当前位置:网站首页>MySql index learning and use; (I think it is detailed enough)
MySql index learning and use; (I think it is detailed enough)
2022-08-05 03:34:00 【If you never betray, dependent life and death I will】
MySql的索引
一,什么是索引?作用是什么?
索引:对数据库中一列或多列的值进行排序的一种结构
作用:使用索引可以快速访问数据库表中特定信息(加速检索表中的数据)
优点
1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间.
缺点
1.索引需要占物理空间.
2.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度.
二、索引类型
Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE
1. FULLTEXT
即为全文索引,其可以在CREATE TABLE ,ALTER TABLE ,CREATE INDEX 使用,不过目前只有 CHAR、VARCHAR ,TEXT 列在这里插入代码片上可以创建全文索引.
全文索引并不是和MyISAM一起诞生的,它的出现是为了解决WHERE name LIKE “%word%"这类针对文本的模糊查询效率较低的问题.
2. HASH
由于HASH的唯一(几乎100%的唯一)及类似键值对的形式,很适合作为索引.
HASH索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率.但是,这种高效是有条件的,即只在“=”和“in”条件下高效,对于范围查询、排序及组合索引仍然效率不高.
3. BTREE
BTREE索引就是一种将索引值按一定的算法,存入一个树形的数据结构中(二叉树),每次查询都是从树的入口root开始,依次遍历node,获取leaf.这是MySQL里默认和最常用的索引类型.
4. RTREE
RTREE在MySQL很少使用,仅支持geometry数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种.
相对于BTREE,RTREE的优势在于范围查找
三、索引类型
普通索引:仅加速查询
唯一索引:加速查询 + 列值唯一(可以有null)
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索
ps.
索引合并,使用多个单列索引组合搜索
覆盖索引,select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖.
四、执行计划
explain + 查询SQL - 用于显示SQL执行信息参数,根据参考信息可以进行SQL优化
普通索引
最基本的索引类型,没有唯一性之类的限制.普通索引可以通过以下几种方式创建:
创建索引,例如CREATE INDEX <索引的名字> ON tablename (列的列表);
修改表,例如ALTER TABLE tablename ADD INDEX [索引的名字] (列的列表);
创建表的时候指定索引,例如CREATE TABLE tablename ( [...], INDEX [索引的名字] (列的列表) );
tablename :表名
列的列表:字段名字 eg:name
An index built with common columns in a table,没有任何限制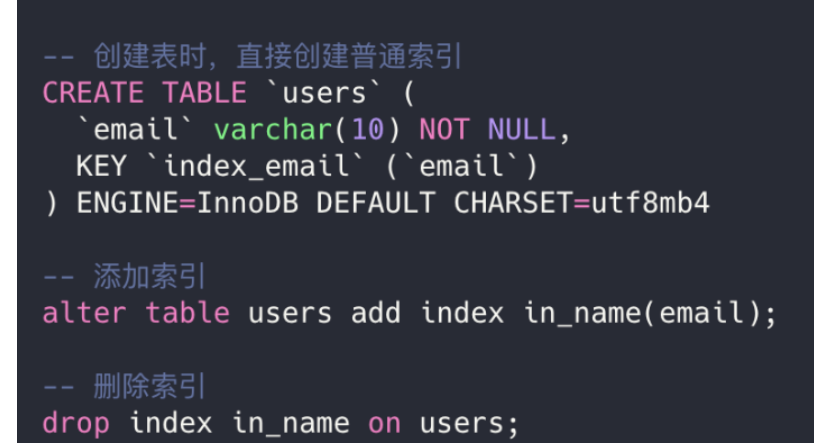
唯一索引
唯一索引是不允许其中任何两行具有相同索引值的索引.
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存.数据库还可能防止添加将在表中创建重复键值的新数据.例如,如果在 employee 表中职员的姓 (lname) 上创建了唯一索引,则任何两个员工都不能同姓.
对某个列建立UNIQUE索引后,插入新记录时,数据库管理系统会自动检查新纪录在该列上是否取了重复值,在CREATE TABLE 命令中的UNIQE约束将隐式创建UNIQUE索引.
