当前位置:网站首页>Mask wearing detection based on yolov1
Mask wearing detection based on yolov1
2022-07-04 14:08:00 【Short section senior】
pick want
In recent years , The target detection algorithm has made a great breakthrough . The more popular algorithms can be divided into two categories , One is based on Region Proposal Of R-CNN System algorithm (R-CNN,Fast R-CNN, Faster R-CNN), They are two-stage Of , You need to use heuristics first (selective search) perhaps CNN The Internet (RPN) produce Region Proposal, And then in Region Proposal Do classification and regression . And the other is Yolo、SSD This kind of one-stage Algorithm , It uses only one CNN The network directly predicts the categories and locations of different targets . The first method has higher accuracy , But it's slow ; The second kind of algorithm is fast , But less accurate . This paper introduces Yolo Algorithm , Its full name is You Only Look Once: Unified, Real-Time Object Detection. This topic basically Yolo The characteristics of the algorithm summarize :You Only Look Once It means only once CNN operation ;Unified It means that this is a unified framework , Provide end-to-end The forecast ; and Real-Time reflect Yolo The algorithm is fast .
key word Image classification ; Mask detection ;YOLOv1; Feature learning ; Preliminary training
introduction
2019 The outbreak of novel coronavirus pneumonia , Great changes have taken place in people's travel —— since 1 month 24 After Wuhan was declared closed on the th , All provinces and cities have successively launched the first level response to major public health emergencies to control population mobility . Many cities have stipulated that masks must be worn 、 Take your temperature before you can take public transportation .2 month 10 Before the rework day on the th , Shanghai 、 Beijing and other key cities have also successively released new regulations : Access to the airport 、 Rail transit 、 Inter-City Bus Station 、 Health care institutions 、 Shopping malls, supermarkets and other public places , Those who do not wear masks will be discouraged .
2 month 13 Japan , Baidu PaddlePaddle announces open source industry's first mask face detection and classification model . Based on this model , It can detect a large number of faces in the public scene at the same time , Mark the face with and without mask , Fast recognition of various scenes without attention 、 Don't pay attention to virus protection , Even people with fluke mentality , Reduce potential safety hazards in public . At the same time, build more public welfare applications for epidemic prevention .
Design concept
On the whole ,Yolo The algorithm uses a separate CNN Model implementation end-to-end Target detection for , The whole system is shown in the figure above : First, input the picture resize To 448 × 448 448 \times 448 448×448, And then send in CNN The Internet , Finally, the network prediction results are processed to obtain the detected target . comparison R-CNN The algorithm is a unified framework , It's faster , and Yolo The training process is also end-to-end Of .
The system divides the input image into S × S S \times S S×S grid . If the center of a target falls into a grid cell , Then the grid unit is responsible for detecting the target . Each grid cell predicts B B B individual bounding box and box The confidence score of . These confidence scores reflect the model's confidence that the box contains an object , And it thinks the accuracy of box prediction . Formally , We define confidence as P r ( O b j e c t ) × I O U Pr(Object)\times IOU Pr(Object)×IOU, I O U IOU IOU finger intersection over union between the predicted box and the ground truth. If there is no prediction object in this cell , Then the confidence should be zero ; Otherwise, the confidence is equal to I O U IOU IOU. Every bounding box from 5 5 5 A prediction consists of : x x x, y y y, w w w, h h h And confidence . x , y x, y x,y Express bounding box Relative to the center of the grid cell boundary ; w , h w, h w,h Predict width and height relative to the entire image ; Last , The confidence level represents the difference between the prediction frame and the real frame I O U IOU IOU.
