当前位置:网站首页>LNX efficient search engine, fastdeploy reasoning deployment toolbox, AI frontier paper | showmeai information daily # 07.04
LNX efficient search engine, fastdeploy reasoning deployment toolbox, AI frontier paper | showmeai information daily # 07.04
2022-07-04 15:13:00 【ShowMeAI】

ShowMeAI daily Series new upgrade ! Cover AI Artificial intelligence Tools & frame | project & Code | post & Share | data & resources | Research & The paper Wait for the direction . Click to see List of historical articles , Subscribe to topics in the official account #ShowMeAI Information daily , Can receive the latest daily push . Click on Thematic collection & Electronic monthly Quickly browse the complete works of each topic . Click on here Reply key daily Free access AI Electronic monthly and information package .
{kind=link}
1. Tools & frame

Tools :Git Based MLOps: use Git / GitHub Realization MLOps
This project shows how to Git/GitHub To realize MLOps. In order to achieve this goal , The project makes extensive use of DVC、DVC Studio、DVCLive Tools such as , And show the detailed process of construction . All products are manufactured by iterative.ai、Google Drive、Jarvislabs.ai and HuggingFace Hub structure .
GitHub: https://github.com/codingpot/git-mlops
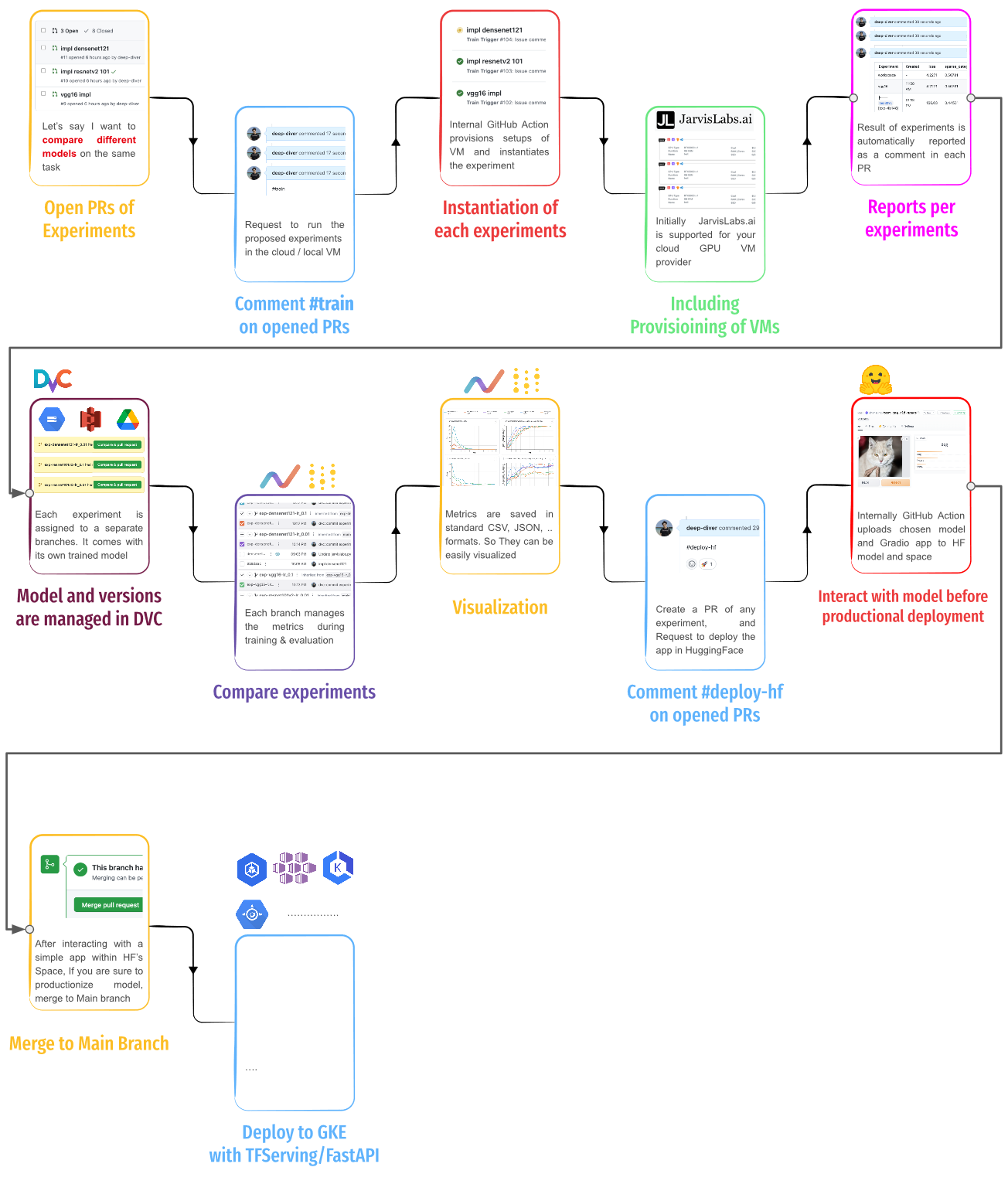
Tools :lnx - Rust Write an efficient search engine
lnx The construction of tokio-rs 、 super Web Framework and tantivy The original computing power of search engines , Constitute an efficient engine system .
