当前位置:网站首页>sql优化之explain
sql优化之explain
2022-07-04 12:51:00 【氵奄不死的鱼】
explain
id
id 列的编号是 select 的序列号,查几个表就有几个 id,并且 id 值越大执行优先级越高。如果 id 值相同,就从上往下执行,最后执行 id 为 null 的。
select_type
查询类型,有如下几种取值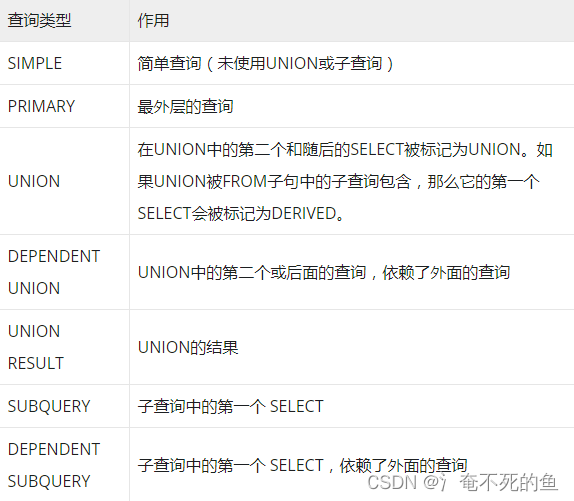
举以一个子SUBQUERY查询依赖外外面的例子
explain select * from (select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no ) erp_travel
where erp_travel.travel_no in (
select max(erp_travel_cost.travel_no) from erp_travel_cost where erp_travel_cost.project_no = erp_travel.project_no
)
limit 1
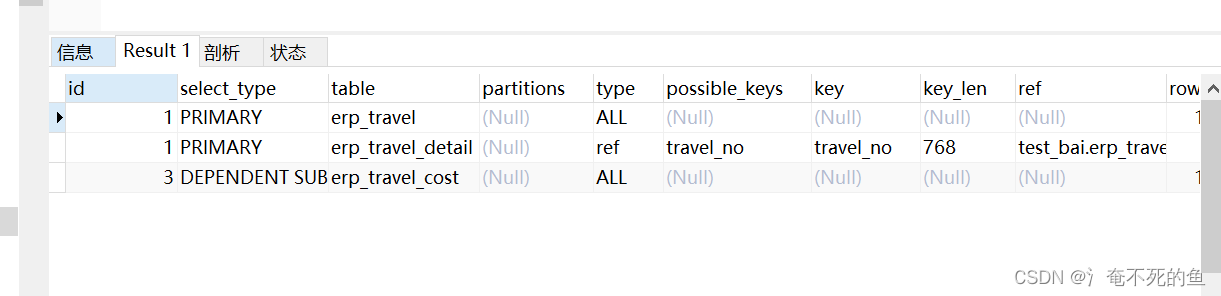
解析查询流程
1.看出执行顺序首先执行id为3的子查询 ,直接全表查出来,全表IO
2.查询出外查询数据结果,挨行去匹配子查询的结果。外查询 挨个根据条件查子查询最大的 travel_no
3.我们知道自查询匹配时笛卡尔积,即 primar的size乘subquery 的size,如果两个查询的数据量仅仅只是分别过万,那么循环次数将是过亿。因此DEPENDENT SUBQUERY一定尽量避免,一旦出现基本就是一个没办法使用sql.
SUBQUERY例子
将子查询中的与外查询中的关联条件去掉
explain select * from (select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no ) erp_travel
where erp_travel.travel_no in (
select max(erp_travel_cost.travel_no) from erp_travel_cost where erp_travel_cost.is_manage is not null
)
limit 1;
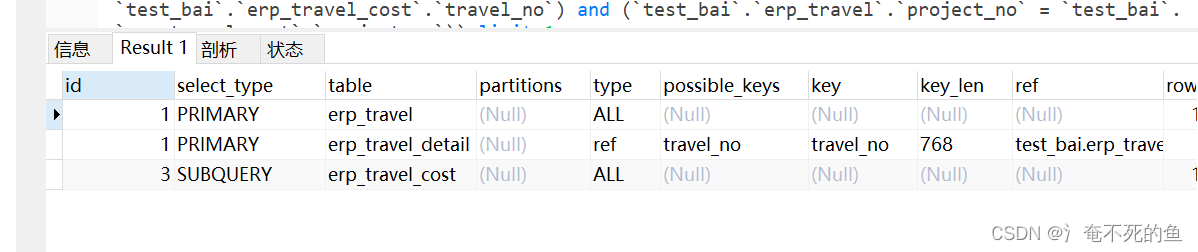