Each grid cell also predicts $ C $ Conditional class probabilities P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i | Object) Pr(Classi∣Object). These probabilities are conditional on the grid cell containing the detection object . No matter what B How many , Predict only one set of class probabilities for each grid cell . At testing time , Multiply the probability of the condition category by the confidence prediction of each box :
P r ( C l a s s i ∣ O b j e c t ) × P r ( O b j e c t ) × I O U t r u t h p r e d = P r ( C l a s s i ) × I O U t r u t h p r e d Pr(Class_i | Object) \times Pr(Object) \times IOU^{truth}{pred} = Pr(Class_i) \times IOU^{truth}{pred} Pr(Classi∣Object)×Pr(Object)×IOUtruthpred=Pr(Classi)×IOUtruthpred
Thus, the confidence of a certain class of each box is obtained . These results represent the probability of the category appearing in the box , And predicted bounding box The degree of suitability for the tested object .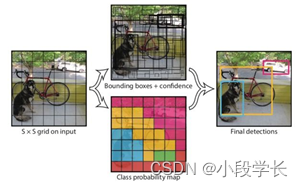
Network design
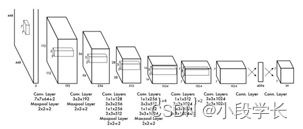
According to the above structure diagram , The input image size is 448 × 448 448 \times 448 448×448, After several convolution layers and pooling layers , Turn into 7 × 7 × 1024 7\times7\times1024 7×7×1024 tensor ( The penultimate cube in Figure 1 ), Finally, it goes through two full connection layers , The output tensor dimension is 7 × 7 × 30 7\times7\times30 7×7×30, This is it. Yolo v1 The whole neural network structure , It is not much different from the general convolution object classification network , The big difference is this : The last full connection layer of the classified network , Usually connected to a one-dimensional vector , Different bits of a vector represent different categories , The output vector here is a three-dimensional tensor ( 7 × 7 × 30 7\times7\times30 7×7×30). Above picture Yolo Network structure , Inspired by GoogLeNet, It's also v2、v3 in Darknet The vanguard of . Essentially nothing special , Not used BN layer , Used a layer Dropout. Except that the output of the last layer uses a linear activation function , All other layers are used Leaky Relu Activation function .
A fast version of YOLO, It aims to break through the boundary of rapid object detection . Fast YOLO The neural network used has fewer convolution layers ( 9 A rather than 24 individual ), And there are fewer filters in these layers . In addition to the size of the network ,YOLO and Fast YOLO All training and test parameters are the same .
LOSS function
After the neural network structure is determined , The training effect is good or bad , from Loss Functions and optimizers decide .Yolo v1 Use the ordinary gradient descent method as the optimizer . Here is a key interpretation Yolo v1 The use of Loss function :
Loss function , The paper gives a more detailed explanation . All losses are based on the sum of squares error formula , Let's not look at the formula for the moment λ c o o r d \lambda_{coord} λcoord And λ n o o b j \lambda_{noobj} λnoobj , The predicted value of output and the loss caused are :
The center point of the prediction box ( x , y ) (x, y) (x,y) . The loss caused is the first line . among 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj Is the control function , At the grid points where the label contains the object , The value is 1 ; If the lattice does not contain an object , The value is 0. That is to say, we only calculate the loss of those grid points that the real object belongs to , If the lattice does not contain an object , So the predicted value does not affect the loss function .(x, y) Simple sum of squares error between values and labels .
The width and height of the prediction box ( w , h ) (w, h) (w,h) . The loss caused is the second line of the figure . 1 i j o b j \mathbb{1}^{obj}_{ij} 1ijobj It means the same thing , It's also that only the grid point to which the real object belongs will cause losses . Here to (w, h) The treatment in the loss function takes the root sign respectively , The reason lies in , If you don't take the root , The loss function tends to adjust the prediction box with larger size . for example , 20 20 20 The deviation of one pixel , about 800 × 600 800 \times 600 800×600 There is little effect on the prediction box of , At this time IOU The value is still very large , But for 30 × 40 30 \times 40 30×40 The prediction box has a great impact . The root sign is to eliminate the difference between the large size box and the small size box as much as possible .
Confidence of prediction frame C. The third and fourth lines . When the lattice does not contain an object , The label of the confidence level is 0; If there are objects , The label of the confidence is the difference between the prediction box and the real object box IOU The number .
Probability of object class P. The fifth row . Corresponding category position , The tag value is 1, The rest are 0, The same as the classification network .
Now let's look at λ c o o r d \lambda_{coord} λcoord And λ n o o b j \lambda_{noobj} λnoobj ,Yolo The problem of object detection , It's a typical problem of unbalanced number of categories . among 49 Grid points , A lattice containing an object usually has only 3、4 individual , The rest are grid points without objects . At this point, if no measures are taken , So object detection is mAP It won't be too high , Because models tend to have no grid points of objects . λ c o o r d \lambda_{coord} λcoord And λ n o o b j \lambda_{noobj} λnoobj The role of , That is, let the lattice containing the object , More weight in the loss function , Make the model more “ Attaches great importance to ” The loss caused by a grid containing objects . In the paper , λ c o o r d \lambda_{coord} λcoord And λ n o o b j \lambda_{noobj} λnoobj The values of are 5 And 0.5.
ginseng Examination writing offer
[] Li Xingchen . The fusion YOLO Detection of multi-target tracking algorithm [J]. Computer engineering and science ,2020(4):665-672.
