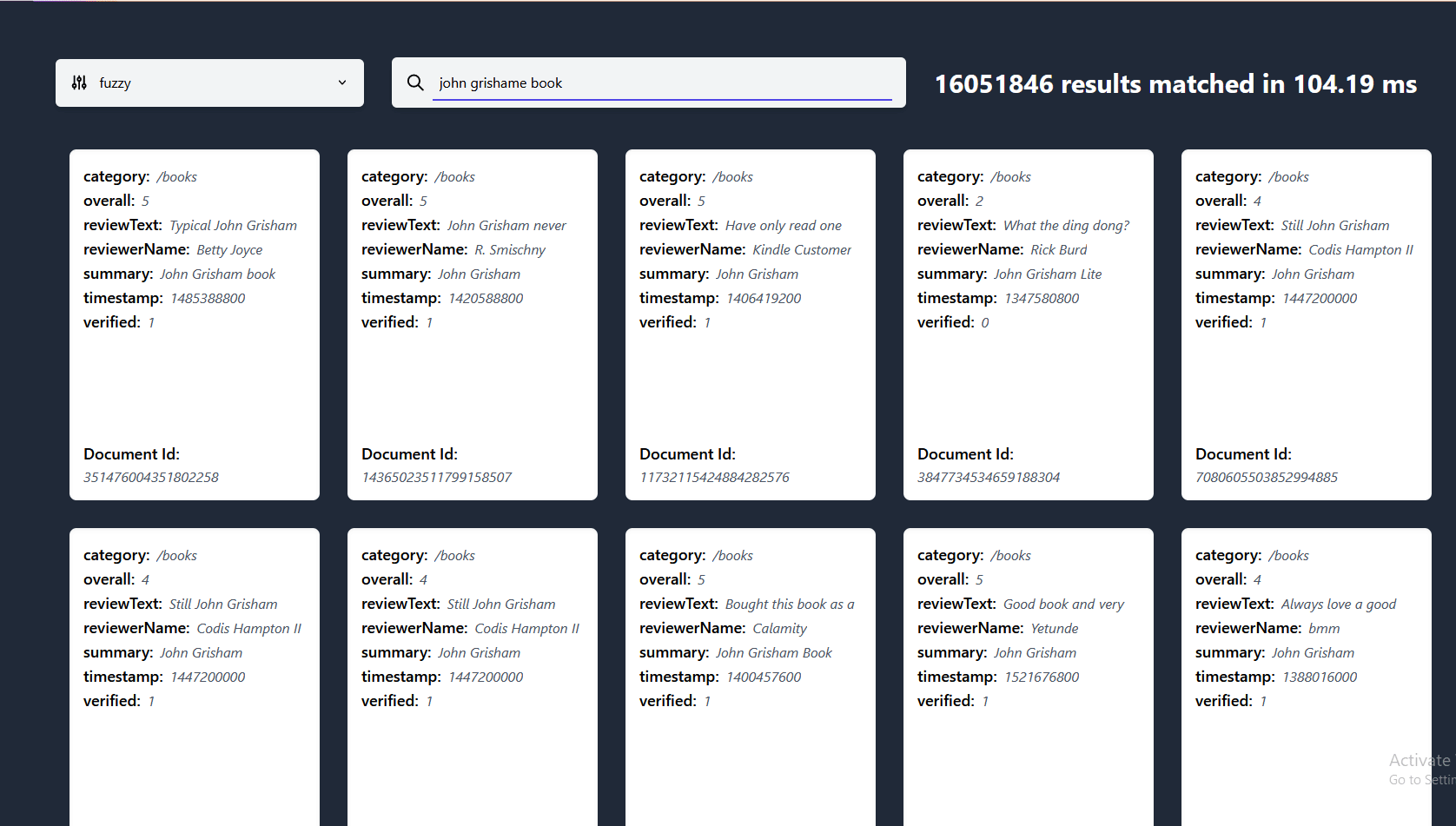
工具:FastDeploy - 简单易用的推理部署工具箱
覆盖业界主流优质预训练模型并提供开箱即用的开发体验,包括图像分类、目标检测、图像分割、人脸检测、人体关键点识别、文字识别等多任务,满足开发者多场景,多硬件、多平台的快速部署需求。
GitHub: https://github.com/PaddlePaddle/FastDeploy

工具系统:HETU - 面向大规模自动化分布式训练的高性能分布式深度学习系统
HETU 河图 是北京大学 DAIR 实验室开发的针对万亿参数深度学习模型训练的高性能分布式深度学习系统。它既考虑了工业的高可用性,也考虑了学术界的创新,具有适用性、高效率、灵活性、敏捷性等许多先进的特点。
GitHub: https://github.com/Hsword/Hetu

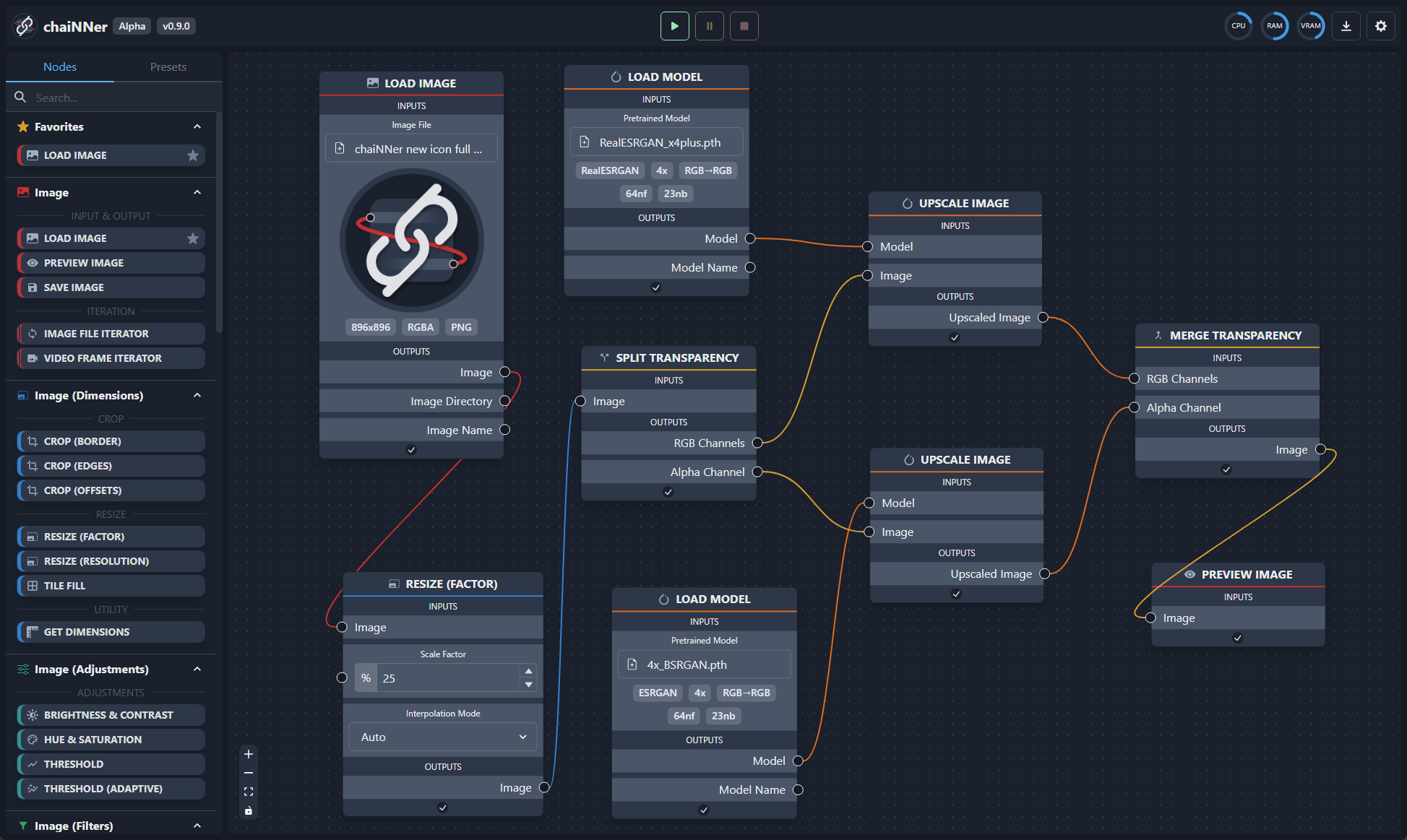
工具:chaiNNer - 基于流程图/节点的图像处理 GUI
一种基于流程图 / 节点的图像处理图形用户界面(GUI),旨在使链接图像处理任务(特别是由神经网络完成的任务)变得简单、直观和可定制。
没有任何现有的升级GUI能够像Chainer那样为您的图像处理工作流提供定制级别。不仅可以完全控制处理管道,还可以通过将几个节点连接在一起来完成极其复杂的任务。
GitHub: https://github.com/joeyballentine/chaiNNer
2.博文&分享

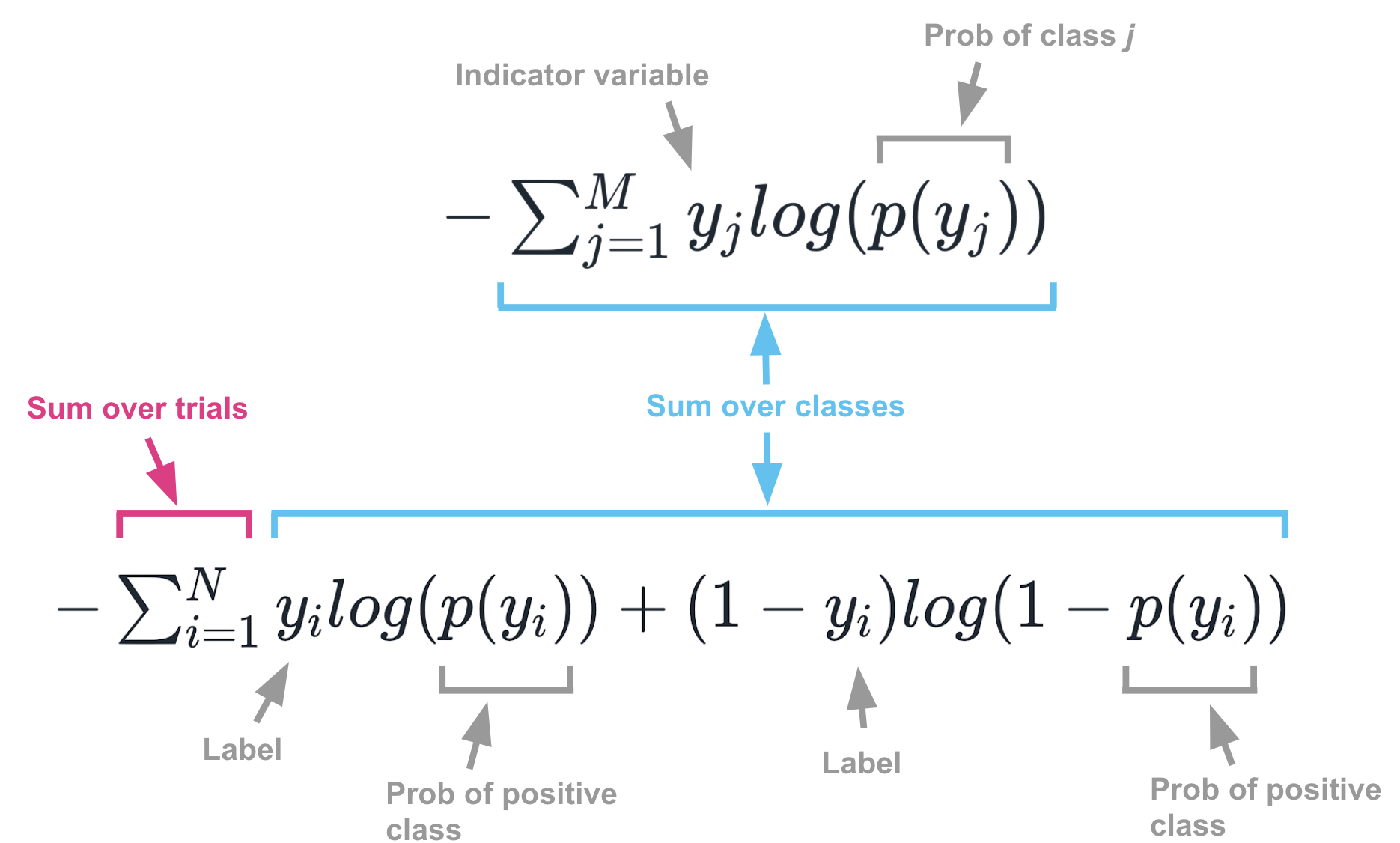
博文:交叉熵解惑
《Things that confused me about cross-entropy》by Chris Said
地址: https://chris-said.io/2020/12/26/two-things-that-confused-me-about-cross-entropy
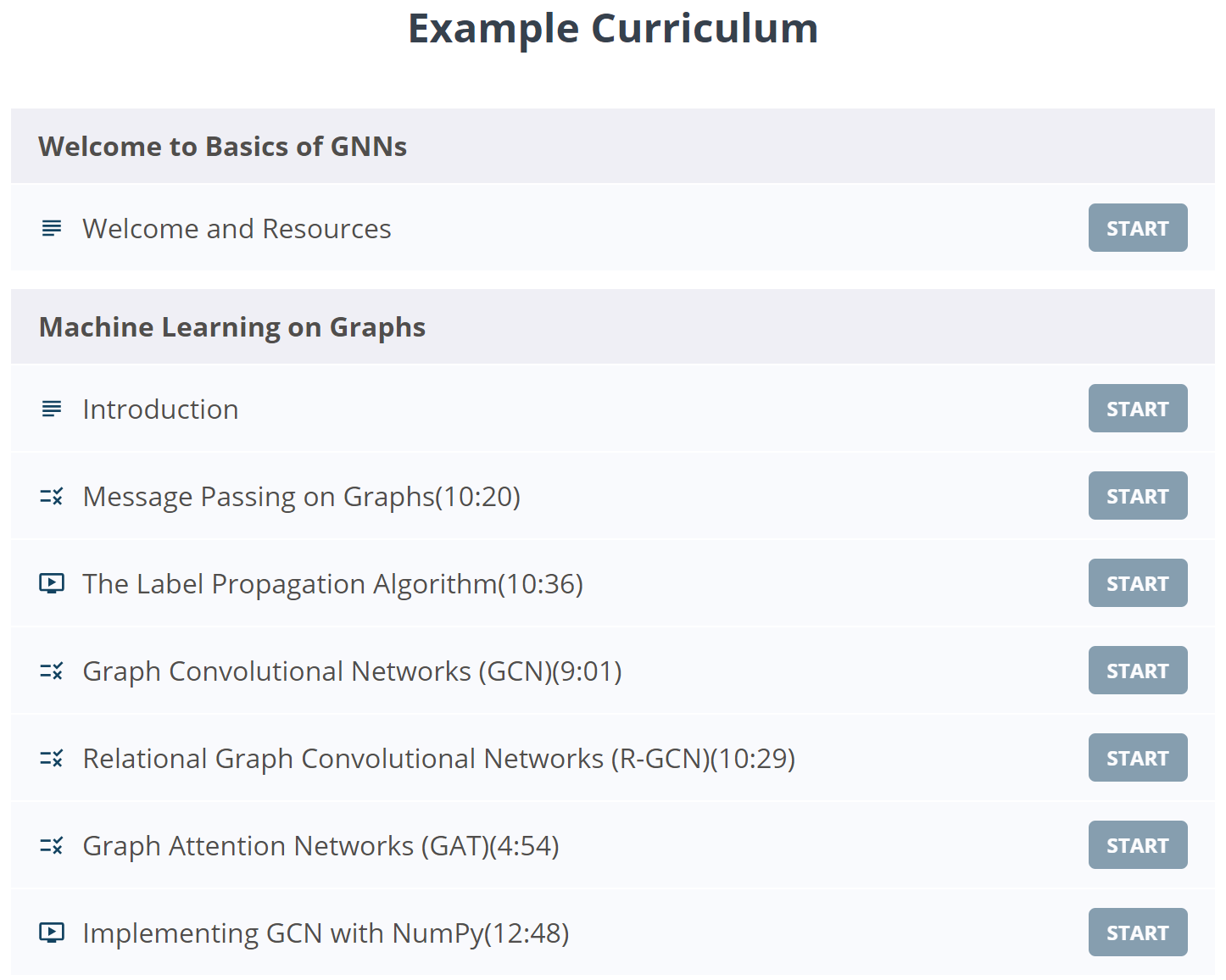
课程:《图神经网络基础》公开课
《Basics of Graph Neural Networks | Welcome AI Overlords》by Zak Jost
本课程是关于图机器学习的快速浏览,介绍消息传递的基本概念并解释核心算法(如标签传播、图卷积网络和图注意网络),并展示如何仅使用 NumPy 从头开始实现图卷积网络。
地址: https://www.graphneuralnets.com/p//basics-of-gnns/
 |  |
3.数据&资源

资源列表:专家混合相关文献资源列表
这个 repo 是关于 混合专家 (awesome mixture of experts)的精彩内容集合,包括论文、代码等。
GitHub: https://github.com/XueFuzhao/awesome-mixture-of-experts
4.研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
