当前位置:网站首页>Flink优化及相关
Flink优化及相关
2022-08-02 21:03:00 【boyzwz】
一、Flink的优化
1、MiniBatch 聚合
默认情况下,无界聚合算子是逐条处理输入的记录,即:(1)从状态中读取累加器,(2)累加/撤回记录至累加器,(3)将累加器写回状态,(4)下一条记录将再次从(1)开始处理。
MiniBatch 聚合的核心思想是将一组输入的数据缓存在聚合算子内部的缓冲区中。当输入的数据被触发处理时,每个 key 只需一个操作即可访问状态。这样可以大大减少状态开销并获得更好的吞吐量。但是,这可能会增加一些延迟,因为它会缓冲一些记录而不是立即处理它们。这是吞吐量和延迟之间的权衡。
下图说明了 mini-batch 聚合如何减少状态操作。

开启MiniBatch 聚合(命令行执行):
-- sql中开启
-- 开启
set table.exec.mini-batch.enabled=true;
-- 最大缓存时间
set table.exec.mini-batch.allow-latency='5 s';
-- 批次大小
set table.exec.mini-batch.size=1000;2、 Local-Global 聚合
Local-Global 聚合是为解决数据倾斜问题提出的,通过将一组聚合分为两个阶段,首先在上游进行本地聚合,然后在下游进行全局聚合,类似于 MapReduce 中的 Combine + Reduce 模式。即数据在map端进行预聚合,减少shuffle阶段数据传输量,这可以大大减少网络 shuffle 和状态访问的成本。

开启 Local-Global 聚合(依赖于启用了 mini-batch):
-- 开启预聚合需要先开启MiniBatch
set table.exec.mini-batch.enabled=true;
-- 最大缓存时间
set table.exec.mini-batch.allow-latency='5 s';
-- 批次大小
set table.exec.mini-batch.size=1000;
-- 开启预聚合
set table.optimizer.agg-phase-strategy=TWO_PHASE;二、Flink的反压
Flink中上游的任务生产数据的速度比下游任务消费数据的速度大,Flink就会发生反压,反压会从下游向上游传播,直到sourcetask会降低拉取数据速度,避免flink任务执行报错 。
Flink中下游任务若接收到的数据过多,来不及处理,则会先将数据放在内存中,当内存不够时,会告诉上游,上游会降低发送数据的速度,并将数据缓存起来,若上游内存不足时会继续向上游传递,直至source task,降低读取数据的速度
