当前位置:网站首页>UFO:微软学者提出视觉语言表征学习的统一Transformer,在多个多模态任务上达到SOTA性能!...
UFO:微软学者提出视觉语言表征学习的统一Transformer,在多个多模态任务上达到SOTA性能!...
2022-07-04 13:19:00 【我爱计算机视觉】
关注公众号,发现CV技术之美
本篇文章分享论文『UFO: A UniFied TransfOrmer for Vision-Language Representation Learning』,微软学者提出视觉语言表征学习的统一Transformer,《UFO》,在多个多模态任务上达到SOTA性能!
详细信息如下:

论文链接:https://arxiv.org/abs/2004.12832
01
摘要
在本文中,作者提出了一种统一Transformer(UFO),它能够处理单模态输入(例如图像或语言)或多模态输入(例如图像和问题的concatenation),用于视觉语言(VL)表示学习。现有方法通常为每个模态设计一个单独的网络和或为多模态任务设计一个特定的融合网络。
为了简化网络结构,作者使用单个Transformer网络,在VL预训练期间实施多任务学习,包括图像文本对比损失、图像文本匹配损失和基于双向和seq2seq注意力掩码的mask语言建模损失。在不同的预训练任务中,相同的Transformer网络用作图像编码器、文本编码器或融合网络。根据实验,作者观察到不同任务之间的冲突较少,在视觉问答、COCO图像字幕(交叉熵优化)和nocaps(SPICE)方面达到了新的水平。在其他下游任务上,例如图像文本检索,UFO也取得了有竞争力的性能。
02
Motivation
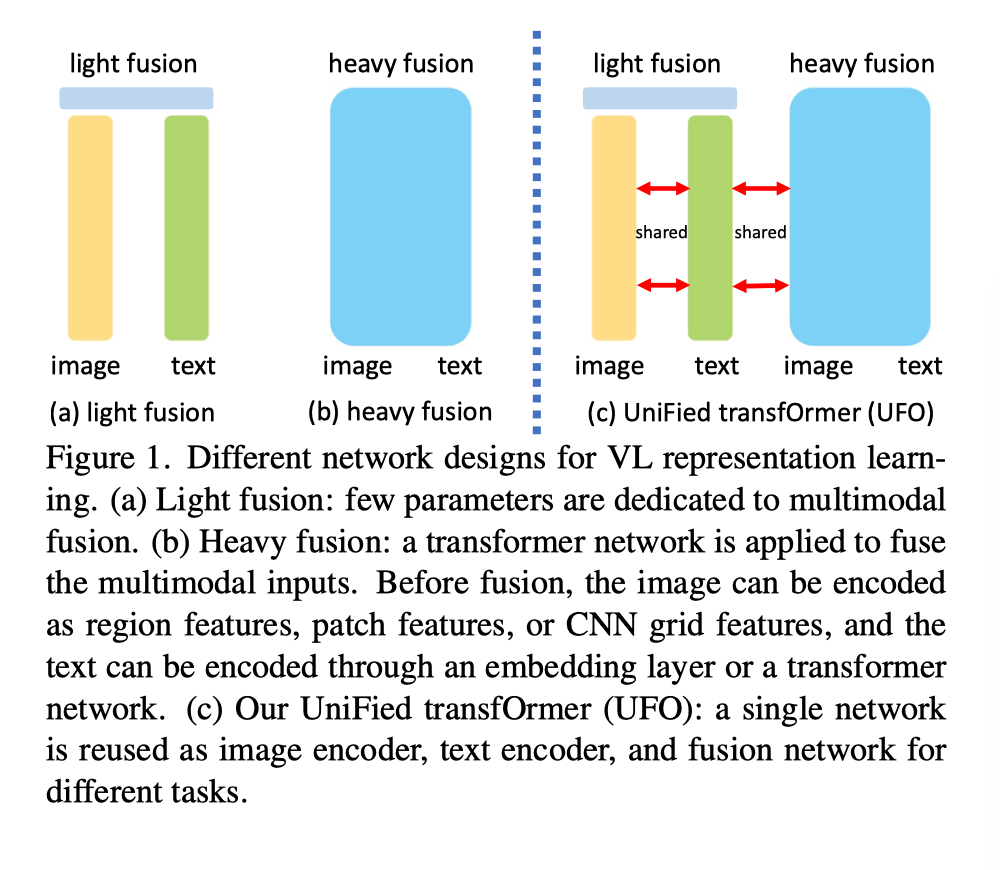
近年来,视觉语言(VL)表征学习取得了巨大进展,其中模型旨在理解视觉/语言信号以及模态之间的关系。应用包括图像字幕、视觉问答(VQA)、图像文本检索等。典型的方法首先从每个模态中提取特征,然后将它们反馈到融合网络,共同学习表示。关于融合网络的设计,可以将现有方法大致分为两类:轻融合和重融合,如上图(a)和(b)所示。
轻融合(图(a))对图像和文本采用单独的编码器,例如在CLIP和ALIGN中。图像编码器可以是ResNet或vision transformer,而文本编码器通常是transformer。融合是基于余弦相似性的对比损失,使得两种模态的表示可以对齐到相同的语义空间。一个很好的应用是图像文本检索,其中每个图像或文本描述都表示为一个固定向量,用于快速的相似性搜索。
