当前位置:网站首页>Concurrent optimization summary
Concurrent optimization summary
2022-07-04 22:14:00 【51CTO】
involves The project is only basic Some things can't be described in detail and can be summarized
Concurrent mode : Reactor The driver Asynchronous completion flag Receiver - The connector
- Reactor Reactor: Event driven applications can be multiplexed --- Distribute ; Control flow can be reversed ; Same as Hollywood principle :“ Don't call us , We will call you ”;
- shortcoming : It cannot support a large number of customers and time-consuming customer requests at the same time ; as a result of The reactor is in the process of event multiplexing Serialization handles all events ;
- The driver Proactor: Different from the reactor mode of passive response , In the active mode, the customer request and the program that completes the request processing are processed through an asynchronous operation ; After the step-by-step operation is completed ,
- Asynchronously operate the processor and the specified driver Procator Components Demultiplex the completion event to the relevant program , And assign hook methods to these programs . After handling an event , Activate another asynchronous operation request
- Asynchronous completion flag : So that the application can effectively multiplex and process the response caused by calling asynchronous operations in the service , So as to improve the efficiency of asynchronous processing , It mainly focuses on the optimization of task multiplexing in the active mode .
- Receiver - The connector : This mode is often used in conjunction with reactor mode , Separate the connection and cooperation initialization of peer services in the networked system from the subsequent processing , This pattern allows applications to configure their connection topology , This configuration does not depend on the services provided by the application
Reactor: How to multiplex events and allocate them to corresponding service programs 、 What are the precautions 、 What are the problems ?
- To improve scalability and responsiveness , Applications should not be blocked by a single indication event , Otherwise, the throughput response will be reduced
- To maximize throughput , To avoid cpu Any unnecessary context switching between Sync Data mobility
- The new or improved service should easily integrate the existing instruction event multiplexing and allocation mechanism
- The application layer code should not be affected by the complexity of multithreading and synchronization mechanism
Solution
Wait for multiple event sources synchronously ( Like connected Socket Handle ) The indication event of arrives . The mechanism for event multiplexing and the allocation of services to handle events will be integrated ; Separate the event multiplexing and allocation mechanism from the application related processing of indicating events in the service .
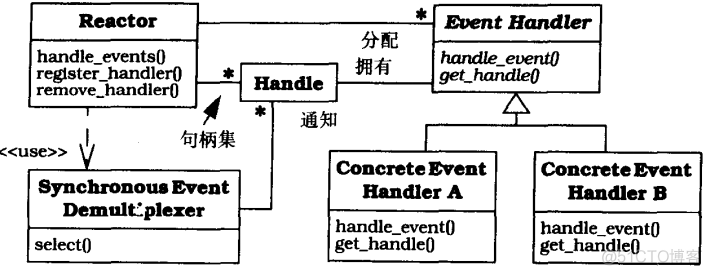
details : For each service provided by the application , Introduce a separate event handler to handle a certain type of event of a certain event source . Register all event handlers in the reactor , The reactor uses a synchronous event demultiplexer to wait for an indication event from one or more event sources . After an indication event , The synchronous event resolver notifies the reactor , The latter synchronously assigns event handlers related to events , So that these event handlers can execute the requested service .
structure
The operating system provides a handle (handle) To identify event sources such as network connections or open files , The event source generates an indication event and queues its . The indication event can come from the outside , It can also come from inside . Once an event source generates an indication event , The prompt event is sent to the queue of the relevant handle , The handle is marked “ be ready ”. This will not block the calling thread .
synchronous event demultiplexer (synchronous event demultiplexer) It's a function . Call this function , You can wait for a set of handles to occur ( Handle set ) One or more indication events on . This function has been blocked at the beginning , Until the indication event on the handle set notifies the synchronous event demultiplexer “ One or more handles on the handle set become ‘ be ready ’”, This means that an operation on the handle can be started without blocking .

