当前位置:网站首页>從交互模型中蒸餾知識!中科大&美團提出VIRT,兼具雙塔模型的效率和交互模型的性能,在文本匹配上實現性能和效率的平衡!...
從交互模型中蒸餾知識!中科大&美團提出VIRT,兼具雙塔模型的效率和交互模型的性能,在文本匹配上實現性能和效率的平衡!...
2022-07-06 18:08:00 【我愛計算機視覺】
關注公眾號,發現CV技術之美
本篇分享論文『VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction』,從交互模型中蒸餾知識!中科大&美團提出VIRT,兼具雙塔模型的效率和交互模型的性能,在文本匹配上實現性能和效率的平衡!
詳細信息如下:

論文鏈接:https://arxiv.org/abs/2112.04195
01
摘要
隨著預訓練Transformer的蓬勃發展,基於孿生Transformer編碼器的錶示模型已成為高效文本匹配的主流技術。然而,與基於交互的模型相比,由於文本對之間缺乏交互,這些模型的性能嚴重下降。現有技術試圖通過對孿生編碼錶示進行額外的交互來解决這一問題,而編碼過程中的交互仍然被忽略。
為了解决這一問題,作者提出了一種虛擬交互機制(VIRT),通過注意力圖提取將交互知識從基於交互的模型轉移到孿生編碼器。VIRT作為一個僅用於訓練運行時的組件,可以完全保持孿生結構的高效性,並且在推理過程中不會帶來額外的計算成本。為了充分利用所學的交互知識,作者進一步設計了一種適應VIRT的交互策略。
在多個文本匹配數據集上的實驗結果錶明,本文的方法優於現有的基於錶示的模型。此外,VIRT可以輕松地集成到現有的基於錶示的方法中,以實現進一步的改進。
02
Motivation
文本匹配旨在對一對文本之間的語義關聯進行建模,這是各種自然語言理解應用中的一個基本問題。例如,在社區問答(CQA)系統中,一個關鍵組件是通過問題匹配從數據庫中找到與用戶問題相關的類似問題。類似地,對話代理需要通過預測用戶陳述和一些預定義假設之間的蘊含關系來進行邏輯推斷。
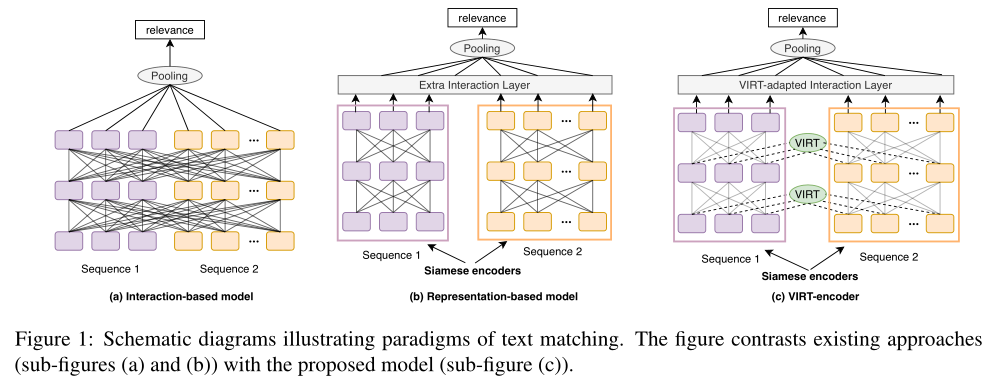
最近,深度預訓練Transformer的廣泛使用在文本匹配任務方面取得了顯著進展。通常有兩種基於微調Transformer編碼器的範例:基於交互的模型(即交叉編碼器)和基於錶示的模型(即雙編碼器),如上圖(a)和(b)所示。基於交互的模型(例如,BERT)將文本對concat為單個序列,並在文本對之間執行完全交互。雖然完全交互提供了從模型底部到頂部的豐富匹配信號,但它也帶來了較高的計算成本和推理延遲,這使得它很難在實際場景中部署。
例如,在一個電子商務搜索系統中,由於有數百萬個好的查詢對,使用基於交互的模型對這些對進行評分需要花費數十天的時間。相反,基於錶示的模型由兩個孿生編碼器獨立編碼文本對,而無需任何交互。因此,它支持嵌入的離線計算,這大大减少了在線延遲,從而使此類模型在實踐中非常有用。不幸的是,沒有任何交互的獨立編碼可能會丟失匹配信號,從而導致性能嚴重下降。