This makes lnx It can index thousands of document inserts at millisecond level at the same time ( No longer wait for things to be indexed !) Each index transaction and the ability to handle search , Just like it's just another lookup on the hash table
GitHub: https://github.com/lnx-search/lnx
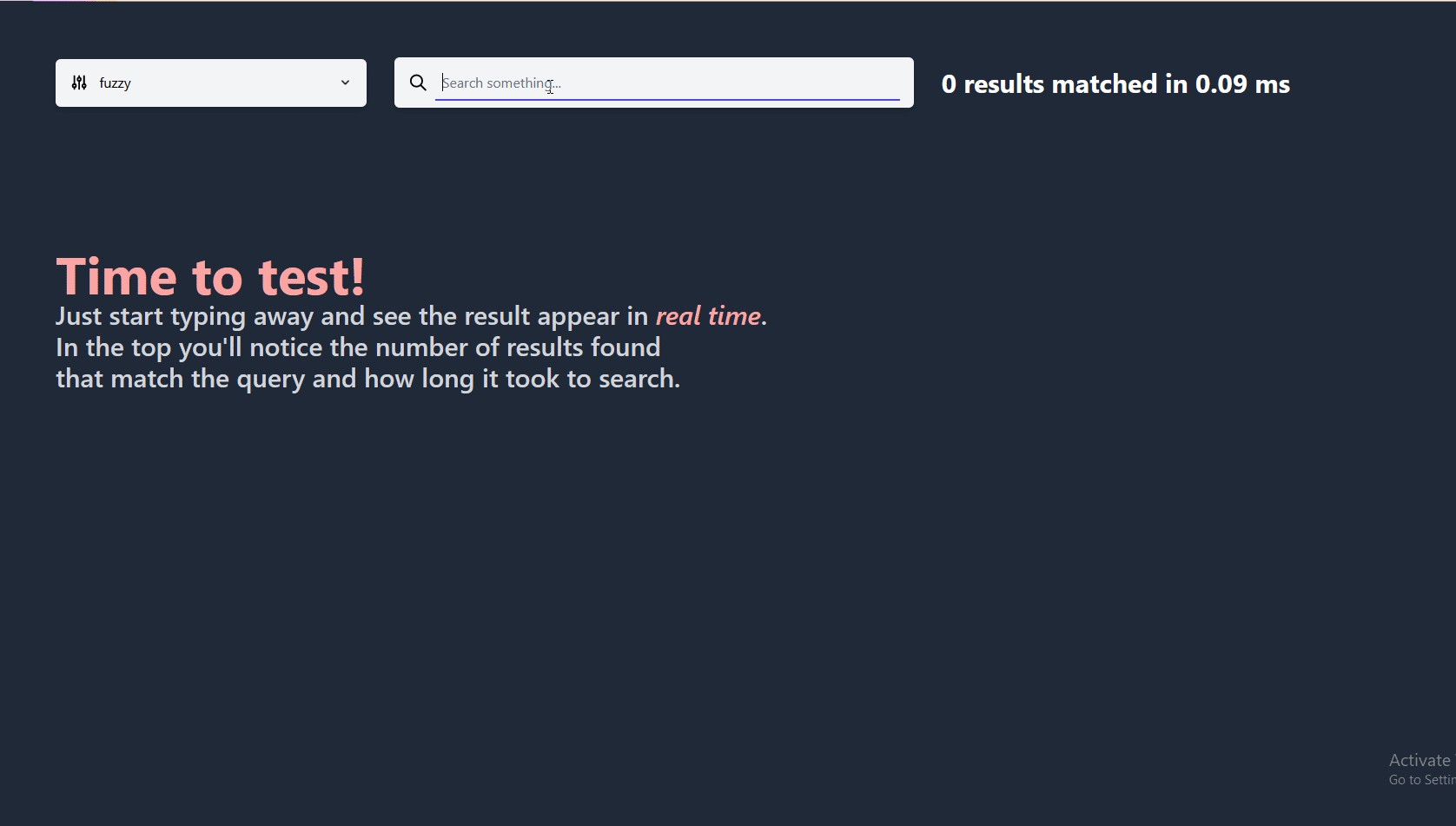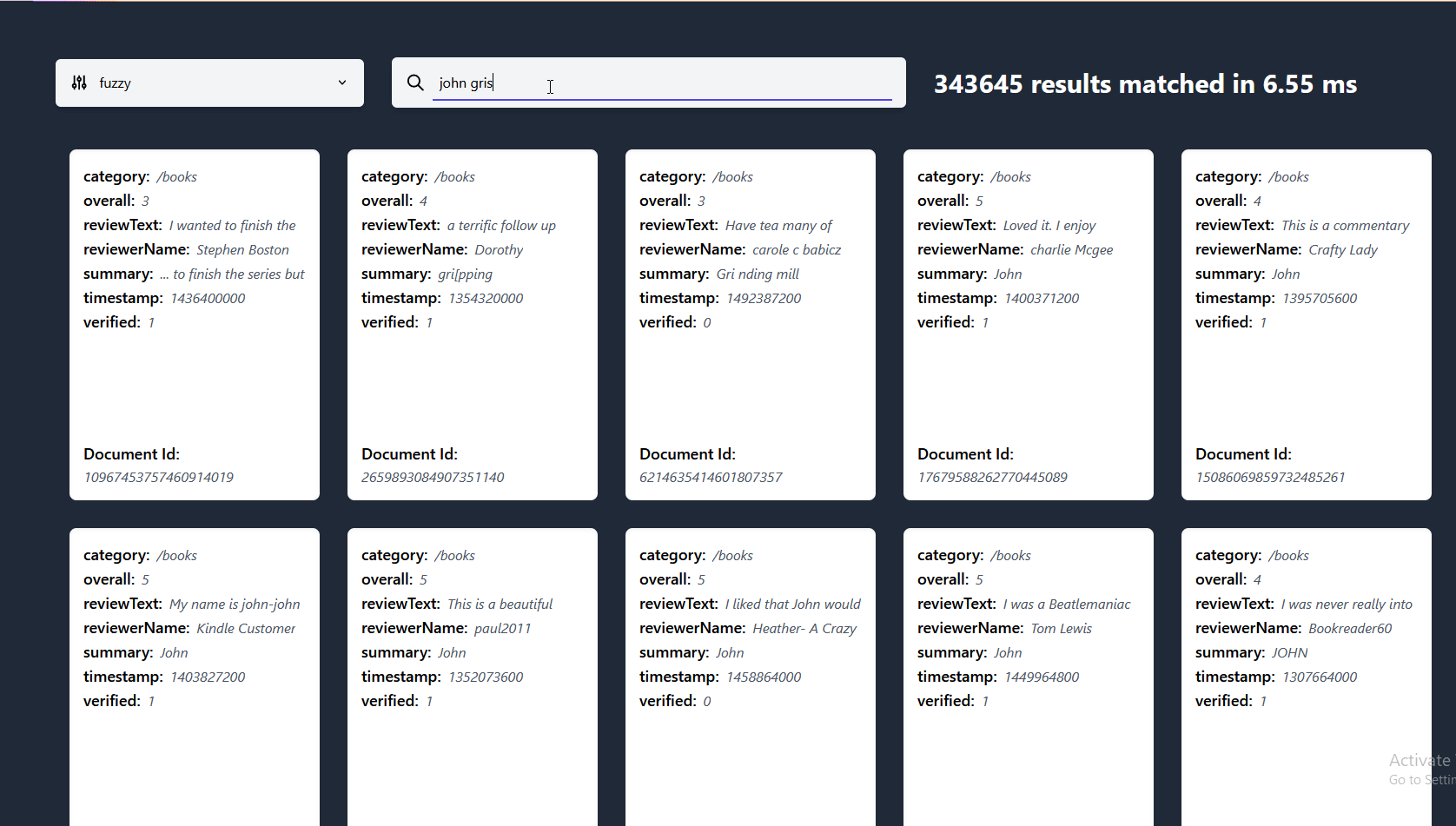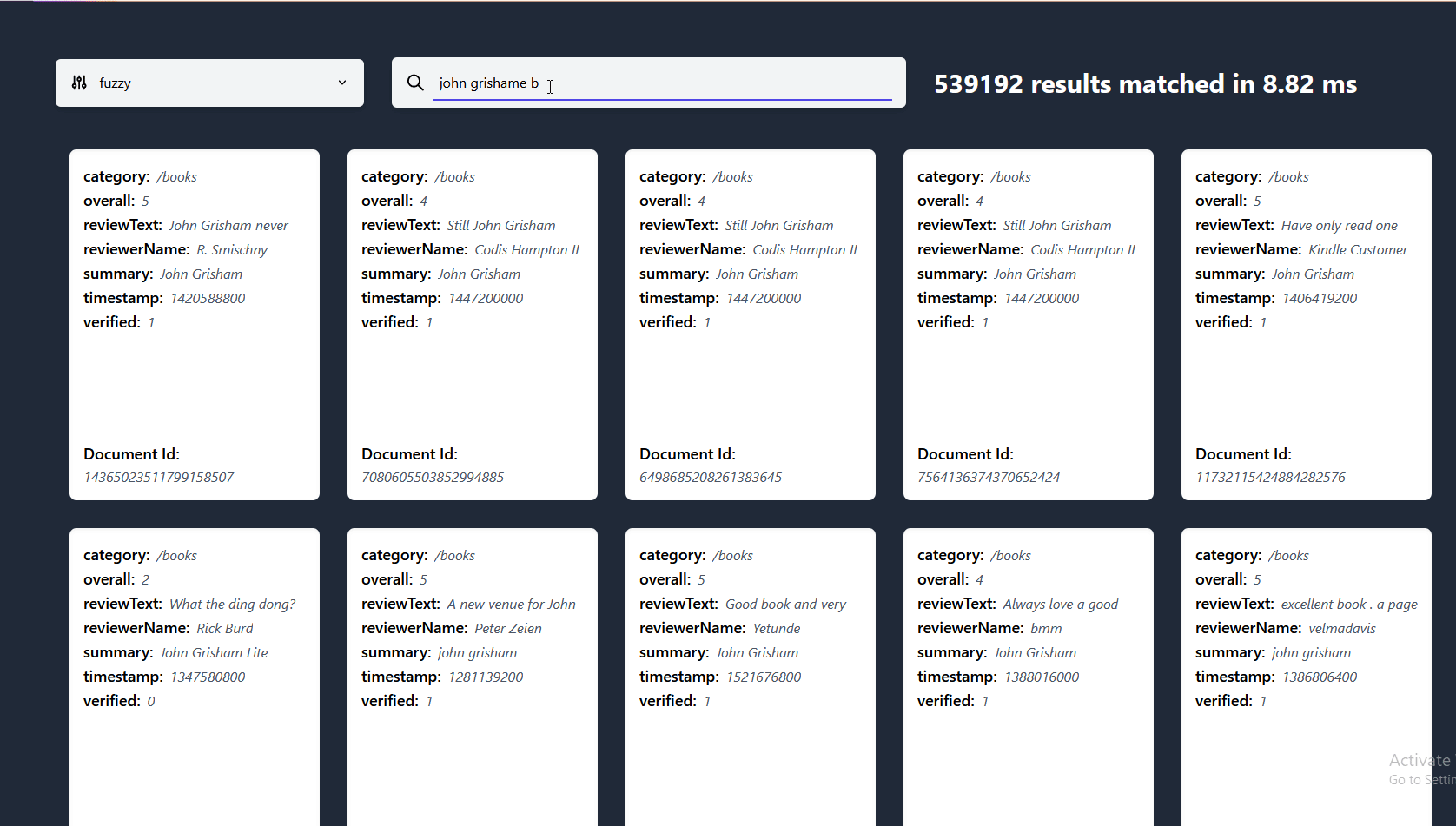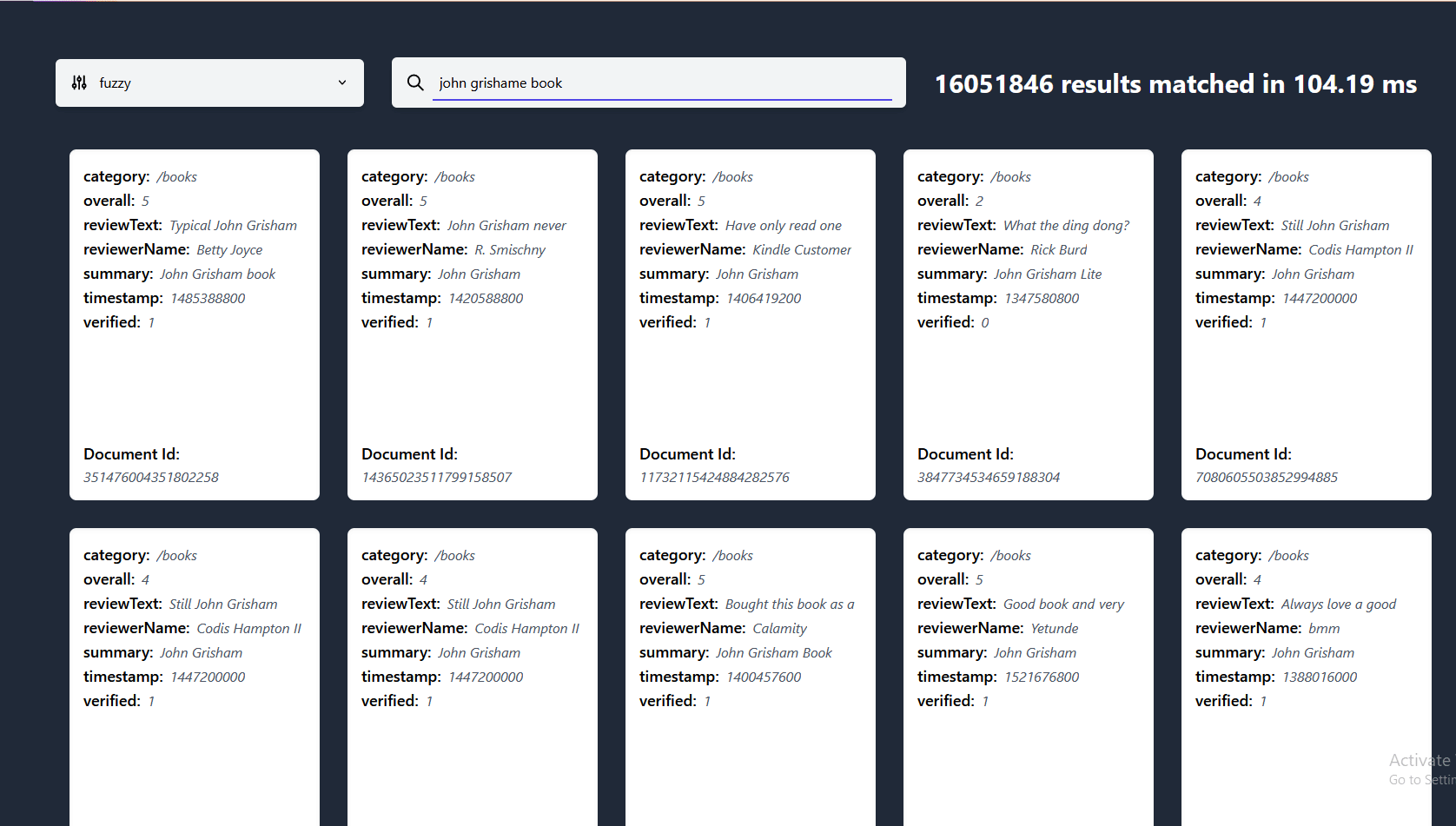
Tools :FastDeploy - Easy to use reasoning deployment toolkit
It covers the mainstream high-quality pre training model in the industry and provides out of the box development experience , Include Image classification 、 object detection 、 Image segmentation 、 Face detection 、 Recognition of key points of human body 、 Character recognition Wait for multiple tasks , Meet developers' multiple scenarios , Multiple hardware 、 Rapid deployment of multiple platforms .
GitHub: https://github.com/PaddlePaddle/FastDeploy

Tool system :HETU - High performance distributed deep learning system for large-scale automated distributed training
HETU River Map It's Peking University DAIR The laboratory developed a high-performance distributed deep learning system for trillion parameter deep learning model training . It considers the high availability of industry , Also consider the innovation of academia , Applicable 、 high efficiency 、 flexibility 、 Agility and many other advanced features .
GitHub: https://github.com/Hsword/Hetu