创建唯一索引的几种方式:
tablename :表名
列的列表:字段名字 eg:name
创建索引,例如CREATE UNIQUE INDEX <索引的名字> ON tablename (列的列表);
修改表,例如ALTER TABLE tablename ADD UNIQUE [索引的名字] (列的列表); ;
创建表的时候指定索引,例如CREATE TABLE tablename ( [...], UNIQUE [索引的名字] (列的列表) );
用来建立索引的列的值必须是唯一的,可以为空.
主键索引
简称为主索引,数据库表中一列或列组合(字段)的值唯一标识表中的每一行.该列称为表的主键.
在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型.该索引要求主键中的每个值都唯一.当在查询中使用主键索引时,它还允许对数据的快速访问.
提示尽管唯一索引有助于定位信息,但为获得最佳性能结果,建议改用主键索引.
即主索引,根据主键创建的索引,不允许重复,不允许为空值.
如果表中没有定义主键,InnoDB会选择一个唯一的非空索引代替.
如果没有这样的索引,InnoDB会隐式的定义一个主键来作为聚簇索引.
全文索引
用大文本对象的列构建的索引
组合索引
An index composed of multiple columns,Nulls are not allowed in these multiple columns
在这里插入图片描述

候选索引
与主索引一样要求字段值的唯一性,并决定了处理记录的顺序.在数据库和自由表中,可以为每个表建立多个候选索引.
聚集索引
也称为聚簇索引,在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同.一个表只能包含一个聚集索引, 即如果存在聚集索引,就不能再指定CLUSTERED 关键字.

索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配.与非聚集索引相比,聚集索引通常提供更快的数据访问速度.聚集索引更适用于对很少对基表进行增删改操作的情况.
如果在表中创建了主键约束,SQL Server将自动为其产生唯一性约束.在创建主键约束时,指定了CLUSTERED关键字或干脆没有制定该关键字,SQL Sever将会自动为表生成唯一聚集索引.
非聚集索引
也叫非簇索引,在非聚集索引中,数据库表中记录的物理顺序与索引顺序可以不相同.一个表中只能有一个聚集索引,但表中的每一列都可以有自己的非聚集索引.如果在表中创建了主键约束,SQL Server将自动为其产生唯一性约束.在创建主键约束时,如果制定CLUSTERED关键字,则将为表产生唯一聚集索引.
UNIQUE——建立唯一索引.
CLUSTERED——建立聚集索引.
NONCLUSTERED——建立非聚集索引.
ASC——索引升序排序.
DESC——索引降序排序.
Example project code
1、字段的数值有唯一性限制
根据Alibaba规范,Indicates fields that are unique in business,即使是组合字段,也必须建成唯一索引.