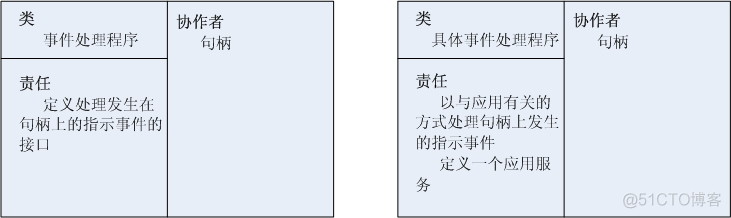
The event handler defines an interface consisting of one or more hook methods . Hook method represents operation , These operations can be used to handle application related indication events that occur on the handle associated with an event handler .
Specific event handlers (concrete event handle) It is an event handler that implements the specific services provided by the application . Each specific event handler is associated with a handle , The handle determines the service in the application . In particular, the specific event handler implements the hook method , These hook methods are responsible for processing the indication events received through the corresponding handle . Write the service result to the handle , And return it to the caller .
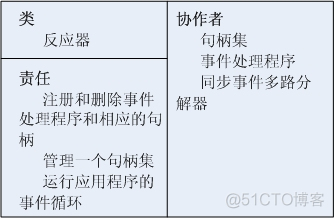
Reactor (reactor) An interface is defined , Allow applications to register or delete event handlers and their corresponding handles , And run the event loop of the application . The reactor uses a synchronous event resolver to wait for an indication event to occur on the handle set . When there is an indication event , The reactor first demultiplexes each indication event to the corresponding event handler from the handle where the indication event occurs , Then allocate the appropriate hook method on the handle to handle these events .
The reactor mode structure is : How to apply the control flow “ The horse ”; Wait for the indication event , The demultiplexer distributes these events to specific application handlers , Assign hook methods to specific event handlers ,
All this is done in reactors Not the responsibility of the application . The specific event handler does not call the reactor ; The reactor assigns a specific event handler . This is a “ Control reversal ” 了
Reactor assembly coupling diagram
Realization
The various parts of the reactor mode are divided into two layers :
· Multichannel decomposition / Allocate components of the infrastructure layer . This layer implements a general , Application independent strategies , Used to demultiplex indication events into event handlers , Then assign the method of the corresponding event handler hook .
· Application layer components . This layer defines specific event handlers , Handle application related processing in the hook method of the specific event handler .
1) Define the event handler interface . The event handler specifies an interface composed of one or more hook methods . These hook methods represent the set of services available to process the indicated event pieces received and allocated by the reactor .
1.1) Determine the type of assignment target . In order to realize the allocation strategy of the reactor , A handle can have two types of event handlers .
· Event handler object (event handler object). In object-oriented applications , A common way to combine event handlers with handles is to create an event handler object .
· Event handler functions (event handler function). Another strategy for combining event handlers with handles is to register a pointer to a function with the reactor . Use function pointers as allocation targets , There is no need to define new subclasses that inherit the event handler base class , You can easily register callback functions .
1.2) Determine the event handler allocation interface policy . Next, you must define the interface types supported by the event handler . Suppose you use an event handler object instead of a function pointer , Here are two general strategies :
· Single method allocation interface policy (single-method dispatch interface strategy). This interface only includes one event handling method . Assign interface policies using a single method , Without changing the class interface , Support new indication event types . But this strategy requires extensive use in the methods of specific event handlers switch and if Statement to handle specific events , This reduces scalability .
· Multi method allocation interface strategy . The strategy is to create a separate hook method for handling each type of event . This is more extensible than the single method allocation interface strategy , Because it is implemented by the reactor rather than by the method of specific event handlers .
2) Define the reactor interface . The application uses the reactor interface to register or delete the event handler and the corresponding handle , And call the event loop of the application .
3) Implement the reactor interface .
3.1) Develop the implementation level of the reactor .
3.2) Choose a synchronous event demultiplexer mechanism .
3.3) Implement a multiway decomposition table . In addition to calling the synchronous event resolver to wait for an indication event to occur in the handle set , The reactor implementation also needs to maintain a multiway decomposition table . The table is a manager , Contains a format of < Handle , Event handler , Indicates the event type > Triple table of . The reactor implementation uses the handle as the key to establish the association with the event handler in the multi decomposition table . This table also stores the type of indication event registered by the event handler to the handle .
