当前位置:网站首页>Flink parsing (III): memory management
Flink parsing (III): memory management
2022-07-06 17:28:00 【Stray_ Lambs】
Catalog
MemorySegment Comparison between in heap memory and out of heap memory
memory management
Flink By Java Language developed by , And based on JVM All data analysis engines need to store a large amount of data in memory ,JVM There are several problems :
- Java Object storage density is low . because Java Objects need to store a lot of other information , For example, a boolean Objects occupy 16 Bytes of memory , It includes the object header 8 Bytes ,boolean Take up a byte , Align fill takes up 7 individual . It's equivalent to wasting 15 Bytes .
- Full GC It can have a huge impact on performance , Especially those with large memory space for processing larger data JVM,GC It may reach the second level or even the minute level .
- OOM Problems affect stability .OOM Is a common problem encountered by distributed computing frameworks , When JVM The size of all objects in exceeds the size assigned to JVM Memory size , It will happen OOM error , Lead to JVM collapse , The robustness and performance of distributed frameworks will be affected .
therefore , At present, more and more big data projects begin to manage themselves JVM The memory , To get something like C Same performance and avoidance OOM Happen , But pay attention to the problem of memory release .Flink To solve the above problems , Mainly in memory management 、 Custom serialization tools 、 Cache friendly data structures and algorithms 、 Out of heap memory 、JIT Compile optimization And so on .
Active memory management
Flink Instead of storing a large number of objects on the heap , Instead, the objects are serialized into a pre allocated memory block , This memory block is called MemorySegment( Mentioned in the back pressure mechanism ), Represents a fixed length of memory ( The default is 32KB), It's also Flink The smallest memory allocation unit in the , It also provides a very efficient reading and writing method . You can take MemorySegment Imagine it as Flink custom java.nio.ByteBuffer. The bottom layer can be an ordinary Java Byte array (byte[]), It can also be an application outside the heap ByteBuffer. Each record is stored serially in one or more MemorySegment in .
Flink stay TaskManager Running user code JVM process .TM The heap memory of is mainly divided into three parts .
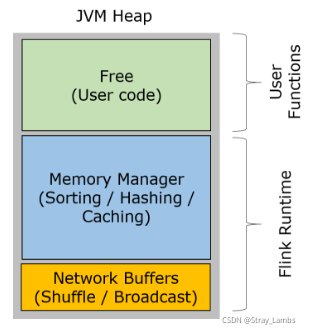
- Network Buffers: A certain number of MemorySegment, Mainly used for network transmission . stay TaskManager Assign on startup , adopt NetworkEnvironment and NetworkBufferPool Conduct management .
- Managed Memory: from MemoryManager A group of managers MemorySegment aggregate , It is mainly used for Batch Mode of sorting,hashing and cache etc. .
- Remaining JVM heap: The remaining heap memory is reserved for TaskManager Data structure and user code when processing data .TaskManager Its own data structure does not occupy too much memory , Therefore, they are mainly used by user code , Objects created by user code usually have a short life cycle
Be careful , The three parts of memory mentioned above are not all JVM Memory on the heap . about Network Buffers, This part of memory is outside the heap (off-heap) Assigned ; about Memory Manager, This part of memory can be configured on the heap , It can also be configured outside the heap . Another thing to note is ,Memory Manager Mainly in the Batch Use... In mode , And in the Streaming In mode, it is used for user-defined functions .
MemorySegment Comparison between in heap memory and out of heap memory
MemorySegment In earlier versions, the memory used in the heap , Subsequently, due to the memory in the heap, the following aspects , Added extra heap memory :
- Start a lot of memory (100s of GBytes heap memory) Of JVM It will take a long time ,GC Stay for a long time ( Seconds or even minutes ). Using off heap memory ,JVM You only need to allocate less heap memory .
- Zero copy technology can be used when writing to disk or network transmission in off heap memory ,I/O And network transmission are more efficient .
- Out of heap memory is shared between processes , in other words , Even if JVM Process crashes will not lose data . This can be used for fault recovery .Flink This feature has not been used yet .
however , There may also be some problems with off heap memory :
- Heap memory can be easily monitored and analyzed , In contrast, off heap memory is more difficult to control ;
- Flink Sometimes a short life cycle may be required MemorySegment, Applying on the heap costs less ;
- Some operations are faster on heap memory .
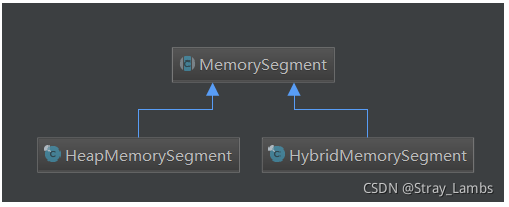
therefore ,Flink The original MemorySegment Becomes an abstract class , And provide two specific subclasses :HeapMemorySegment and HybridMemorySegment. The former is used to allocate heap memory , The latter is used to allocate off heap memory and heap memory .
Serialization method
Flink A similar DBMS Of sort and join Algorithm , Direct manipulation of binary data , So that serialization / The cost of deserialization is minimal . If the data to be processed exceeds the memory limit , Some data will be stored on the hard disk . The advantage of this treatment is :
- Reduce GC pressure . Obvious , Because all resident data exists in binary form Flink Of MemorySegment in , Staying in the old generation will not be GC Recycling . Other data objects are basically short-lived objects generated by user code , This part of the object can be Minor GC Quick recovery . As long as the user does not create a large number of resident objects similar to cache , Then the size of the old age will not change ,Major GC It will never happen . Thus, the pressure of waste recycling is effectively reduced . in addition , The memory block here can also be off heap memory , You can make JVM Smaller memory , So as to speed up garbage collection .
- Avoided OOM. All runtime data structures and algorithms can only apply for memory through the memory pool , It ensures that the memory size used is fixed , Does not happen because of runtime data structures and algorithms OOM. In the case of tight memory , Algorithm (sort/join etc. ) It can efficiently write a large number of memory blocks to disk , Then read back ( amount to spark The fall of the market ).
- Save memory space .Java Objects consume a lot of extra storage , If only the binary content of the actual data is stored , This part of consumption can be avoided .
- Efficient binary operation & Cache friendly Computing . Binary data is stored in a defined format , Can efficiently compare and operate . in addition , The binary form can put the relevant values , as well as hash value , Key values and pointers are placed adjacent to each other in memory , Make the data structure more cache friendly , It can be downloaded from L1/L2/L3 Cache performance improvement .
Flink Serialize data types
Now? Java There are already many serialization frameworks in the ecosystem , for instance Java serialization, Kryo, Apache Avro wait . however Flink Still choose your own customized serialization framework , So what's the point ? if Flink Choose your own customized serialization framework , The more you know about types , Type checking can be done early , Better way to choose serialization , Do data layout , Save data storage space , Direct manipulation of binary data .
Flink The data type of is shown in the figure , It can be divided into basic types (Basic)、 Array (Arrays)、 The compound type (Composite)、 Auxiliary type (Auxiliary)、 Generics and other types (Generic).Flink Support arbitrary Java or Scala type . No need to be like Hadoop To implement a specific interface as well (org.apache.hadoop.io.Writable),Flink Automatically identify data types . also Each specific type corresponds to a specific TypeInformation Implementation class .
TypeInformation yes Flink The core class of the type system . For user-defined Function Come on ,Flink A type information is needed as the input and output type of the function , namely TypeInfomation. The type information class is used as a tool to generate the serializer of the corresponding type TypeSerializer, And used to perform semantic checking .