例如,The student number in the student table is a unique field,Establishing a unique index for this field can quickly query the information of a certain student,如果使用姓名的话,There may be cases with the same name,从而降低查询速度.
2、频繁作为Where查询条件的字段
某个字段在Select语句的Where条件中经常被使用到,那么就需要给这个字段创建索引,Especially in the case of large amount of data,Creating a common index can greatly improve query efficiency.
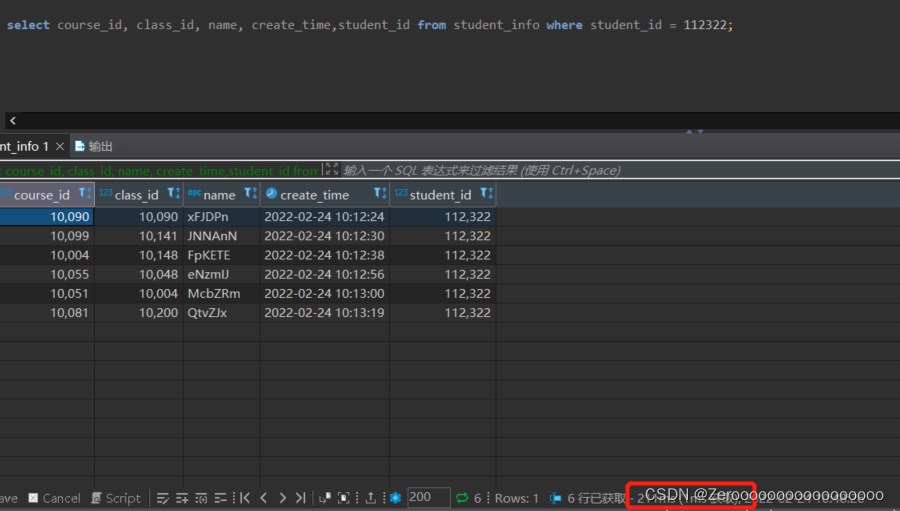
比如测试表student_info有100万数据,假设查询student_id=112322的用户信息,如果没有对student_id字段创建索引,查询结果如下:
select course_id, class_id, name, create_time,student_id from student_info where
student_id = 112322;# 花费211ms
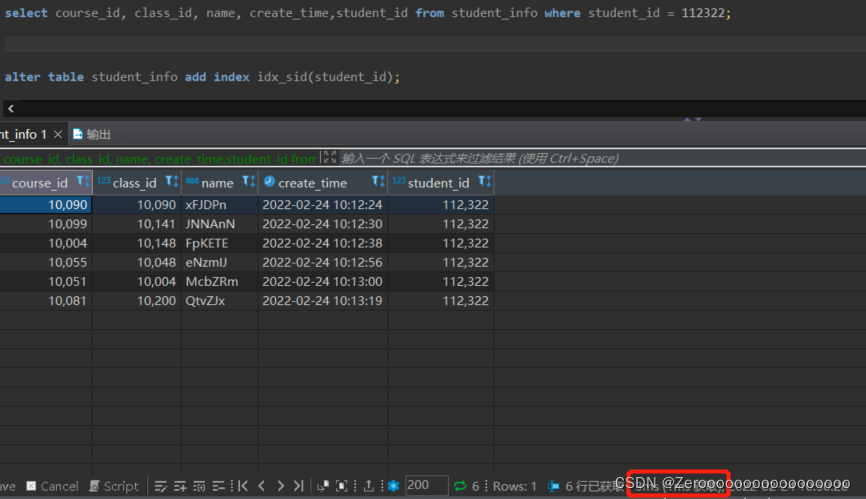
为student_id创建索引后,查询结果如下:
alter table student_info add index idx_sid(student_id);
select course_id, class_id, name, create_time,student_id from
student_info where student_id = 112322;# 花费3ms
3、经常Group by和Order by的列
索引就是让数据按照某种顺序进行存储或检索,因此当使用Group byQuery or use grouped dataOrder by对数据进行排序的时候 ,It is necessary to index the grouped or sorted fields.如果待排序的列有多个,That can build composite indexes on those columns.
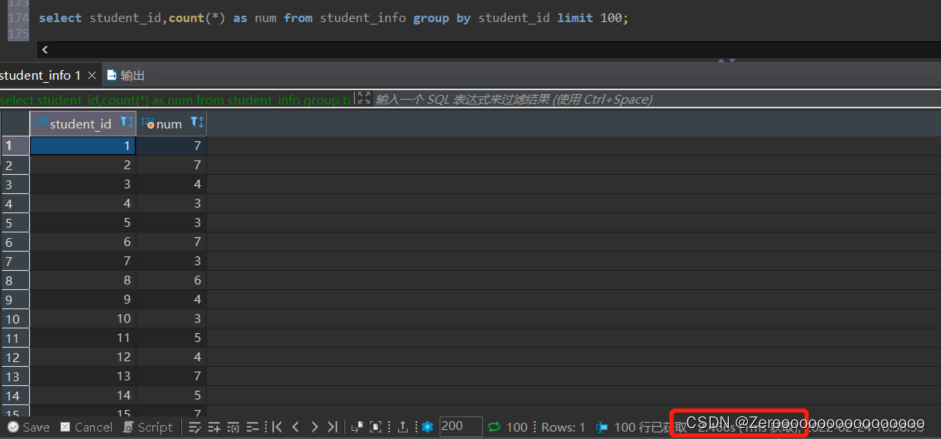
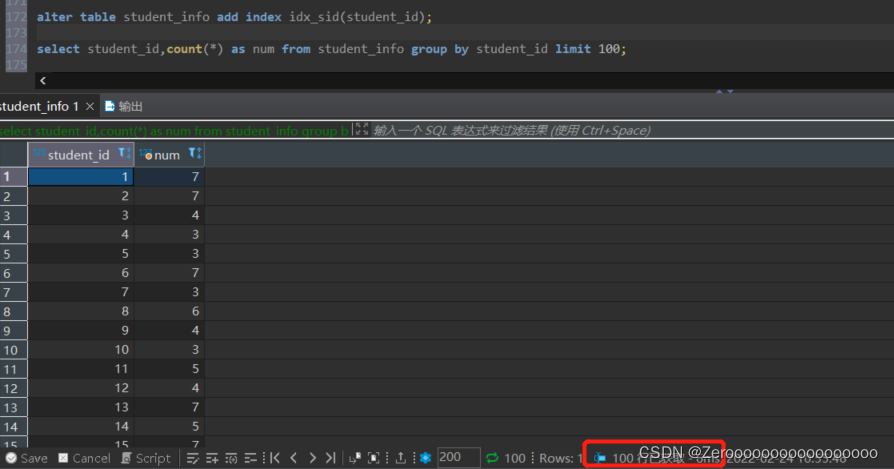
比如,按照student_idGroup the courses for which students are drafted,显示不同的student_idand the number of courses,显示100条.如果不对student_id创建索引,查询结果如下:
select student_id,count(*) as num from student_info group by student_id limit 100;#花费2.466s