3.4) Define the specific implementation of the reactor .
4) Determine the number of reactors required for the application . For some real-time applications , By associating different reactors with threads with different priorities , It can provide different levels of quality of service for different types of synchronous operations to process indication events .
5) Implement specific event handlers .
5.1) Determine the strategy for maintaining the state of specific event handlers . An event handler needs to maintain status information related to a specific request .
5.2) Implement the policy of configuring each specific event handler with a handle .
· Hard encoding . This strategy hard codes the handle or the wrapper appearance of the handle into a specific event handler . This method is easy to implement , However, for different applications, different types of handles or IPC When the mechanism is configured into the event handler , Poor reusability .
· Genus (generic) Method . A more general strategy is to instantiate the wrapper appearance with type as a parameter in the templated event handler class . This method can produce more flexible and reusable event handlers , Although always use a handle type or IPC In the case of mechanisms , This versatility is unnecessary .
5.3) Realize the function of specific event handler .
advantage :
1) Transaction separation . The reactor mode separates the application independent multiplexing and allocation mechanism from the application related hook method function . Application independent mechanisms are designed as reusable components . This component knows how to multiplex the indicated event and assign the appropriate hook method defined by the event handler . contrary , The application related functions in the hook method know how to complete a specific type of service .
2) modularization , Reusability and configurability . This pattern decomposes the event driven application function into several components . They are loosely integrated in the reactor , This modularity is conducive to higher-level software component reuse .
3) Portability . Just separate the reactor interface from the synchronous event demultiplexer function of the low-level operating system used in the implementation , You can easily migrate applications that use the reactor pattern across platforms .
Insufficient :
1) The scope of application is limited . If the operating system supports synchronous event multiplexing of handle sets , Using reactor mode will be very efficient . However , If the operating system does not provide such support , You can use multithreading in the reactor implementation to simulate the semantics of the reactor pattern .
2) Non preemptive way (Non-pre-emptive). Event handlers should not perform time-consuming operations , Because this will block the whole process , And prevent the reactor from responding to clients connected to other handles .
3) The complexity of debugging and testing .
MEM:
- Cache efficiency principle
- Cache update strategy
- Cache usage scenarios ------ Read more and write less :
- Memory pool
- Thread pool
- Object pool
CPU:
- Zero copy
- IO Reuse
- protoubuf
- No lock programming lock-free lock-wait
- Multithreading
- Request merge Event merging
- Preprocessing
- Delays in processing
- Service decoupling --- Subscribe to the publication model Flow control cache

Design :
How to design statistical counters ?
Array based implementation , Reference resources per_cpu Variable ; In a multithreaded TLS Stored per thread _thread Storage class
Requirements for consistency of results ??
1 unsigned long __thread counter = 0;
2 unsigned long *counterp[NR_THREADS] = { NULL };
3 unsigned long finalcount = 0;
4 DEFINE_SPINLOCK(final_mutex);
5
6 static __inline__ void inc_count(void)
7 {
8 WRITE_ONCE(counter, counter + 1);
9 }
10
11 static __inline__ unsigned long read_count(void)
12 {
13 int t;
14 unsigned long sum;
15
16 spin_lock(&final_mutex);
17 sum = finalcount;
18 for_each_thread(t)
19 if (counterp[t] != NULL)
20 sum += READ_ONCE(*counterp[t]);
21 spin_unlock(&final_mutex);
22 return sum;
23 }
24
25 void count_register_thread(unsigned long *p)
26 {
27 int idx = smp_thread_id();
28
29 spin_lock(&final_mutex);
30 counterp[idx] = &counter;
31 spin_unlock(&final_mutex);
32 }
34 void count_unregister_thread(int nthreadsexpected)
35 {
36 int idx = smp_thread_id();
38 spin_lock(&final_mutex);
39 finalcount += counter;
40 counterp[idx] = NULL;
41 spin_unlock(&final_mutex);
42 }
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
DEFINE_PER_THREAD(unsigned long, counter);
2 unsigned long global_count;
3 int stopflag;
5 static __inline__ void inc_count(void)
6 {
7 unsigned long *p_counter = &__get_thread_var(counter);
9 WRITE_ONCE(*p_counter, *p_counter + 1);
10 }
12 static __inline__ unsigned long read_count(void)
13 {
14 return READ_ONCE(global_count);
15 }
17 void *eventual(void *arg)
18 {
19 int t;
20 unsigned long sum;
22 while (READ_ONCE(stopflag)< 3) {
23 sum = 0;
24 for_each_thread(t)
25 sum += READ_ONCE(per_thread(counter, t));
26 WRITE_ONCE(global_count, sum);
27 poll(NULL, 0, 1);
28 if (READ_ONCE(stopflag)) {
29 smp_mb();
30 WRITE_ONCE(stopflag, stopflag + 1);
31 }
32 }
33 return NULL;
34 }
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
How to design the upper limit counter ?
