当前位置:网站首页>Transfer learning and domain adaptation
Transfer learning and domain adaptation
2022-07-05 08:59:00 【Wanderer001】
Transfer learning and domain adaptation refer to the use of a scenario ( for example , Distribution P1) To improve another situation ( Like distribution P2) Generalization in , Escape between unsupervised learning tasks and supervised learning tasks .
In transfer learning , The learner must perform two or more different tasks , But we assume that it can explain P1 Many factors of change and learning P2 Relevant changes that need to be grasped . This can usually be explained in supervised learning , The input is the same , But the output has different properties . for example , We may have learned a group of visual categories in the first scenario , Like cats and dogs , Then learn a group of different visual categories in the second scenario , Like ants and wasps . If the first scenario ( from P1 sampling ) There is a lot of data in , Then it helps to learn to make from P2 Fast generalization representation in very few samples . Many visual categories share some low-level concepts , Like the edge 、 Visual shape 、 Set change 、 The influence of light changes . generally speaking , When there are useful characteristics of different situations or tasks , And these characteristics correspond to the potential factors of a situation , The migration study 、 Multi task learning and domain adaptation can be achieved by using representation learning .
Sometimes different tasks share semantics other than input , It's the semantics of the output . for example , Speech recognition system needs to produce effective sentences at the output layer , But the lower level near the input may need to recognize very different versions of the same phoneme or sub phoneme pronunciation ( It depends on who speaks ). In this case , Share the upper layer of neural network ( Near output ) And task specific preprocessing is meaningful .
In the field of domain adaptation (domain adaption) In the relevant circumstances , Tasks between each scenario ( And optimal input-output mapping ) It's all the same , But the input distribution is slightly different . for example , Consider the task of emotional analysis , For example, judge whether a comment expresses positive or negative emotions . There are many categories of online comments . In the book 、 Emotional predictor of customer comments trained on media content such as video and music , It is used to analyze the comments of consumer electronic products such as televisions or smart phones , Domain adaptive scenarios may appear . As you can imagine , There is a potential function that can determine whether any statement is positive 、 Neutral or negative , But vocabulary and style may vary from field to field , It makes cross domain generalization training more difficult . Simple unsupervised training ( De noise self encoder ) It has been successfully used in domain adaptive emotion analysis .
A related problem is concept drift (concept drift), We can regard it as a kind of transfer learning , Because the data distribution changes gradually over time . Concept drift transfer learning can be regarded as a specific form of multi task learning .“ Multi task learning ” This term usually refers to supervised learning tasks , The broader concept of transfer learning is also applicable to unsupervised learning and reinforcement learning .
In all these cases , Our goal is to use the data in the first scenario , Extract information that may be useful when learning in the second scenario or making predictions directly . The core idea of representation learning is that the same representation may be useful in both situations . The two scenarios use the same representation , So that the representation can benefit from the training data of two tasks .
As mentioned earlier , Unsupervised deep learning in transfer learning has been successful in some machine learning competitions . Under an experimental configuration in these competitions . First, each participant gets a first scenario ( From the distribution P1) Data set of , There are samples of some categories . Participants must use this to learn a good feature space to learn a good feature space ( Map raw input to a representation ), So when we apply this learning transformation to the migration scenario ( Distribution P2) When inputting , Linear classifiers can be trained on rarely labeled samples , And generalize well . The most striking result of this competition is , The deeper the network architecture of learning representation ( In the first scenario P1 The data in is learned in a purely unsupervised way ), In the second scenario ( transfer )P2 The better the curve learned in the new category . For depth representation , Migration learning can significantly improve generalization performance with only a small number of labeled samples . The two extreme forms of transfer learning are one-time learning (one-shot learning) And zero learning (zero-shot learning) , Sometimes called zero data learning (zero-data learning). The migration task with only one labeled sample is called one-time learning ; The migration task without labeled samples is called zero learning .
Because the representation learned in the first stage can clearly separate the potential categories , So a study is possible . In the transfer learning stage , Only one annotation sample is needed to infer the labels representing many possible test samples gathered around the same point in the space . This makes in the learned representation space , The change factor corresponding to invariance has been completely separated from other factors , When distinguishing certain categories of objects , We can learn which factors are decisive .
Consider an example of a zero time learning scenario , The learner has read a lot of text , Then we need to solve the problem of object recognition . If the text describes the object well enough , So even if you don't see the image of an object , It can also identify the category of the object . for example , Known cats have 4 Sharp ears of legs , Then the learner can guess the cat in the image without seeing the cat .