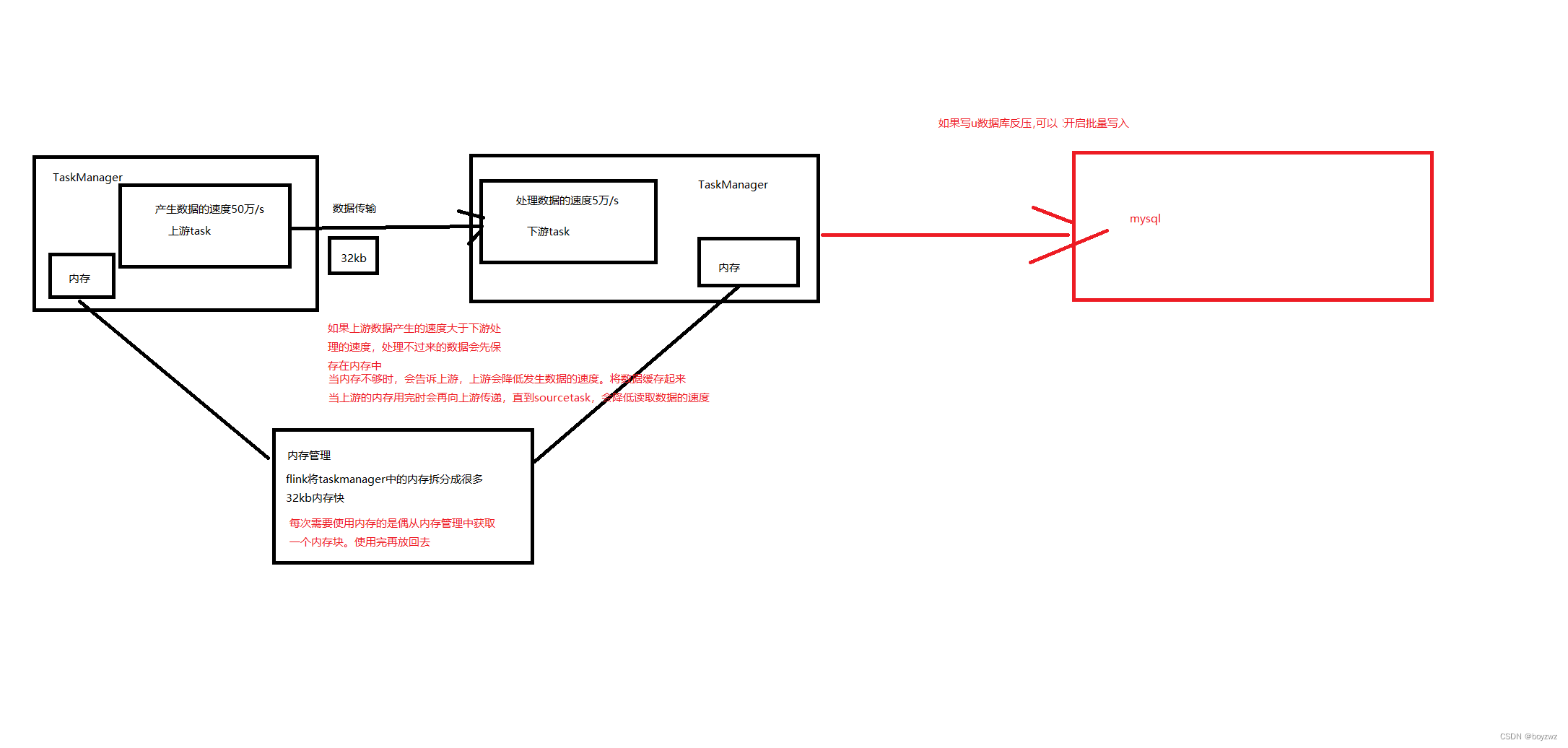
1、Flink内部反压
增加flink任务的并行度(即增加资源,加快数据处理)
开启MiniBatch和预聚合(会增加延迟)
2、将数据写入外部系统
Flink处理完数据向外部系统输出数据的速度大于外部系统写入的速度,可增加并行度,加快写入速度
Flink写入hbase可以开启异步IO,lookup.async=true,只支持hbase2.2以上版本
-- 在创建flink sink表时添加设置
-- 每批次最大值,会增加延迟
'sink.buffer-flush.max-rows'='1000'
--提高写入数据并行度,增加成本
'sink.parallelism' ='3' 三、Flink Join
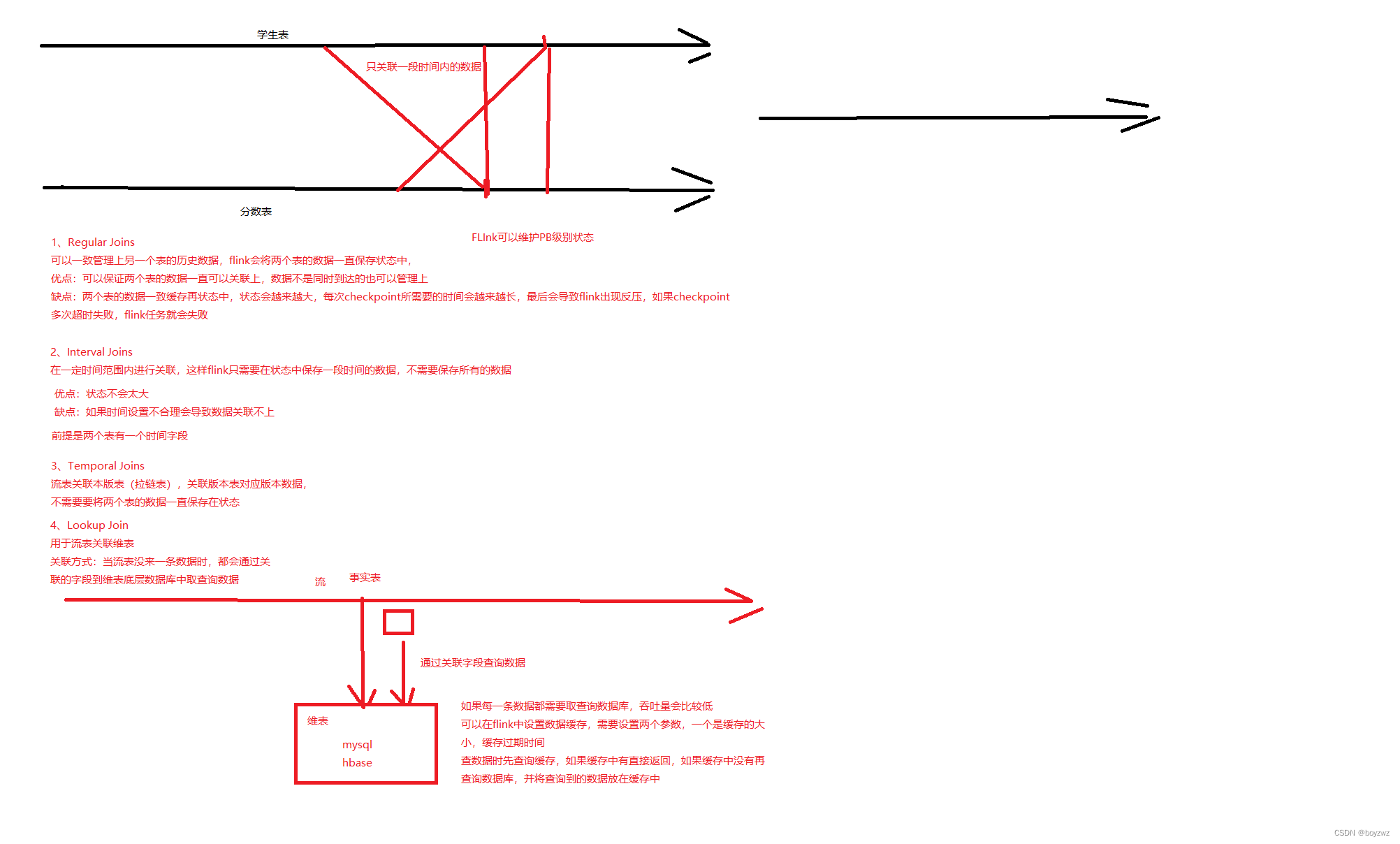
1、Regular Joins
两个动态表关联,会将两个表的数据一直保存在状态中,随着数据的读取,状态会越来越大;
类似于批处理中两表关联
-- eg
SELECT * FROM Orders
INNER/LEFT/FULL JOIN Product
ON Orders.productId = Product.id2、Interval Joins
关联一段时间内的数据,只需在状态中保存该时间段内的数据
-- eg
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_time
-- s.ship_time - INTERVAL '4' HOUR <= o.order_time <= s.ship_time 才会关联3、Temporal Joins
流表关联版本表(拉链表),不需要将两个表的数据一直保存在状态
-- Temporal Joins
SELECT
order_id,
price,
orders.currency,
conversion_rate,
order_time
FROM orders
LEFT JOIN currency_rates FOR SYSTEM_TIME AS OF orders.order_time
ON orders.currency = currency_rates.currency;4、流表关联维表
常规Join:
从数据库中读取维表数据保存在状态中与流表关联,若在数据库中维表的数据发生改变,在flink中无法捕获更新,因为flink读取数据库表为有界流,读取完数据任务就结束了,所以只能关联到任务刚启动时读取的数据
Lookup Join:
Lookup Join关联方式,流表需要有一个时间字段
Lookup Join是在流表中每来一条数据时,再通过关联字段到维表底层数据库中查询数据进行关联,不用在状态中保存数据库数据,但会增加延迟