Each specific data type corresponds to a TypeInformation The concrete realization of , every last TypeInformation Will provide an exclusive serializer for the corresponding specific data type . adopt Flink You can see the serialization process diagram of TypeInformation A createSerialize() Method , Through this method, you can get the objects of this type for data serialization and reordering operations TypeSerializer.
Flink Bottom principle of sorting algorithm
In a distributed computing framework , Sorting is the top priority . As a processing framework of stream batch integration Flink, There is no need to sort in streaming processing ( After all, the data comes one by one , There's no need to sort …), therefore sort Buffer Will be used as useBuffer. And in batch processing , because Flink Processing binary data , The data size is inconsistent, which leads to sorting directly , Movement will be relatively complex , You can't exchange two directly .
So we will sort Buffer Divided into two different MemorySegment, Adopt the idea of pointer , One area holds the complete binary data of all objects , Another area stores pointers to data and fixed length key, In other words, this area is used to store (key+point). If the data object is of variable length type , It will be serialized with its prefix .
The advantage of dividing into two areas is that , First of all , The area where the pointer is stored belongs to the fixed length block , Each object is a fixed length , Therefore, sorting and exchange are more efficient and convenient , The problem is that when comparing data, you need to send and serialize the comparison according to the pointer , This will affect efficiency . So while storing the pointer, it also stores key, It can also be understood as the prefix part of the data , The direct picture above may be clearer . second , Separate storage is cache friendly , because key It can be continuously stored in memory , Greatly improve the hit rate of cache .
To sum up :
- adopt Key and Full data The separated storage method minimizes the operated data as much as possible , Improve Cache The probability of hit , So as to improve CPU Throughput .
- When moving data , Just move Key+Pointer, Without moving the data itself , Greatly reduce the amount of data copied in memory .
- TypeComparator Operate directly on binary data , Saves deserialization time .