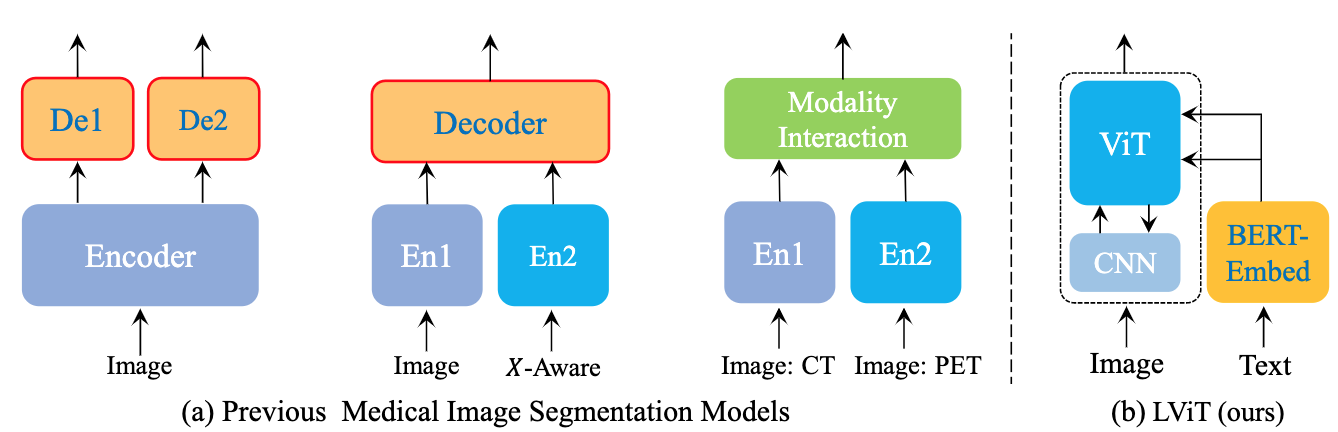
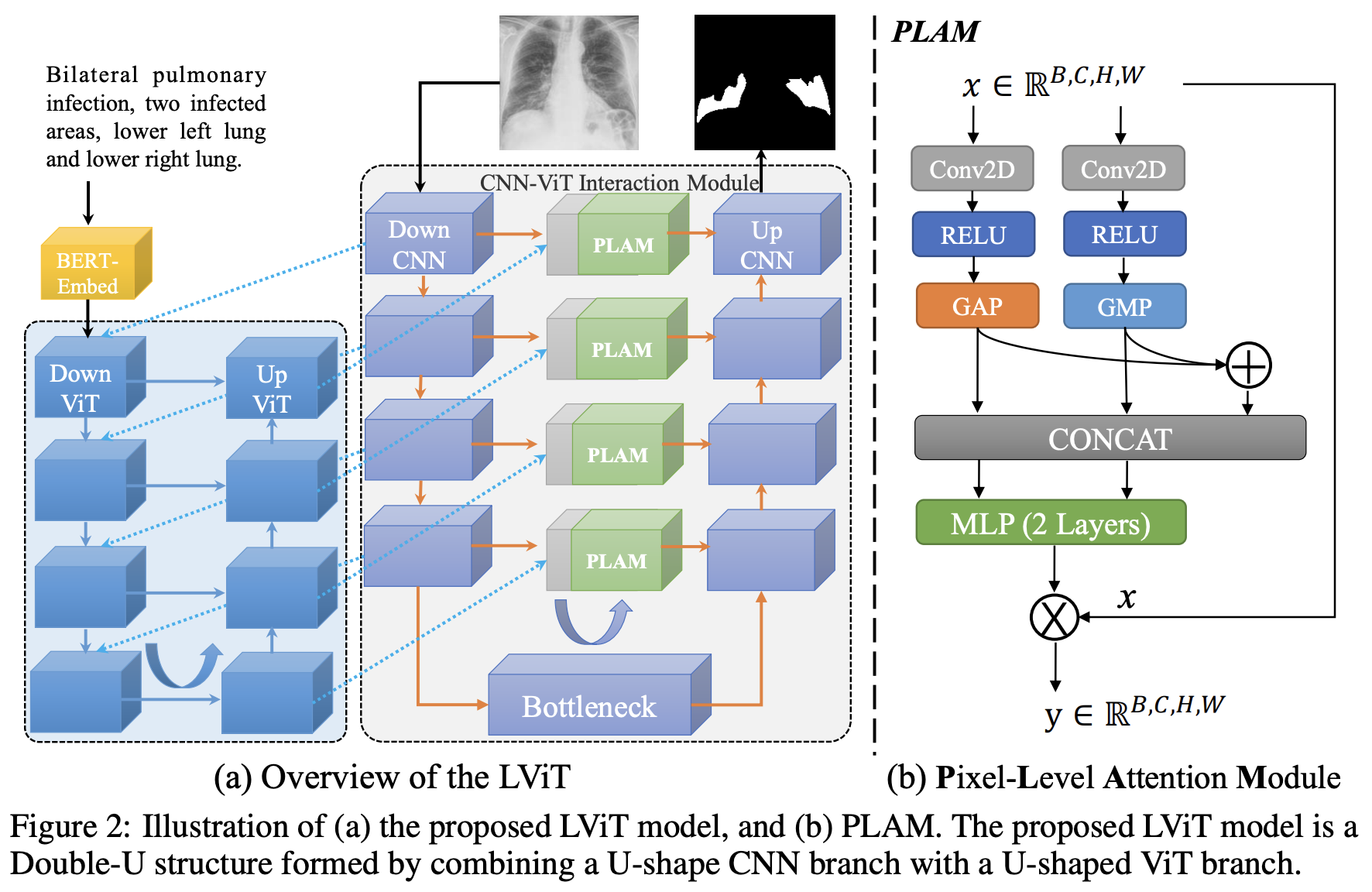
论文:LViT: Language meets Vision Transformer in Medical Image Segmentation
论文标题:LViT: Language meets Vision Transformer in Medical Image Segmentation
论文时间:29 Jun 2022
所属领域:医疗
对应任务:Medical Image Segmentation,Semantic Segmentation,医疗影像分割,语义分割
论文地址:https://arxiv.org/abs/2206.14718
代码实现:https://github.com/huanglizi/lvit
论文作者:Zihan Li, Yunxiang Li, Qingde Li, You Zhang, Puyang Wang, Dazhou Guo, Le Lu, Dakai Jin, Qingqi Hong
论文简介:In our model, medical text annotation is introduced to compensate for the quality deficiency in image data./在我们的模型中,引入了医学文本注释来弥补图像数据的质量缺陷。
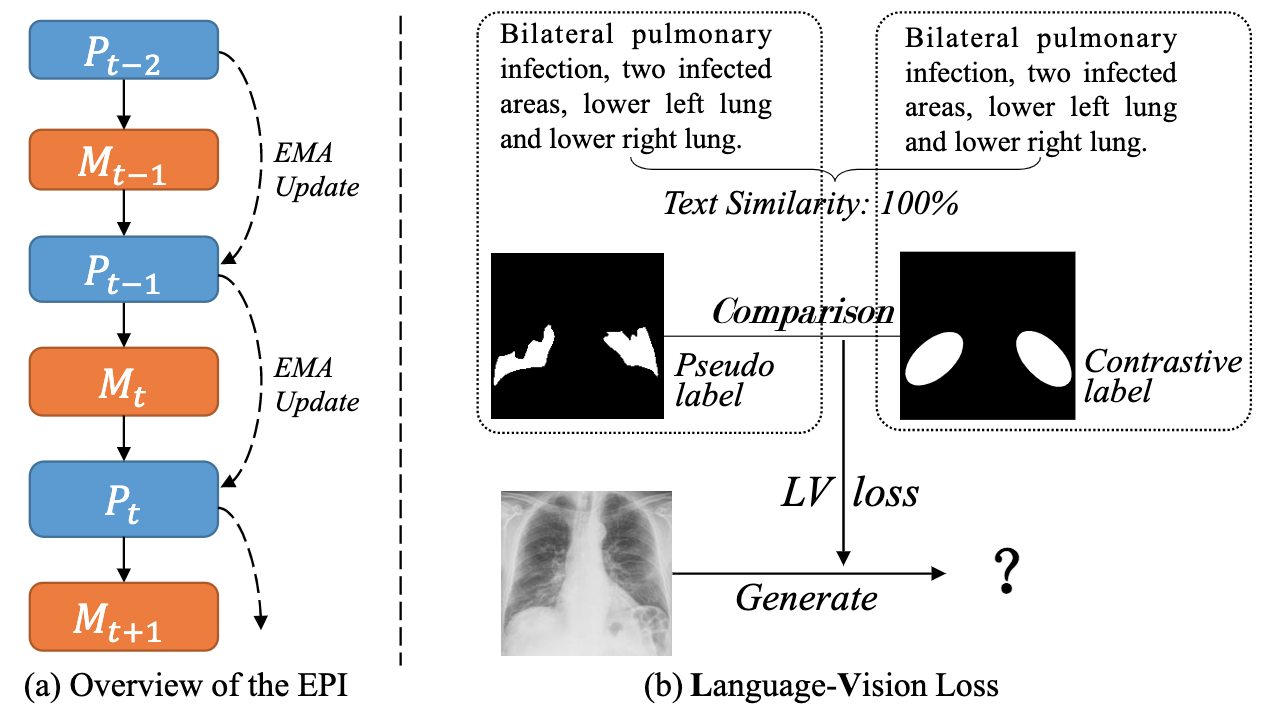
论文摘要:Deep learning has been widely used in medical image segmentation and other aspects. However, the performance of existing medical image segmentation models has been limited by the challenge of obtaining sufficient number of high-quality data with the high cost of data annotation. To overcome the limitation, we propose a new vision-language medical image segmentation model LViT (Language meets Vision Transformer). In our model, medical text annotation is introduced to compensate for the quality deficiency in image data. In addition, the text information can guide the generation of pseudo labels to a certain extent and further guarantee the quality of pseudo labels