当前位置:网站首页>Deep learning 7 transformer series instance segmentation mask2former
Deep learning 7 transformer series instance segmentation mask2former
2022-07-04 14:39:00 【Racing CD】
List of articles
Preface
Text
Open source address
https://github.com/facebookresearch/Mask2Former
install
Reference resources https://github.com/facebookresearch/Mask2Former/blob/main/INSTALL.md
conda create --name mask2former python=3.8 -y
conda activate mask2former
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
# Here to cudatoolkit Source change
conda install cudatoolkit -c anaconda
pip install opencv-python
### install detectron2 API
git clone [email protected]:facebookresearch/detectron2.git
cd detectron2
pip install -e .
pip install git+https://github.com/cocodataset/panopticapi.git
pip install git+https://github.com/mcordts/cityscapesScripts.git
cd ..
git clone [email protected]:facebookresearch/Mask2Former.git
cd Mask2Former
pip install -r requirements.txt
cd mask2former/modeling/pixel_decoder/ops
sh make.sh
verification ( Download the corresponding model )
conda activate mask2former
cd Mask2Former/demo
python demo.py --config-file ../configs/coco/panoptic-segmentation/maskformer2_R50_bs16_50ep.yaml --input 1.jpg --output ./output
python demo.py --config-file ../configs/coco/instance-segmentation/swin/maskformer2_swin_tiny_bs16_50ep.yaml --input 2.jpg --output ./tiny --opts MODEL.WEIGHTS "../weights/swin_tiny_patch4_window7_224.pkl"
python demo.py --config-file ../configs/coco/instance-segmentation/swin/maskformer2_swin_large_IN21k_384_bs16_100ep.yaml --input 2.jpg --output ./large --opts MODEL.WEIGHTS "../weights/swin_large_patch4_window12_384_22k.pkl"
Training
Mask2Former All training reasoning is based on detectron2 API, You need to build your own data set before training , And to detectron2 API register
Register a custom dataset
Specify :
https://detectron2.readthedocs.io/en/latest/tutorials/datasets.html
Registration instance :
https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5#scrollTo=PIbAM2pv-urF
from detectron2.structures import BoxMode
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {
}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
for d in ["train", "val"]:
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get("balloon_train")
COCO Format datasets , Please call directly API register
from detectron2.data.datasets import register_coco_instances
register_coco_instances("my_dataset_train", {
}, "json_annotation_train.json", "path/to/image/dir")
register_coco_instances("my_dataset_val", {
}, "json_annotation_val.json", "path/to/image/dir")
Designated training data set
BASE: …/maskformer2_R50_bs16_50ep.yaml
DATASETS:
TRAIN: (“my_dataset_train”,)
TEST: (“my_dataset_val”,)
MODEL:
BACKBONE:
NAME: “D2SwinTransformer”
SWIN:
EMBED_DIM: 192
DEPTHS: [2, 2, 18, 2]
NUM_HEADS: [6, 12, 24, 48]
WINDOW_SIZE: 12
APE: False
DROP_PATH_RATE: 0.3
PATCH_NORM: True
PRETRAIN_IMG_SIZE: 384
WEIGHTS: “swin_large_patch4_window12_384_22k.pkl”
PIXEL_MEAN: [123.675, 116.280, 103.530]
PIXEL_STD: [58.395, 57.120, 57.375]
MASK_FORMER:
NUM_OBJECT_QUERIES: 200
SOLVER:
STEPS: (655556, 710184)
MAX_ITER: 737500
Training
cd Mask2Former
python train_net.py --num-gpus 1 --config-file configs/coco/instance-segmentation/swin/maskformer2_swin_large_IN21k_384_bs16_100ep.yaml MODEL.WEIGHTS "weights/swin_large_patch4_window12_384_22k.pkl"
Condition handling
1) Insufficient memory
RuntimeError: CUDA out of memory. Tried to allocate 410.00 MiB (GPU 0; 10.91 GiB total capacity; 4.24 GiB already allocated; 151.44 MiB free; 4.62 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
【 Solution 】 Use smaller models and smaller batch_size, Modify... In the configuration file , Its configuration file depends on layers , Pay attention to the parameters set at each layer
SOLVER:
IMS_PER_BATCH: 1
2)
File “/dataset/projects/Mask2Former/mask2former/modeling/matcher.py”, line 141, in memory_efficient_forward
cost_dice = batch_dice_loss_jit(out_mask, tgt_mask)
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
RuntimeError: Global alloc not supported yet
【 Solution 】 Reference resources https://github.com/facebookresearch/Mask2Former/issues/4
take batch_dice_loss_jit Replace with batch_dice_loss
# cost_dice = batch_dice_loss_jit(out_mask, tgt_mask)
cost_dice = batch_dice_loss(out_mask, tgt_mask)
3) The classification number of data set is inconsistent with the model
Just modify the configuration file
_BASE_: ../maskformer2_R50_bs16_50ep.yaml
MODEL:
RETINANET:
NUM_CLASSES: 2
ROI_HEADS:
NUM_CLASSES: 2
SEM_SEG_HEAD:
NUM_CLASSES: 2
BACKBONE:
NAME: "D2SwinTransformer"
SWIN:
EMBED_DIM: 96
DEPTHS: [2, 2, 18, 2]
NUM_HEADS: [3, 6, 12, 24]
WINDOW_SIZE: 7
APE: False
DROP_PATH_RATE: 0.3
PATCH_NORM: True
WEIGHTS: "swin_small_patch4_window7_224.pkl"
PIXEL_MEAN: [123.675, 116.280, 103.530]
PIXEL_STD: [58.395, 57.120, 57.375]
DATASETS:
TRAIN: ("my_dataset_train",)
TEST: ("my_dataset_val",)
SOLVER:
IMS_PER_BATCH: 1
DATALOADER:
NUM_WORKERS: 1
OUTPUT_DIR: ./output/small_wf_alarm
边栏推荐
- Stm32f1 and stm32subeide programming example -max7219 drives 8-bit 7-segment nixie tube (based on GPIO)
- NowCoder 反转链表
- LVGL 8.2 Menu
- LVGL 8.2 Line wrap, recoloring and scrolling
- R language uses follow up of epidisplay package The plot function visualizes the longitudinal follow-up map of multiple ID (case) monitoring indicators, and uses stress The col parameter specifies the
- opencv3.2 和opencv2.4安装
- Wt588f02b-8s (c006_03) single chip voice IC scheme enables smart doorbell design to reduce cost and increase efficiency
- 使用CLion编译OGLPG-9th-Edition源码
- Talk about 10 tips to ensure thread safety
- MySQL的触发器
猜你喜欢
![[information retrieval] experiment of classification and clustering](/img/05/ee3b3bc4ab79d52b63cdc34305aa57.png)
[information retrieval] experiment of classification and clustering
(1)性能调优的标准和做好调优的正确姿势-有性能问题,上HeapDump性能社区!