在轻融合中分配的参数很少,上图(b)所示的重融合方法在单模态特征之上应用transformer网络来共同学习表示。图像可以通过Faster RCNN编码为对象特征,通过卷积神经网络编码为网格特征,或者通过原始像素上的线性投影编码为patch特征。文本可以通过transformer网络或简单嵌入层编码为token表示。通过较重的融合网络,最终表示可以更好地捕捉模态之间的上下文联系。一个典型的应用是VQA,网络根据图像和问题预测答案。
现有的方法针对不同的任务设计不同的网络架构。由于transformer网络可用于所有这些组件,因此在本文中,作者尝试为轻融合和重融合场景设计一个单一的统一transformer(UFO),如上图(c)所示。对于轻融合任务,transformer同时用作图像编码器和文本编码器。对于重融合任务,相同的transformer被重新用作融合模块,以将两个信号一起处理。
在输入transformer之前,原始图像像素被分组为patch,并通过线性映射进行投影。文本描述通过嵌入层投影到同一维度。这样,在模态特定处理中分配尽可能少的可学习参数,并将大部分用于共享transformer网络。根据每个单独模态应分配多少表示能力以及联合表示应分配多少,自动调整网络。
为了使网络具有单模态输入的能力,作者在VL预训练(VLP)期间对输出应用图像-文本对比(ITC)损失。对于多模态融合能力,作者采用了基于双向和seq2seq注意力的图像文本匹配(ITM)损失和屏蔽语言建模(MLM)损失。为了优化包含多个任务的网络,作者在每个迭代中随机选择一个任务以提高效率,并利用momentum teacher来指导学习。通过广泛的消融研究,作者观察到这些任务之间的冲突较少。在某些情况下,不同的任务甚至可以互相帮助。
03
方法
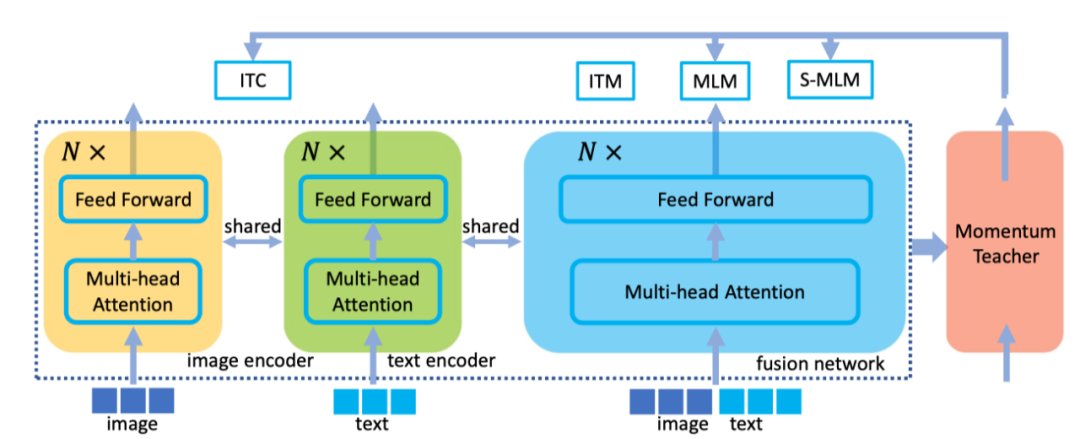
UFO关键的想法是只利用一个transformer网络,它被重用为图像编码器、文本编码器或融合编码器。作者遵循广泛使用的预训练-微调方案来训练网络。在预训练期间,作者获得了大量的图像-文本对语料库,并强制执行多次损失以增强网络能力。对于单模态信号,作者采用图像-文本对比损失。对于多模态融合任务,作者采用了基于双向(MLM)和单向(S-MLM)注意力的图像-文本匹配损失(ITM)和掩蔽语言建模损失。上图示出了预训练框架。
3.1. Network Structure