in semi-supervised learning. We also propose the Exponential Pseudo label Iteration mechanism (EPI) to help extend the semi-supervised version of LViT and the Pixel-Level Attention Module (PLAM) to preserve local features of images. In our model, LV (Language-Vision) loss is designed to supervise the training of unlabeled images using text information directly. To validate the performance of LViT, we construct multimodal medical segmentation datasets (image + text) containing pathological images, X-rays,etc. Experimental results show that our proposed LViT has better segmentation performance in both fully and semi-supervised conditions. Code and datasets are available at https://github.com/huanglizi/lvit
深度学习已经被广泛地应用于医学图像分割和其他方面。然而,现有的医学图像分割模型的性能受到了挑战,主要受限于需要足够数量的高质量数据和高成本的数据注释。为了克服这一限制,我们提出了一个新的视觉语言医学图像分割模型LViT(Language meets Vision Transformer)。在我们的模型中,引入了医学文本注释来弥补图像数据的质量缺陷。此外,文本信息可以在一定程度上指导伪标签的生成,进一步保证半监督学习中伪标签的质量。我们还提出了指数伪标签迭代机制(EPI)来帮助扩展半监督版本的LViT和像素级注意模块(PLAM),以保留图像的局部特征。在我们的模型中,LV(Language-Vision)损失被设计用来监督直接使用文本信息的无标签图像的训练。为了验证LViT的性能,我们构建了多模态医学分割数据集(图像+文本),包含病理图像、X射线等。实验结果表明,我们提出的LViT在完全和半监督条件下都有更好的分割性能。代码和数据集可在 https://github.com/huanglizi/lvit 获取。
论文:VLCap: Vision-Language with Contrastive Learning for Coherent Video Paragraph Captioning
论文标题:VLCap: Vision-Language with Contrastive Learning for Coherent Video Paragraph Captioning
