当前位置:网站首页>Mobilenet series (4): mobilenetv3 network details
Mobilenet series (4): mobilenetv3 network details
2022-06-27 03:46:00 【@BangBang】
introduction
Nowadays, many lightweight networks often use MobileNetv3, This article will explain google Following MobileNetv2 Later proposed v3 edition .MobileNetv3 The paper :Searching for MobileNetV3
according to MobileNetV3 The paper summary , The network has the following 3 Points that need your attention :
Updated Block(bneck), stay v3 This version of the original paper is calledbneck, stay v2 editionInverse residual structureA simple change has been made on the .- Used NAS(
Neural Architecture Search) Search parameters Redesigned the time-consuming structure: Author useNASThe network after searching , Next, the reasoning time of each layer of the network is analyzed , Some time-consuming layer structures are further optimized
MobileNetV3 Performance improvement
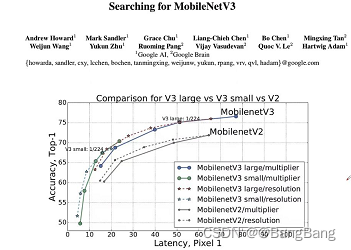
MobileNetV3-Largeis3.2%moreaccurateon ImageNet classification while reducinglatency by 20%compared toMobileNetV2.MobileNetV3-Smallis6.6%more accuratecompared to a MobileNetV2model with comparable latency. MobileNetV3-Large detection is over 25% faster at roughly the same accuracy as MobileNetV2 on COCO detection. MobileNetV3-Large LRASPP is 34% faster than MobileNetV2 R-ASPP at similar accuracy for Cityscapes segmentation

- It can be seen that V3 Version of Large 1.0
(V3-Large 1.0)OfTop-1yes75.2, aboutV2 1.0itsTop-1yes72, It's equivalent to a promotion3.2% - There is also a certain improvement in reasoning speed ,
(V3-Large 1.0)stayP-1The reasoning time on the mobile phone is51ms, andV2yes64ms, ObviouslyV3ThanV2, Not only is it more accurate , And faster V3-SmallVersion ofTop-1yes67.4, andV2 0.35(0.35 Represents the magnification factor of the convolution kernel ) OfTop-1Only60.8, Improved accuracy6.6%
Obviously V3 Version than V2 The version should be better
Network improvements
Updated Block
- Joined the SE modular ( Attention mechanism )
- Updated activation function
MobieNetV2 Block

- First of all, it will pass a
1x1Convolution layer to carry out dimension raising processing , After convolution, there will beBNandReLU6Activation function - And then there was a
3x3sizeDWConvolution , Convolution will still be followed byBNandReLU6Activation function - The last accretion layer is
1x1Convolution , Play the role of dimensionality reduction , Note that after convolution, onlyBNstructure , Not usedReLU6Activation function .
In addition, there is a shortcut branch in the network shotcut, Add our input characteristic matrix and output characteristic matrix on the same dimension . And only DW The convolution steps are 1, And input_channel==output_channel, Only then shotcut Connect
MobieNetV3 Block

What do you think , And MobieNetV2 Block It doesn't make any difference , The most obvious difference is that MobieNetV3 Block in SE modular ( Attention mechanism )
SE modular
For the obtained characteristic matrix , For each channel Pool treatment , Next, through two Fully connected layer Get the output vector , The first fully connected layer , its Number of nodes in the full connection layer Is equal to the input characteristic matrix channel Of 1/4, The second fully connected layer channel Is related to our characteristic matrix channel Be consistent . After average pooling + Two fully connected layers , The output eigenvector can be understood as a pair of SE Each of the previous characteristic matrices channel A weight relation is analyzed , It thinks that the more important channel Will give a greater weight , For less important channel The dimension corresponds to a relatively small weight