为student_id创建索引后,查询结果如下:
alter table student_info add index idx_sid(student_id);
select student_id,count(*) as num from student_info group by student_id limit 100;#花费6ms
对于既有group by又有order by的查询语句,It is recommended to build a joint index,并且将group bythe fields in the order byfront of the field,满足‘最左前缀匹配原则’,In this way, the utilization of the index will be high,The efficiency of natural query will also be high;同时8.0Later versions support descending indexes,如果order bySubsequent fields are in descending order,Consider creating a descending index directly,也会提高查询效率.
4、Update、Delete的where条件列
对数据按照某个条件进行查询后再进行Update或Delete的操作,如果对Where字段创建了索引,answer to improve efficiency.The reason is because it needs to be based on firstWhere条件列检索出来这条记录,Then update or delete it.如果进行更新的时候,更新的字段是非索引字段,The efficiency improvement will be more obvious,This is because the fee index field update does not require maintenance.
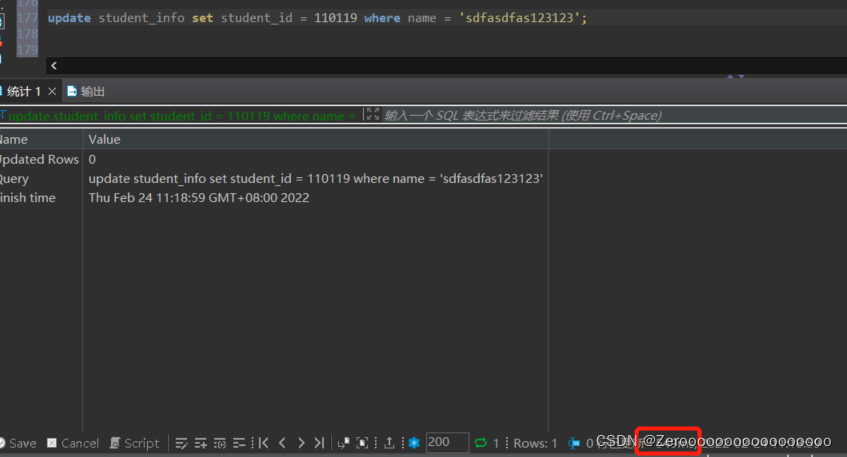
比如对student_info表中的name字段为sdfasdfas123123的数据修改student_id为110119,在没有对name字段建立索引的情况下,执行情况如下:
update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费549ms
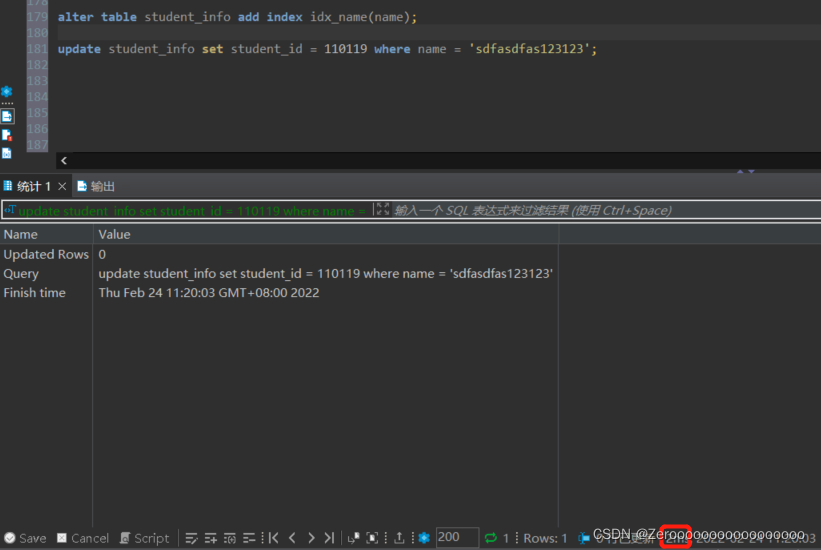
添加索引后,执行情况如下:
alter table student_info add index idx_name(name);
update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费2ms
5、Distinct字段需要创建索引
有时候需要对某个字段进行去重,使用Distinct,Then creating an index on this will also improve query efficiency.