论文时间:26 Jun 2022
所属领域:计算机视觉
对应任务:Contrastive Learning,Video Captioning,对比学习,视频字幕
论文地址:https://arxiv.org/abs/2206.12972
代码实现:https://github.com/UARK-AICV/VLCAP
论文作者:Kashu Yamazaki, Sang Truong, Khoa Vo, Michael Kidd, Chase Rainwater, Khoa Luu, Ngan Le
论文简介:In this paper, we leverage the human perceiving process, that involves vision and language interaction, to generate a coherent paragraph description of untrimmed videos./在本文中,我们利用人类的感知过程,包括视觉和语言的互动,对未修剪的视频产生一个连贯的段落描述。
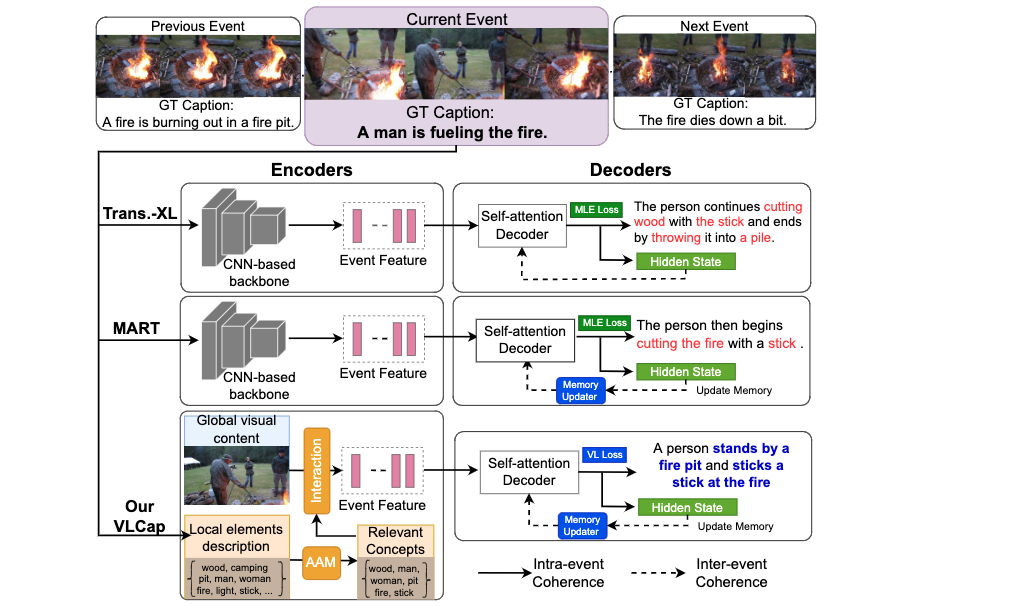
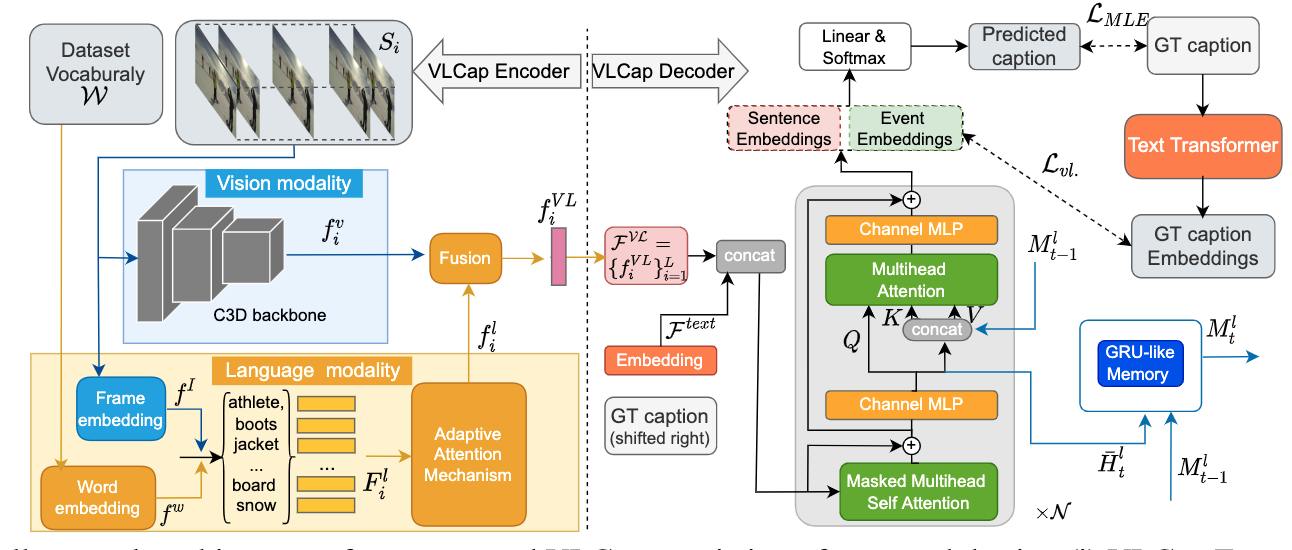
论文摘要:In this paper, we leverage the human perceiving process, that involves vision and language interaction, to generate a coherent paragraph description of untrimmed videos. We propose vision-language (VL) features consisting of two modalities, i.e., (i) vision modality to capture global visual content of the entire scene and (ii) language modality to extract scene elements description of both human and non-human objects (e.g. animals, vehicles, etc), visual and non-visual elements (e.g. relations, activities, etc). Furthermore, we propose to train our proposed VLCap under a contrastive learning VL loss. The experiments and ablation studies on ActivityNet Captions and YouCookII datasets show that our VLCap outperforms existing SOTA methods on both accuracy and diversity metrics.