SUBQUERY执行的速度是很快的,因为子查询只执行了一回,产生一条记录,与外查询无关联。根本没有笛卡尔积循环匹配这个过程。
如果是普通的子查询会怎么样
将子查询的聚合max去掉,避免DEPENDENT SUBQUERY
explain select * from (select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no ) erp_travel
where erp_travel.travel_no in (
select erp_travel_cost.travel_no from erp_travel_cost where erp_travel_cost.project_no = erp_travel.project_no
)
limit 1
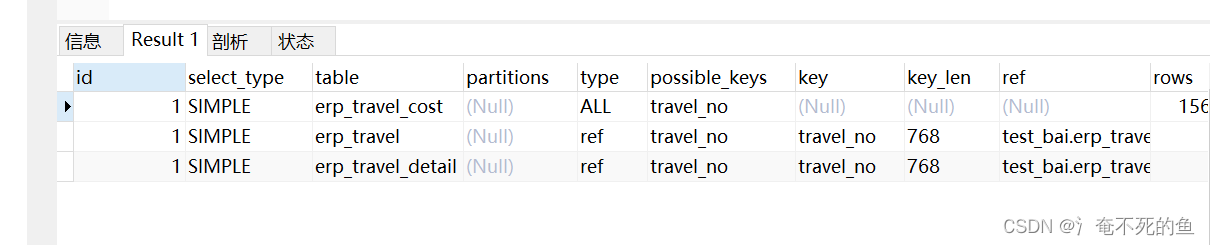
这个查询为什么这么快,我们分析一下
经过sql优化器优化 ,可以看出来子查询已经被优化成了连接查询
为什么将子查询转为关联查询?
我们知道子查询意味着外查询和内查询的笛卡尔积,那么连接查询呢。连接查询使用的连接方式为Nest Loop Join,对于内连接,自动优化为小表驱动大表
1.子查询erp_travel_cost全表IO查出结果,作为驱动表
2.使用join buffer 批量查询连接外查询结果集。
由于peoject_no不是索引,两个表都有15w左右的数据,那么这样全表连接,一定是一个灾难。几乎不可能跑出来结果
table
表示当前这一行正在访问哪张表,如果SQL定义了别名,则展示表的别名
partitions
当前查询匹配记录的分区。对于未分区的表,返回null
分区时将不同的数据分到对应的区块,这样每块的大小变小,加快IO速度
了解什么是分区MySQL 表分区?涨知识了!
type
| ALL | 全表扫描
| index | 索引全扫描
| range | 索引范围扫描,常用语<,<=,>=,between等操作
| ref | 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
| const/system | 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询
| null | MySQL不访问任何表或索引,直接返回结果
ALL全表扫描
当查询条件没有索引可以走,那么就是全表io
explain select * from erp_travel_cost where is_manage is null

