当前位置:网站首页>[information retrieval] link analysis
[information retrieval] link analysis
2022-07-04 14:28:00 【Alex_ SCY】
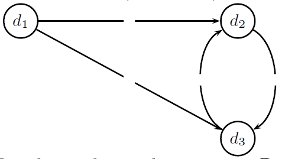
(1). Reading materials 《Introduction to Information Retrieval》 The first 464-470 page 21.2 As described in section PageRank computing method ( adopt power iteration To achieve ), use Java Language or other commonly used languages to implement the algorithm . Take the structure shown in the following figure as an example to calculate each document Of PageRank value , among teleportation rate=0.05.
Preset some program parameters :
Create adjacency matrix according to the graph given in the title :

For this question , The adjacency matrix is shown below :
linkMatrix[i][j]=1 It indicates that there is a slave node i Point to the node j The directed side of .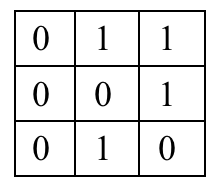
Then start to calculate the transition probability matrix :
There are three steps :
- Use 1 Take out each 1
- The processed result matrix is multiplied by 1-α
- Add alpha/N
Finally, the transition probability matrix corresponding to the ontology can be obtained :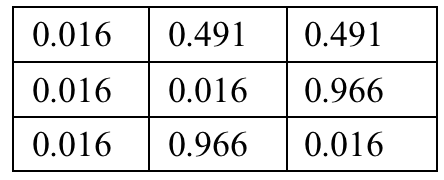
Perform power iteration :
Initialize the probability distribution vector :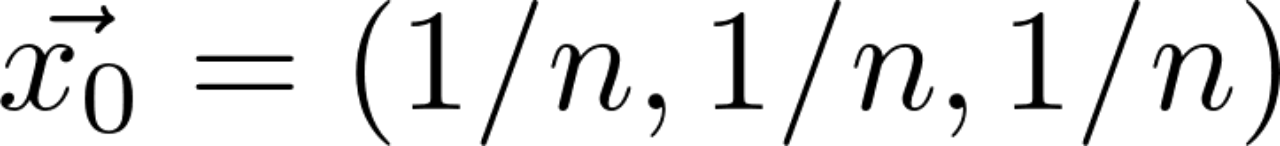
Then iterate according to the following formula , Until the probability distribution vector converges :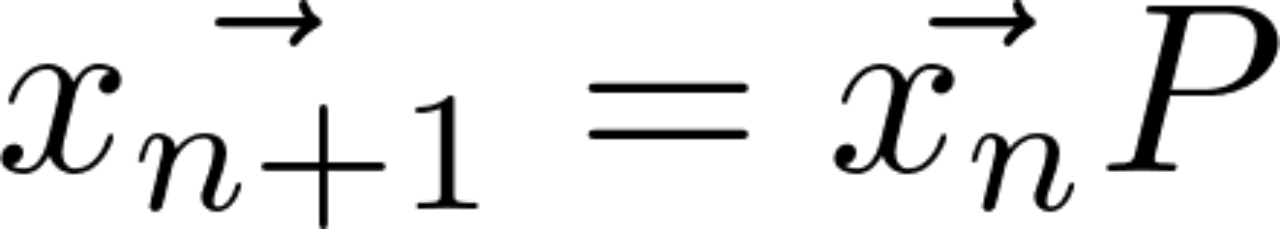

The final calculation results are as follows : It can converge after one iteration 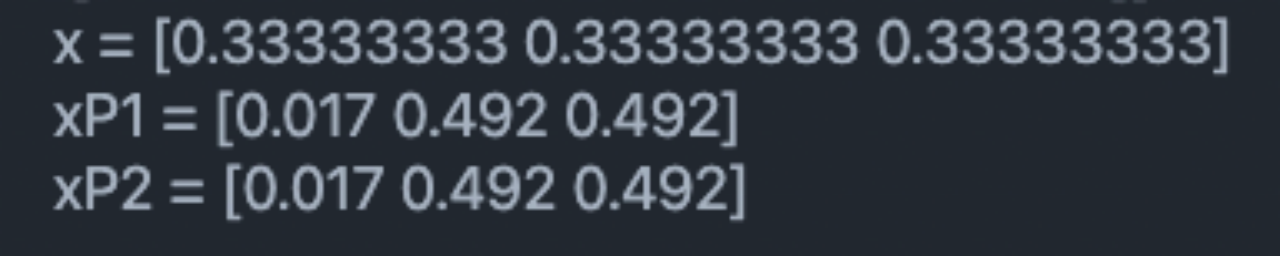
namely Pagerank(d1)=0.017,Pagerank(d2)=0.492,Pagerank(d3)=0.492. A simple analysis shows that ,d2 And d3 It's symmetrical . At the same time, because there is no document Point to d1, Only when you encounter random jump, you will jump to document1, therefore Pagerank(d1) Will be significantly smaller than the other two values .