[2] Li Zhangwei . Overview of vision based object detection methods [J]. Computer engineering and Application ,2020(3):1-9.
[3] Liu Lei . A kind of YOLO Identification and Mean shift Tracking traffic flow statistical method [J. Manufacturing automation ,2020(2):16-20.
[4] Wang Feng . Application of artificial intelligence in drawing recognition in door and window inspection [J]. Sichuan cement ,2019(9):137-138.
Welcome to join me for wechat exchange and discussion ( Please note csdn Add )
边栏推荐
- Lick the dog until the last one has nothing (state machine)
- Getting started with the go language is simple: go implements the Caesar password
- How to choose a technology stack for web applications in 2022
- 2022kdd pre lecture | 11 first-class scholars take you to unlock excellent papers in advance
- Service Mesh的基本模式
- 嵌入式编程中五个必探的“潜在错误”
- 分布式BASE理论
- Source code compilation and installation of MySQL
- 好博医疗冲刺科创板:年营收2.6亿 万永钢和沈智群为实控人
- find命令报错: paths must precede expression(转)
猜你喜欢
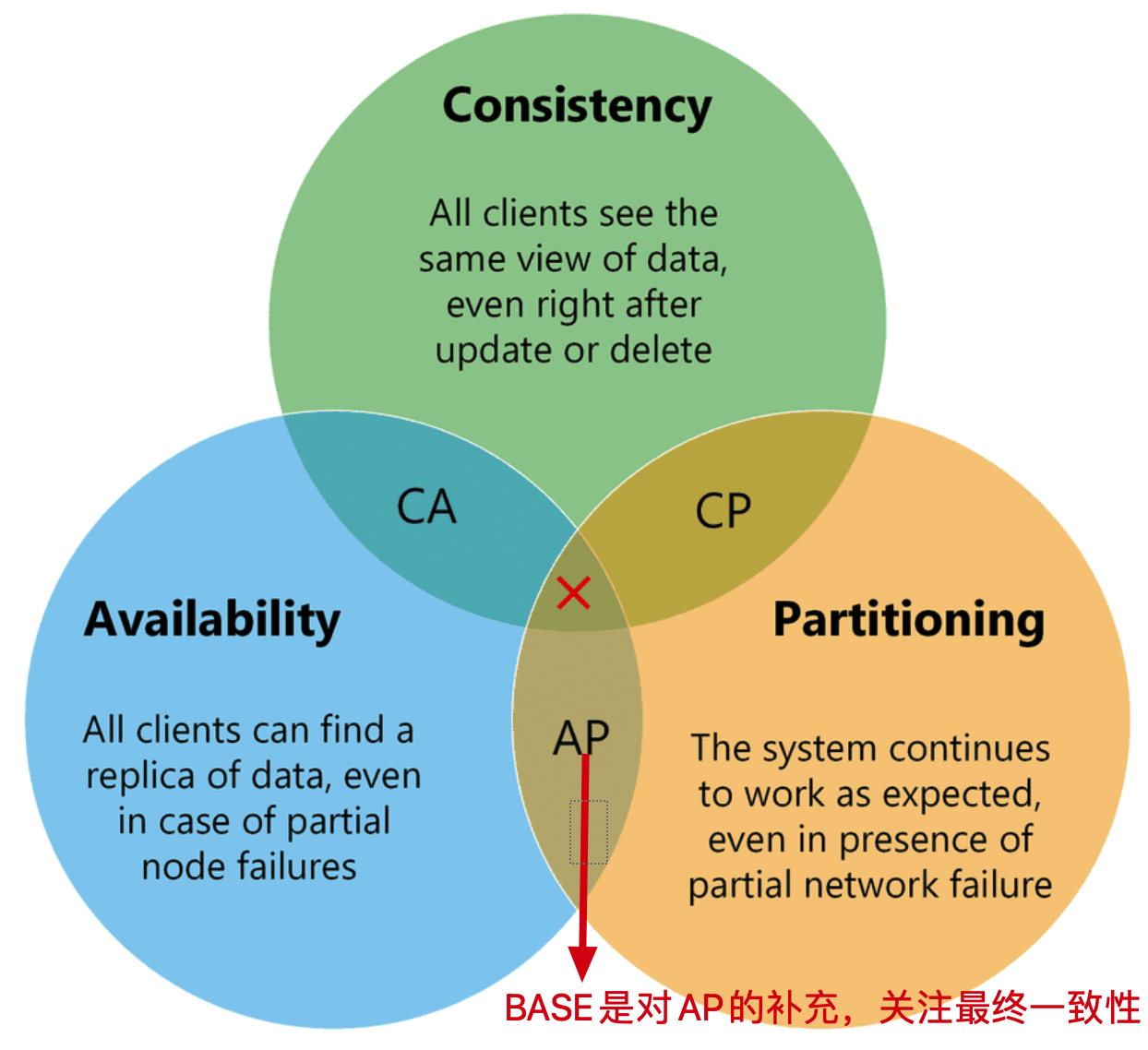
分布式BASE理论
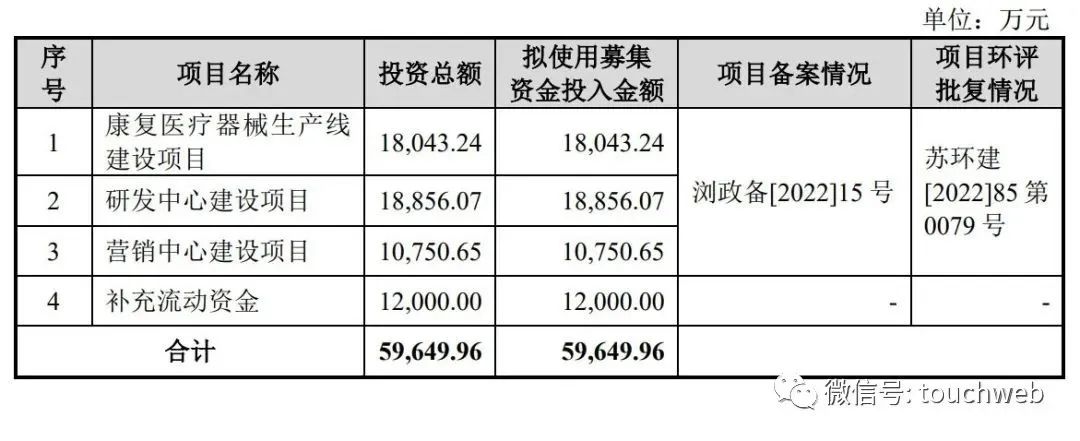
Haobo medical sprint technology innovation board: annual revenue of 260million Yonggang and Shen Zhiqun are the actual controllers
.Net之延迟队列

国内酒店交易DDD应用与实践——代码篇

markdown 语法之字体标红