Tools :chaiNNer - Based on the flow chart / Image processing of nodes GUI
A flow chart based / Image processing graphical user interface of node (GUI), Designed to link image processing tasks ( Especially the task completed by neural network ) Become simple 、 Intuitive and customizable .
There are no existing upgrades GUI Can be like Chainer That provides a custom level for your image processing workflow . It can not only completely control the processing pipeline , You can also accomplish extremely complex tasks by connecting several nodes together .
GitHub: https://github.com/joeyballentine/chaiNNer
2. post & Share

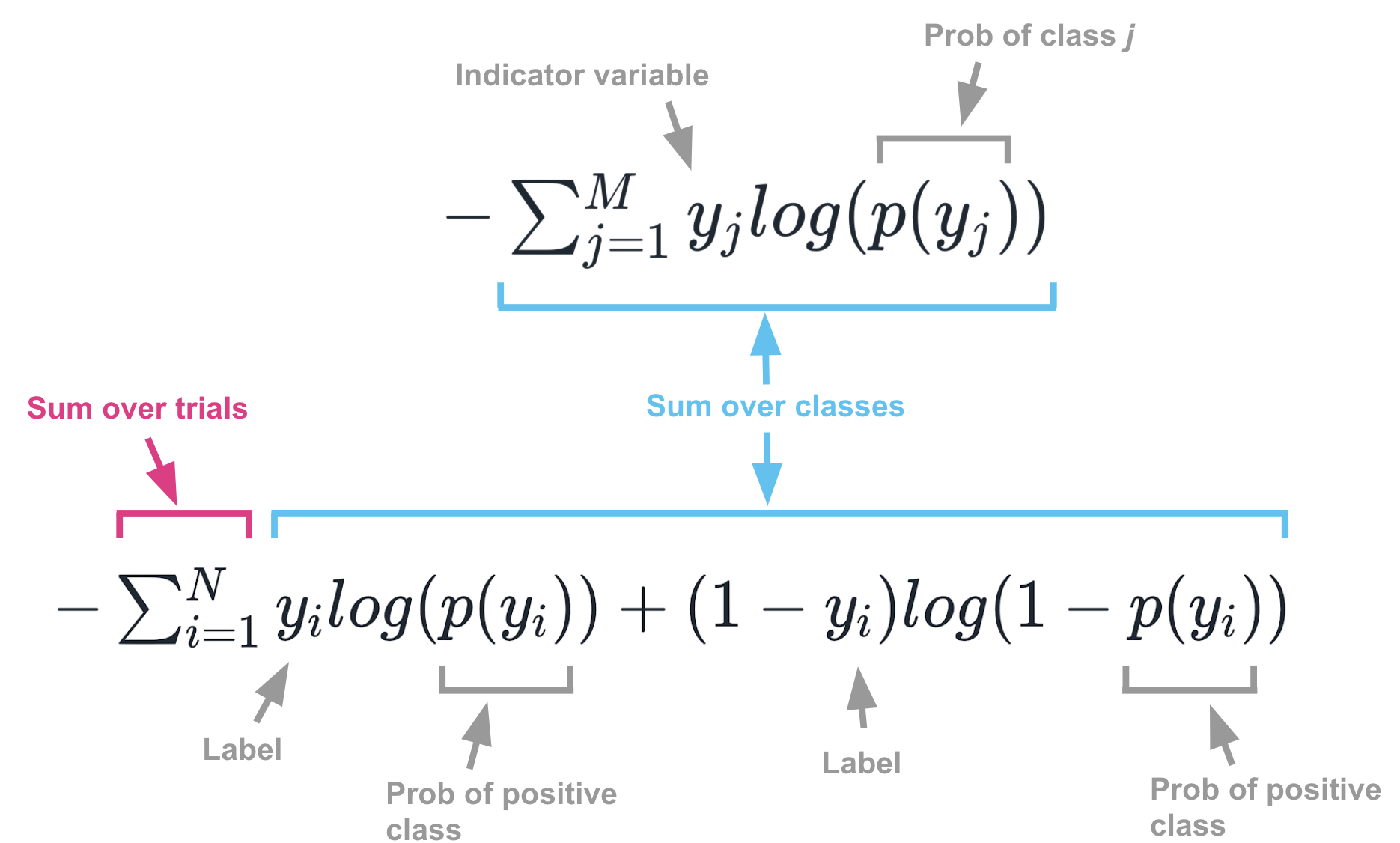
post : Cross entropy solution
《Things that confused me about cross-entropy》by Chris Said
Address : https://chris-said.io/2020/12/26/two-things-that-confused-me-about-cross-entropy
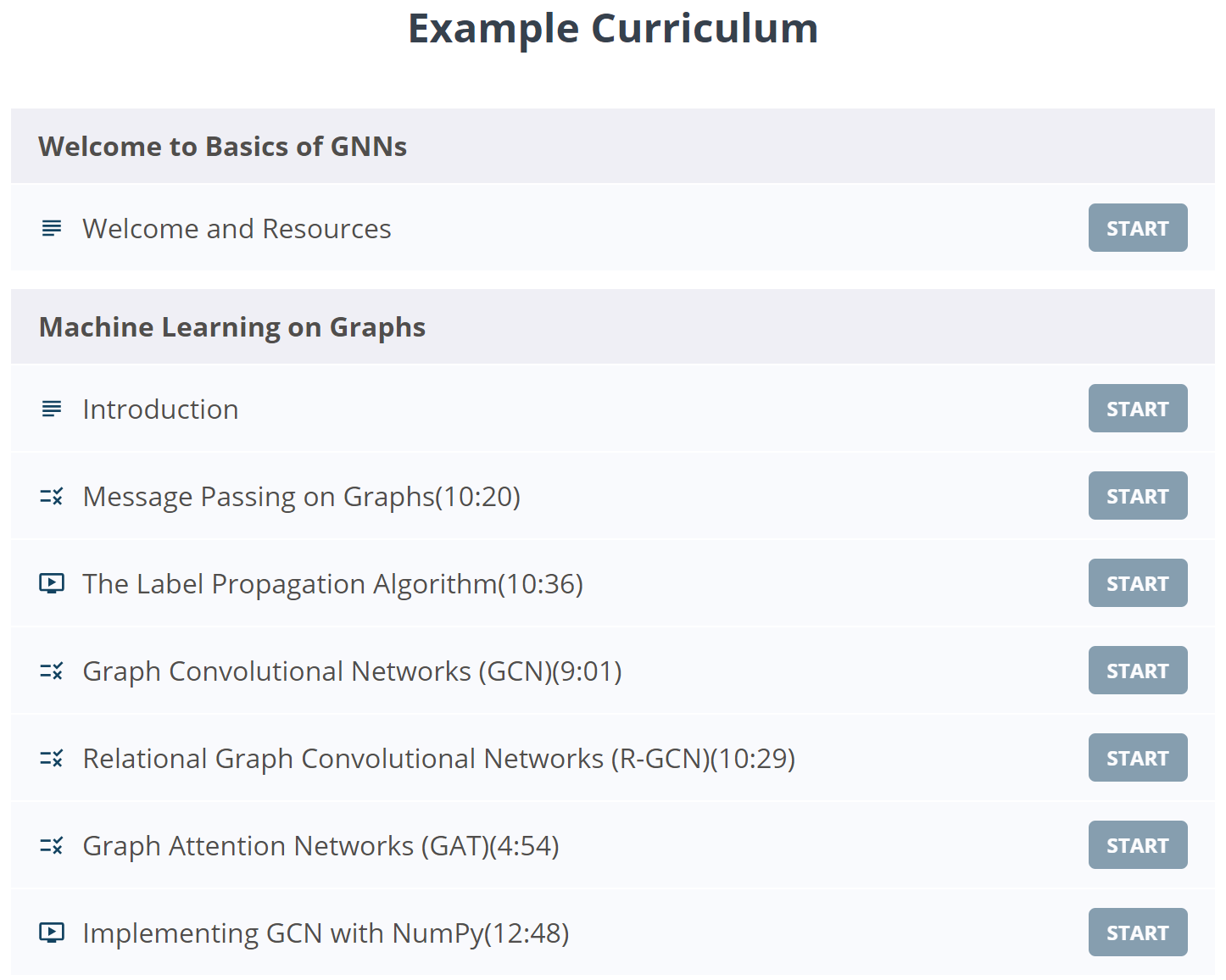
Course :《 Graph neural network foundation 》 Public class
《Basics of Graph Neural Networks | Welcome AI Overlords》by Zak Jost
This course is a quick tour of graph machine learning , Introduce the basic concept of message passing and explain the core algorithm ( Such as label propagation 、 Graph convolution network and graph attention network ), And show how to use only NumPy Realize graph convolution network from scratch .
Address : https://www.graphneuralnets.com/p//basics-of-gnns/
 |  |
3. data & resources

resource list : List of expert mixed related literature resources
This repo It's about Mixed experts (awesome mixture of experts) Collection of wonderful content , Including papers 、 Code etc. .
GitHub: https://github.com/XueFuzhao/awesome-mixture-of-experts
4. Research & The paper

