当前位置:网站首页>Cann operator: using iterators to efficiently realize tensor data cutting and blocking processing
Cann operator: using iterators to efficiently realize tensor data cutting and blocking processing
2022-07-04 14:44:00 【Huawei cloud developer Alliance】
Abstract : This article takes Diagonal For example, operators , Introduce and explain in detail how to use iterators to n dimension Tensor Carry out mass data reading based on position coordinates .
This article is shared from Huawei cloud community 《CANN operator : Use iterators to achieve Tensor Data cutting and block processing 》, author : CatherineWang .
Mission scenarios and objectives
stay CANN aicpu Operator development and implementation , Often need to be right n dimension Tensor Slice (slice)、 cutting (dice)、 Transposition (transpose)、 Exchange specified dimension data (shuffle) Wait for the operation . The above operations are essentially data reading in sequence according to the specified rules , And write the read data into the new data address .
This article takes Diagonal For example, operators , Introduce and explain in detail how to use iterators to n dimension Tensor Carry out mass data reading based on position coordinates .
Diagonal The operator wants to extract diagonal elements from the data with two specified dimensions , Finally, the diagonal element of the tensor is returned . In essence, the operator passes through the attribute dim1 and dim2 Determine a matrix , Returns the diagonal elements of the matrix ( There is an offset offset), And put it in the last dimension . Not dim1 and dim2 Dimensions , Will be regarded as batch Dimension processing .
Conventional scheme :
Scheme 1 : take shape by s, The number of elements is numel Of Input Tensor:x Turn into Eigen::Tensor:eigen_x; Yes eigen_x Conduct shuffle operation , take dim1 and dim2 Change to the penultimate dimension and the penultimate dimension ; adopt reshape Operation will eigen_x Change into a three-dimensional Eigen::Tensor:reshape_x,shape=(numel/ s[dim1]/s[dim2],s[dim1],s[dim2]); Take diagonal elements for the last two-dimensional data , And assign the final data to the output data address . Be careful : because Eigen::Tensor<typename T, int NumIndices_> Cannot dynamically set dimensions , namely NumIndices_ Item must be a specific value , Therefore, you need to define the corresponding dimension in advance Eigen::Tensor spare .
Option two : For one n Dimensional Tensor, utilize n layer for Cycle the positioning and reading of data , And take the diagonal value .
It can be seen that the above two schemes are cumbersome in the implementation of dynamic size input calculation , You need to set the corresponding dimension in advance according to the situation Eigen::Tensor or for Loop logic structure , That is, there are dimensional constraints .
Prepare knowledge and analysis
We know we'll AICPU in , For one Tensor, We can get through GetTensorShape、GetData Wait a function to get Tensor Shape and size 、 Specific data address and other information . However, we cannot directly obtain the data value of the specified position in the form of position coordinates .
1. step
First, introduce the step size (stride) The concept of ( If you have mastered this part of knowledge, you can directly jump to the next part ).stride Is in the specified dimension dim The step size necessary to jump from one element to the next in . for example , For one shape=(2, 3, 4, 5) Of Tensor, Its stride=(60, 20, 5, 1). So if you want to get the above Tensor The middle position coordinate is [1, 2, 1, 3] The data of , Just find the number in the data address 108(=60*1+20*2+5*1+3) Bit corresponding value .
2. iterator
Define iterator PositionIterator, Contains private members pos_ and shape_, among pos_ Is the initial position ,shape_ Standard shape . By overloading ++ Symbol , Yes pos_ Make changes , Realize the self increment operation of iterators . Based on the above iterators , It can realize the given shape Take positions in sequence . For a given shape=(d_1,d_2,…,d_n), From the initial position (0,0,…,0) Start , Take... In turn (0,0,…,0,0), (0,0,…,0,1),…,(0,0,…,0,d_n-1), (0,0,…,1,0), (0,0,…,1,1),…, (d_1 - 1,d_2 - 1,…,d_{n-1}-1,d_{n}-1).