Design of segmentation and synchronization
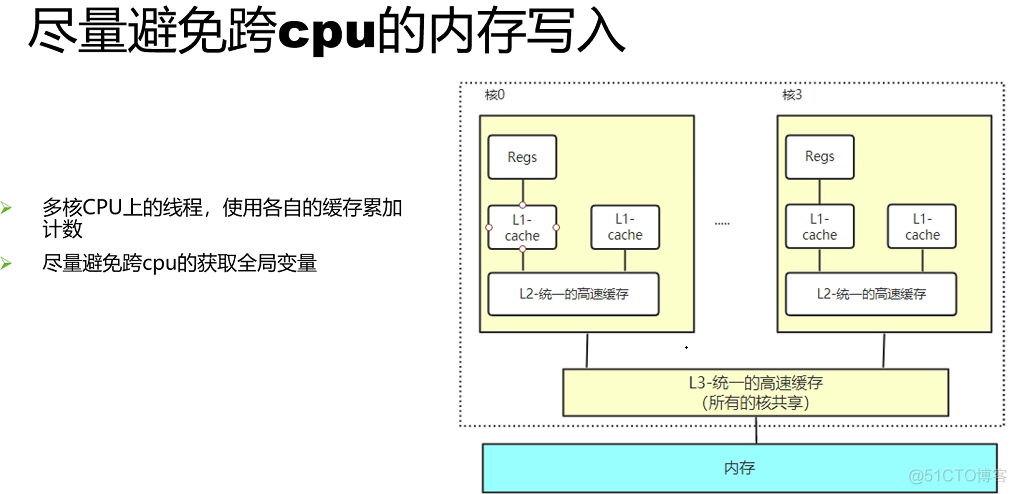
Resource allocation parallel fast path ----- Every time cpu Reserved cache ? General parallel programming methods include : line up 、 Reference count 、RCU
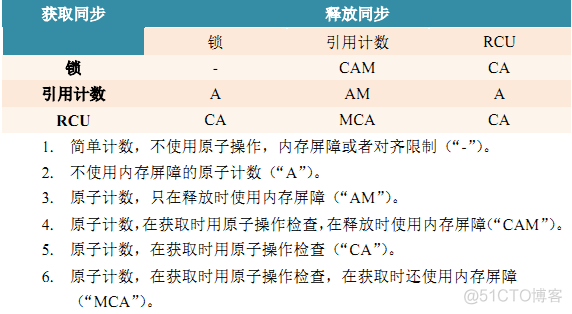
void kref_get(struct kref *kref)
{
WARN_ON(!atomic_read(&kref->refcount));
atomic_inc(&kref->refcount);
smp_mb__after_atomic_inc();
}
int kref_put(struct kref *kref, void (*release)(struct kref *kref))
{
WARN_ON(release == NULL);
WARN_ON(release == (void (*)(struct kref *))kfree);
if (atomic_dec_and_test(&kref->refcount)) {
release(kref);
return 1;
}
return 0;
}
/* initialization kref after ,kref The use of should follow the following three rules :
1) If you create a non transient copy of the structure pointer , Especially when this copy pointer will be passed to other execution threads , You must execute before passing the copy pointer kref_get():
kref_get(&data->refcount);
2) When you're done with , Pointers to structures are no longer needed , Must be implemented kref_put, If this is the last reference of the structure pointer ,release() Function will be called , If the code never calls without having a reference count kref_get(), stay kref_put() There is no need to lock :
kref_put(&data->refcount, data_release);
3) If the code attempts to call without having a reference count kref_get(), It has to be serialized kref_put() and kref_get() Implementation , Because it is likely to be kref_get() Before or during execution ,kref_put() Is called and the entire structure is released :
for example , You allocate some data and pass it to other threads to process :*/
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
/**
* kref_put - decrement refcount for object.