作者采用transformer网络作为backbone。主要原因是transformer网络在图像任务、语言任务和VL任务上表现良好。其他选择是卷积神经网络(CNN)或所有MLP结构,但尚不清楚如何有效地将此类网络应用于所有这三种作用。
transformer网络的输入是一系列token,每个token都表示为d维向量。为了tokenize图像,作者将原始图像分割为不相交的patch,每个patch通过可学习的线性层线性投影到d维空间中。将可学习的二维位置嵌入添加到每个patch表示中,并附加图像[CLS] token。文本描述首先被tokenized,然后通过嵌入矩阵嵌入到d维空间。然后添加[CLS]的起始token和EOS的结束token来包装文本序列。向每个文本token添加可学习的一维位置嵌入。
这里,图像[CLS]和文本[CLS]是两个不同的token。在将输入送到transformer网络之前,将特定于模态的嵌入添加到相应的输入中。对于VL任务,两种模态输入在发送到transformer之前进行concatenated。虽然输入可能具有不同的token长度,但transformer网络自然能够处理不同的输入长度。
3.2. Pre-training Tasks
Image-Text Contrastive Loss
图像-文本对比(ITC)损失是训练网络处理图像或文本,并将匹配对对齐为相似的表示。对于图像,网络用作图像编码器,并且选择与[CLS] token相对应的输出作为表示。对于文本,网络被重用为文本编码器,与[EOS] token相对应的网络作为表示。文本[CLS] token用于图像文本匹配损失。设和分别为第I个图像和文本的表示。给定一个训练batch中的N对,损失为:
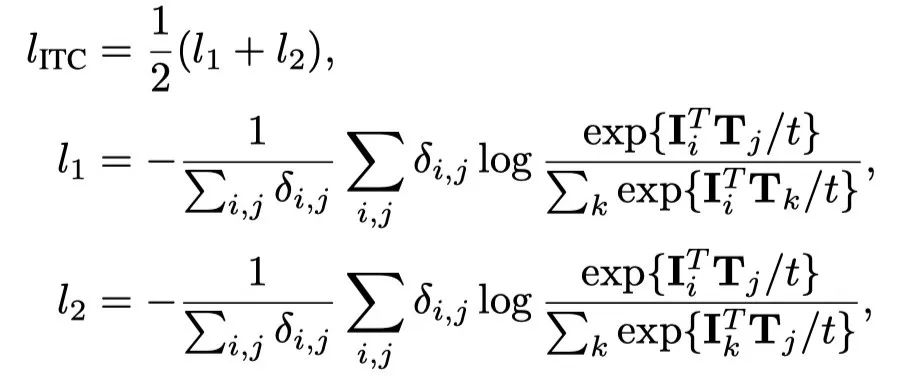
其中,t是可学习的,初始化为1。如果第i个图像与第j个文本配对,则的指示符为1,否则为0。这是为了处理图像(或文本)与多个文本(或图像)关联的数据。
Image-Text Matching Loss
网络输入是匹配或不匹配图像文本对的concatenation。通过在数据集中为给定图像随机选择文本描述来构造不匹配对。网络需要预测是否匹配,这是一项二分类任务。这里,作者使用文本的表示[CLS]作为联合表示,然后使用MLP层进行预测。交叉熵损失用于惩罚错误预测。
Masked Language Modeling Loss