在本文中,我们利用人类的感知过程,包括视觉和语言的互动,来生成未修剪视频的连贯段落描述。我们提出了由两种模式组成的视觉-语言(VL)特征,即:(1)视觉模式捕捉整个场景的整体视觉内容;(2)语言模式提取人类和非人类物体(如动物、车辆等)、视觉和非视觉元素(如关系、活动等)的场景要素描述。此外,我们建议在对比学习VL损失下训练我们提出的VLCap。对ActivityNet Captions和YouCookII数据集的实验和消融研究表明,我们的VLCap在准确性和多样性指标上都优于现有的SOTA方法。
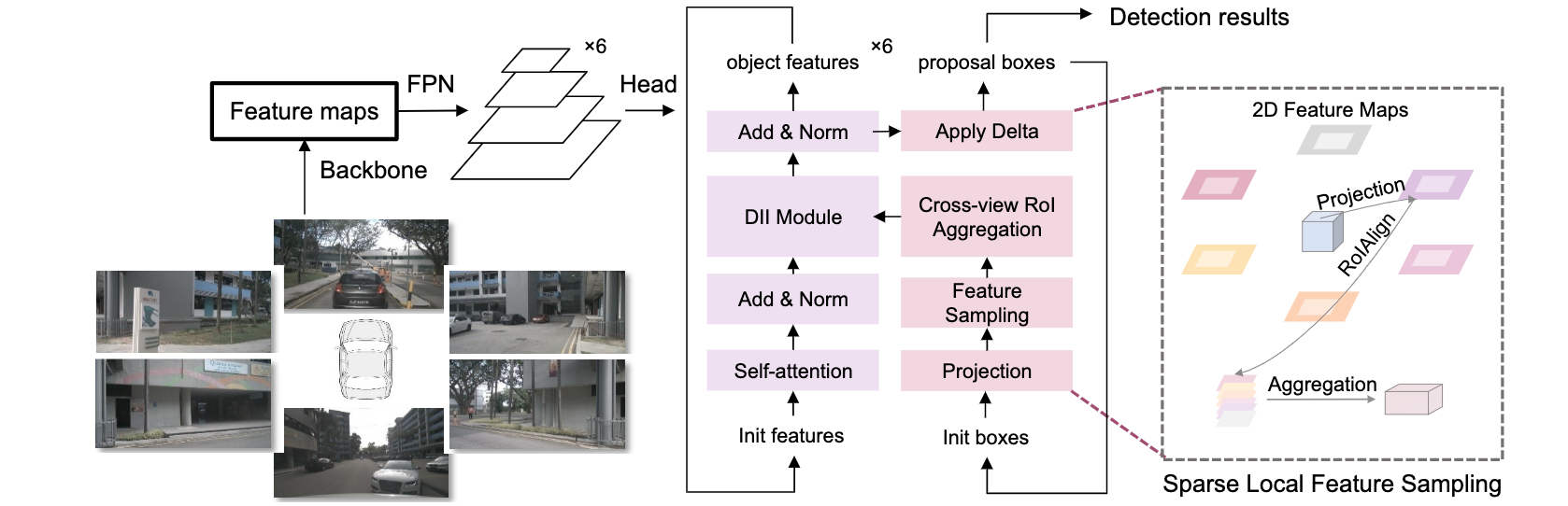
论文:SRCN3D: Sparse R-CNN 3D Surround-View Camera Object Detection and Tracking for Autonomous Driving
论文标题:SRCN3D: Sparse R-CNN 3D Surround-View Camera Object Detection and Tracking for Autonomous Driving
论文时间:29 Jun 2022
所属领域:计算机视觉
对应任务:3D Multi-Object Tracking,Autonomous Driving,Multi-Object Tracking,object-detection,Object Detection,Object Tracking,三维多目标追踪,自主驾驶,多目标追踪,目标探测,目标检测,目标追踪
论文地址:https://arxiv.org/abs/2206.14451
代码实现:https://github.com/synsin0/srcn3d
论文作者:Yining Shi, Jingyan Shen, Yifan Sun, Yunlong Wang, Jiaxin Li, Shiqi Sun, Kun Jiang, Diange Yang
论文简介:This paper proposes Sparse R-CNN 3D (SRCN3D), a novel two-stage fully-convolutional mapping pipeline for surround-view camera detection and tracking./本文提出了稀疏R-CNN 3D(SRCN3D),这是一种新型的两阶段完全卷积映射管道,用于环视摄像头的检测和跟踪。
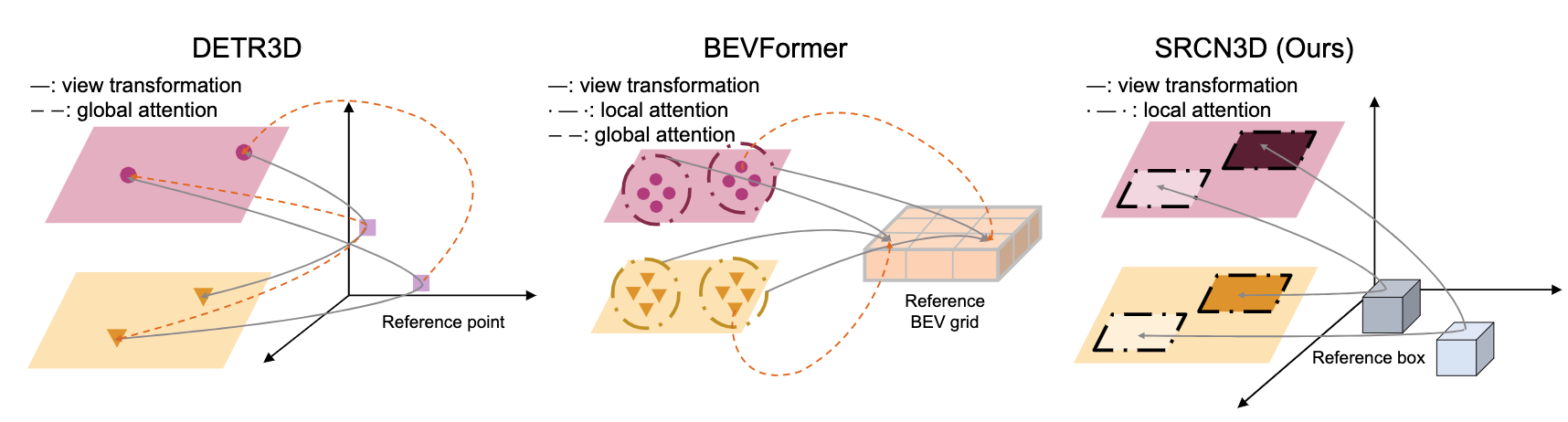
论文摘要:Detection And Tracking of Moving Objects (DATMO) is an essential component in environmental perception for autonomous driving. While 3D detectors using surround-view cameras are just flourishing, there is a growing tendency of using different transformer-based methods to learn queries in 3D space from 2D feature maps of perspective view. This paper proposes Sparse R-CNN 3D (SRCN3D), a novel two-stage fully-convolutional mapping pipeline for surround-view camera detection and tracking. SRCN3D adopts a cascade structure with twin-track update of both fixed number of proposal boxes and proposal latent features. Proposal boxes are projected to perspective view so as to aggregate Region of Interest (RoI) local features. Based on that, proposal features are refined via a dynamic instance interactive head, which then generates classification and the offsets applied to original bounding boxes. Compared to prior arts, our sparse feature sampling module only utilizes local 2D features for adjustment of each corresponding 3D proposal box, leading to a complete sparse paradigm. The proposal features and appearance features are both taken in data association process in a multi-hypotheses 3D multi-object tracking approach. Extensive experiments on nuScenes dataset demonstrate the effectiveness of our proposed SRCN3D detector and tracker. Code is available at https://github.com/synsin0/srcn3d
移动物体的检测和跟踪(DATMO)是自动驾驶环境感知的一个重要组成部分。虽然使用环视摄像机的三维检测器刚刚兴起,但使用不同的基于变换器的方法从透视的二维特征图中学习三维空间的查询的趋势越来越强。本文提出了稀疏R-CNN 3D(SRCN3D),这是一个新颖的两阶段全卷积映射管道,用于环视摄像头检测和跟踪。SRCN3D采用了一个级联结构,对固定数量的候选框和候选潜在特征进行双轨更新。候选框被投射到透视图中,以聚集感兴趣区域(RoI)的局部特征。在此基础上,通过一个动态的实例交互头来完善建议特征,然后产生分类和应用于原始边界框的偏移。与之前的艺术相比,我们的稀疏特征采样模块只利用局部二维特征来调整每个相应的三维提议框,从而形成一个完整的稀疏范式。在一个多假设的三维多物体跟踪方法中,建议特征和外观特征都是在数据关联过程中采取的。在nuScenes数据集上的大量实验证明了我们提出的SRCN3D检测器和跟踪器的有效性。代码可在 https://github.com/synsin0/srcn3d 查看。
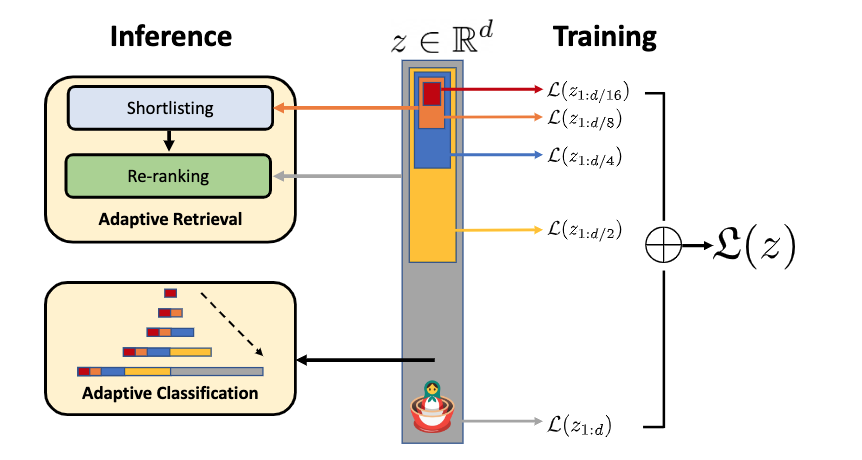
论文:Matryoshka Representations for Adaptive Deployment
论文标题:Matryoshka Representations for Adaptive Deployment
论文时间:26 May 2022
所属领域:机器学习
对应任务:Representation Learning,表征学习
论文地址:https://arxiv.org/abs/2205.13147
代码实现:https://github.com/raivnlab/mrl
论文作者:Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, KaiFeng Chen, Sham Kakade, Prateek Jain, Ali Farhadi
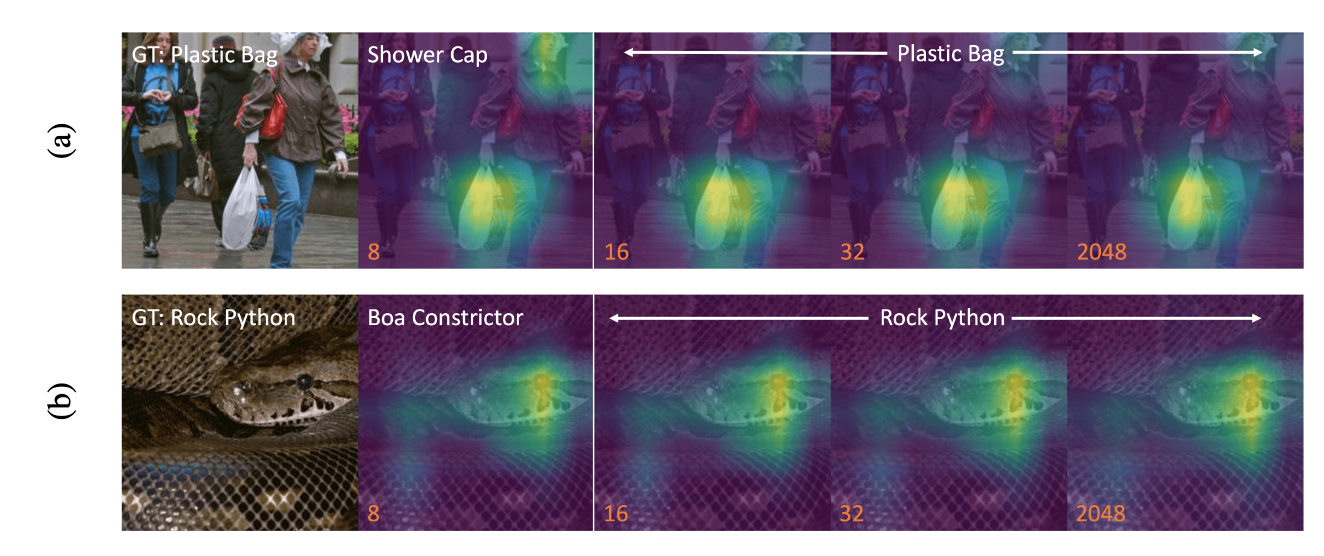