For example, the query curriculum is differentstudent_id都有哪些,如果没有为student_id创建索引,执行情况如下:
select distinct(student_id) from student_id;#花费2ms
创建索引后,执行情况如下:
alter table student_info add index idx_sid(student_id);
select distinct(student_id) from student_id;#花费0.1ms
6、多表Join连接操作时,创建索引注意事项
首先,The amount of data in the join table should not exceed as much as possible3张,因为每增加一张表就相当于增加了一次嵌套的循环,数量级增长非常快,严重影响查询效率.其次,对Where条件创建索引,因为Where才是对数据条件的过滤,If the amount of data is very large,没有WhereTerrible when conditional filtering,最后,对于连接的字段创建索引,And the type of the changed field must be the same in multiple tables.

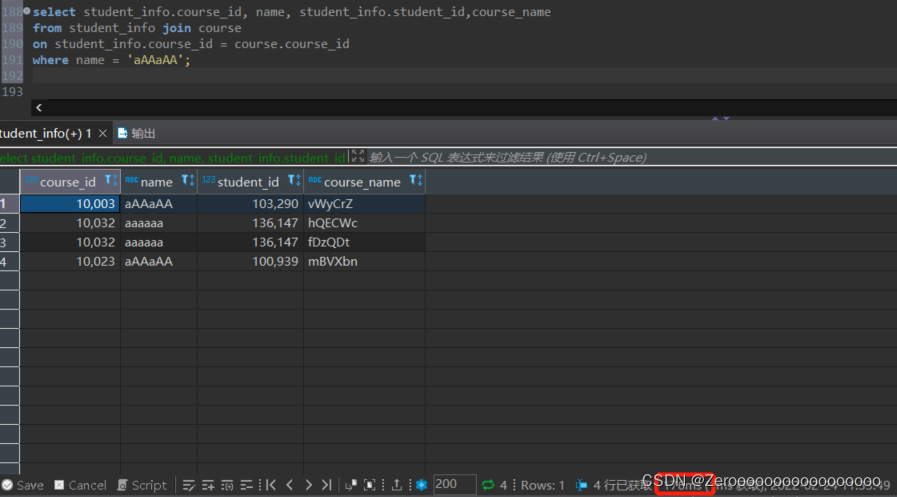
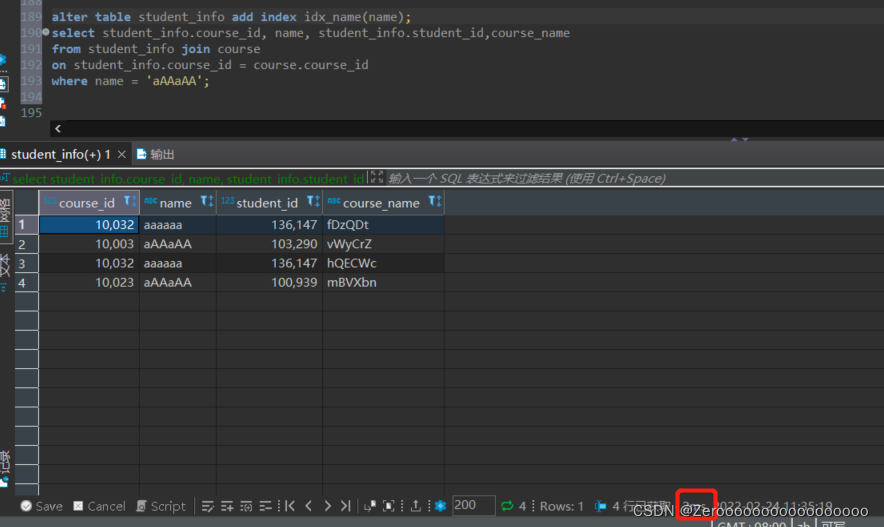
比如,只对student_id创建索引,查询结果如下:
select course_id, name, student_info.student_id,course_name
from student_info join course
on student_info.course_id = course.course_id
where name = 'aAAaAA'; #花费176ms
给name字段创建索引后,查询结果如下:
alter table student_info add index idx_name(name);
select course_id, name, student_info.student_id,course_name
from student_info join course
on student_info.course_id = course.course_id
where name = 'aAAaAA'; #花费2ms
7、使用列的类型小的创建索引
这里所说的类型小值意思是该类型表示的数据范围的大小.For example, the type of the specified column to be displayed when defining the table structure,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT等,The storage space they occupy increases sequentially,The range of data that can be represented is also one increment.If indexed against an integer column,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,For example, it can be usedINT不要使用BIGINT,能使用MEDIUMINT不使用INT,原因如下:
数据类型越小,在查询时进行的比较操作越快
数据类型越小,索引占用的空间就越少,在一个数据页内就可以存下更多的记录,从而减少磁盘I/O带来的性能损耗,This means that more data can be stored in the data pages,提高读写效率.
The above is fine for primary keys,Because the data is stored in the clustered index,Indexes are also stored,Can be very good to reduce the diskI/O;而对于二级索引来说,A return table operation is also required to find the complete data,You can also add a diskI/O.
8、使用字符串前缀创建索引
根据Alibaba开发手册,When indexing on strings,必须指定索引长度,没有必要对全字段建立索引.
For example, there is a list of goods,The item description field in the table is long,Build a prefix index on the description field as follows:
create table product(id int, desc varchar(120) not null);
alter table product add index(desc(12));
The calculation of the degree of discrimination can be usedcount(distinct left(列名, 索引长度))/count(*)来确定
9、区分度高的列适合作为索引