in fact , The above iterator can be understood as a base , For a given standard shape shape_=(d_1,d_2,…,d_n), The first i Bit operation is every d_i Into the 1. At the same time through PositionIterator .End() Control the end of the iterator . The specific implementation is as follows :
template <typename T>class PositionIterator { public: PositionIterator(){}; ~PositionIterator(){}; PositionIterator(std::vector<T> stt, std::vector<T> sh) { if (stt.size() != sh.size()) { PositionIterator(); } else { for (unsigned int i = 0; i < sh.size(); i++) { if (stt[i] >= sh[i]) { PositionIterator(); } } pos_ = stt; shape_ = sh; } } PositionIterator operator++() { pos_[shape_.size() - 1] += 1; for (unsigned int i = shape_.size() - 1; i > 0; i--) { if (pos_[i] / shape_[i] != 0) { pos_[i - 1] += pos_[i] / shape_[i]; pos_[i] = pos_[i] % shape_[i]; } } return *this; } bool End() { if (pos_[0] != shape_[0]) { return false; } return true; } std::vector<T> GetPos() { return pos_; } std::vector<T> GetShape() { return shape_; } private: std::vector<T> pos_; std::vector<T> shape_;};Diagonal The realization of operators
Using iterators , In general , We only need two floors for loop , Can be realized Diagonal The calculation of the operator . first floor for The loop is used to determine the division dim1 and dim2 Position coordinates of dimensions , The second floor for A loop is used for dim1 and dim2 The corresponding dimension determines the position of diagonal elements , Through such two layers for loop , The position of diagonal elements can be determined . Through such value processing , Compare with Eigen Realize the idea , The computing speed has been significantly improved , And there are no dimensional restrictions ,st The test results are compared as follows :
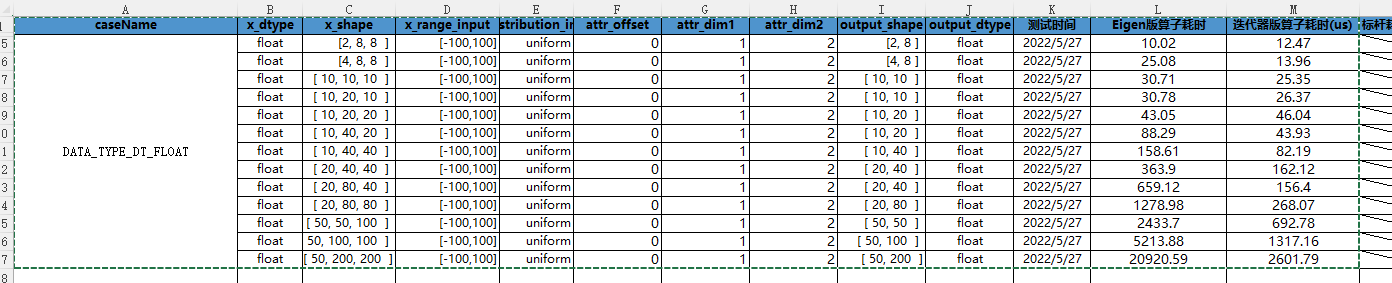
See the following code for specific implementation :
template <typename T>uint32_t DiagonalCpuKernel::DoComputeType(CpuKernelContext &ctx, const int64_t &offset, const int64_t &dim1, const int64_t &dim2) { // Get the inuput and output Tensor *input_x = ctx.Input(0); Tensor *y = ctx.Output(0); // Get some information of input auto x_shape = input_x->GetTensorShape(); std::vector<int64_t> x_shape_ = x_shape->GetDimSizes(); const int64_t x_dim = x_shape->GetDims(); auto dataptr = reinterpret_cast<T *>(ctx.Input(0)->GetData()); auto y_dataptr = reinterpret_cast<T *>(y->GetData()); // Compute // First, calculate the number of diagonal elements int64_t dsize = OffsetSize(offset, dim1, dim2, x_shape_); // To generate the input Tensor Step vector of x_stride std::vector<int64_t> x_stride = ConstructStride<int64_t>(x_shape_); // Discussion by situation ,2 Peacekeeping greater than 2 The d if (x_dim != N2) { //set the vx_shape and vx_stride // Generate x_shape and x_stride Remove from dim1 and dim2 Corresponding to vx_shape And vx_stride std::vector<int64_t> vx_shape, vx_stride; for (unsigned int tmp_dim = 0; tmp_dim < x_shape_.size(); tmp_dim++) { if (tmp_dim != dim1 && tmp_dim != dim2) { vx_shape.push_back(x_shape_[tmp_dim]); vx_stride.push_back(x_stride[tmp_dim]); } } // set the y_shape, y_stride, vy_stride // Generate output Tensor Shape and step vector of :y_shape and y_stride std::vector<int64_t> y_shape = vx_shape; y_shape.push_back(dsize); std::vector<int64_t> y_stride = ConstructStride<int64_t>(y_shape); // Generate output Tensor Out of the last one-dimensional step vector :vy_stride std::vector<int64_t> vy_stride = y_stride; vy_stride.pop_back(); // Read diagonal data std::vector<int64_t> v_start(vx_shape.size(), 0); for (PositionIterator<int64_t> myiter(v_start, vx_shape); !myiter.End(); ++myiter) { // Use the iterator to determine the division dim1 and dim2 Position coordinates of dimensions auto p = myiter.GetPos(); // The basic position values of input and output are calculated by step vector and position coordinates base_pos1 and outbase_pos int64_t base_pos1 = MulSum<int64_t>(p, vx_stride); int64_t outbase_pos = MulSum<int64_t>(p, vy_stride); for (int i = 0; i < dsize; i++) { // Combined with the foundation position value calculated above , Yes dim1 and dim2 The corresponding dimension determines the position of diagonal elements , And assign it to the output data address (get_data It involves taking elements from the upper diagonal or the lower diagonal , It does not affect the understanding of the function of iterators ) int64_t base_pos2 = i * (x_stride[dim1] + x_stride[dim2]); int64_t arr[N2] = {x_stride[dim1], x_stride[dim2]}; y_dataptr[outbase_pos + i] = get_data(base_pos1 + base_pos2, offset, arr, dataptr); } } } else { for (int i = 0; i < dsize; i++) { int64_t base_pos = i * (x_stride[dim1] + x_stride[dim2]); int64_t arr[N2] = {x_stride[dim1], x_stride[dim2]}; y_dataptr[i] = get_data(base_pos, offset, arr, dataptr); } } return KERNEL_STATUS_OK;}Other uses of iterators
1、 Data slicing : Such as Sort In operator , Use iterators for Tensor Data about tmp_axis Take a dimension , For subsequent sorting operations .