Only when using additional information during training , Zero data learning and zero learning are possible . We can think that the zero data learning scenario includes 3 Random variables : Traditional input x, Traditional output y, And additional random variables that describe the task T. The model is trained to estimate the conditional distribution p(x|y,T), among T Is a description of the task we want to perform . In our case , Read the text information of the cat and recognize the cat , for example “ Is there a cat in this image ?” If the training set contains and T Unsupervised object samples in the same space , We may be able to infer the unknown T The meaning of the example . In our case , I didn't see the image of the cat in advance to recognize the cat , So there are some unlabeled text data containing sentences such as “ The cat has 4 Legs ” or “ Cats have sharp ears ”, It is very helpful for learning .
Only when using additional information during training , Zero data learning and zero learning are possible . We can think that the zero data learning scenario includes 3 Random variables : Traditional input or target y, And additional random variables that describe the task T. The model is trained to estimate the conditional distribution p(y|x,T), among T Is a description of the task we want to perform . In our case , Read the text information of the cat and recognize the cat , The output is a binary variable y,y=1 Express “ yes ”,y=0 Express “ No ”. Task variables T Indicates the question to be answered , for example “ Is there a cat in this image ?” If the training set contains and T A sample of unsupervised objects in the same space , We may be able to infer the unknown T The meaning of the example . In our case , I didn't see the image of the cat in advance to recognize the cat , So there are some annotated text data containing sentences such as “ The cat has 4 Legs ” or “ Cats have sharp ears ”, It is very helpful for learning .
Zero learning requirements T Expressed as some form of generalization . for example ,T It cannot only indicate the object category one-hot code . By using the embedded representation of each category word , A distributed representation of object classes is proposed . We can also find a similar phenomenon in machine translation : We already know words in a language , You can also learn the relationship between words in a monolingual corpus , On the other hand , We have translated sentences related to words in one language and words in another language . Even though we may not have language X The words in A Translate into language Y The words in B Label Sample , We can also generalize and guess words A Translation , This is because we have learned the language X and Y Distributed representation of words , And the training samples are composed of matching pairs of sentences in two languages , The link between the two spaces is generated ( It may be two-way ). If joint learning 3 Species composition ( Two representations and the relationship between them ), Then this migration will be very successful .