* @kref: object.
* @release: pointer to the function that will clean up the object when the
* last reference to the object is released.
* This pointer is required, and it is not acceptable to pass kfree
* in as this function. If the caller does pass kfree to this
* function, you will be publicly mocked mercilessly by the kref
* maintainer, and anyone else who happens to notice it. You have
* been warned.
*
* Decrement the refcount, and if 0, call release().
* Return 1 if the object was removed, otherwise return 0. Beware, if this
* function returns 0, you still can not count on the kref from remaining in
* memory. Only use the return value if you want to see if the kref is now
* gone, not present.
*/
static inline int kref_put(struct kref *kref, void (*release)(struct kref *kref))
{
return kref_sub(kref, 1, release);
}
static inline int kref_put_mutex(struct kref *kref,
void (*release)(struct kref *kref),
struct mutex *lock)
{
WARN_ON(release == NULL);
if (unlikely(!atomic_add_unless(&kref->refcount, -1, 1))) {
mutex_lock(lock);
if (unlikely(!atomic_dec_and_test(&kref->refcount))) {
mutex_unlock(lock);
return 0;
}
release(kref);
return 1;
}
return 0;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
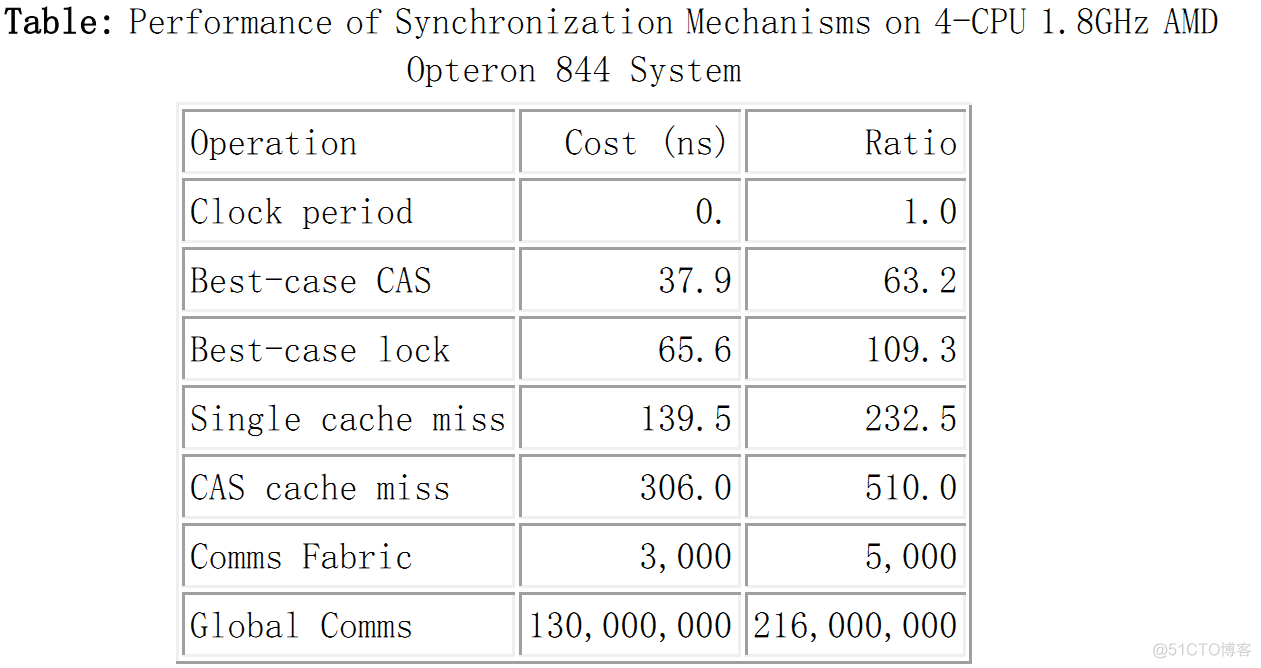