网络输入是图像token和部分mask文本token的串联,而transformer网络经过训练以预测masked token。作者选择15%的文本token进行预测。每个选定的token都其他token替换,[MASK] token占80%;随机token占10%,未更改token占10%。MLM头应用于mask token的输出,用于预测交叉熵损失,表示为。
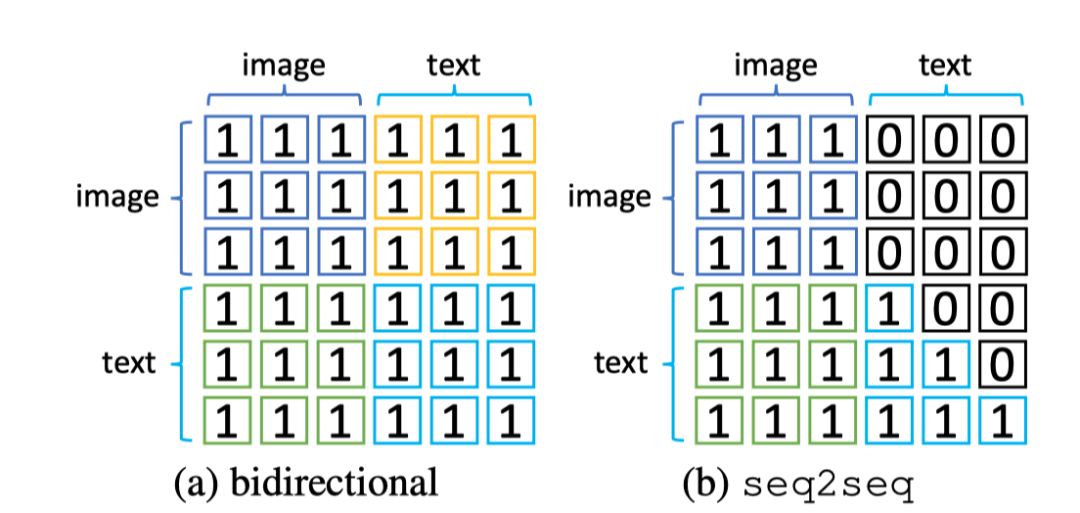
在将预训练好的模型应用于图像字幕任务时,作者更改了注意力掩码,使得当前文本token只能依赖于前面的token。因此,作者还结合了另一种基于seq2seq注意的mask语言建模损失,并将其表示为。上图显示了MLM和S-MLM的注意力掩码。
3.3. Pre-training Strategies
One Loss per Iteration

上表总结了每次预训练损失的特征。在不同的损失中,输入格式不同,transformer被用作不同的角色,注意力掩码也可能不同。为了简单起见,在每次迭代中,作者随机抽取一个预训练损失,并计算参数更新的梯度。根据实验,作者发现,当损失计算的总数相同时,这种策略比计算每次迭代中的所有损失更有效。
Momentum Teacher
作者增加了一个Momentum Teacher来指导预训练。具体而言,Momentum Teacher是transformer网络的克隆,参数更新为目标网络参数的指数移动平均值。设为目标网络的参数,为教师的参数。在每个迭代中:
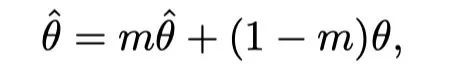
其中m在实验中设置为0.999。对于ITC/MLM/S-MLM的预训练损失,同样的输入和注意掩码也被馈送给Momentum Teacher,输出被用作目标网络输出的软目标。在ITC中,设是第i个图像和第j个文本之间的相似度,是Momentum Teacher网络中的相似度。然后,在ITC顶部添加蒸馏损失,如下所示:
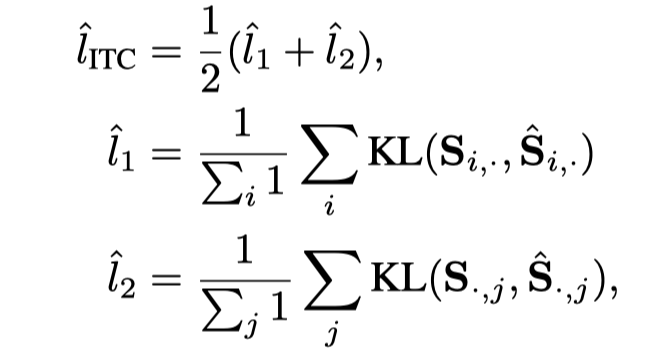
其中,表示输入softmax上的Kullback–Leibler散度损失。对于MLM损失,假设g是对应于masked token的预测logits,g是来自Momentum Teacher的logits,则蒸馏损失为。同样,也有S-MLM的蒸馏损失。
04
实验
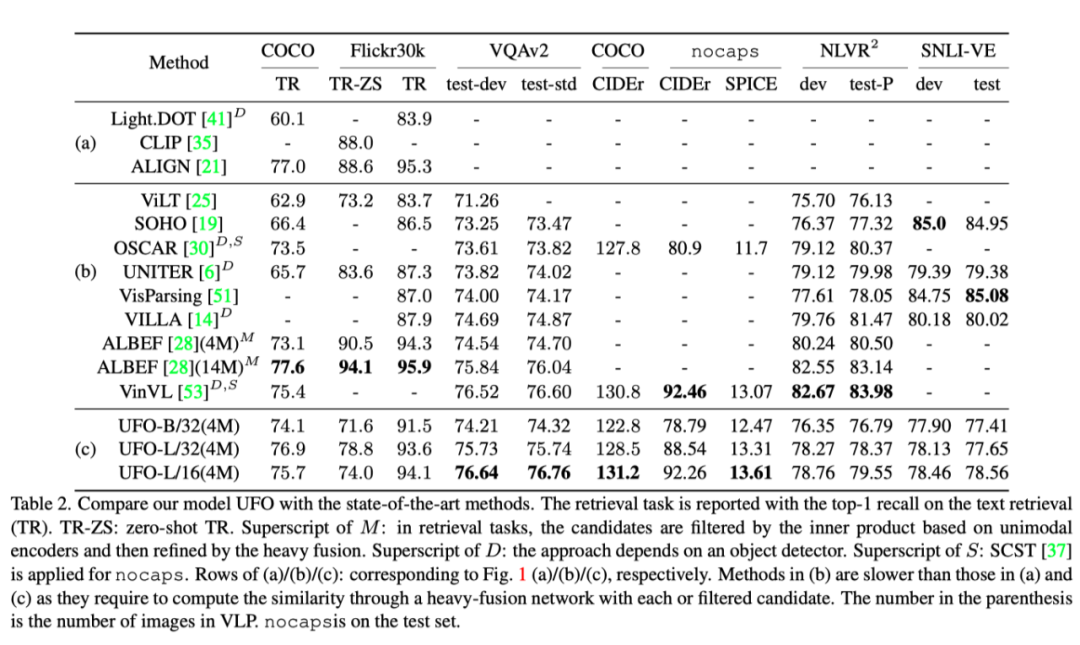
上表展示了各个数据集和任务上,本文提出的UFO和其他SOTA方法的结果对比。