You can click on the here Reply key daily , Get the collected papers for free .
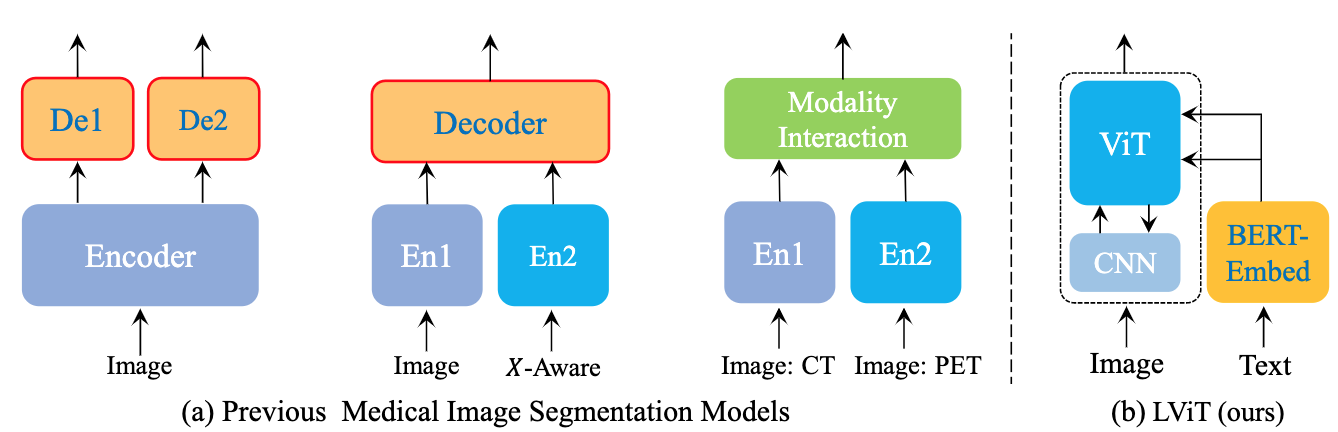
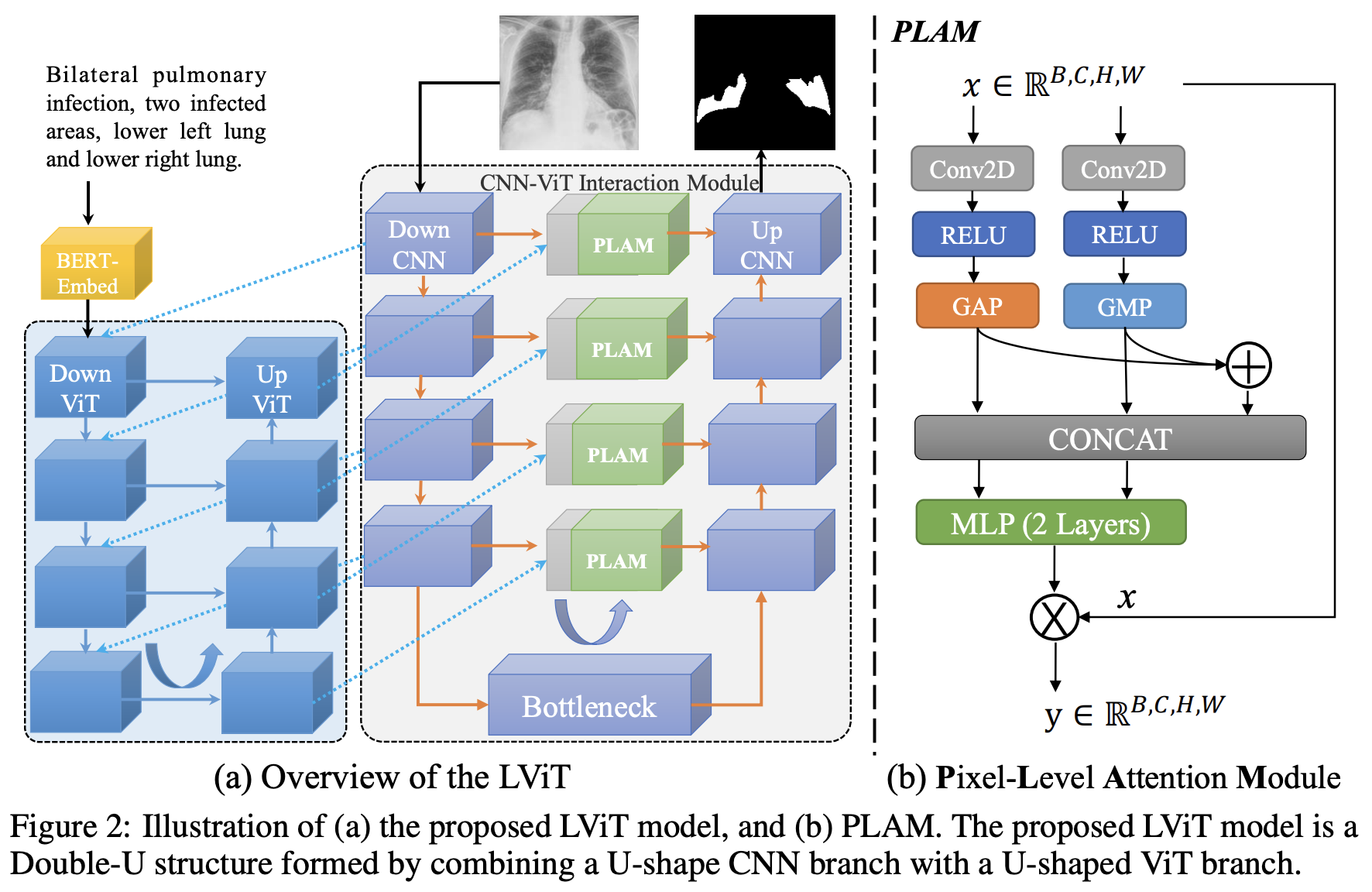
The paper :LViT: Language meets Vision Transformer in Medical Image Segmentation
Paper title :LViT: Language meets Vision Transformer in Medical Image Segmentation
Paper time :29 Jun 2022
Field : Medical care
Corresponding tasks :Medical Image Segmentation,Semantic Segmentation, Medical image segmentation , Semantic segmentation
Address of thesis :https://arxiv.org/abs/2206.14718
Code implementation :https://github.com/huanglizi/lvit
Author of the paper :Zihan Li, Yunxiang Li, Qingde Li, You Zhang, Puyang Wang, Dazhou Guo, Le Lu, Dakai Jin, Qingqi Hong
Brief introduction of the paper :In our model, medical text annotation is introduced to compensate for the quality deficiency in image data./ In our model , Medical text annotation is introduced to make up for the quality defects of image data .
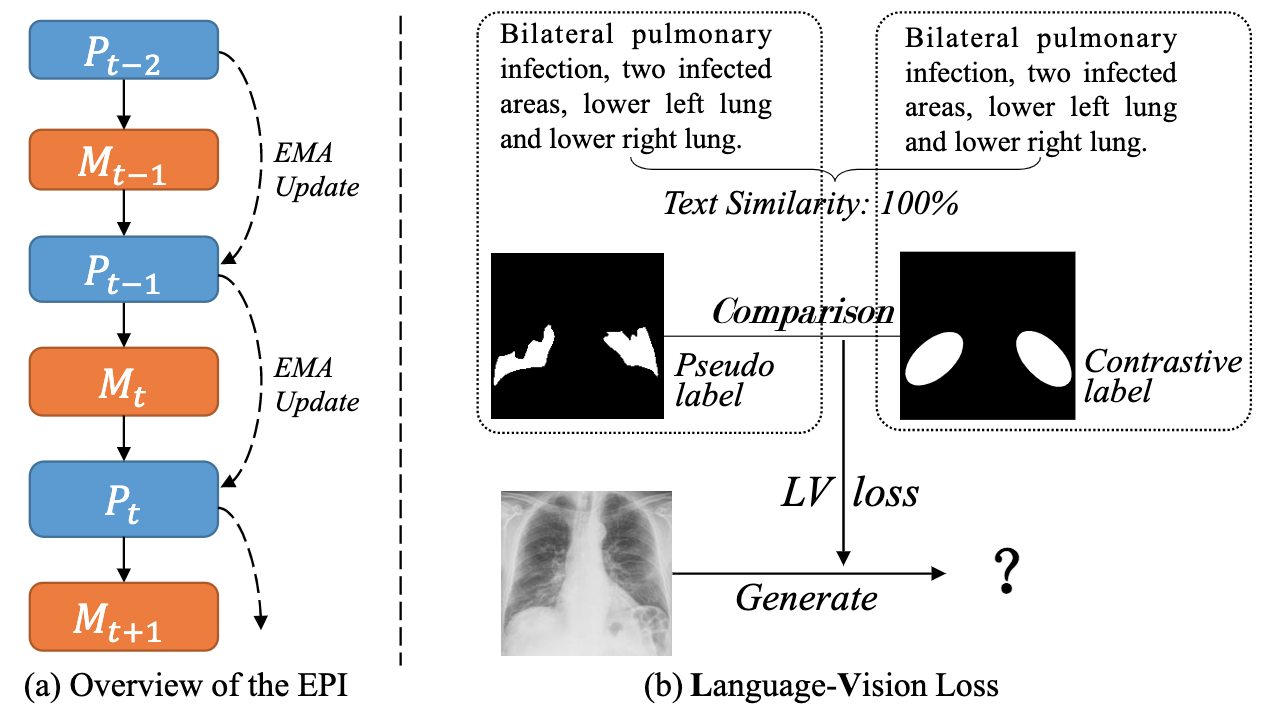
Abstract of paper :Deep learning has been widely used in medical image segmentation and other aspects. However, the performance of existing medical image segmentation models has been limited by the challenge of obtaining sufficient number of high-quality data with the high cost of data annotation. To overcome the limitation, we propose a new vision-language medical image segmentation model LViT (Language meets Vision Transformer). In our model, medical text annotation is introduced to compensate for the quality deficiency in image data. In addition, the text information can guide the generation of pseudo labels to a certain extent and further guarantee the quality of pseudo labels in semi-supervised learning. We also propose the Exponential Pseudo label Iteration mechanism (EPI) to help extend the semi-supervised version of LViT and the Pixel-Level Attention Module (PLAM) to preserve local features of images. In our model, LV (Language-Vision) loss is designed to supervise the training of unlabeled images using text information directly. To validate the performance of LViT, we construct multimodal medical segmentation datasets (image + text) containing pathological images, X-rays,etc. Experimental results show that our proposed LViT has better segmentation performance in both fully and semi-supervised conditions. Code and datasets are available at https://github.com/huanglizi/lvit
Deep learning has been widely used in medical image segmentation and other aspects . However , The performance of existing medical image segmentation models has been challenged , Mainly limited by the need for a sufficient number of high-quality data and high-cost data annotation . To overcome this limitation , We propose a new visual language medical image segmentation model LViT(Language meets Vision Transformer). In our model , Medical text annotation is introduced to make up for the quality defects of image data . Besides , Text information can guide the generation of pseudo tags to a certain extent , Further ensure the quality of pseudo tags in semi supervised learning . We also propose an exponential pseudo label iteration mechanism (EPI) To help extend the semi supervised version LViT And pixel level attention module (PLAM), To preserve the local features of the image . In our model ,LV(Language-Vision) Loss is designed to supervise the training of unlabeled images that directly use text information . In order to verify LViT Performance of , We constructed a multimodal medical segmentation dataset ( Images + Text ), Including pathological images 、X Rays, etc . Experimental results show that , What we proposed LViT It has better segmentation performance under both complete and semi supervised conditions . Code and data sets can be found in https://github.com/huanglizi/lvit obtain .
The paper :VLCap: Vision-Language with Contrastive Learning for Coherent Video Paragraph Captioning
Paper title :VLCap: Vision-Language with Contrastive Learning for Coherent Video Paragraph Captioning
Paper time :26 Jun 2022
Field : Computer vision
Corresponding tasks :Contrastive Learning,Video Captioning, Comparative learning , Video subtitles
Address of thesis :https://arxiv.org/abs/2206.12972
Code implementation :https://github.com/UARK-AICV/VLCAP
Author of the paper :Kashu Yamazaki, Sang Truong, Khoa Vo, Michael Kidd, Chase Rainwater, Khoa Luu, Ngan Le
Brief introduction of the paper :In this paper, we leverage the human perceiving process, that involves vision and language interaction, to generate a coherent paragraph description of untrimmed videos./ In this paper , We use human perception , Including the interaction between vision and language , Produce a coherent paragraph description of the untrimmed video .
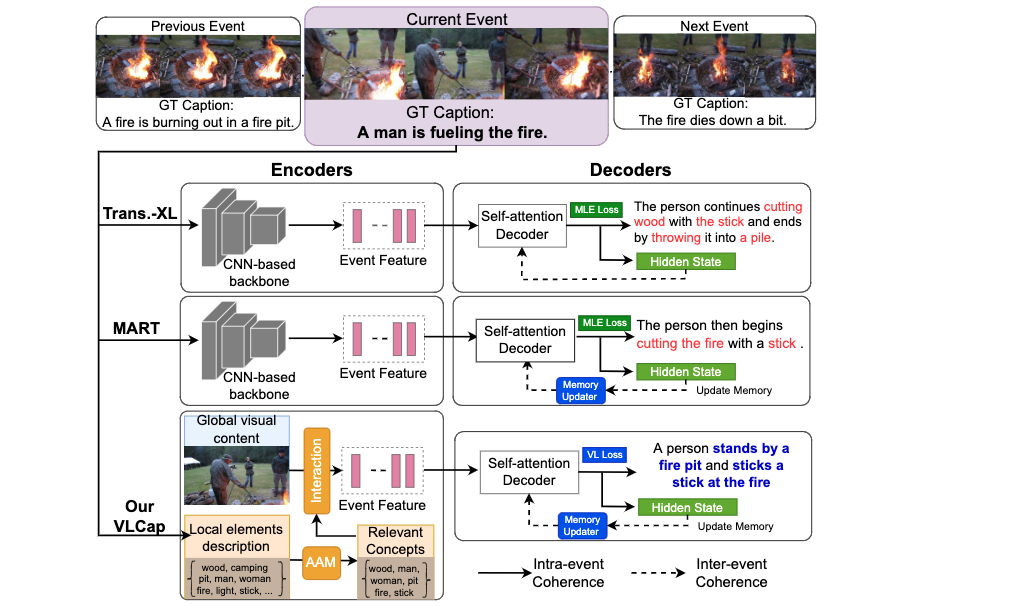
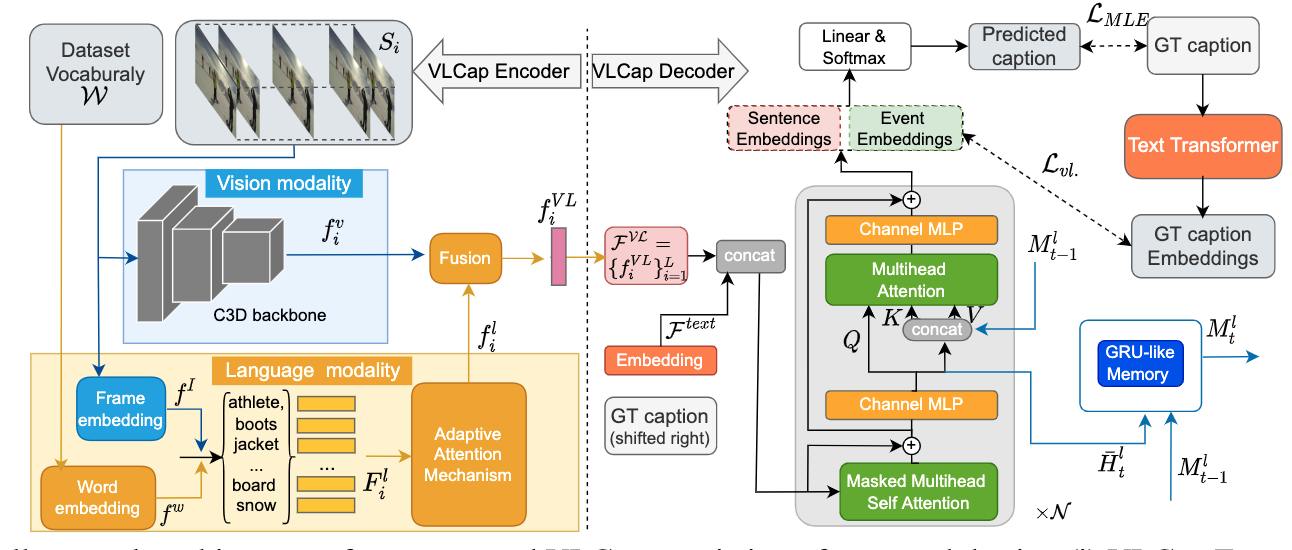
Abstract of paper :In this paper, we leverage the human perceiving process, that involves vision and language interaction, to generate a coherent paragraph description of untrimmed videos. We propose vision-language (VL) features consisting of two modalities, i.e., (i) vision modality to capture global visual content of the entire scene and (ii) language modality to extract scene elements description of both human and non-human objects (e.g. animals, vehicles, etc), visual and non-visual elements (e.g. relations, activities, etc). Furthermore, we propose to train our proposed VLCap under a contrastive learning VL loss. The experiments and ablation studies on ActivityNet Captions and YouCookII datasets show that our VLCap outperforms existing SOTA methods on both accuracy and diversity metrics.
In this paper , We use human perception , Including the interaction between vision and language , To generate a coherent paragraph description of the untrimmed video . We propose a vision composed of two modes - Language (VL) features , namely :(1) Visual mode captures the overall visual content of the entire scene ;(2) Language patterns extract human and non-human objects ( Such as animals 、 Vehicles, etc )、 Visual and non visual elements ( Such as relationship 、 Activities, etc ) Description of scene elements . Besides , We suggest learning by comparison VL Under the loss of training we put forward VLCap. Yes ActivityNet Captions and YouCookII Experimental and ablation studies of data sets show , our VLCap It is better than the existing SOTA Method .