(2). In another way ( No power iteration The way ) Calculate with pen ( No program calculation ) topic (1) Each of them document Of PageRank value . Detailed description and calculation process are required .(10 branch )
It can be calculated according to algebraic algorithm :
PageRank The definition of :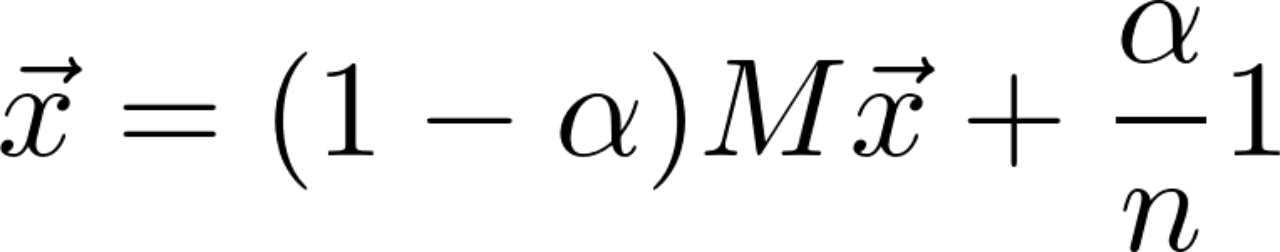
therefore :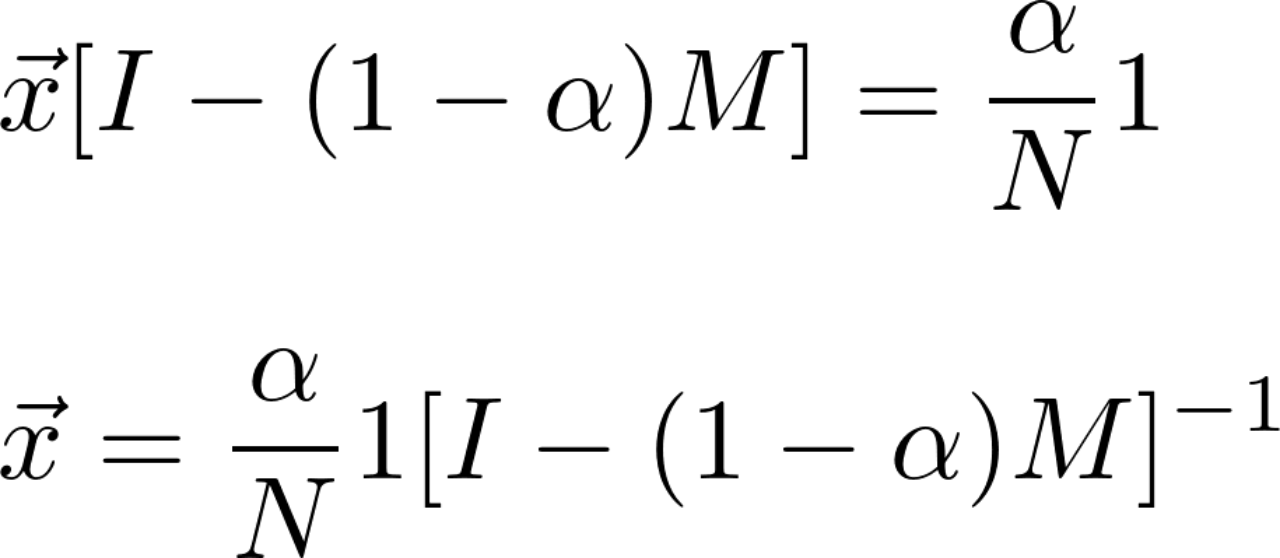
among M Is the transition probability matrix ( No random jump ),1 by [1*N] The holonomic matrix of ,I Is the unit matrix 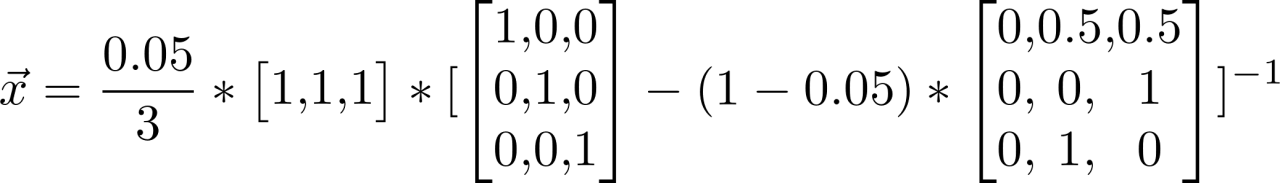
And that gives us 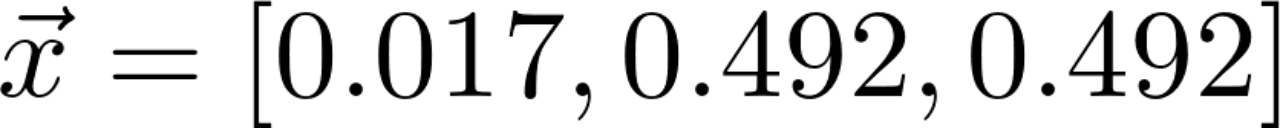 ,Pagerank(d1)=0.017,Pagerank(d2)=0.492,Pagerank(d3)=0.492, The results are obtained by the power iteration method .