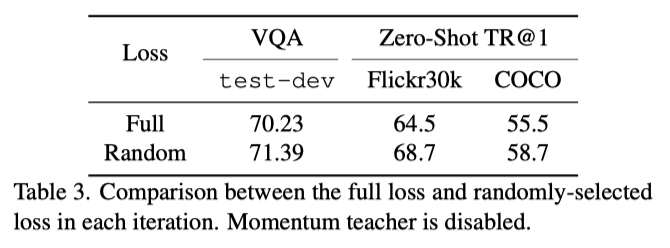
上表展示了在训练中每次随机选择损失函数和使用全部损失函数的消融结果对比,可以看出使用随机损失函数的效果更好一些。
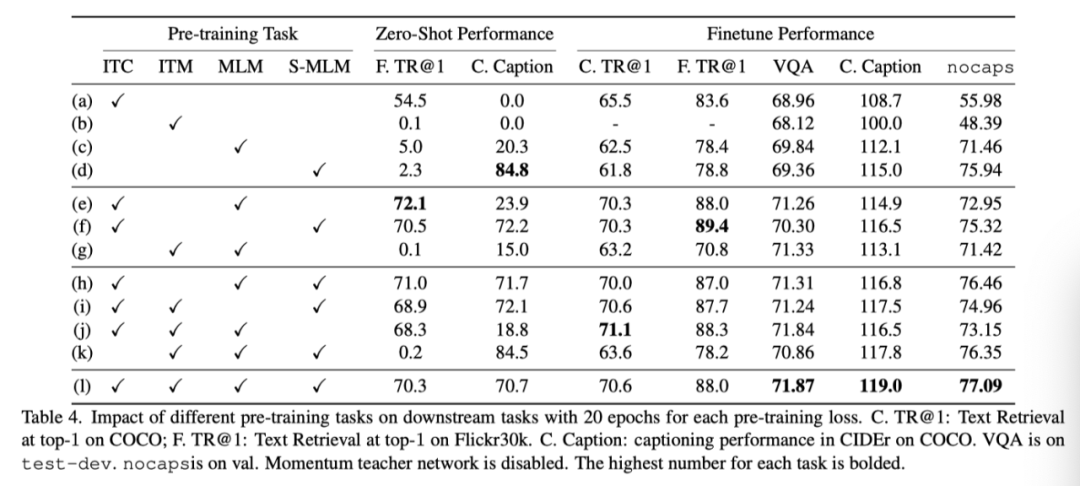
上表展示了不同预训练方法的消融结果对比。
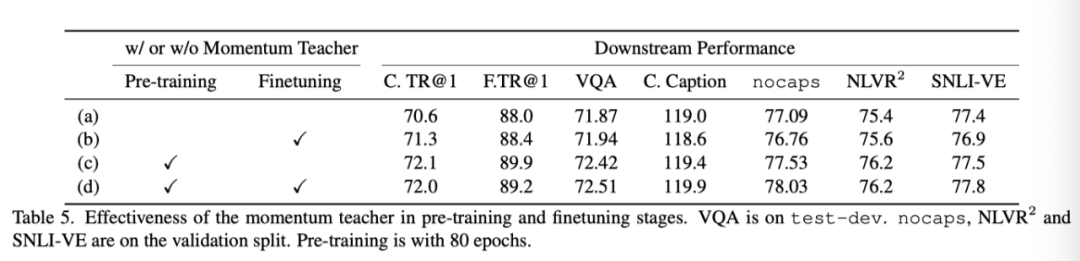
上表展示了在预训练和微调过程中是否使用momentum teacher的实验结果。
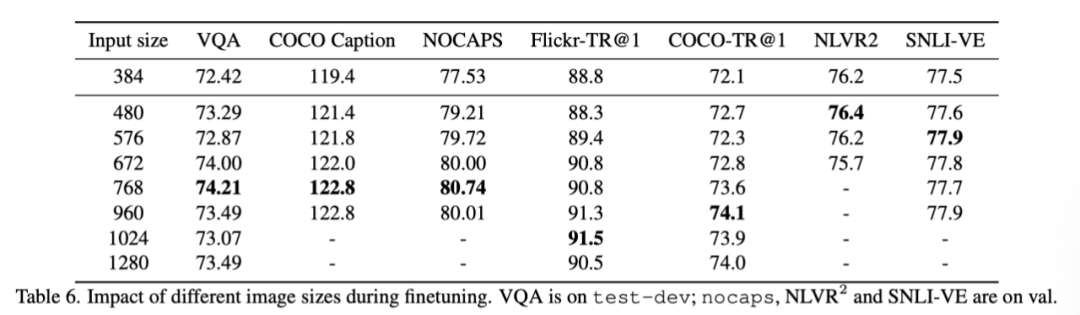
上表显示了针对每个下游任务的不同输入图像大小的研究。在VQA、图像字幕和检索任务中,输入量越大,准确率就越高。同时,不同任务的最佳输入大小也不同,这表明不同的任务可能期望不同的图像理解粒度级别。
05
总结
作者提出了一种统一Transformer(UFO),它能够处理图像或文本的单模态输入和多模态输入。在视觉语言预训练过程中,学习网络通过多种损失来理解不同的信号,包括图像文本对比损失、图像文本匹配损失和基于双向和seq2seq掩码的mask语言建模损失。
大量实验表明,与现有方法相比,本文的单一模型可以获得具有竞争力的结果,现有方法通常为每个模态和模态融合设计特定的网络。由于本文的模型在VLP中只有400万张图像上达到了大尺寸(24层),因此作者希望将来能够同时放大模型尺寸和预训练数据。
参考资料
[1]https://arxiv.org/abs/2004.12832

END
欢迎加入「视觉语言」交流群备注:VL

边栏推荐
- Digi重启XBee-Pro S2C生产,有些差别需要注意
- Scratch Castle Adventure Electronic Society graphical programming scratch grade examination level 3 true questions and answers analysis June 2022
- opencv3.2 和opencv2.4安装
- The failure rate is as high as 80%. What are the challenges on the way of enterprise digital transformation?
- Solutions aux problèmes d'utilisation de l'au ou du povo 2 dans le riz rouge k20pro MIUI 12.5