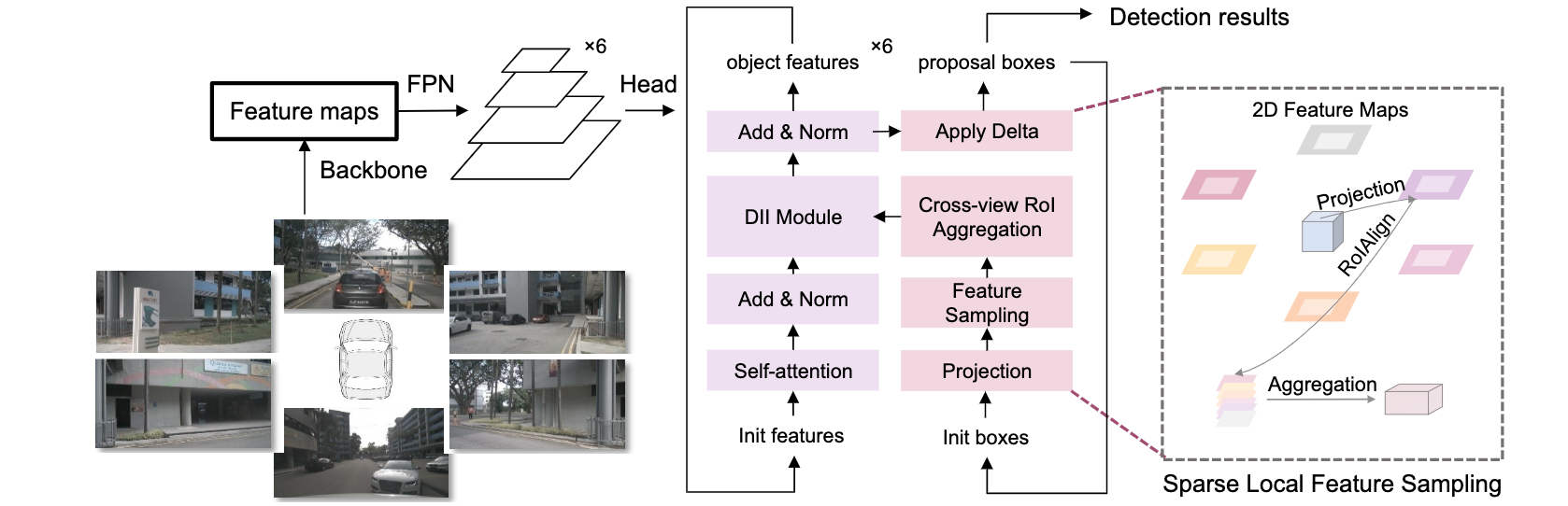
The paper :SRCN3D: Sparse R-CNN 3D Surround-View Camera Object Detection and Tracking for Autonomous Driving
Paper title :SRCN3D: Sparse R-CNN 3D Surround-View Camera Object Detection and Tracking for Autonomous Driving
Paper time :29 Jun 2022
Field : Computer vision
Corresponding tasks :3D Multi-Object Tracking,Autonomous Driving,Multi-Object Tracking,object-detection,Object Detection,Object Tracking, Three dimensional multi-target tracking , Autonomous driving , Multi target tracking , Target detection , object detection , Target tracking
Address of thesis :https://arxiv.org/abs/2206.14451
Code implementation :https://github.com/synsin0/srcn3d
Author of the paper :Yining Shi, Jingyan Shen, Yifan Sun, Yunlong Wang, Jiaxin Li, Shiqi Sun, Kun Jiang, Diange Yang
Brief introduction of the paper :This paper proposes Sparse R-CNN 3D (SRCN3D), a novel two-stage fully-convolutional mapping pipeline for surround-view camera detection and tracking./ This paper proposes sparse R-CNN 3D(SRCN3D), This is a new two-stage complete convolution mapping pipeline , For the detection and tracking of the look around camera .
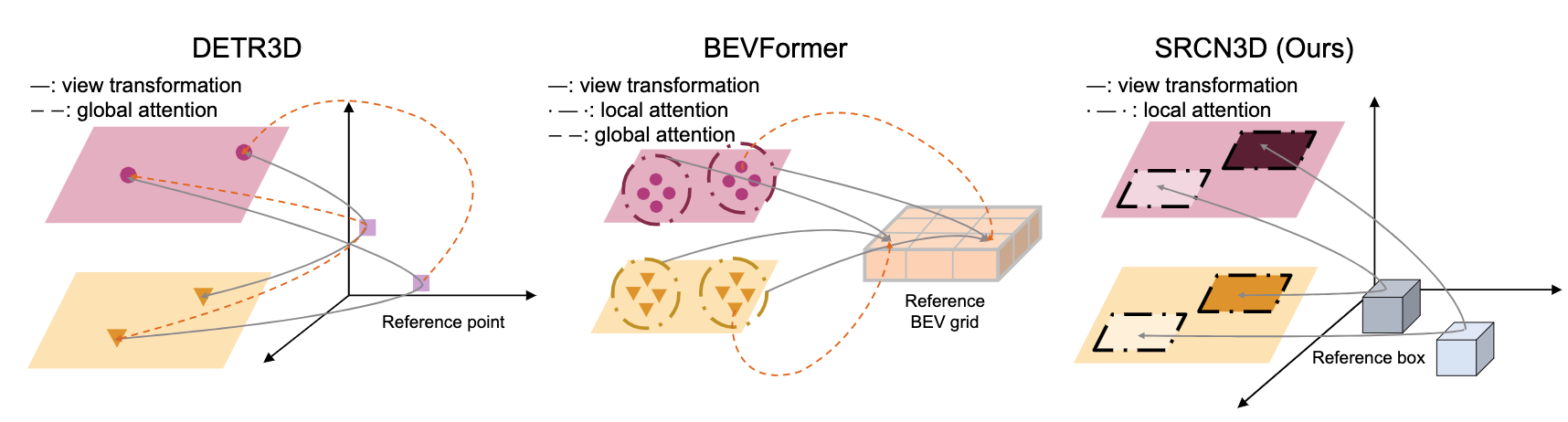
Abstract of paper :Detection And Tracking of Moving Objects (DATMO) is an essential component in environmental perception for autonomous driving. While 3D detectors using surround-view cameras are just flourishing, there is a growing tendency of using different transformer-based methods to learn queries in 3D space from 2D feature maps of perspective view. This paper proposes Sparse R-CNN 3D (SRCN3D), a novel two-stage fully-convolutional mapping pipeline for surround-view camera detection and tracking. SRCN3D adopts a cascade structure with twin-track update of both fixed number of proposal boxes and proposal latent features. Proposal boxes are projected to perspective view so as to aggregate Region of Interest (RoI) local features. Based on that, proposal features are refined via a dynamic instance interactive head, which then generates classification and the offsets applied to original bounding boxes. Compared to prior arts, our sparse feature sampling module only utilizes local 2D features for adjustment of each corresponding 3D proposal box, leading to a complete sparse paradigm. The proposal features and appearance features are both taken in data association process in a multi-hypotheses 3D multi-object tracking approach. Extensive experiments on nuScenes dataset demonstrate the effectiveness of our proposed SRCN3D detector and tracker. Code is available at https://github.com/synsin0/srcn3d
Detection and tracking of moving objects (DATMO) It is an important part of automatic driving environment perception . Although three-dimensional detectors using surround cameras are just emerging , However, there is a growing trend to use different converter based methods to learn 3D spatial queries from perspective 2D feature maps . This paper proposes sparse R-CNN 3D(SRCN3D), This is a novel two-stage full convolution mapping pipeline , Used for looking around camera detection and tracking .SRCN3D A cascade structure is adopted , Double track update of a fixed number of candidate boxes and candidate potential features . Candidate boxes are projected into the perspective , To gather regions of interest (RoI) Local characteristics of . On this basis , Through a dynamic instance interaction header to improve the proposed features , Then generate the classification and the offset applied to the original bounding box . Compared with previous art , Our sparse feature sampling module only uses local two-dimensional features to adjust each corresponding three-dimensional proposal box , Thus forming a complete sparse paradigm . In a multi hypothesis 3D multi object tracking method , Suggested features and appearance features are taken in the process of Data Association . stay nuScenes A large number of experiments on data sets have proved our proposed SRCN3D Effectiveness of detectors and trackers . The code can be found in https://github.com/synsin0/srcn3d see .
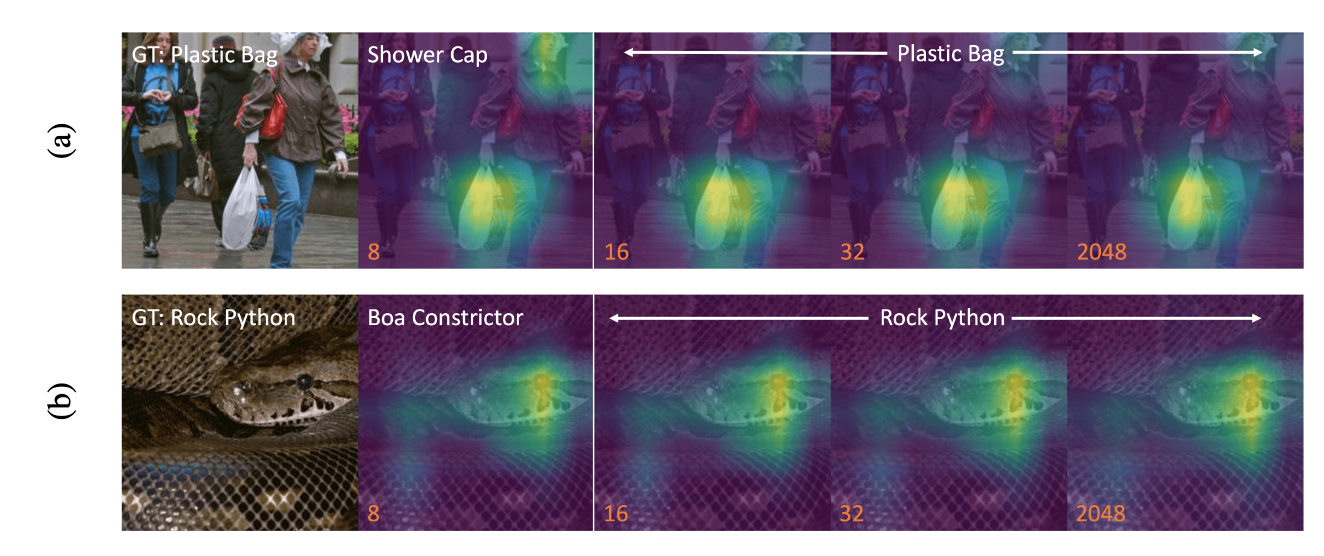
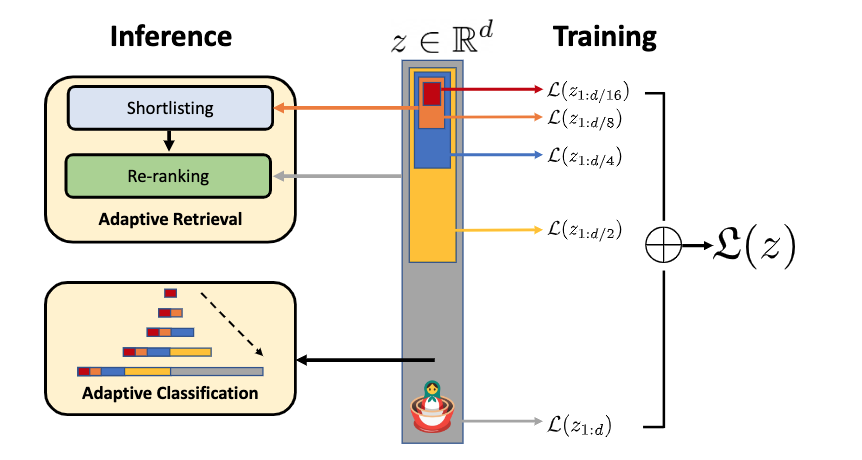
The paper :Matryoshka Representations for Adaptive Deployment
Paper title :Matryoshka Representations for Adaptive Deployment
Paper time :26 May 2022
Field : machine learning
Corresponding tasks :Representation Learning, Representational learning
Address of thesis :https://arxiv.org/abs/2205.13147
Code implementation :https://github.com/raivnlab/mrl
Author of the paper :Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, KaiFeng Chen, Sham Kakade, Prateek Jain, Ali Farhadi
Brief introduction of the paper :The flexibility within the learned Matryoshka Representations offer: (a) up to 14x smaller embedding size for ImageNet-1K classification at the same level of accuracy; (b) up to 14x real-world speed-ups for large-scale retrieval on ImageNet-1K and 4K; and up to 2% accuracy improvements for long-tail few-shot classification, all while being as robust as the original representations./ Learned Matryoshka The flexibility of notation provides :(a) With the same accuracy ,ImageNet-1K The embedded size of classification is reduced 14 times ;(b) ImageNet-1K and 4K The actual speed of large-scale retrieval has been improved 14 times ; as well as The classification accuracy of a few photos with long tails has been improved 2%, And all of this is as powerful as the original representation .