The cardinality value of a column is the number of distinct data in a column,Say a column contains values2,5,3,6,2,7,2,虽然有7条记录,但该列的基数却是5,也就是说,在记录行数一定的情况下,列的基数越大,The values in that column are more spread out;列的基数越小,The more concentrated the values in that column.The cardinality indicator of the column is very important here,Directly affects whether the index can be effectively used.最好为列的基数大的列建立索引,Indexing columns with too small cardinality is not good.
可以使用公式select count(distinct col)/count(*) from table to calculate the distinction,越接近1区分度越好.
10、使用最频繁的列放到联合索引的左侧
This is the so-called leftmost prefix matching principle. 通俗来讲就是将WhereCondition fields that are often used after the condition are placed at the far left of the index,Put the ones that are used less frequently to the right.
11、在多个字段都要创建索引的情况下,Joint indexes are due to single-valued indexes
二、不适合创建索引
1、在where中使用不到的字段不要设置索引
Usually indexing comes at a cost,If the indexed field does not appearwhere条件(包括group by、order by)中,It is recommended not to create an index or drop an index in the first place,Because the existence of the index will also take up space.
2、数据量小的表最好不要使用索引
3、有大量重复数据的列上不要建立索引
在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引.For example, the gender field in the student table,There are only male and female values,So there is no need to build an index.如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度.
4、避免对经常更新的表创建过多的索引
- 频繁更新的字段不一定要创建索引,因为更新数据的时候,The index should also be updated accordingly,如果索引太多,It will cause server pressure when updating,从而影响效率.
- 避免对经常更新的表创建过多的索引,并且索引中的列尽可能少.At this time, although the query speed is improved,同时也会降低更新表的速度.
5、不建议用无序的值作为索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等.
6、Drop indexes that are not in use or are rarely used
After the data in the table has been updated a lot or the way the data is used has changed,Some of the original indexes may not be used.DBAThese indexes should be identified and removed periodically,Thereby, less useless indexes affect the update operation.
7、不要定义冗余或重复的索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等.
8、Drop indexes that are not in use or are rarely used
After the data in the table has been updated a lot or the way the data is used has changed,Some of the original indexes may not be used.DBAThese indexes should be identified and removed periodically,Thereby, less useless indexes affect the update operation.