优化,可以在flink中设置缓存数据,每次在数据库查找以后,将数据加载到缓存中,可以在下次关联数据时,先在缓存中查找,缓存中没有再去数据库中查找
'lookup.cache.max-rows' = '100' ,-- 开启缓存,指定缓存数据量,可以提高关联性能
'lookup.cache.ttl' = '30s' -- 缓存过期时间,一般会按照维表更新频率设置
-- eg
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;边栏推荐
- 包管理工具Chocolate - Win10如何安装Chocolate工具、快速上手、进阶用法
- Electrical diagram of power supply system
- 增删改查这么多年,最后栽在MySQL的架构设计上!
- 从零开始配置 vim(5)——本地设置与全局设置
- js函数防抖和函数节流及其他使用场景
- [C题目]力扣1. 两数之和
- Flutter 常见异常分析
- Li Mu hands-on deep learning V2-BERT pre-training and code implementation
- How to use windbg check c # a thread stack size?
- 模糊查询like用法实例(Bee)
猜你喜欢




随机推荐
js函数防抖和函数节流及其他使用场景
引用类型 ,值类型 ,小坑。
汉源高科千兆4光4电工业级网管型智能环网冗余以太网交换机防浪涌防雷导轨式安装
用户之声 | 我与GBase的缘分
@Transactional 事务调用与生效场景总结
并发与并行
Bena's life cycle
汇编语言中b和bl关键字的区别
JumpServer open source bastion machine completes Loongson architecture compatibility certification
HCIP--路由策略实验
命令行启动常见问题及解决方案
Day35 LeetCode
【流媒体】推流与拉流简介
CS5213芯片|HDMI to VGA转换头芯片资料分享
如何成为一名正义黑客?你应该学习什么?
包管理工具Chocolate - Win10如何安装Chocolate工具、快速上手、进阶用法
解道6-编程技术3
Nervegrowold hands-on learning deep learning V2 - Bert pre training data set and code implementation
golang刷leetcode:统计区间中的整数数目
JMeter的基本使用