As shown in the figure above : Let's assume that the of our characteristic matrix channel by 2, Use Avg pooling For each channel To find an average , Because there are two channel, So get 2 Vectors of elements , Then it passes through two full connection layers in turn , first channel For the original channel Of 1/4, And it corresponds to relu Activation function . For the second fully connected layer, its channel And our characteristic matrix channel The dimensions are consistent , Note that the activation function used here makes h-sigmod, Then we get the sum characteristic matrix channel A vector of the same size , Each element corresponds to each channel Of The weight . For example, the first element is 0.5, take 0.5 And the first of the characteristic matrix channel Multiply the elements of , Get a new one channel data .
In addition, the network has updated the activation function 
Corresponds to NL It is a nonlinear activation function , The activation functions used in different layers are different , There is no explicit activation function here , It is marked with a NL, Pay attention to the last layer 1x1 There is no nonlinear activation function used in the convolution of , Using a linear activation function .
MobieNetV3 Block and MobieNetV2 Block The structure is basically the same , Mainly increased SE structure , The activation function is updated
Redesign the time-consuming layer structure
stay Original thesis It mainly talks about two parts :
Reduce the number of convolutions of the first convolution layer (32 -> 16)
stay v1,v2 The number of convolution kernels in the first layer of the version is 32 Of , stay v3 In this version, we only use 16 individual
In the original paper , The author said that the convolution kernel Filter Number from 32 Turn into 16 after , Its accuracy is the same as 32 It's the same , Since the accuracy has no effect , With less convolution kernel, the amount of computation becomes smaller . I'm saving roughly2msOperation time ofStreamlining Last Stage
In the use ofNASThe last part of the searched network structure , be calledOriginal last Stage, Its network structure is as follows :
The network is mainly generated by stacking convolution , The author found this in the course of useOriginal Last StageIt is a time-consuming part , The author has simplified the structure , Came up with aEfficient Last Stage

Efficient Last Stage Compared with the previous Original Last Stage, A lot less convolution , The author found that the accuracy of the updated network is almost unchanged , But it saves 7ms Execution time of . this 7ms Occupy the reasoning 11% Time for , Therefore use Efficient Last Stage after , It is quite obvious for us to improve our speed .
Redesign the activation function
Before that v2 We basically use ReLU6 Activation function , Now the commonly used activation function is swish Activation function .
s w i t h x = x . σ ( x ) swith x=x.\sigma(x) swithx=x.σ(x)
among σ \sigma σ The calculation formula of is as follows :
σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1
Use switch After activating the function , It can really improve the accuracy of the network , But there are 2 A question :
- Calculation 、 Derivation is complicated
- Unfriendly to the quantification process ( For mobile devices , Basically, it will be quantified for acceleration )
Because of the problem , The author put forward that h-switch Activation function , Talking about h-switch Before activating the function, let's talk about h-sigmoid Activation function
h-sigmoid The activation function is in relu6 Activate the function to modify :
R E L U 6 ( x ) = m i n ( m a x ( x , 0 ) , 6 ) RELU6(x)=min(max(x,0),6) RELU6(x)=min(max(x,0),6)
h − s i g m o i d = R e L U 6 ( x + 3 ) 6 h-sigmoid=\frac{ReLU6(x+3)}{6} h−sigmoid=6ReLU6(x+3)

As you can see from the diagram h-sigmoid And sigmoid The activation function is close to , So in many scenarios h-sigmoid Activate the function to replace our sigmoid Activation function . therefore h-switch in σ \sigma σ Replace with h-sigmoid after , The form of the function is as follows :
h − s w i t c h [ x ] = x R e L U 6 ( x + 3 ) 6 h-switch[x]=x\frac{ReLU6(x+3)}{6} h−switch[x]=x6ReLU6(x+3)
As shown in the right part of the above figure , yes switch and h-switch Comparison of activation functions , Obviously the two curves are very similar , So using h-switch To replace switch The activation function is great .
In the original paper , The author said that h-switch Replace switch, take h-sigmoid Replace sigmoid, For the reasoning process of the network , It is helpful in reasoning speed , It is also very friendly to the quantification process .
MobieNetV3-Large Version of the network structure