效率最差
INDEX索引全表扫描
explain select project_no from erp_travel_cost ; -- all
explain select travel_no from erp_travel_cost -- index

index: Full Index Scan, index与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和index都是读全表,但index是从索引中读取的,而all是从硬盘中读的)
index 指的是扫描全量的索引,且不需要回表,要么直接查主键索引,要么直接查二级索引
RANGE
- range: 只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引
一般就是在你的where语句中出现了between、<、>、in等的查询
这种范围扫描索引扫描比全表扫描要好,因为他只需要开始索引的某一点,而结束语另一点,不用扫描全部索引
首先range要求是对索引指定范围,对于非索引肯定是全表
explain select * from erp_travel_cost where erp_travel_cost.create_time > '2022-01-01 00:00:00' -- all
explain select * from erp_travel_cost where travel_no> '2' --range

因为索引自带顺序,很容易利用B+树确定索引范围,如果需要回表,再过索引得到的返回分别根据主键去回表查询,如果回表数据比较多时,加上在索引上也需要Io,因此范围较大时会直接使用全表查询
ref
- ref: 非唯一索引扫描,返回匹配某个单独值的所有行。
本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,
它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体
explain select * from erp_travel_cost where travel_no = ( '1000127141') -- ref
explain select * from erp_travel_cost where travel_no in( '1000127141','1000127142') --range
eq_ref
读取本表中和关联表表中的每行组合成的一行。除 了 system 和 const 类型以外, 这是最好的联接类型。当链接使用索引的全部部分时, 索引是主键或惟一非 NULL 索引时, 将使用该值。
eq_ref 可用于使用 = 运算符比较的索引列。比较值能够是常量或使用此表以前读取的表中的列的表达式。在下面的示例中, MySQL 能够使用 eq_ref 链接(join)ref_table来处理:ui
explain select * from app_user_copy1 left join app_user on app_user.id = app_user_copy1.id
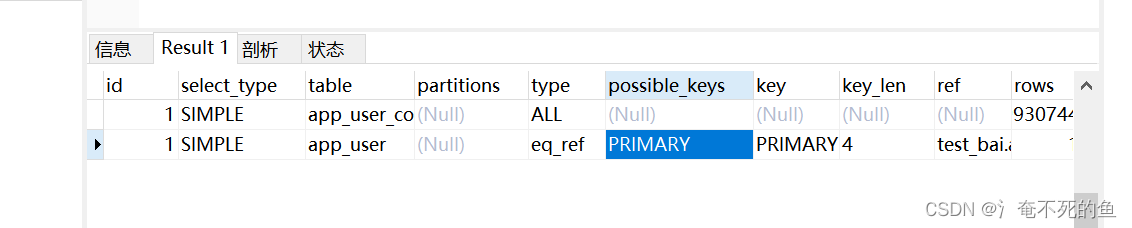
const
表示通过索引一次就找到了,const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快。如将主键至于where列表中,MySQL就能将该查询转换为一个常量
system
- system: 表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,这个也可以忽略不计
index_merge
但是我今天的问题是,两个不同的二级索引树,会同时生效吗?理论上来说,应该是可以同时生效的,不然这个 MySQL 也太笨了。基本都发生在 or 条件上
explain select * from erp_travel where project_no_form = 'A21020028' or user_no ='00022139'

两个列的索引都会被使用
possible_keys
MYSQL的优化器会找出所有可以用来执行该语句的方案,并在对比这些方案后找出成本最低的方案。这里会列出来可能会用到的索引
显示可能应用在这张表中的索引,一个或多个。查询涉及的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。
key
可能用到的key有多个,但是优化器会选择索引进行查询,不一定会只选择一个索引还要index_merge
key列表示经过查询优化器计算使用不同索引成本后决定使用的索引名,即实际使用的索引列。如果为null则没有使用索引。
查询中若使用了覆盖索引,则索引和查询的select字段重叠
key_len
key_len列表示当优化器决定使用某个索引执行查询时,该索引记录的最大长度,它是由这三个部分构成的:
① 对于使用固定长度类型的索引列来说,它实际占用的存储空间的最大长度就是该固定值,对于指定字符集的变长类型的索引列来说,比如某个索引列的类型是varchar(255),使用的字符集是utf8(MySQL utf8字符集占用3个字节长度),那么该列实际占用的最大存储空间就是255 × 3 + 2= 767个字节。
② 如果该索引列可以存储NULL值,则key_len比不可以存储NULL值时多1个字节 为758。
③ 对于变长字(varchar)段来说,都会有2个字节的空间来存储该变长列的实际长度。
对与联合索引还可以通过key_len看出来到底使用了几列联合索引,用的列越多,就能更多的根据索引过滤,减少io次数
explain select * from erp_travel where user_no = '00022139' -- key_len 768
explain select * from erp_travel where user_no = '00022139' and user_name = '00022139' --key_len 1536
explain select * from erp_travel where user_no = '00022139' and user_name = '00022139' and creater = '00022139' --key_len 2304
ref
当使用索引列等值匹配的条件去执行查询时,也就是在访问方法是const、eq_ref、ref、ref_or_null、unique_subquery、index_subquery其中之一时,ref列展示的就是与索引列作等值匹配的条件,如常数或某个列。
explain select * from erp_travel where user_no ='00022139'

这里与索引列student_name做等值匹配的是一个具体的字符串,是常数, 所以ref这列显示const
explain select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no