,Pagerank(d1)=0.017,Pagerank(d2)=0.492,Pagerank(d3)=0.492, The results are obtained by the power iteration method .
(3). Reading materials 《Introduction to Information Retrieval》 The first 474-477 page 21.3 As described in section HITS computing method ( adopt power iteration To achieve ), use Java Language or other commonly used languages to implement the algorithm . Take the structure shown in the following figure as an example to calculate each document Of authority Values and hub value .
Preset some program parameters :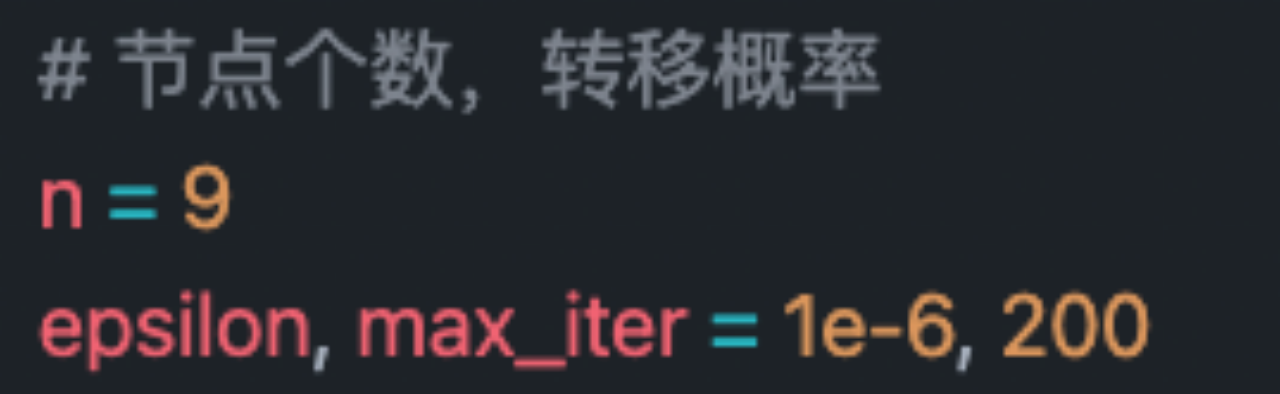
Then label the nodes in the graph , And generate the corresponding adjacency matrix , As shown below :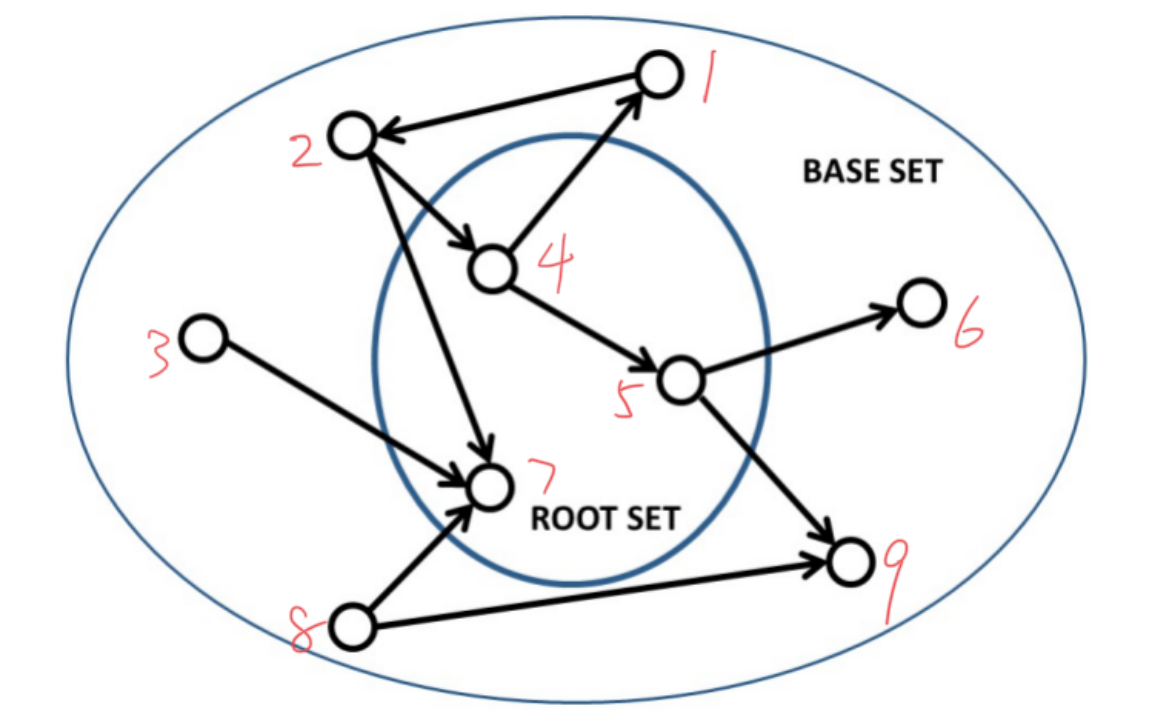