Abstract of paper :Learned representations are a central component in modern ML systems, serving a multitude of downstream tasks. When training such representations, it is often the case that computational and statistical constraints for each downstream task are unknown. In this context rigid, fixed capacity representations can be either over or under-accommodating to the task at hand. This leads us to ask: can we design a flexible representation that can adapt to multiple downstream tasks with varying computational resources? Our main contribution is Matryoshka Representation Learning (MRL) which encodes information at different granularities and allows a single embedding to adapt to the computational constraints of downstream tasks. MRL minimally modifies existing representation learning pipelines and imposes no additional cost during inference and deployment. MRL learns coarse-to-fine representations that are at least as accurate and rich as independently trained low-dimensional representations. The flexibility within the learned Matryoshka Representations offer: (a) up to 14x smaller embedding size for ImageNet-1K classification at the same level of accuracy; (b) up to 14x real-world speed-ups for large-scale retrieval on ImageNet-1K and 4K; and up to 2% accuracy improvements for long-tail few-shot classification, all while being as robust as the original representations. Finally, we show that MRL extends seamlessly to web-scale datasets (ImageNet, JFT) across various modalities – vision (ViT, ResNet), vision + language (ALIGN) and language (BERT). MRL code and pretrained models are open-sourced at https://github.com/raivnlab/mrl
Representational learning is modern ML Core components of the system , Serve many downstream tasks . When training this representation , Usually , The computational and statistical constraints of each downstream task are unknown . under these circumstances , Rigid 、 The characterization of fixed capacity is important for the task at hand , There may be problems of over adaptation or inadaptability . Then guide us to think : Can you design a flexible representation , To accommodate multiple downstream tasks with different computing resources ? Our main contribution is Matryoshka Representational learning (MRL), It encodes information at different granularity , And allow a single embedding to adapt to the computational constraints of downstream tasks .MRL The existing representation learning pipeline is modified to the greatest extent , And there is no additional cost in the process of reasoning and deployment .MRL The representation of learning from coarse to fine , At least as accurate and rich as the low dimensional representation of independent training . Learned Matryoshka Flexibility in characterization provides :(a) With the same accuracy ,ImageNet-1K The embedding size of classification is reduced at most 14 times ;(b) stay ImageNet-1K and 4K In large-scale retrieval , The actual speed increases at most 14 times ; as well as (c) In the classification of a few photos with long tails , The accuracy can be improved at most 2%, At the same time, it is as powerful as the original representation . Last , We show that ,MRL Data sets that can be seamlessly extended to network scale (ImageNet,JFT), Across all modes – Vision (ViT,ResNet), Vision + Language (ALIGN) And language (BERT).MRL The code and pre training model of have been in https://github.com/raivnlab/mrl Release .
The paper :Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
Paper title :Diffusion Autoencoders: Toward a Meaningful and Decodable Representation
Paper time :CVPR 2022
Field : Computer vision
Corresponding tasks :Denoising,Image Generation,Representation Learning, Noise reduction , Image generation , Representational learning
Address of thesis :https://arxiv.org/abs/2111.15640
Code implementation :https://github.com/phizaz/diffae
Author of the paper :Konpat Preechakul, Nattanat Chatthee, Suttisak Wizadwongsa, Supasorn Suwajanakorn
Brief introduction of the paper :Our key idea is to use a learnable encoder for discovering the high-level semantics, and a DPM as the decoder for modeling the remaining stochastic variations./ Our key idea is to use a learnable encoder to discover high-level semantics , And use DPM As a decoder to simulate the rest of the random changes .
Abstract of paper :Diffusion probabilistic models (DPMs) have achieved remarkable quality in image generation that rivals GANs’. But unlike GANs, DPMs use a set of latent variables that lack semantic meaning and cannot serve as a useful representation for other tasks. This paper explores the possibility of using DPMs for representation learning and seeks to extract a meaningful and decodable representation of an input image via autoencoding. Our key idea is to use a learnable encoder for discovering the high-level semantics, and a DPM as the decoder for modeling the remaining stochastic variations. Our method can encode any image into a two-part latent code, where the first part is semantically meaningful and linear, and the second part captures stochastic details, allowing near-exact reconstruction. This capability enables challenging applications that currently foil GAN-based methods, such as attribute manipulation on real images. We also show that this two-level encoding improves denoising efficiency and naturally facilitates various downstream tasks including few-shot conditional sampling. Please visit our project page: https://diff-ae.github.io/
Diffusion probability model (DPMs) Remarkable quality has been achieved in image generation , It can be done with GANs Comparable . But with GANs The difference is ,DPMs Use a set of potential variables that lack semantics , It cannot be used as a useful representation of other tasks . This paper discusses the use of DPMs The possibility of representational learning , And try to extract the meaningful and interpretable representation of the input image through automatic coding . Our key idea is to use a learnable encoder to discover high-level semantics , And use DPM As a decoder to simulate the rest of the random changes . Our method can encode any image into two parts of latent code , The first part is semantic and linear , The second part captures random details , Allow near accurate reconstruction . This ability makes it possible to GAN The challenging application of the restricted based approach becomes possible , For example, attribute operations on real images . We also show that , This two-stage coding improves the denoising efficiency , And naturally promote various downstream tasks , Including less sample condition generation . Please visit our project page :https://diff-ae.github.io/