9、不要定义冗余或重复的索引
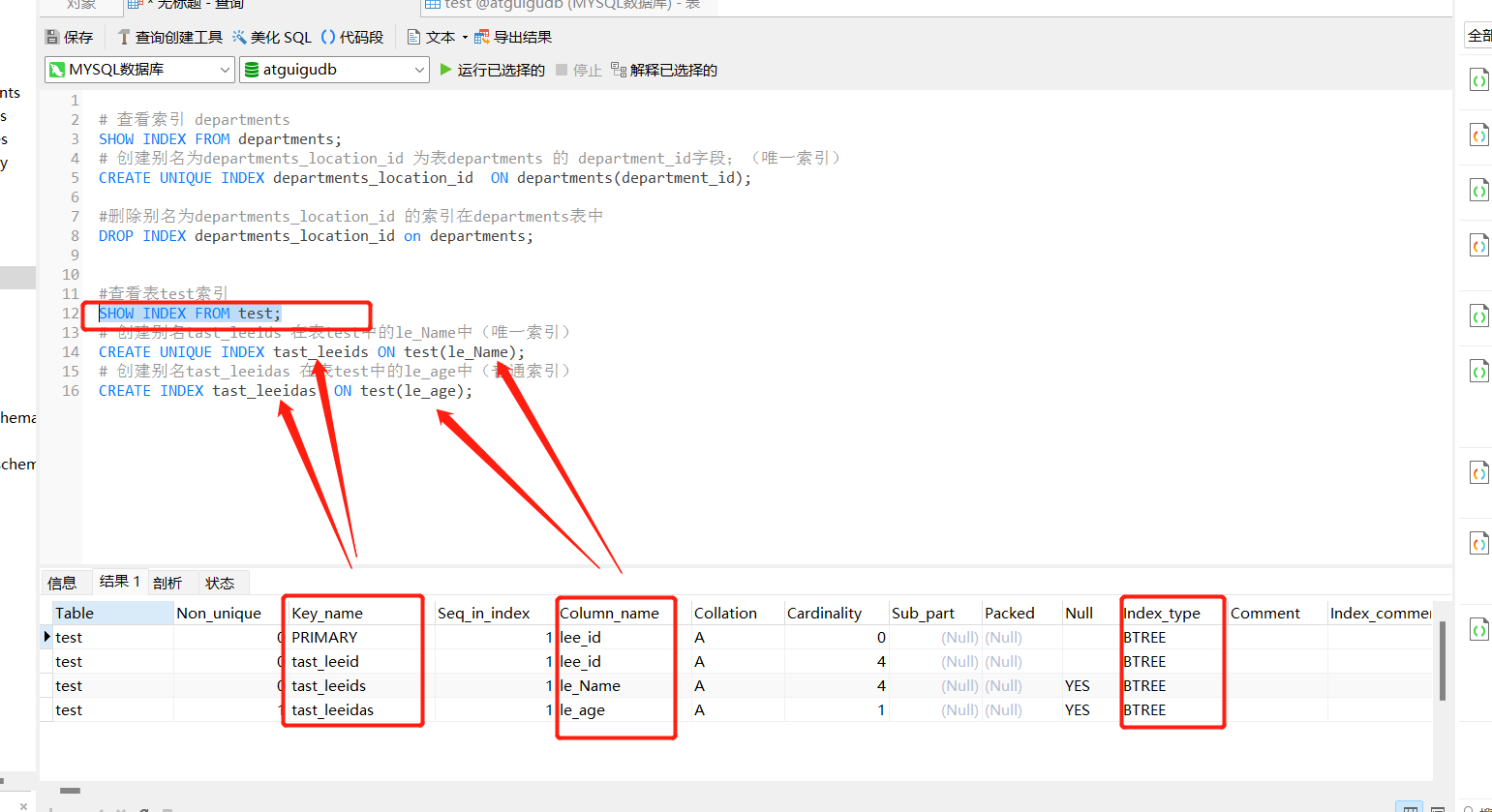
Local easy-to-understand ideasDEMO
# 查看索引表 departments
SHOW INDEX FROM departments;
# Create an alias asdepartments_location_id 为表departments 的 department_id字段;(唯一索引)
CREATE UNIQUE INDEX departments_location_id ON departments(department_id);
#删除别名为departments_location_id 的索引在departments表中
DROP INDEX departments_location_id on departments;
#查看表test索引
SHOW INDEX FROM test;
# 创建别名tast_leeids 在表test中的le_Name中(唯一索引)
CREATE UNIQUE INDEX tast_leeids ON test(le_Name);
# 创建别名tast_leeidas 在表test中的le_age中(普通索引)
CREATE INDEX tast_leeidas ON test(le_age);
不足之处;还请多多指教;
边栏推荐
- UE4 通过与其它Actor互动开门
- 2022.8.4-----leetcode.1403
- 用Unity发布APP到Hololens2无坑教程
- 关于#SQL#的迭代、父子结构查询问题,如何解决?