為了平衡效率和效能,一些工作試圖為孿生結構配備交互模塊。已經提出了各種交互策略,例如注意力層和Transformer層。然而,出於效率考慮,這些交互模塊是在孿生編碼器之後添加的,為了保留孿生特性,孿生編碼器編碼過程中的交互仍然被忽略。因此,豐富的交互信號丟失,現有的基於錶示的模型在以下方面仍然遠遠落後於基於交互的模型。
在這項工作中,作者試圖打破基於交互的模型和基於錶示的模型之間的困境。關鍵思想是在基於錶示的模型中,在不破壞孿生結構的情况下,整合孿生編碼過程中的交互。為此,作者提出了虛擬交互(VIRT),這是一種將文本對交互中的知識傳遞到基於錶示的模型的孿生編碼器的新機制。
具體來說,孿生編碼器通過模仿完整的交互來學習這對文本之間的交互信息,並以基於交互的模型傳遞的知識為指導。將知識轉移作為訓練過程中的注意圖提取任務來實現,在推理過程中可以删除該任務以保持孿生特征。因此稱之為“虛擬互動”。此外,為了進一步利用孿生編碼後所學的交互知識,作者設計了一種虛擬適應的交互策略。在一個名為VIRT編碼器的基於錶示的模型聯合實現了VIRT和VIRT適應的交互策略,如上圖(c)所示。
本文的貢獻可以總結如下:
作者提出了一種新的虛擬交互機制VIRT,通過從基於交互的模型中提取注意力圖,將其集成到基於錶示的模型的孿生編碼器中,而無需額外的推理成本。
大量實驗錶明,本文提出的VIRT編碼器優於以前基於SOTA錶示的模型,同時保持了推理效率。
VIRT可以很容易地集成到其他基於錶示的文本匹配模型中,以進一步提高其性能。
03
方法
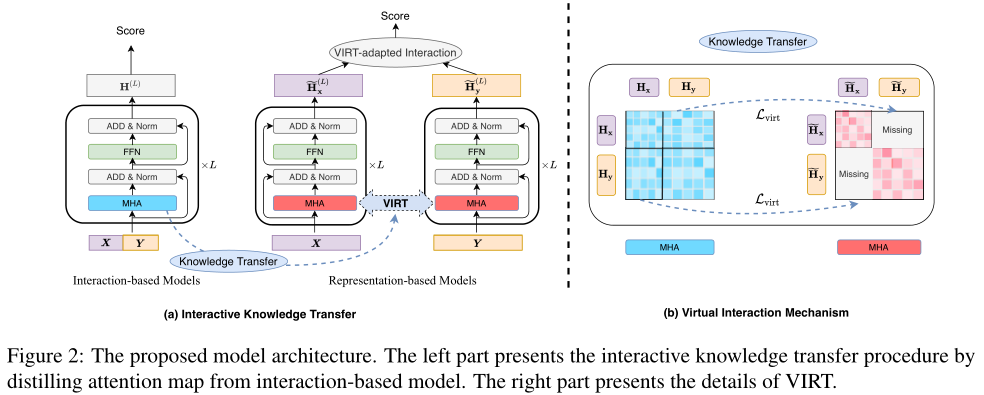
在本節中,作者將首先描述基於交互的模型和基於錶示的模型。然後,介紹虛擬交互機制(VIRT),它將交互知識從基於交互的模型提取到孿生編碼器。此外,通過VIRT適應的交互策略,可以充分利用所學的交互知識。VIRT的體系結構如上圖所示。
3.1 Interaction-based Models
給定兩個文本序列和作為輸入,基於交互的模型將X和Y concat為,並使用L層Transformer對進行編碼:。Transformer的每一層由兩個殘差子層組成:一個多頭注意力操作(MHA)和一個前饋網絡(FFN):
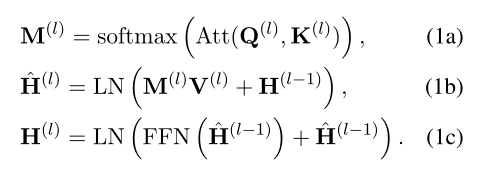
,其中d是隱藏狀態的維數。這裏,為了便於描述,省略了batch大小和注意力頭的維度。
402 Payment Required
是第(l-1)層的中間錶示,它對X和Y之間的交互信息進行編碼。 和 是第l層的注意力參數,由 映射而來。 錶示LayerNorm操作。可以看到,基於交互的模型能够通過完全注意力機制將交互信息編碼到X和Y的錶示中。具體地,組合錶示以生成注意力圖M,其錶示不同交互信號的權重。這些錶示根據M來進行選擇和融合。
3.2 Representation-based Models
與基於交互的模型相比,基於錶示的模型首先通過兩個獨立的孿生Transformer編碼器分別對X和Y進行編碼(這裏假設每個編碼器有L個Transformer層):,。然後,它們對孿生編碼的和進行額外的相互作用。transformer的結構與基於交互的模型相同,只是注意圖(或)僅用X(或Y)單獨計算:
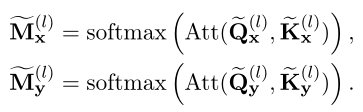
與基於交互的模型相比,編碼過程中X和Y之間沒有交互。在基於錶示的模型中,X和Y之間的細粒度交互信息會丟失,這會導致性能下降。
3.3 Virtual Interaction
如前所述,基於錶示的模型的主要缺點是在單獨編碼兩個輸入序列時缺乏交互。直觀地說,基於交互的模型通過MHA機制執行交互。通過對應於X和Y的錶示來計算。與基於交互的模型相比,基於錶示的模型僅通過X(或Y)單獨計算(或)。在接下來的部分中,將首先詳細說明這兩種模型在MHA操作方面的差异。接下來,介紹了VIRT機制,它可以在不增加額外推理成本的情况下改進基於錶示的模型。
首先分解基於交互模型的MHA操作,如上圖(b)中的藍色注意圖所示。具體而言,基於交互的模型中第l層的輸入錶示,即,可分解為X部分和Y部分。因此,,其中,
402 Payment Required
。基於此,注意力參數也可以重寫為X部分(錶示為 和 )和Y部分(錶示為 和 )的組合。Softmax(·)操作之前的最終注意力得分(錶示為 )可分解為以下分區矩陣: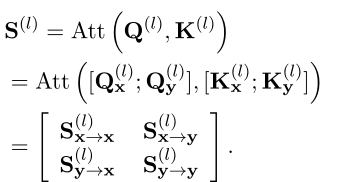
因此可以分為四部分:
402 Payment Required
,即: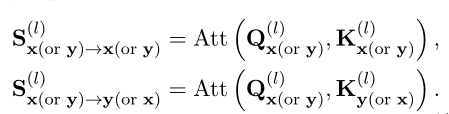
是僅在X或Y中執行的MHA操作,其對應於基於錶示的模型中的MHA操作。和指基於交互的模型中x和Y之間的交互,這些模型負責用交互信息豐富錶示。然而,它們在基於錶示的模型中缺失,從而導致這兩種模型之間的性能差距。
通過以上分析,可以將基於錶示的模型的缺失交互提取為X和Y之間的MHA操作。為了恢複這種缺失的交互,讓基於錶征的模型模擬基於交互模型中的交互,如下所示:
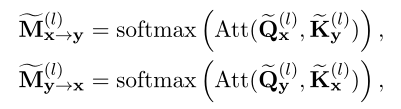
其中錶示由attend到生成的注意力圖,錶示由attend到生成的注意力圖。這兩個額外的注意力圖錶示基於錶示的模型中缺少的交互信號。
由於希望將基於錶征的模型的性能改進為基於交互的模型,因此作者提出將缺失的注意圖與其在基於交互的模型中已經存在的對應關系進行對齊。基於交互的模型中的注意圖可以指導錶征(即和)朝著交互豐富的方向發展,就好像錶示在編碼過程中相互作用一樣。通過這種方式,在交互過程中提取知識,並將其傳輸到雙編碼器中,而不需要任何額外的計算開銷。這就是為什麼稱這種機制為“虛擬交互”。
為了實現VIRT,作者采用了知識蒸餾技術,其中一個經過訓練的基於交互的模型被視為教師,一個需要訓練的基於錶示的模型被視為學生。和對應基於交互的模型中X和Y之間的交互。他們可以直接從softmax(·)之前的注意力分數中得到:是的前m行和最後n列部分,對應於最後n行和前m列。除了softmax操作之外,作者還直接挑選這兩個切片,以從基於交互的模型中形成引導注意圖:
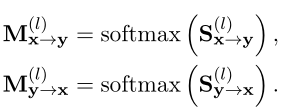
作為有監督的交互知識進一步轉移,以指導VIRT。具體來說,目標是最小化和的L2距離:
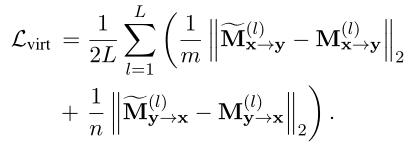
僅在訓練階段將上述公式作為優化目標,並在推理期間將其删除。這保留了基於錶示的模型的孿生屬性,同時不會帶來額外的推理成本。
3.4 VIRT-Adapted Interaction
通過VIRT,交互知識可以深入到基於錶示的模型的每個編碼層中。然而,在孿生編碼後,最後一層的錶示,即和,仍然無法看到對方,因此缺乏明確的交互。為了充分利用所學的交互知識,作者進一步設計了一種適應VIRT的交互策略,該策略在VIRT學習的注意力圖的指導下融合了和。
具體而言,作者在以下過程中執行和之間的VIRT適應交互。生成的注意圖公式如下:
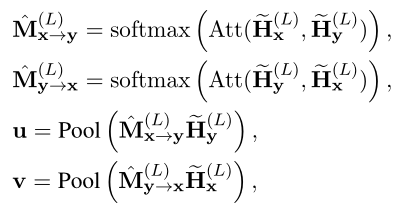
其中Pool(·)錶示平均池化操作。最後,利用簡單融合預測匹配標簽y:
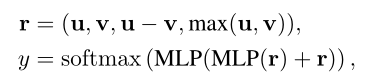
其中是concat操作,MLP錶示多層感知機。總體訓練目標是將特定任務的監督損失(即交叉熵損失)和的組合降至最低:
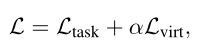
其中α是衡量虛擬交互影響的超參數。
值得注意的是,VIRT是一種通用策略,可用於增强任何基於錶示的匹配模型。
04
實驗
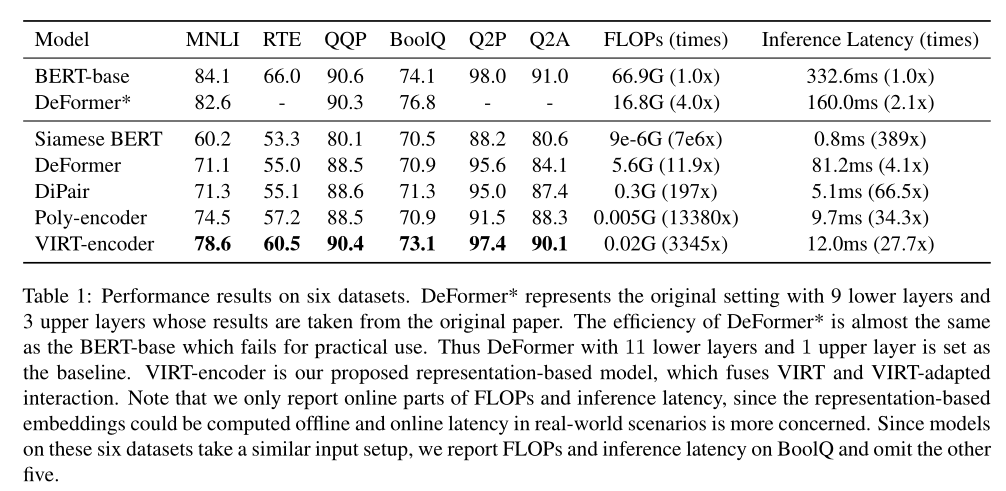
不同方法的性能如上錶所示。BERT-base作為一個强大的基於交互的模型,顯示了它的有效性。與BERT相比,Siamese BERT的性能顯著下降。本文提出的VIRT編碼器實現了最好的性能,優於所有基於錶示的baseline,甚至與基於交互的BERT模型相比具有競爭力。這證明VIRT能够近似基於交互的模型的深度交互建模能力。
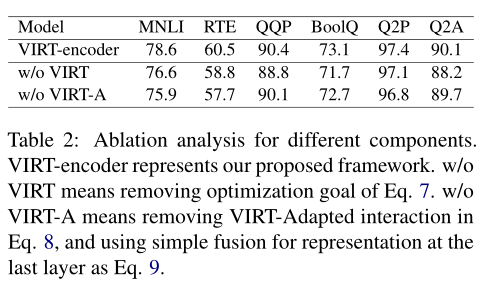
上錶顯示了本文提出的VIRT以及VIRT適應相互作用的貢獻。不使用VIRT或VIRT適應交互的性能下降錶明了這兩種體系結構的有效性。對於MNLI和RTE,由於移除VIRT適應的交互而導致的性能下降更為嚴重。
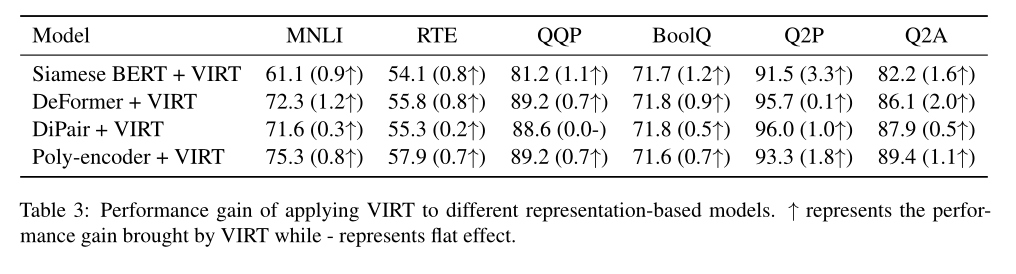
為了驗證所提出的VIRT的通用性,作者進一步將其導入到上述基於錶示的模型中。結果如上錶所示。根據結果,可以觀察到VIRT可以很容易地集成到其他基於錶示的文本匹配模型中,以進一步提高性能。
05
總結
基於錶示的模型因其效率高而被廣泛應用於文本匹配任務中,而基於交互的模型由於缺乏交互而性能不佳。以前的工作經常引入額外的交互層,而孿生編碼器中的交互仍然缺失。
在本文中,作者提出了一種虛擬交互(VIRT)機制,該機制可以通過從基於交互的模型中提取注意圖到基於錶示模型的孿生編碼器來近似交互建模能力,而無需額外的推理成本。
所提出的VIRT編碼器采用VIRT和VIRT適應交互策略,在多個文本匹配任務中實現了現有基於錶示的模型的最新性能。此外,VIRT對現有的基於錶示的模型進行了進一步的改進。
參考資料
[1]https://arxiv.org/abs/2112.04195