for (position_iterator<int64_t> mit(v_start, v_shape); !mit.end(); ++mit) { auto p = mit.get_pos(); int axis_len = input_shape_[tmp_axis]; std::vector<ValueIndex<T>> data_(axis_len); int base_pos = mul_sum<int64_t>(p, v_stride); for (int32_t i = 0; i < axis_len; i++) { data_[i].value = x_dataptr[base_pos + i * input_stride[tmp_axis]]; data_[i].index = i; }2、 Data segmentation : Chunking can be iterated by two iterators , You can also use an iterator and two coordinate positions for loop
3、 About specifying dimensions dim, Yes Tensor Dimension reduction is split into N Son Tensor: Such as UniqueConsecutive In operator , First, we need to talk about attributes axis dimension , Will be the original Tensor The data is split into input_shape[axis] Height Tensor( This is used here vector Storage Tensor Data in ).
std::vector<std::vector<T1>> data_; for (int64_t i = 0; i < dim0; i++) { std::vector<T1> tmp_v1; for (PositionIterator<int64_t> mit(v_start, v_shape); !mit.End(); ++mit) { auto pos = mit.GetPos(); tmp_v1.push_back( x_dataptr[MulSum<int64_t>(pos, v_stride) + i * input_stride[axis]]); } data_.push_back(tmp_v1); }
Click to follow , The first time to learn about Huawei's new cloud technology ~
边栏推荐
- Red envelope activity design in e-commerce system
- 5g TV cannot become a competitive advantage, and video resources become the last weapon of China's Radio and television
- Scratch Castle Adventure Electronic Society graphical programming scratch grade examination level 3 true questions and answers analysis June 2022
- UFO:微软学者提出视觉语言表征学习的统一Transformer,在多个多模态任务上达到SOTA性能!...
- Opencv3.2 and opencv2.4 installation
- 利用Shap值进行异常值检测
- Programmers exposed that they took private jobs: they took more than 30 orders in 10 months, with a net income of 400000
- 曝光一下阿里的工资待遇和职位级别
- [information retrieval] experiment of classification and clustering
- Abnormal value detection using shap value
猜你喜欢

Digi重启XBee-Pro S2C生产,有些差别需要注意
(1)性能调优的标准和做好调优的正确姿势-有性能问题,上HeapDump性能社区!
Wt588f02b-8s (c006_03) single chip voice IC scheme enables smart doorbell design to reduce cost and increase efficiency
WT588F02B-8S(C006_03)单芯片语音ic方案为智能门铃设计降本增效赋能

Xcode abnormal pictures cause IPA packet size problems
Gin integrated Alipay payment
PyTorch的自动求导机制详细解析,PyTorch的核心魔法

数据湖(十三):Spark与Iceberg整合DDL操作
ML之shap:基于boston波士顿房价回归预测数据集利用shap值对XGBoost模型实现可解释性案例
各大主流编程语言性能PK,结果出乎意料
随机推荐
《opencv学习笔记》-- 线性滤波:方框滤波、均值滤波、高斯滤波
Deep learning 7 transformer series instance segmentation mask2former
Solutions aux problèmes d'utilisation de l'au ou du povo 2 dans le riz rouge k20pro MIUI 12.5
[C language] Pointer written test questions
Digi重启XBee-Pro S2C生产,有些差别需要注意
Combined with case: the usage of the lowest API (processfunction) in Flink framework
Programmer turns direction
How to match chords
C language programming
Some problems and ideas of data embedding point
C language book rental management system
remount of the / superblock failed: Permission denied
Ranking list of databases in July: mongodb and Oracle scores fell the most
Docker compose public network deployment redis sentinel mode
阿里被裁员工,找工作第N天,猎头又传来噩耗...
AI与生命科学
One architecture to complete all tasks - transformer architecture is unifying the AI Jianghu on its own
【算法leetcode】面试题 04.03. 特定深度节点链表(多语言实现)
曝光一下阿里的工资待遇和职位级别
Kubernets Pod 存在 Finalizers 一直处于 Terminating 状态