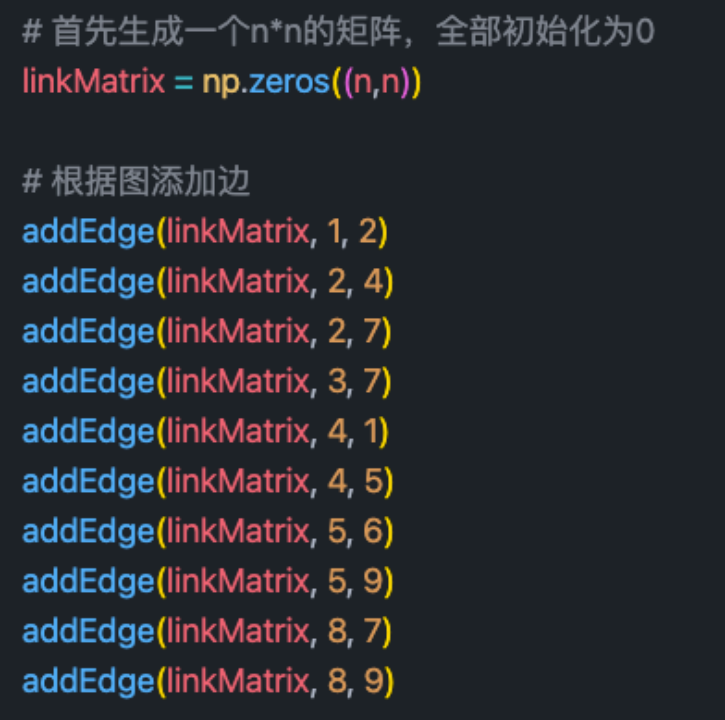
Adjacency matrix :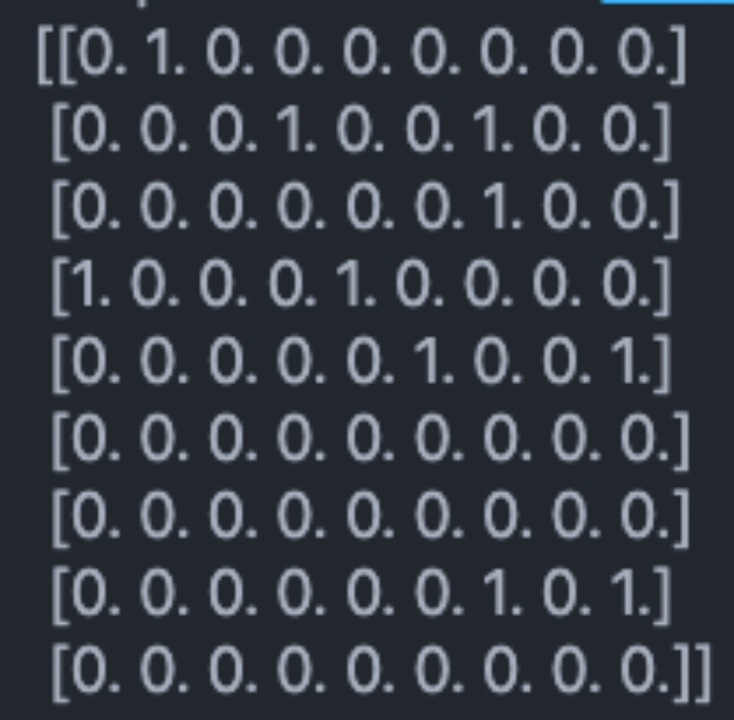
initialization hub as well as authority vector :
Start the iteration according to the following formula , At the same time, after each iteration, the vector needs to be normalized , until hub And authority Vector convergence :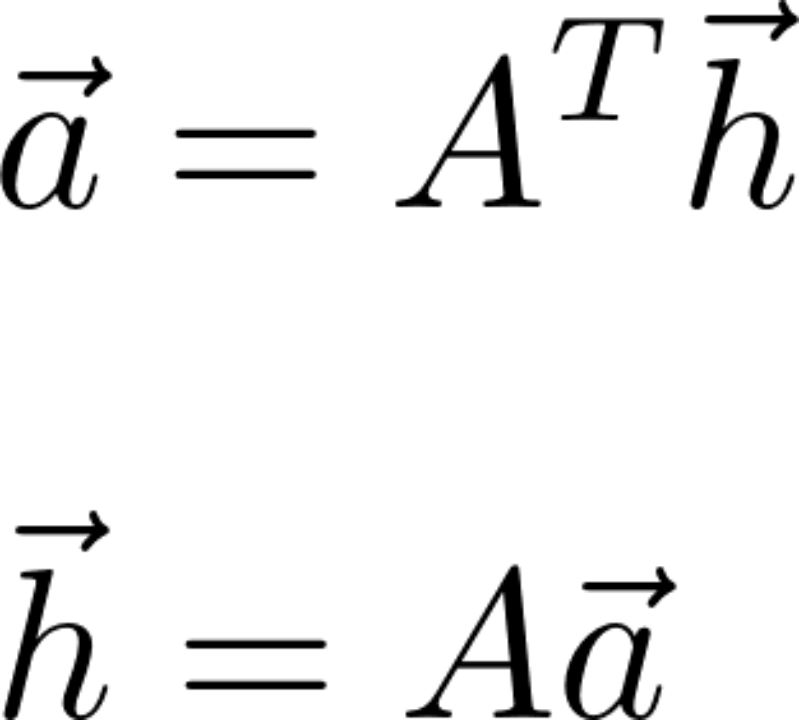

The final running results are as follows :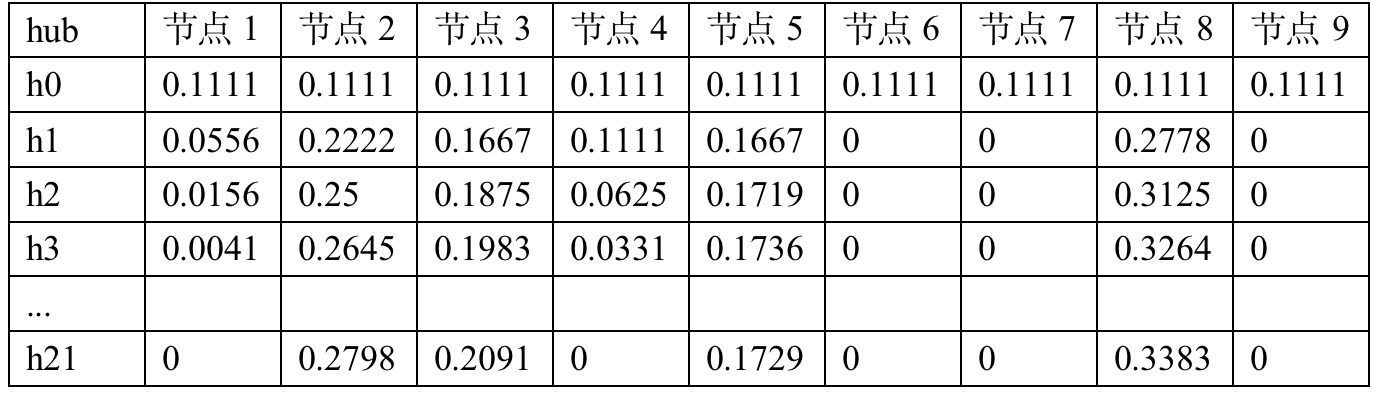
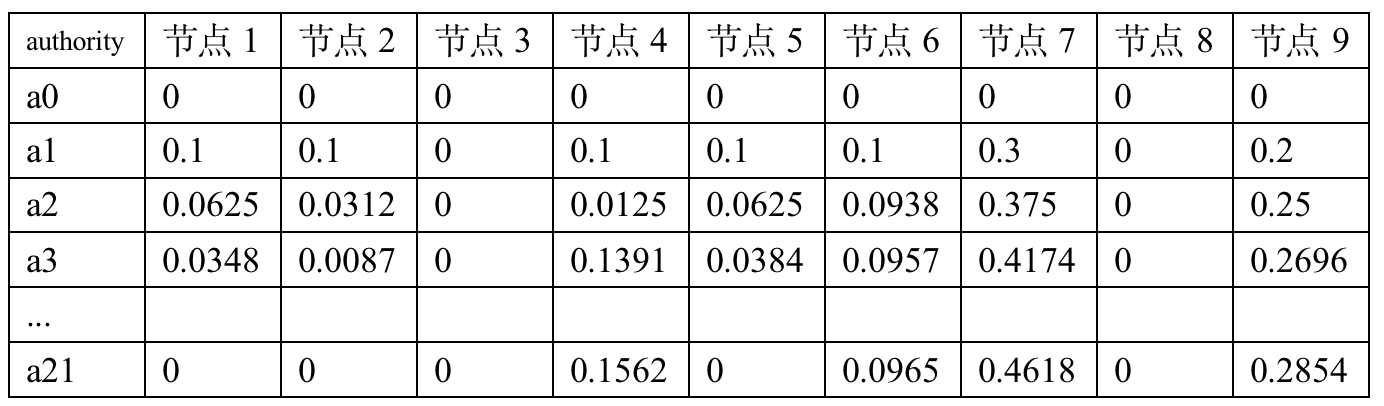
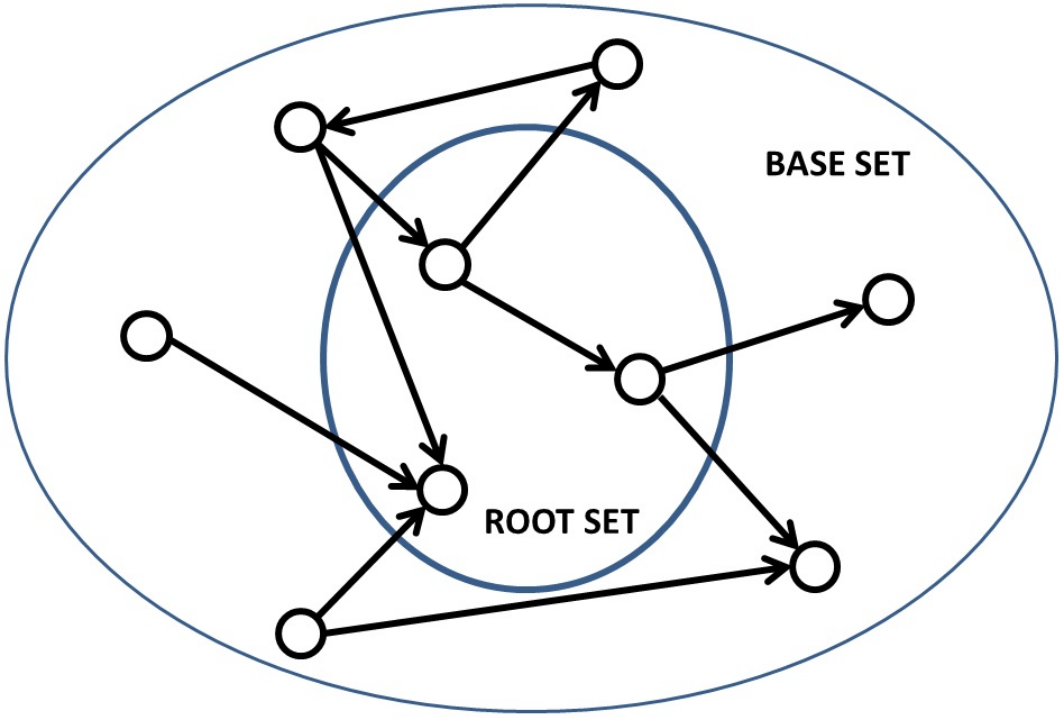
Final hub The largest value is the node 8( be in base set) , node 8 Pointing to the node 7 and 9, meanwhile 7 and 9 It is pointed to by multiple nodes (authority High value ), So nodes 8 Of hub The highest value is very reasonable .