论文简介:The flexibility within the learned Matryoshka Representations offer: (a) up to 14x smaller embedding size for ImageNet-1K classification at the same level of accuracy; (b) up to 14x real-world speed-ups for large-scale retrieval on ImageNet-1K and 4K; and up to 2% accuracy improvements for long-tail few-shot classification, all while being as robust as the original representations./学习到的Matryoshka表示法的灵活性提供了:(a) 在相同的准确度下,ImageNet-1K分类的嵌入大小减少了14倍;(b) ImageNet-1K和4K的大规模检索的实际速度提高了14倍;以及 长尾的少数照片分类的准确度提高了2%,而所有这些都与原始表示法一样强大。
论文摘要:Learned representations are a central component in modern ML systems, serving a multitude of downstream tasks. When training such representations, it is often the case that computational and statistical constraints for each downstream task are unknown. In this context rigid, fixed capacity representations can be either over or under-accommodating to the task at hand. This leads us to ask: can we design a flexible representation that can adapt to multiple downstream tasks with varying computational resources? Our main contribution is Matryoshka Representation Learning (MRL) which encodes information at different granularities and allows a single embedding to adapt to the computational constraints of downstream tasks. MRL minimally modifies existing representation learning pipelines and imposes no additional cost during inference and deployment. MRL learns coarse-to-fine representations that are at least as accurate and rich as independently trained low-dimensional representations. The flexibility within the learned Matryoshka Representations offer: (a) up to 14x smaller embedding size for ImageNet-1K classification at the same level of accuracy; (b) up to 14x real-world speed-ups for large-scale retrieval on ImageNet-1K and 4K; and up to 2% accuracy improvements for long-tail few-shot classification, all while being as robust as the original representations. Finally, we show that MRL extends seamlessly to web-scale datasets (ImageNet, JFT) across various modalities – vision (ViT, ResNet), vision + language (ALIGN) and language (BERT). MRL code and pretrained models are open-sourced at https://github.com/raivnlab/mrl
表征学习是现代ML系统的核心组成部分,为众多的下游任务服务。在训练这种表征时,通常情况下,每个下游任务的计算和统计约束是未知的。在这种情况下,僵化的、固定容量的表征对手头的任务来说,可能有过度适应或不适应的问题。继而引导我们思考:能否设计一个灵活的表示,以适应具有不同计算资源的多个下游任务?我们的主要贡献是Matryoshka表征学习(MRL),它在不同的粒度上对信息进行编码,并允许单一的嵌入来适应下游任务的计算限制。MRL最大限度地修改了现有的表征学习管道,并且在推理和部署过程中不产生额外的成本。MRL学习的从粗到细的表征,至少与独立训练的低维表征一样准确和丰富。学习到的Matryoshka表征中的灵活性提供了:(a)在相同的准确度下,ImageNet-1K分类的嵌入尺寸最多减少14倍;(b)在ImageNet-1K和4K的大规模检索中,实际速度最多增加14倍;以及(c)在长尾少数照片分类中,准确度最多提高2%,同时与原始表征一样强大。最后,我们表明,MRL可以无缝地扩展到网络规模的数据集(ImageNet,JFT),跨越各种模式–视觉(ViT,ResNet),视觉+语言(ALIGN)和语言(BERT)。MRL的代码和预训练模型已在 https://github.com/raivnlab/mrl 发布。
论文:Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
论文标题:Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
论文时间:CVPR 2022
所属领域:计算机视觉
对应任务:Denoising,Image Generation,Representation Learning,降噪,图像生成,表征学习
论文地址:https://arxiv.org/abs/2111.15640
代码实现:https://github.com/phizaz/diffae
论文作者:Konpat Preechakul, Nattanat Chatthee, Suttisak Wizadwongsa, Supasorn Suwajanakorn
论文简介:Our key idea is to use a learnable encoder for discovering the high-level semantics, and a DPM as the decoder for modeling the remaining stochastic variations./我们的关键想法是使用可学习的编码器来发现高级语义,并使用DPM作为解码器来模拟其余的随机变化。