Zero learning is a special form of transfer learning . The same principle can explain how to perform multimodal learning (multimodel learning), Learn the representation of two modes , And observations in a mode x And the observation in another mode y Composed pair (x,y) The relationship between ( It is usually a joint distribution ). By learning all three sets of parameters ( from x To its expression , from y To its expression , And the relationship between the two representations ), Concepts in one representation are anchored in another , vice versa , Thus, it can be effectively extended to new pairs .
边栏推荐
- Numpy pit: after the addition of dimension (n, 1) and dimension (n,) array, the dimension becomes (n, n)
- kubeadm系列-00-overview
- [daily training -- Tencent selected 50] 557 Reverse word III in string
- Halcon snap, get the area and position of coins
- Halcon color recognition_ fuses. hdev:classify fuses by color
- . Net service governance flow limiting middleware -fireflysoft RateLimit
- [牛客网刷题 Day4] JZ55 二叉树的深度
- Adaboost使用
- Latex improve
- 12. Dynamic link library, DLL
猜你喜欢

Programming implementation of subscriber node of ROS learning 3 subscriber
![Introduction Guide to stereo vision (4): DLT direct linear transformation of camera calibration [recommended collection]](/img/ed/0483c529db2af5b16b18e43713d1d8.jpg)
Introduction Guide to stereo vision (4): DLT direct linear transformation of camera calibration [recommended collection]
Ros-10 roslaunch summary
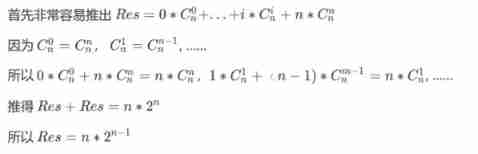
Solution to the problems of the 17th Zhejiang University City College Program Design Competition (synchronized competition)

Halcon shape_ trans
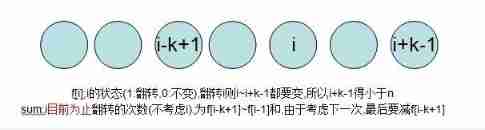
Summary of "reversal" problem in challenge Programming Competition
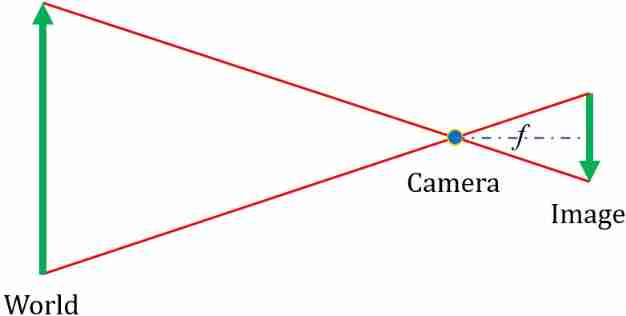
Introduction Guide to stereo vision (1): coordinate system and camera parameters
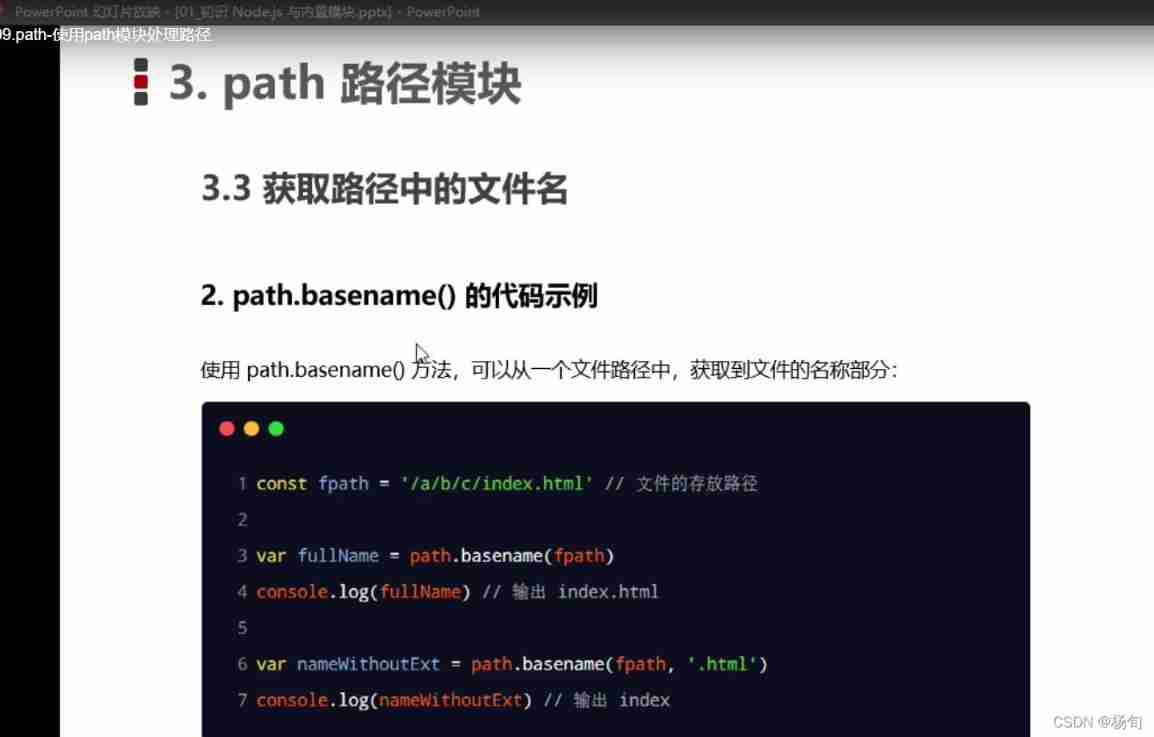
fs. Path module
![C [essential skills] use of configurationmanager class (use of file app.config)](/img/8b/e56f87c2d0fbbb1251ec01b99204a1.png)
C [essential skills] use of configurationmanager class (use of file app.config)
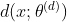
生成对抗网络
随机推荐
Codeforces Round #648 (Div. 2) D. Solve The Maze
Array, date, string object method
Ros-10 roslaunch summary
Codeworks round 639 (Div. 2) cute new problem solution
Rebuild my 3D world [open source] [serialization-1]
图解网络:什么是网关负载均衡协议GLBP?
C# LINQ源码分析之Count
[code practice] [stereo matching series] Classic ad census: (4) cross domain cost aggregation
. Net service governance flow limiting middleware -fireflysoft RateLimit
The location search property gets the login user name
[牛客网刷题 Day4] JZ55 二叉树的深度
2309. 兼具大小写的最好英文字母
Illustrated network: what is gateway load balancing protocol GLBP?
Hello everyone, welcome to my CSDN blog!
Understanding rotation matrix R from the perspective of base transformation
uni-app 实现全局变量
nodejs_ fs. writeFile
12、动态链接库,dll
ECMAScript6介绍及环境搭建
AUTOSAR从入门到精通100讲(103)-dbc文件的格式以及创建详解