authority The largest value is the node 7 ( be in root set), node 7 By node 2,3,8 Point to , At the same time node 2,3,8 Of hub High value , So nodes 7 Of authority The highest value is very reasonable .
hub/authority Value can reflect the navigation and authority of a web page . Different website purposes should focus on different indicators , For example, navigation websites should focus on hub value , This can point more accurately ; Portal websites should focus on authority value , Let more navigation websites point to it , Improve Authority .
边栏推荐
- MySQL triggers
- MySQL的触发器
- Codeforce:c. sum of substrings
- Chapter 16 string localization and message Dictionary (2)
- Popular framework: the use of glide
- 【MySQL从入门到精通】【高级篇】(五)MySQL的SQL语句执行流程
- Ml: introduction, principle, use method and detailed introduction of classic cases of snap value
- flink sql-client. SH tutorial
- 软件测试之测试评估
- 一文概览2D人体姿态估计
猜你喜欢
![Incremental ternary subsequence [greedy training]](/img/92/7efd1883c21c0e804ffccfb2231602.png)



随机推荐
GCC【6】- 编译的4个阶段
Scratch Castle Adventure Electronic Society graphical programming scratch grade examination level 3 true questions and answers analysis June 2022
R语言使用lattice包中的bwplot函数可视化箱图(box plot)、par.settings参数自定义主题模式
Excel快速合并多行数据
ARouter的使用
软件测试之测试评估
Ws2818m is packaged in cpc8. It is a special circuit for three channel LED drive control. External IC full-color double signal 5v32 lamp programmable LED lamp with outdoor engineering
GCC [6] - 4 stages of compilation
leetcode:6109. 知道秘密的人数【dp的定义】
Map of mL: Based on Boston house price regression prediction data set, an interpretable case of xgboost model using map value
Xcode 异常图片导致ipa包增大问题
Digi XBee 3 rf: 4 protocols, 3 packages, 10 major functions
ML之shap:基于boston波士顿房价回归预测数据集利用Shap值对LiR线性回归模型实现可解释性案例
Industrial Internet has greater development potential and more industry scenarios
数据埋点的一些问题和想法
LifeCycle
如何游戏出海代运营、游戏出海代投
Map of mL: Based on Boston house price regression prediction data set, an interpretable case is realized by using the map value to the LIR linear regression model
第十六章 字符串本地化和消息字典(二)
WT588F02B-8S(C006_03)单芯片语音ic方案为智能门铃设计降本增效赋能