STM32F1与STM32CubeIDE编程实例-MAX7219驱动8位7段数码管(基于GPIO)
flink sql-client.sh 使用教程
The failure rate is as high as 80%. What are the challenges on the way of enterprise digital transformation?
Sqlserver functions, creation and use of stored procedures
LVGL 8.2 Line
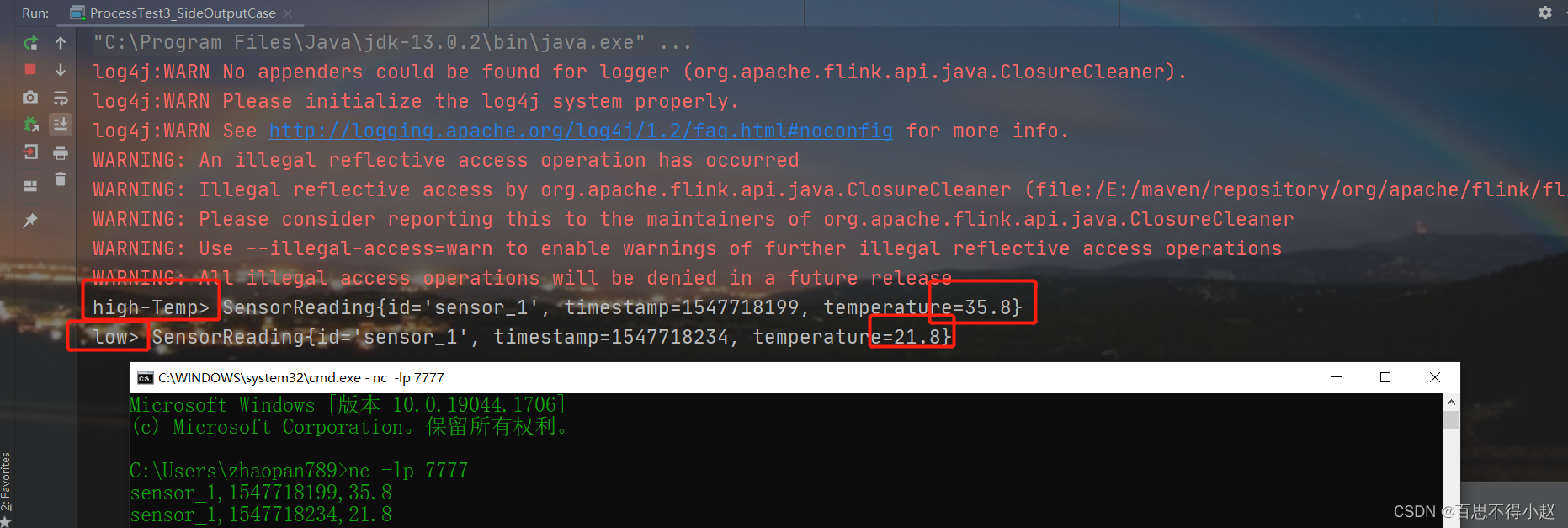
Combined with case: the usage of the lowest API (processfunction) in Flink framework
LVGL 8.2 Line
LVGL 8.2 Draw label with gradient color
随机推荐
C language book rental management system
Node mongodb installation
数据湖(十三):Spark与Iceberg整合DDL操作
[C language] Pointer written test questions
【MySQL从入门到精通】【高级篇】(五)MySQL的SQL语句执行流程
关于miui12.5 红米k20pro用au或者povo2出现问题的解决办法
One architecture to complete all tasks - transformer architecture is unifying the AI Jianghu on its own
Redis daily notes
(1)性能调优的标准和做好调优的正确姿势-有性能问题,上HeapDump性能社区!
产业互联网则具备更大的发展潜能,具备更多的行业场景
LVLG 8.2 circular scrolling animation of a label
【算法leetcode】面试题 04.03. 特定深度节点链表(多语言实现)
Popular framework: the use of glide
商业智能BI财务分析,狭义的财务分析和广义的财务分析有何不同?
The implementation of OSD on rk1126 platform supports color translucency and multi-channel support for Chinese
Data center concept
Codeforce:c. sum of substrings
LVGL 8.2 Sorting a List using up and down buttons
An overview of 2D human posture estimation
Stm32f1 and stm32subeide programming example -max7219 drives 8-bit 7-segment nixie tube (based on GPIO)