erp_travel_detail做等值匹配的时erp_travel的travel_no字段,因此这里显示erp_travel.travel_no
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数. 这个可以算是最重要的指标了,因为所有的优化的最终目的都是为了减少最后扫描的行数, 也就是减少rows这个值.
rows究竟是怎么计算的呢?
这个rows在官网文档中的解释如下:
“
rows (JSON name: rows)
The rows column indicates the number of rows MySQL believes it must examine to execute the query.
For [InnoDB] tables, this number is an estimate, and may not always be exact.
http://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain_rows
简单翻译就是:这个方法仅仅根据给出的关于这个索引的条件和索引本身,来判断需要扫描多少行。
总结
MySQL Explain 里的 rows 这个值
- 是MySQL认为它要检查的行数(仅做参考),而不是结果集里的行数;
- 同时 SQL里的 LIMIT 和这个也是没有直接关系的。
另外,很多优化手段,例如关联缓冲区和查询缓存,都无法影响到rows的显示。MySQL可能不必真的读所有它估计到的行,它也不知道任何关于操作系统或硬件缓存的信息。
这个rows的价值在于是看索引在查询中的作用,是否合理 仅仅根据查询或者连接条件的索引进行大致的估计。如果没有索引肯定估值为全表,即使加上Limit
explain select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.travel_no = erp_travel_detail.travel_no

首先erp_travel作为驱动表, 全表查询,估算rows就是全表行数
然后根据索引连接条件,travel_no连接erp_travel_detail,根据索引估算,只需要一行数据就能匹配索引,但是实际肯定不止扫描了这么多数据,
filtered
MySql explain语句的返回结果中,filtered字段要怎么理解?
MySql5.7官方文档中描述如下:
The filtered column indicates an estimated percentage of table rows filtered by the table condition. The maximum value is 100, which means no filtering of rows occurred. Values decreasing from 100 indicate increasing amounts of filtering. rows shows the estimated number of rows examined and rows × filtered shows the number of rows joined with the following table. For example, if rows is 1000 and filtered is 50.00 (50%), the number of rows to be joined with the following table is 1000 × 50% = 500.
这段文字不是很好理解,举例来说,有如下三个查询语句的explain结果,针对b和c表的显示filtered是100,而针对a表的显示是18。
+-------------+-------+--------+---------+---------+------+----------+
| select_type | table | type | key | key_len | rows | filtered |
+-------------+-------+--------+---------+---------+------+----------+
| PRIMARY | a | range | search | 4 | 174 | 18.00 |
| PRIMARY | b | eq_ref | PRIMARY | 4 | 1 | 100.00 |
| PRIMARY | c | ALL | PRIMARY | 4 | 1 | 100.00 |
我们可以怎么理解filtered的值呢?从filtered的值中得出什么结论呢?到底是100更好还是18更好?
首先,这里的filtered表示通过查询条件获取的最终记录行数占通过type字段指明的搜索方式搜索出来的记录行数的百分比。
以上图的第一条语句为例,MySQL首先使用索引(这里的type是range)扫描表a,预计会得到174条记录,也就是rows列展示的记录数。接下来MySql会使用额外的查询条件对这174行记录做二次过滤,最终得到符合查询语句的32条记录,也就是174条记录的18%。而18%就是filtered的值。
更完美的情况下,应该是使用某个索引,直接搜索出32条记录并且过滤掉另外82%的记录。
因此一个比较低filtered值表示需要有一个更好的索引,假如type=all,表示以全表扫描的方式得到1000条记录,且filtered=0.1%,表示只有1条记录是符合搜索条件的。此时如果加一个索引可以直接搜出来1条数据,那么filtered就可以提升到100%。
由此可见,filtered=100%确实是要比18%要好。
当然,filtered不是万能的,关注执行计划结果中其他列的值并优化查询更重要。比如为了避免出现filesort(使用可以满足order by的索引),即使filtered的值比较低也没问题。再比如上面filtered=0.1%的场景,我们更应该关注的是添加一个索引提高查询性能,而不是看filtered的值。
Extra
Extra列是用来说明一些额外信息的,我们可以通过这些额外信息来更准确的理解MySQL到底将如何执行给定的查询语句。MySQL提供的额外信息有好几十个,就不一个一个介绍了,在这只介绍常见的一些额外信息说明 .
① Using filesort: 如果根据索引列进行排序(order by 索引列)是可以用到索引的,SQL查询引擎会先根据索引列进行排序,然后获取对应记录的主键id执行回表操作,如果排序字段用不到索引则只能在内存中或磁盘中进行排序操作,MySQL把这种在内存或者磁盘上进行排序的方式统称为文件排序(英文名:filesort),如果某个查询需要使用文件排序的方式执行查询,就会在执行计划的Extra列中显示Using filesort
explain select * from erp_travel_detail order by travel_no limit 1000

根据索引排序,一般不会使用filesort但是如果数据量大了,还是会不走缩影
把1000改成10000
explain select * from erp_travel_detail order by travel_no limit 10000