According to the picture above , A simple example , Describe the general process and method of sorting .
Assume that 100,101,200,1100,2000,23,14 Sort ,key Set to the first two digits + The number of digits , Then when sorting, it is based on the first comparison key The number of digits in , Two digit row ahead , Behind the four digit row , If the digits are the same , Then compare the size of the prefix ,10 Than 20 Small , And so on . In the end, we can't compare , Will deserialize the original data according to the pointer , Compare .
Because of the key The existence of , So it's easy to hit the cache , Effectively reduce a large number of deserialization operations , also L1/L2/L3 Cache performance has been improved . And the reason for fixing the length , It is also more convenient to exchange logical positions , It can be exchanged in pairs .
Reference resources
Flink Data type and serialization _lixinkuan The blog of -CSDN Blog _flink serialize
In depth understanding of Flink Core technology and principle - Laobaitiao - Blog Garden
边栏推荐
- February database ranking: how long can Oracle remain the first?
- [VNCTF 2022]ezmath wp
- Precipitated database operation class - version C (SQL Server)
- Flink 解析(一):基础概念解析
- Flink 解析(二):反压机制解析
- 信息与网络安全期末复习(完整版)
- CTF reverse entry question - dice
- CTF逆向入门题——掷骰子
- MySQL advanced (index, view, stored procedure, function, password modification)
- Interpretation of Flink source code (III): Interpretation of executiongraph source code
猜你喜欢
Resume of a microservice architecture teacher with 10 years of work experience

How does wechat prevent withdrawal come true?

全网最全tcpdump和Wireshark抓包实践
Garbage first of JVM garbage collector
JVM class loading subsystem
Koa Middleware

Wu Jun's trilogy insight (V) refusing fake workers

Deploy flask project based on LNMP
Program counter of JVM runtime data area
Set up the flutter environment pit collection
随机推荐
【逆向中级】跃跃欲试
网络分层概念及基本知识
DataGridView scroll bar positioning in C WinForm
mysql的合计/统计函数
ByteDance overseas technical team won the championship again: HD video coding has won the first place in 17 items
connection reset by peer
Basic knowledge of assembly language
【逆向】脱壳后修复IAT并关闭ASLR
MySQL advanced (index, view, stored procedure, function, password modification)
Redis快速入门
沉淀下来的数据库操作类-C#版(SQL Server)
Interpretation of Flink source code (III): Interpretation of executiongraph source code
C# WinForm系列-Button简单使用
February database ranking: how long can Oracle remain the first?
肖申克的救赎有感
About selenium starting Chrome browser flash back
Shawshank's sense of redemption
Flink 解析(六):Savepoints
Based on infragistics Document. Excel export table class
当前系统缺少NTFS格式转换器(convert.exe)