论文摘要:Diffusion probabilistic models (DPMs) have achieved remarkable quality in image generation that rivals GANs’. But unlike GANs, DPMs use a set of latent variables that lack semantic meaning and cannot serve as a useful representation for other tasks. This paper explores the possibility of using DPMs for representation learning and seeks to extract a meaningful and decodable representation of an input image via autoencoding. Our key idea is to use a learnable encoder for discovering the high-level semantics, and a DPM as the decoder for modeling the remaining stochastic variations. Our method can encode any image into a two-part latent code, where the first part is semantically meaningful and linear, and the second part captures stochastic details, allowing near-exact reconstruction. This capability enables challenging applications that currently foil GAN-based methods, such as attribute manipulation on real images. We also show that this two-level encoding improves denoising efficiency and naturally facilitates various downstream tasks including few-shot conditional sampling. Please visit our project page: https://diff-ae.github.io/
扩散概率模型(DPMs)在图像生成方面取得了显著的质量,可以与GANs相媲美。但与GANs不同的是,DPMs使用一组缺乏语义的潜在变量,不能作为其他任务的有用表示。本文探讨了使用DPMs进行表征学习的可能性,并试图通过自动编码提取输入图像的有意义和可解读的表征。我们的关键想法是使用一个可学习的编码器来发现高级语义,并使用DPM作为解码器来模拟其余的随机变化。我们的方法可以将任何图像编码成两部分的潜伏代码,其中第一部分是有语义的和线性的,第二部分捕捉随机细节,允许近乎精确的重建。这种能力使目前以GAN为基础的方法受到限制的挑战性应用成为可能,例如真实图像上的属性操作。我们还表明,这种两级编码提高了去噪效率,并自然地促进了各种下游任务,包括少样本条件生成。请访问我们的项目页面:https://diff-ae.github.io/



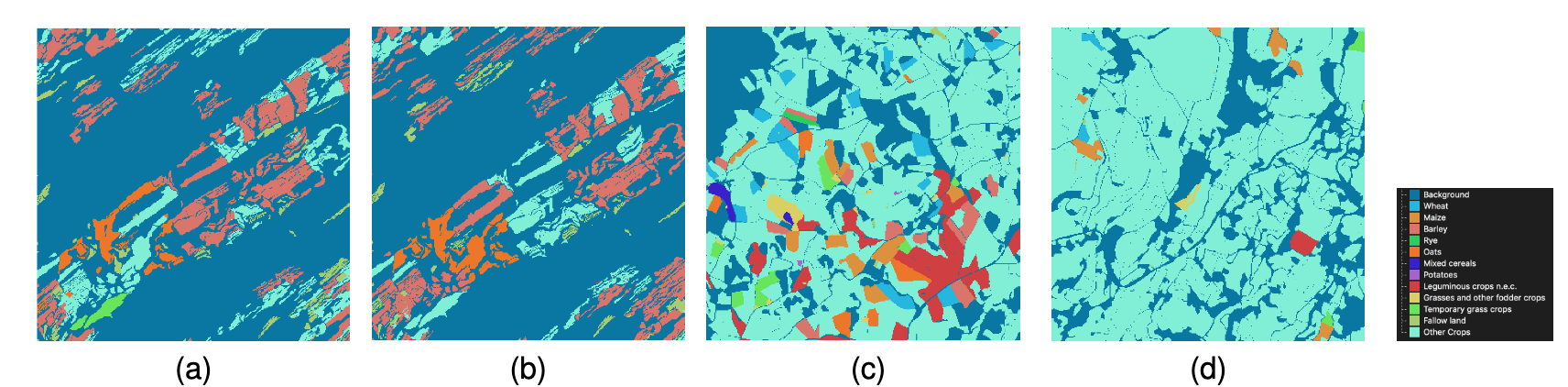
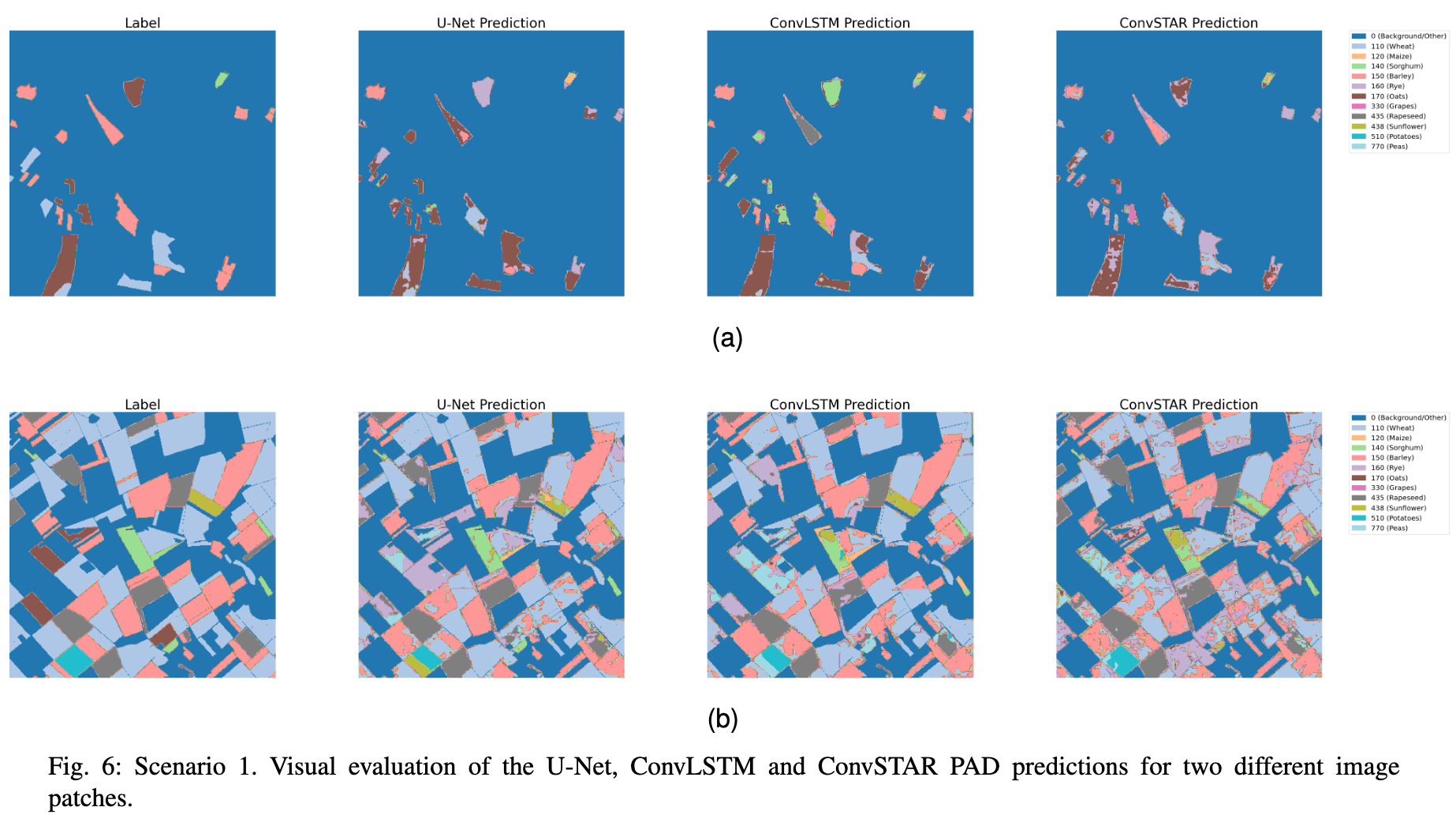
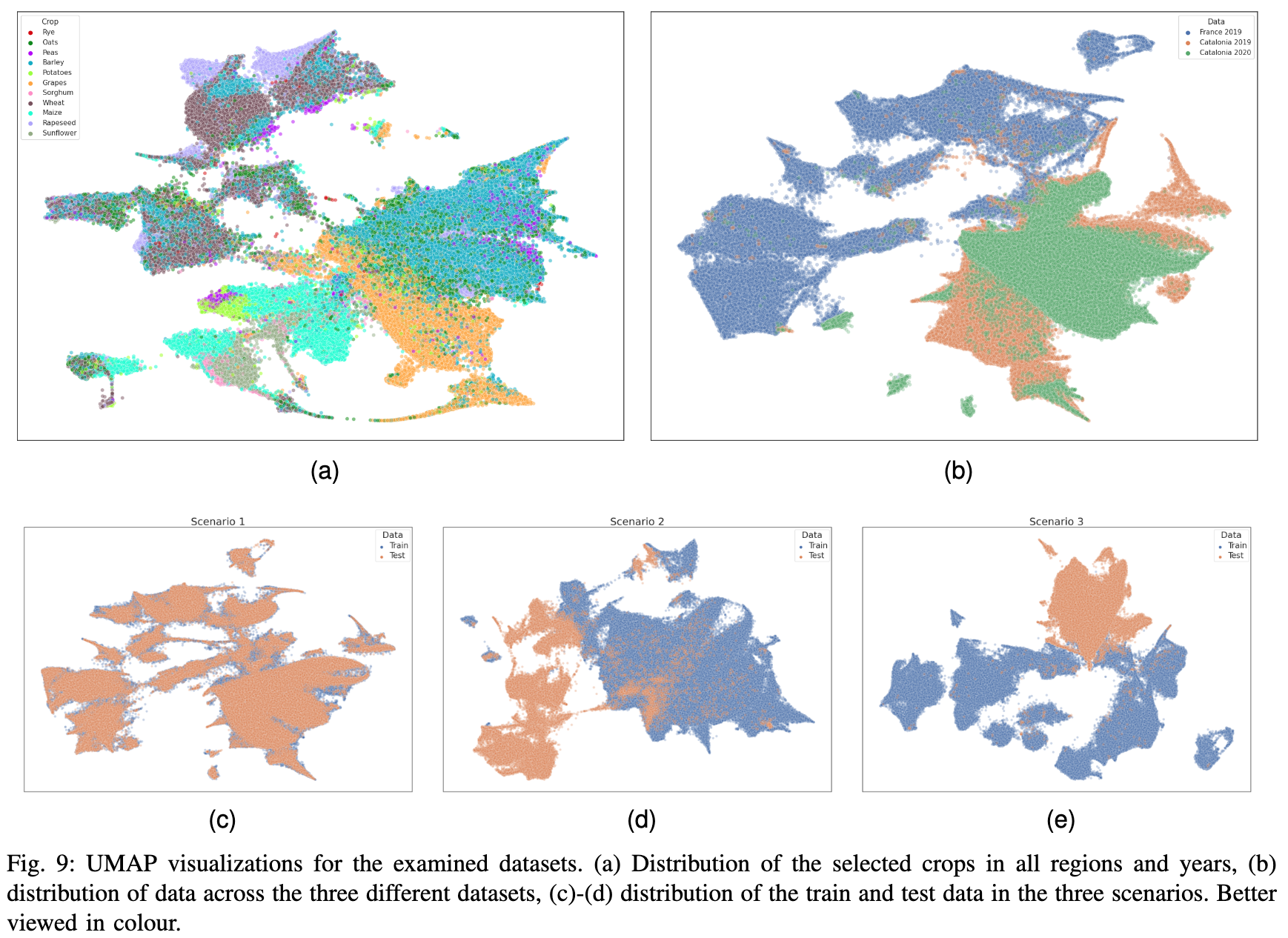
论文:A Sentinel-2 multi-year, multi-country benchmark dataset for crop classification and segmentation with deep learning
论文标题:A Sentinel-2 multi-year, multi-country benchmark dataset for crop classification and segmentation with deep learning
论文时间:2 Apr 2022
所属领域:计算机视觉
对应任务:Crop Classification,Semantic Segmentation,Time Series,农作物分类,语义分割,时间序列
论文地址:https://arxiv.org/abs/2204.00951
代码实现:https://github.com/orion-ai-lab/s4a
论文作者:Dimitrios Sykas, Maria Sdraka, Dimitrios Zografakis, Ioannis Papoutsis
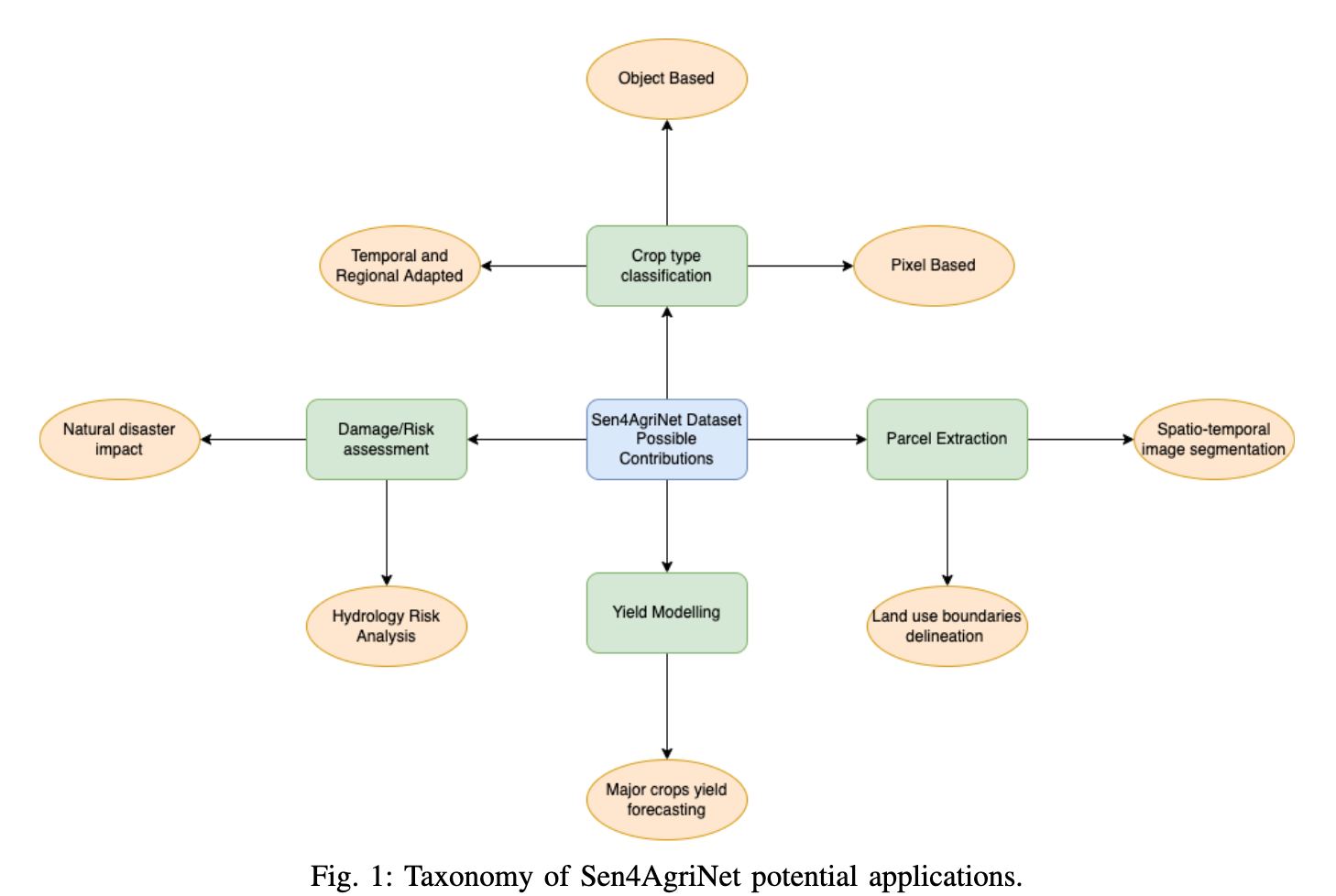
论文简介:In this work we introduce Sen4AgriNet, a Sentinel-2 based time series multi country benchmark dataset, tailored for agricultural monitoring applications with Machine and Deep Learning./在这项工作中,我们介绍了Sen4AgriNet,这是一个基于Sentinel-2的时间序列的多国基准数据集,通过机器和深度学习为农业监测应用量身定制。
论文摘要:In this work we introduce Sen4AgriNet, a Sentinel-2 based time series multi country benchmark dataset, tailored for agricultural monitoring applications with Machine and Deep Learning. Sen4AgriNet dataset is annotated from farmer declarations collected via the Land Parcel Identification System (LPIS) for harmonizing country wide labels. These declarations have only recently been made available as open data, allowing for the first time the labeling of satellite imagery from ground truth data. We proceed to propose and standardise a new crop type taxonomy across Europe that address Common Agriculture Policy (CAP) needs, based on the Food and Agriculture Organization (FAO) Indicative Crop Classification scheme. Sen4AgriNet is the only multi-country, multi-year dataset that includes all spectral information. It is constructed to cover the period 2016-2020 for Catalonia and France, while it can be extended to include additional countries. Currently, it contains 42.5 million parcels, which makes it significantly larger than other available archives. We extract two sub-datasets to highlight its value for diverse Deep Learning applications; the