Clock consumption of various basic operations
http proxy server (3-4-7 Layer of the agent )- Network event library common component 、 kernel kernel drive Camera drive tcpip Network protocol stack 、netfilter、bridge Seems to have seen !!!! But he that doeth good Don't ask future -- Height and weight 180 Fat man
边栏推荐
- QT—双缓冲绘图
- Representation of confidence interval
- Open3d surface normal vector calculation
- How to transfer to software testing, one of the high paying jobs in the Internet? (software testing learning roadmap attached)
- 力扣3_383. 赎金信
- PostgreSQL JOIN实践及原理
- 股票开户流程是什么?使用同花顺手机炒股软件安全吗?
- 好用app推荐:扫描二维码、扫描条形码并查看历史
- Which securities company is better to open an account? Is online account opening safe
- HUAWEI nova 10系列发布 华为应用市场筑牢应用安全防火墙
猜你喜欢
傳智教育|如何轉行互聯網高薪崗比特之一的軟件測試?(附軟件測試學習路線圖)

Deveco device tool 3.0 release brings five capability upgrades to make intelligent device development more efficient
力扣98:验证二叉搜索树
Éducation à la transmission du savoir | Comment passer à un test logiciel pour l'un des postes les mieux rémunérés sur Internet? (joindre la Feuille de route pour l'apprentissage des tests logiciels)

卷积神经网络模型之——LeNet网络结构与代码实现
并发优化总结
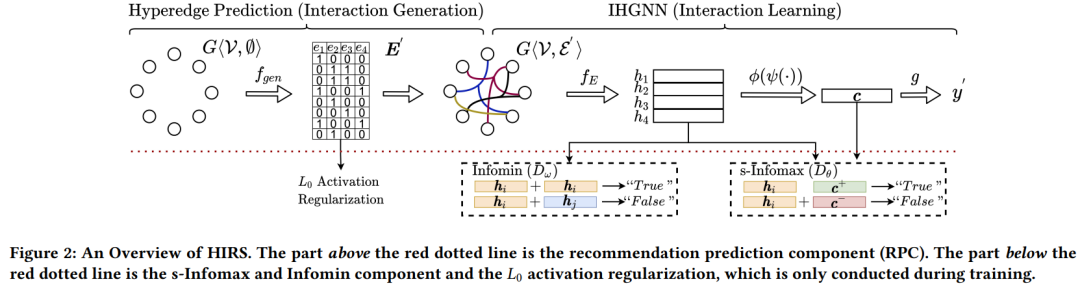
KDD2022 | 什么特征进行交互才是有效的?

Energy momentum: how to achieve carbon neutralization in the power industry?