- 数组常用方法总结
- iMedicalLIS监听程序(2)
- You may use special comments to disable some warnings. Three ways to report errors
- Why did they choose to fall in love with AI?
- Acid (ACID) Base (BASE) Principles for Database Design
- How to Add Category-Specific Widgets in WordPress
猜你喜欢
【七夕节】浪漫七夕,代码传情。将爱意变成绚烂的立体场景,给她(他)一个惊喜!(送代码)
Defect detection (image processing part)
Swing有几种常用的事件处理方式?如何监听事件?
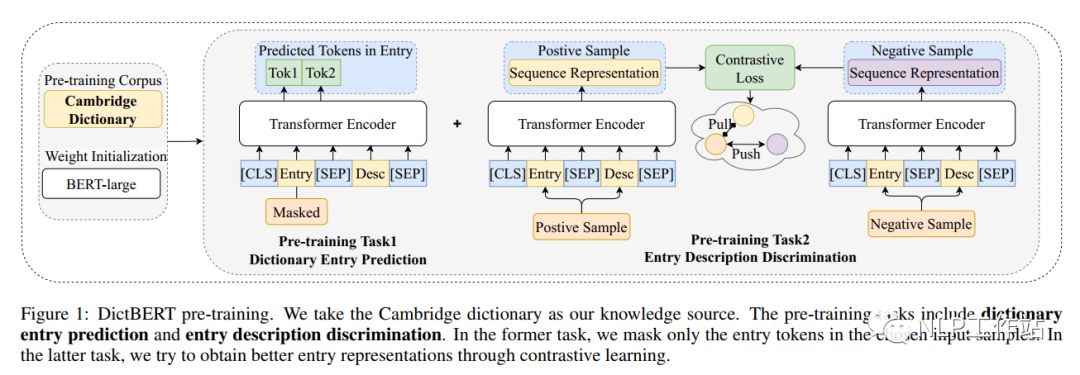
IJCAI2022 | DictBert: Pre-trained Language Models with Contrastive Learning for Dictionary Description Knowledge Augmentation
ASP.NET应用程序--Hello World

七夕节代码表白
新人如何入门和学习软件测试?

UE4 后期处理体积 (角色受到伤害场景颜色变淡案例)
YYGH-13-客服中心
冰蝎V4.0攻击来袭,安全狗产品可全面检测
随机推荐
UE4 通过互动(键盘按键)开门
Based on holding YOLOv5 custom implementation of FacePose YOLO structure interpretation, YOLO data format conversion, YOLO process modification"
Detailed and comprehensive postman interface testing practical tutorial
Why did they choose to fall in love with AI?
七夕节代码表白
.NET应用程序--Helloworld(C#)
What is the difference between SAP ERP and ORACLE ERP?
There are several common event handling methods in Swing?How to listen for events?
shell脚本:for循环与while循环
Summary of common methods of arrays
Industry Status?Why do Internet companies prefer to spend 20k to recruit people rather than raise their salary to retain old employees~
冰蝎V4.0攻击来袭,安全狗产品可全面检测
ffmpeg enumeration decoders, encoders analysis
冒泡排序与快速排序
On governance and innovation, the 2022 OpenAtom Global Open Source Summit OpenAnolis sub-forum came to a successful conclusion
Slapped in the face: there are so many testers in a certain department of byte
The sword refers to Offer--find the repeated numbers in the array (three solutions)
数组常用方法总结
[论文笔记] MapReduce: Simplified Data Processing on Large Clusters
Initial solution of the structure