- Data Lake (13): spark and iceberg integrate DDL operations
- A collection of classic papers on convolutional neural networks (deep learning classification)
- Ml: introduction, principle, use method and detailed introduction of classic cases of snap value
- Practical puzzle solving | how to extract irregular ROI regions in opencv
- flink sql-client. SH tutorial
猜你喜欢
数据中台概念
![[MySQL from introduction to proficiency] [advanced chapter] (IV) MySQL permission management and control](/img/cc/70007321395afe3a9fc6b6032d30aa.png)
[MySQL from introduction to proficiency] [advanced chapter] (IV) MySQL permission management and control

软件测试之测试评估
Docker compose public network deployment redis sentinel mode
![[information retrieval] experiment of classification and clustering](/img/05/ee3b3bc4ab79d52b63cdc34305aa57.png)
[information retrieval] experiment of classification and clustering
Gin integrated Alipay payment
![[MySQL from introduction to proficiency] [advanced chapter] (V) SQL statement execution process of MySQL](/img/58/a8dbed993921f372d04f7a1ee19679.png)
[MySQL from introduction to proficiency] [advanced chapter] (V) SQL statement execution process of MySQL
Leetcode T48:旋转图像
LVGL 8.2 text shadow
LVGL 8.2 text shadow
随机推荐
LVGL 8.2 Line wrap, recoloring and scrolling
Progress in architecture
Digi XBee 3 rf: 4 protocols, 3 packages, 10 major functions
Abnormal value detection using shap value
C language achievement management system for middle school students
STM32F1与STM32CubeIDE编程实例-MAX7219驱动8位7段数码管(基于GPIO)
各大主流编程语言性能PK,结果出乎意料
Ultrasonic distance meter based on 51 single chip microcomputer
Ml: introduction, principle, use method and detailed introduction of classic cases of snap value
LVGL 8.2 Line wrap, recoloring and scrolling
A collection of classic papers on convolutional neural networks (deep learning classification)
flink sql-client.sh 使用教程
【算法leetcode】面试题 04.03. 特定深度节点链表(多语言实现)
WT588F02B-8S(C006_03)单芯片语音ic方案为智能门铃设计降本增效赋能
Real time data warehouse
leetcode:6110. The number of incremental paths in the grid graph [DFS + cache]
软件测试之测试评估
Practical puzzle solving | how to extract irregular ROI regions in opencv
LVGL 8.2 Line
5G电视难成竞争优势,视频资源成中国广电最后武器