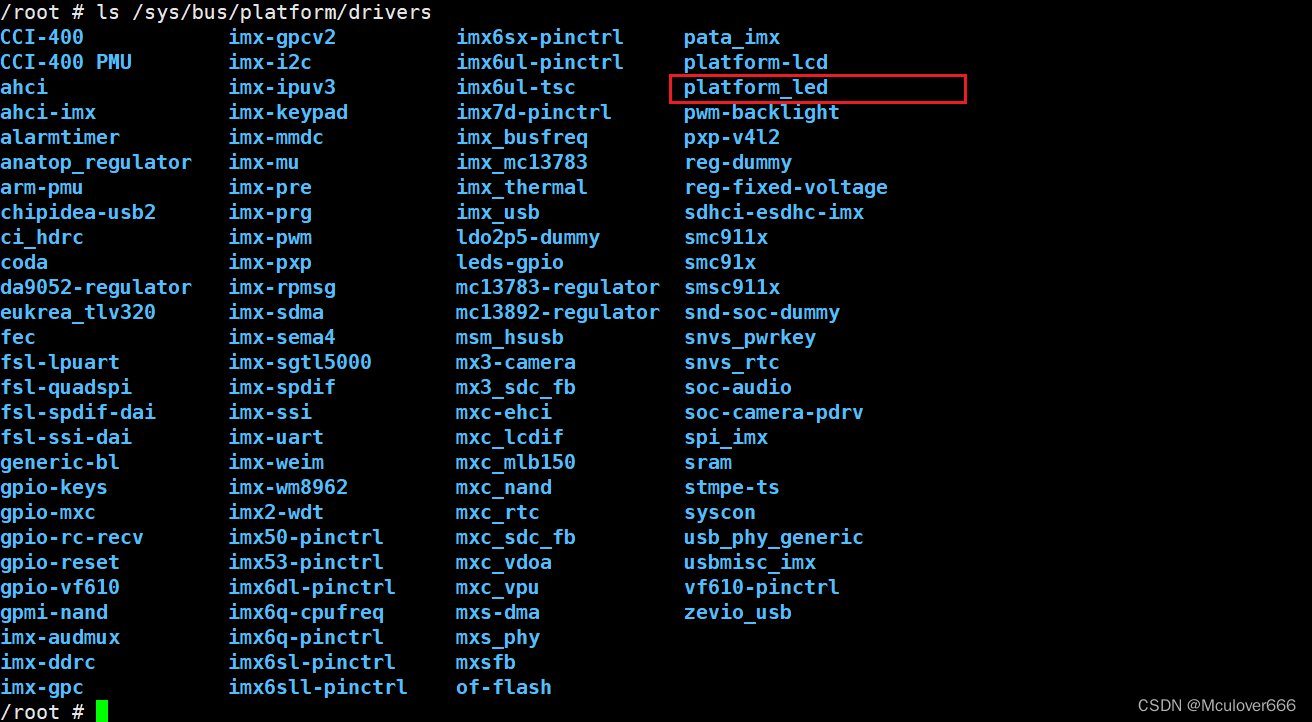
i.MX6ULL驱动开发 | 24 - 基于platform平台驱动模型点亮LED
HUAWEI nova 10系列发布 华为应用市场筑牢应用安全防火墙
随机推荐
Implementation rules for archiving assessment materials of robot related courses 2022 version
NAACL-22 | 在基于Prompt的文本生成任务上引入迁移学习的设置
VS2019 C# release下断点调试
可视化任务编排&拖拉拽 | Scaleph 基于 Apache SeaTunnel的数据集成
关系型数据库
ACM Multimedia 2022 | 视觉语言预训练模型中社会偏见的反事实衡量和消除
KDD2022 | 什么特征进行交互才是有效的?
Scala下载和配置
A large number of virtual anchors in station B were collectively forced to refund: revenue evaporated, but they still owe station B; Jobs was posthumously awarded the U.S. presidential medal of freedo
QT—双缓冲绘图
Radio and television Wuzhou signed a cooperation agreement with Huawei to jointly promote the sustainable development of shengteng AI industry
gtest从一无所知到熟练使用(3)什么是test suite和test case
Representation of confidence interval
做BI开发,为什么一定要熟悉行业和企业业务?
HUAWEI nova 10系列发布 华为应用市场筑牢应用安全防火墙
制作条形码的手机App推荐
gtest从一无所知到熟练使用(2)什么是测试夹具/装置(test fixture)
HDU - 1078 fatmouse and cheese (memory search DP)
【米哈游2023届秋招】开启【校招唯一专属内推码EYTUC】
Cloudcompare & open3d DBSCAN clustering (non plug-in)