END
加入「計算機視覺」交流群備注:CV

边栏推荐
- SAP UI5 框架的 manifest.json
- 中移动、蚂蚁、顺丰、兴盛优选技术专家,带你了解架构稳定性保障
- Unity particle special effects series - treasure chest of shining stars
- JMeter interface test response data garbled
- 面试突击63:MySQL 中如何去重?
- node の SQLite
- Reppoints: advanced order of deformable convolution
- Unity tips - draw aiming Center
- Is it meaningful for 8-bit MCU to run RTOS?
- MarkDown语法——更好地写博客
猜你喜欢

一体化实时 HTAP 数据库 StoneDB,如何替换 MySQL 并实现近百倍性能提升

RB157-ASEMI整流桥RB157

基于STM32+华为云IOT设计的智能路灯
编译原理——预测表C语言实现

传统家装有落差,VR全景家装让你体验新房落成效果
Video fusion cloud platform easycvr adds multi-level grouping, which can flexibly manage access devices

Take you through ancient Rome, the meta universe bus is coming # Invisible Cities

开源与安全的“冰与火之歌”
C语言指针*p++、*(p++)、*++p、*(++p)、(*p)++、++(*p)对比实例

Getting started with pytest ----- test case pre post, firmware
随机推荐
8位MCU跑RTOS有没有意义?
一体化实时 HTAP 数据库 StoneDB,如何替换 MySQL 并实现近百倍性能提升
李書福為何要親自掛帥造手機?
How to use scroll bars to dynamically adjust parameters in opencv
1700C - Helping the Nature
基于STM32+华为云IOT设计的智能路灯
Easy introduction to SQL (1): addition, deletion, modification and simple query
Interesting - questions about undefined
面试突击62:group by 有哪些注意事项?
传统家装有落差,VR全景家装让你体验新房落成效果
ASEMI整流桥DB207的导通时间与参数选择
Jerry's watch deletes the existing dial file [chapter]
J'aimerais dire quelques mots de plus sur ce problème de communication...
高精度运算
重磅!蚂蚁开源可信隐私计算框架“隐语”,主流技术灵活组装、开发者友好分层设计...
Interview assault 63: how to remove duplication in MySQL?
What is the reason why the video cannot be played normally after the easycvr access device turns on the audio?
std::true_type和std::false_type
30 分钟看懂 PCA 主成分分析
Reppoints: advanced order of deformable convolution