Object Aggregated Dataset (OAD) and the Patches Assembled Dataset (PAD). OAD capitalizes zonal statistics of each parcel, thus creating a powerful label-to-features instance for classification algorithms. On the other hand, PAD structure generalizes the classification problem to parcel extraction and semantic segmentation and labeling. The PAD and OAD are examined under three different scenarios to showcase and model the effects of spatial and temporal variability across different years and different countries.
在这项工作中,我们介绍了Sen4AgriNet,这是一个基于Sentinel-2的时间序列的多国基准数据集,为农业监测应用定制了机器学习和深度学习。Sen4AgriNet数据集的注释来自于通过地块识别系统(LPIS)收集的农民申报,用于协调全国范围的标签。这些声明最近才作为公开数据提供,首次允许从地面真实数据中对卫星图像进行标注。我们将根据粮食及农业组织(FAO)的指示性作物分类方案,在欧洲范围内提出新的作物类型分类标准,以满足共同农业政策(CAP)的需要。Sen4AgriNet是唯一包括所有光谱信息的多国多年的数据集。它的构建涵盖了2016-2020年加泰罗尼亚和法国的情况,同时可以扩展到其他国家。目前,它包含4250万个数据包,这使得它明显大于其他可用的档案。我们提取了两个子数据集,以突出其对不同深度学习应用的价值;对象汇总数据集(OAD)和补丁组装数据集(PAD)。OAD利用每个地块的分区统计,从而为分类算法创造了一个强大的标签到特征的实例。另一方面,PAD结构将分类问题概括为地块提取、语义分割和标签。PAD和OAD在三种不同的情况下被检验,以展示和模拟不同年份和不同国家的空间和时间变化的影响。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

边栏推荐
- I plan to teach myself some programming and want to work as a part-time programmer. I want to ask which programmer has a simple part-time platform list and doesn't investigate the degree of the receiv
- Force button brush question 01 (reverse linked list + sliding window +lru cache mechanism)
- The performance of major mainstream programming languages is PK, and the results are unexpected
- %S format character
- 力扣刷题01(反转链表+滑动窗口+LRU缓存机制)
- UFO: Microsoft scholars have proposed a unified transformer for visual language representation learning to achieve SOTA performance on multiple multimodal tasks
- [learning notes] matroid
- [differential privacy and data adaptability] differential privacy code implementation series (XIV)
- LVGL 8.2 Line
- LVGL 8.2 Sorting a List using up and down buttons
猜你喜欢
Redis 發布和訂閱

深度学习 神经网络案例(手写数字识别)
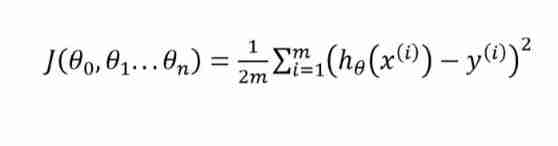
Five minutes per day machine learning: use gradient descent to complete the fitting of multi feature linear regression model

对话龙智高级咨询顾问、Atlassian认证专家叶燕秀:Atlassian产品进入后Server时代,中国用户应当何去何从?

5G电视难成竞争优势,视频资源成中国广电最后武器
Preliminary exploration of flask: WSGI
自动控制原理快速入门+理解

Korean AI team plagiarizes shock academia! One tutor with 51 students, or plagiarism recidivist

Intelligent customer service track: Netease Qiyu and Weier technology play different ways
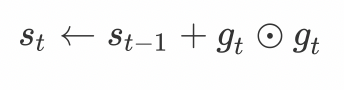
深度学习 神经网络的优化方法
随机推荐
Flutter reports an error no mediaquery widget ancestor found
flutter 报错 No MediaQuery widget ancestor found.
华为云数据库DDS产品深度赋能
Luo Gu - some interesting questions 2
Intelligent customer service track: Netease Qiyu and Weier technology play different ways
Redis 解决事务冲突之乐观锁和悲观锁
Redis 发布和订阅
Five minutes per day machine learning: use gradient descent to complete the fitting of multi feature linear regression model
UFO:微软学者提出视觉语言表征学习的统一Transformer,在多个多模态任务上达到SOTA性能!...
%S format character
EventBridge 在 SaaS 企业集成领域的探索与实践
PLC模拟量输入 模拟量转换FC S_ITR (CODESYS平台)
Memory management summary
Halo effect - who says that those with light on their heads are heroes
Halcon knowledge: NCC_ Model template matching
Introduction to modern control theory + understanding
找数字
Leetcode 1200 minimum absolute difference [sort] the way of leetcode in heroding
力扣刷题01(反转链表+滑动窗口+LRU缓存机制)
The performance of major mainstream programming languages is PK, and the results are unexpected