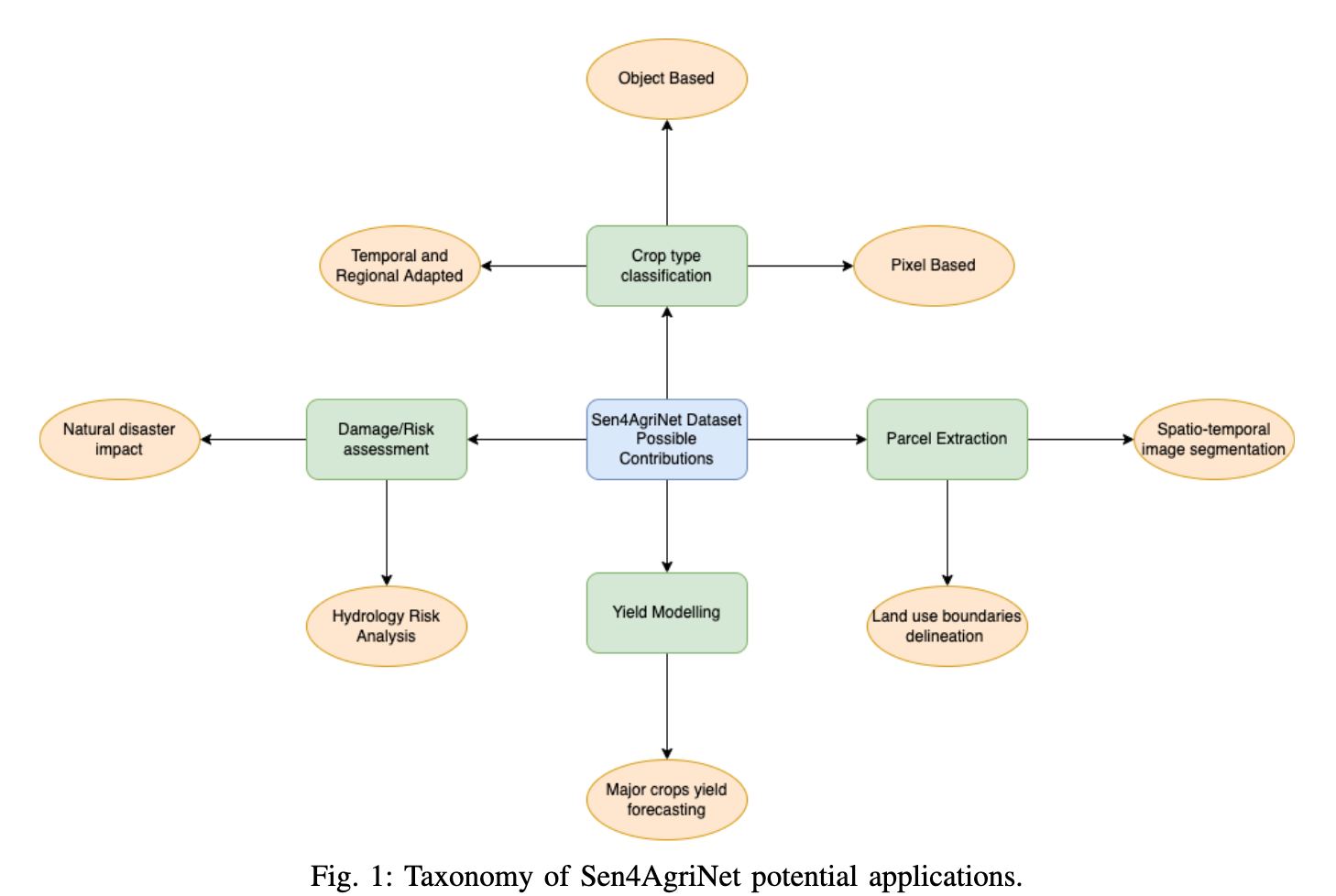
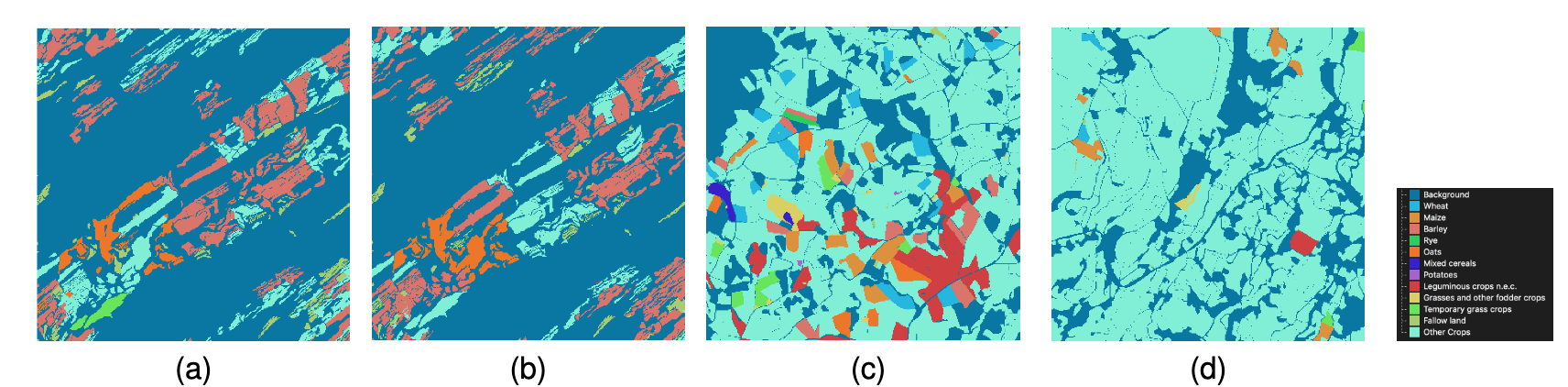
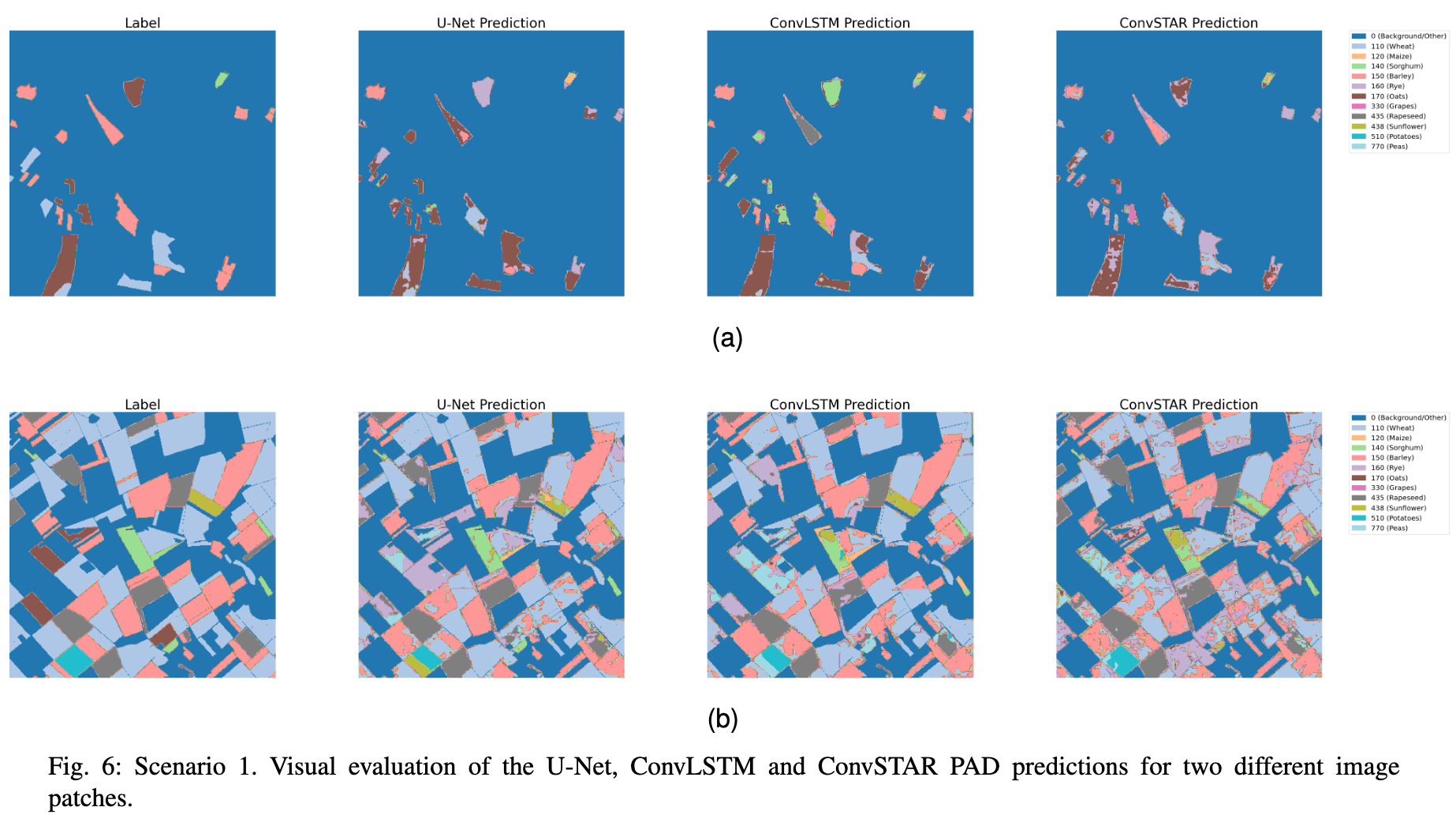
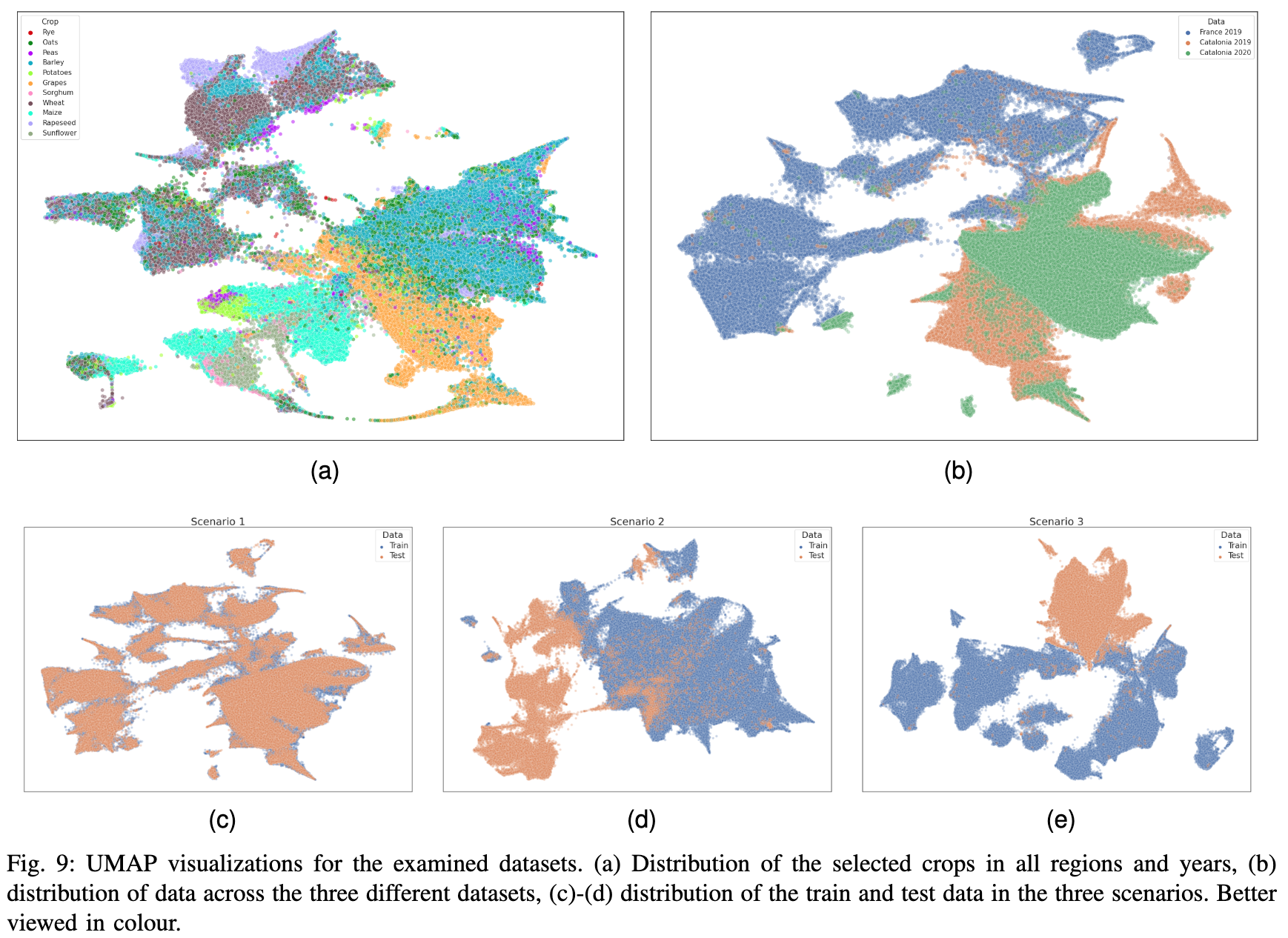
The paper :A Sentinel-2 multi-year, multi-country benchmark dataset for crop classification and segmentation with deep learning
Paper title :A Sentinel-2 multi-year, multi-country benchmark dataset for crop classification and segmentation with deep learning
Paper time :2 Apr 2022
Field : Computer vision
Corresponding tasks :Crop Classification,Semantic Segmentation,Time Series, Crop classification , Semantic segmentation , The time series
Address of thesis :https://arxiv.org/abs/2204.00951
Code implementation :https://github.com/orion-ai-lab/s4a
Author of the paper :Dimitrios Sykas, Maria Sdraka, Dimitrios Zografakis, Ioannis Papoutsis
Brief introduction of the paper :In this work we introduce Sen4AgriNet, a Sentinel-2 based time series multi country benchmark dataset, tailored for agricultural monitoring applications with Machine and Deep Learning./ In this work , We introduced Sen4AgriNet, This is a base Sentinel-2 Multi Country benchmark data set of time series , Tailored for agricultural monitoring applications through machines and deep learning .
Abstract of paper :In this work we introduce Sen4AgriNet, a Sentinel-2 based time series multi country benchmark dataset, tailored for agricultural monitoring applications with Machine and Deep Learning. Sen4AgriNet dataset is annotated from farmer declarations collected via the Land Parcel Identification System (LPIS) for harmonizing country wide labels. These declarations have only recently been made available as open data, allowing for the first time the labeling of satellite imagery from ground truth data. We proceed to propose and standardise a new crop type taxonomy across Europe that address Common Agriculture Policy (CAP) needs, based on the Food and Agriculture Organization (FAO) Indicative Crop Classification scheme. Sen4AgriNet is the only multi-country, multi-year dataset that includes all spectral information. It is constructed to cover the period 2016-2020 for Catalonia and France, while it can be extended to include additional countries. Currently, it contains 42.5 million parcels, which makes it significantly larger than other available archives. We extract two sub-datasets to highlight its value for diverse Deep Learning applications; the Object Aggregated Dataset (OAD) and the Patches Assembled Dataset (PAD). OAD capitalizes zonal statistics of each parcel, thus creating a powerful label-to-features instance for classification algorithms. On the other hand, PAD structure generalizes the classification problem to parcel extraction and semantic segmentation and labeling. The PAD and OAD are examined under three different scenarios to showcase and model the effects of spatial and temporal variability across different years and different countries.
In this work , We introduced Sen4AgriNet, This is a base Sentinel-2 Multi Country benchmark data set of time series , Machine learning and deep learning are customized for agricultural monitoring applications .Sen4AgriNet The annotation of the dataset comes from the parcel recognition system (LPIS) Farmers' declarations collected , Used to coordinate nationwide labels . These statements have only recently been made available as public data , For the first time, it is allowed to label satellite images from real ground data . According to the food and Agriculture Organization (FAO) Indicative crop classification scheme , Put forward new classification standards of crop types in Europe , To meet the common agricultural policy (CAP) The need for .Sen4AgriNet It is the only multi-national data set that includes all spectral information for many years . Its construction covers 2016-2020 The situation of Catalonia and France in , At the same time, it can be extended to other countries . at present , It contains 4250 Million packets , This makes it significantly larger than other available files . We extracted two sub datasets , To highlight the value of its application to different depth learning ; Object summary dataset (OAD) And patch assembly dataset (PAD).OAD Use the zoning statistics of each plot , Thus, it creates a powerful example of label to feature for classification algorithm . On the other hand ,PAD Structure generalizes the classification problem as parcel extraction 、 Semantic segmentation and labeling .PAD and OAD Tested in three different situations , To show and simulate the impact of spatial and temporal changes in different years and countries .
We are ShowMeAI, Dedicated to communication AI High quality content , Share industry solutions , Accelerate every technological growth with knowledge ! Click to see List of historical articles , Subscribe to topics in the official account #ShowMeAI Information daily , Can receive the latest daily push . Click on Thematic collection & Electronic monthly Quickly browse the complete works of each topic . Click on here Reply key daily Free access AI Electronic monthly and information package .