即使跟进索引排序,还是使用了filesort
② Using temporary
Using temporary表示由于排序没有走索引、使用union、子查询连接查询、使用某些视图等原因(详见internal-temporary-tables),因此创建了一个内部临时表。注意这里的临时表可能是内存上的临时表,也有可能是硬盘上的临时表,理所当然基于内存的临时表的时间消耗肯定要比基于硬盘的临时表的实际消耗小。
临时表其实也很好理解就是,要根据sql先处理一个结果,再根据这个结果进一步处理得到最终结果。那么这个中间的结果就是中间表
mysql> show global status like '%tmp%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Created_tmp_disk_tables | 0 |
| Created_tmp_files | 5 |
| Created_tmp_tables | 11 |
+-------------------------+-------+
3 rows in set
explain select updater from erp_travel
group by updater

explain select travel_no from erp_travel
group by travel_no
走索引.索引自带有序,直接根据索引就可以在有序的基础上进行分组了,而不需要排序,创建临时表
explain select distinct updater from erp_travel;
非索引,创建了临时表
explain select distinct updater from erp_travel where updater = '00022139';

数据量少也不没必要建立临时表处理
explain select distinct creater from erp_travel

对于联合索引,即使不符合最左匹配,这样也还是可以通过索引减少io次数。
③ USING index: 表示相应的select操作中使用了覆盖索引(Covering Index),避免回表操作,效率不错!
如果同时出现using where,表明索引被用来执行索引键值的查找;如果没有同时出现using where,表名索引用来读取数据而非执行查找动作。
④ Using where: 使用了where过滤
⑤ using join buffer: 在连接查询执行过程中,当被驱动表不能有效的利用索引加快访问速度,MySQL一般会为其分配一块名叫join buffer的内存块来加快查询速度
explain select erp_travel.*,erp_travel_detail.destination from erp_travel left join erp_travel_detail on erp_travel.user_no = erp_travel_detail.creater

连接条件不是索引(采用join buffer)
⑥ impossible where: where子句的值总是false,不能用来获取任何元组
⑦ select tables optimized away: 在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。
explain select max(travel_no) from erp_travel

⑧ distinct: 优化distinct,在找到第一匹配的元组后即停止找同样值的工作
⑨ Using index condition:查找使用了索引,但是需要回表查询数据
explain select * from erp_travel_cost where travel_no in( '1000127141','1000127142')

边栏推荐
- Install MySQL
- golang fmt. Printf() (turn)
- 2022 practice questions and mock exams for the main principals of hazardous chemical business units
- 【Matlab】conv、filter、conv2、filter2和imfilter卷积函数总结
- 吃透Chisel语言.12.Chisel项目构建、运行和测试(四)——Chisel测试之ChiselTest
- 按照功能对Boost库进行分类
- 【FAQ】华为帐号服务报错 907135701的常见原因总结和解决方法
- Huahao Zhongtian sprint Technology Innovation Board: perte annuelle de 280 millions de RMB, projet de collecte de fonds de 1,5 milliard de Beida Pharmaceutical est actionnaire
- Haobo medical sprint technology innovation board: annual revenue of 260million Yonggang and Shen Zhiqun are the actual controllers
- JVM memory layout detailed, illustrated, well written!
猜你喜欢

![递增的三元子序列[贪心训练]](/img/92/7efd1883c21c0e804ffccfb2231602.png)



随机推荐
R语言ggplot2可视化:gganimate包创建动画图(gif)、使用anim_save函数保存gif可视化动图
go vendor 项目迁移到 mod 项目
Hardware Basics - diode Basics
Understand chisel language thoroughly 06. Chisel Foundation (III) -- registers and counters
How to package QT and share exe
Deming Lee listed on Shenzhen Stock Exchange: the market value is 3.1 billion, which is the husband and wife of Li Hu and Tian Hua
Ws2818m is packaged in cpc8. It is a special circuit for three channel LED drive control. External IC full-color double signal 5v32 lamp programmable LED lamp with outdoor engineering
MySQL 5 installation and modification free
做事的真正意义和目的,真正想得到什么
Blob, text geometry or JSON column'xxx'can't have a default value query question
Why should Base64 encoding be used for image transmission
英视睿达冲刺科创板:年营收4.5亿 拟募资9.79亿
学内核之三:使用GDB跟踪内核调用链
[FAQ] summary of common causes and solutions of Huawei account service error 907135701
程序员的焦虑
Install MySQL
递增的三元子序列[贪心训练]
【Matlab】conv、filter、conv2、filter2和imfilter卷积函数总结
游戏出海,全球化运营
qt 怎么检测鼠标在不在某个控件上