Simply look at the meanings of the parameters in the following table :
inputInput layer characteristic matrix shapeoperatorIt means operation , For the first convolution layer conv2d; there#outOf the output characteristic matrix channel, We said it was v3 The first convolution kernel in this version uses16Convolution kernels- there
NLRepresents the activation function , amongHSIt stands forhard switchActivation function ,REIt stands for ReLU Activation function ; - there
sRepresentativeDWConvolution step ; - there beneck Corresponding to the structure in the figure below ;
exp sizeRepresents the first convolution of ascending dimensions , How many dimensions are we going to raise ,exp sizeHow many? , We'll use the first floor1x1How many dimensions does convolution rise to .SE: Indicates whether the attention mechanism is used , As long as the form is awarded√The correspondingbneckStructure uses our attention mechanism , Yes, No√You won't use the attention mechanismNBNThe last two convolutions operator TipsNBN, Indicates that these two convolutions do not useBNstructure , The last two convolutions are equivalent to the function of full connectionBe careful: firstbneckstructure , There is something special here , itsexp sizeAnd the input characteristic matrix channel It's the same , OriginallybneckThe first convolution in plays the role ofL dThe role of , But there is no upgrade here . So in the process of implementation , firstbneckThere is no structure1x1Convolutional , It is a direct analysis of our characteristic matrixDWConvolution processing

- First, through
1x1Convolution is carried out to increase the dimension toexp size, adoptDWThe dimension of convolution will not change , Similarly passed SE after channel Will it change . Finally through1x1Convolution for dimensionality reduction . After the dimension reductionchannelCorresponding to#outThe value given . - about
shortcutShortcut Branch , Must beDWThe convolution steps are 1, AndbneckOfinput_channel=output_channelOnly thenshortcutConnect
Through this table, we can build MobilenetV3 Network structure
about MobileNetV3-Small Network structure , as follows , I won't talk about it here , It is basically consistent with what I said .

边栏推荐
- List of best reading materials for machine learning in communication
- ERP需求和销售管理 金蝶
- 流沙画模拟器源码
- Network structure and model principle of convolutional neural network (CNN)
- Quicksand painting simulator source code
- fplan-电源规划
- Stack overflow vulnerability
- Games101 job 7 improvement - implementation process of micro surface material
- Agile development - self use
- PAT甲级 1021 Deepest Root
猜你喜欢
![[数组]BM94 接雨水问题-较难](/img/2b/1934803060d65ea9139ec489a2c5f5.png)
[数组]BM94 接雨水问题-较难

Super detailed, 20000 word detailed explanation, thoroughly understand es!

发现一款 JSON 可视化工具神器,太爱了!

TopoLVM: 基于LVM的Kubernetes本地持久化方案,容量感知,动态创建PV,轻松使用本地磁盘

Anaconda3 is missing a large number of files during and after installation, and there are no scripts and other directories

There are two problems when Nacos calls microservices: 1 Load balancer does not contain an instance for the service 2. Connection refused

PAT甲级 1025 PAT Ranking
![Promise source code class version [III. promise source code] [detailed code comments / complete test cases]](/img/51/e1c7d5a7241a6eca6c179ac2cb9088.png)
Promise source code class version [III. promise source code] [detailed code comments / complete test cases]

2021:Greedy Gradient Ensemble for Robust Visual Question Answering

卷积神经网络(CNN)网络结构及模型原理介绍
随机推荐
Kotlin Compose 隐式传参 CompositionLocalProvider
Further exploration of handler (I) (the most complete analysis of the core principle of handler)
Easy to use plug-ins in idea
A^2=E | 方程的解 | 这个方程究竟能告诉我们什么
TopoLVM: 基于LVM的Kubernetes本地持久化方案,容量感知,动态创建PV,轻松使用本地磁盘
语义化版本 2.0.0
JMeter distributed pressure measurement
Fplan power planning
NestJS环境变量配置,解决如何在拦截器(interceptor)注入服务(service)的问题
ERP demand and sales management Kingdee
PAT甲级 1025 PAT Ranking
Kotlin Compose compositionLocalOf 与 staticCompositionLocalOf
Cs5213 HDMI to VGA (with audio) single turn scheme, cs5213 HDMI to VGA (with audio) IC
静态时序分析-OCV和time derate
Geometric distribution (a discrete distribution)
ESP8266
GAMES101作业7提高-微表面材质的实现过程
通信中的机器学习最佳阅读资料列表
MATLAB | 基于分块图布局的三纵坐标图绘制
记录unity 自带读取excel的方法和遇到的一些坑的解决办法