- author : Han Xinzi @ShowMeAI
- List of historical articles
- Thematic collection & Electronic monthly
- Statement : copyright , For reprint, please contact the platform and the author and indicate the source
- Welcome to reply , Please praise , Leave a message to recommend valuable articles 、 Tools or suggestions , We will reply as soon as possible ~
边栏推荐
- Is it safe to open an account online for stock speculation? Will you be cheated.
- 03-存储系统
- MySQL组合索引(多列索引)使用与优化案例详解
- Preliminary exploration of flask: WSGI
- 微博、虎牙挺进兴趣社区:同行不同路
- Redis publier et s'abonner
- UFO:微软学者提出视觉语言表征学习的统一Transformer,在多个多模态任务上达到SOTA性能!...
- flutter 报错 No MediaQuery widget ancestor found.
- IO flow: node flow and processing flow are summarized in detail.
- 音视频技术开发周刊 | 252
猜你喜欢

I plan to teach myself some programming and want to work as a part-time programmer. I want to ask which programmer has a simple part-time platform list and doesn't investigate the degree of the receiv

Helix Swarm中文包发布,Perforce进一步提升中国用户体验

Why do domestic mobile phone users choose iPhone when changing a mobile phone?

这几年爆火的智能物联网(AIoT),到底前景如何?

开源人张亮的 17 年成长路线,热爱才能坚持

Is BigDecimal safe to calculate the amount? Look at these five pits~~
金额计算用 BigDecimal 就万无一失了?看看这五个坑吧~~

Analysis of nearly 100 million dollars stolen and horizon cross chain bridge attacked

Halcon knowledge: NCC_ Model template matching
numpy笔记
随机推荐
Introduction to asynchronous task capability of function calculation - task trigger de duplication
Redis 發布和訂閱
Redis的4种缓存模式分享
从0到1建设智能灰度数据体系:以vivo游戏中心为例
web聊天室实现
Programmers exposed that they took private jobs: they took more than 30 orders in 10 months, with a net income of 400000
ES6 modularization
Halcon knowledge: NCC_ Model template matching
Introduction to modern control theory + understanding
How to match chords
一篇文章搞懂Go语言中的Context
Leecode learning notes - Joseph problem
[learning notes] matroid
Graduation season - personal summary
On the implementation plan of MySQL explain
Helix swarm Chinese package is released, and perforce further improves the user experience in China
.Net 应用考虑x64生成
浮点数如何与0进行比较?
Quick introduction to automatic control principle + understanding
Unity update process_ Principle of unity synergy