![30: Chapter 3: develop Passport Service: 13: develop [change / improve user information, interface]; (use * * * Bo class to accept parameters, and use parameter verification)](/img/89/aabf79ca02bf587e93885cadd5f98a.png)
30: Chapter 3: develop Passport Service: 13: develop [change / improve user information, interface]; (use * * * Bo class to accept parameters, and use parameter verification)
Introduction to reverse debugging PE structure resource table 07/07

2022kdd pre lecture | 11 first-class scholars take you to unlock excellent papers in advance

数据库公共字段自动填充
结合案例:Flink框架中的最底层API(ProcessFunction)用法
随机推荐
吃透Chisel语言.08.Chisel基础(五)——Wire、Reg和IO,以及如何理解Chisel生成硬件
php 日志调试
.Net之延迟队列
Qt如何实现打包,实现EXE分享
以房抵债能否排除强制执行
OpenHarmony应用开发之如何创建DAYU200预览器
吃透Chisel语言.05.Chisel基础(二)——组合电路与运算符
美国土安全部部长警告移民“不要踏上危险的旅程”
2022年山东省安全员C证考试题库及在线模拟考试
华昊中天冲刺科创板:年亏2.8亿拟募资15亿 贝达药业是股东
ViewBinding和DataBinding的理解和区别
Ws2811 m is a special circuit for three channel LED drive and control, and the development of color light strip scheme
Lick the dog until the last one has nothing (state machine)
近日小结(非技术文)
基于YOLOv1的口罩佩戴检测
Secretary of Homeland Security of the United States: domestic violent extremism is one of the biggest terrorist threats facing the United States at present
find命令报错: paths must precede expression(转)
分布式BASE理论
【FAQ】华为帐号服务报错 907135701的常见原因总结和解决方法
MySQL5免安装修改